 Groq LPU 如何让万亿参数模型「飞」起来?揭秘 Kimi K2 40 倍提速背后的黑科技
Groq LPU 如何让万亿参数模型「飞」起来?揭秘 Kimi K2 40 倍提速背后的黑科技

Groq LPU 如何让万亿参数模型「飞」起来?揭秘 Kimi K2 40 倍提速背后的黑科技
最近,Moonshot AI 的千亿参数大模型 Kimi K2 在 GroqCloud 上开放预览,引发了开发者社区的疯狂讨论——为什么 Groq 能跑得这么快?
传统 AI 推理硬件(如 GPU)往往面临一个两难选择:
✅ 快(但牺牲精度)
⛔ 准(但延迟高到无法接受)
而 Groq 的 LPU(Language Processing Unit) 却打破了这一魔咒,既快又准。
1. 精度与速度的「鱼与熊掌」:如何兼得?
传统硬件的「量化陷阱」
大多数 AI 加速器(如 GPU)为了提升推理速度,会采用 INT8/FP8 等低精度计算,但这会导致累积误差,模型质量大幅下降。
Groq 的「TruePoint Numerics」黑科技
Groq 的解决方案是 动态精度调整:
权重/激活函数:用低精度存储(节省内存)
矩阵运算:全精度计算(保证结果无损)
输出阶段:根据下游需求智能选择量化策略
这样一来,速度比 BF16 快 2-4 倍,但精度无损(MMLU/HumanEval 等基准测试验证)。
传统 AI 芯片(如 GPU)依赖 HBM/DRAM 作为主存,每次权重访问延迟高达数百纳秒,严重影响推理速度。
而 Groq 直接集成数百兆片上 SRAM,让权重加载零延迟,计算单元全速运转。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
91文章
42612浏览量
303527 -
大模型
+关注
关注
2文章
3912浏览量
5348
发布评论请先 登录
相关推荐
热点推荐
登临科技KS系列GPU产品Day 0适配Kimi-K2.6模型
2026年4月,随着Kimi-K2.6这一开源原生多模态智能体模型的正式发布,AI领域迎来了又一次重要的技术演进。该模型在长周期编程、编程驱动设计、智能体集群任务编排及主动自主执行等核心能力上取得了显著进展,为开发者和企业带来了

壁仞科技壁砺166系列GPU产品率先支持Kimi K2.6模型
4月20日晚,月之暗面正式发布并开源Kimi K2.6模型,带来行业领先(state-of-the-art)的代码、长程任务执行和Agent集群能力。壁仞科技(06082.HK)旗舰通用GPU产品壁

Kimi K2.6模型发布当天上线华为云
4月20日, Kimi K2.6模型正式发布并开源,带来行业领先的代码、长程任务执行和Agent集群能力。当前,华为云完成适配并实现针对性优化。华为云MaaS模型即服务平台已为开发者提

中科曙光scaleX万卡超集赋能中国大模型出海新篇章
榜首,Kimi K2.5、智谱GLM-5、DeepSeek V3.2全线霸榜。这标志着中国大模型正加速走向全球,Token作为AI时代的通用货币,已成为中国数字价值出海的新载体。
大模型 ai coding 比较
:DeepSeek 10/10(100%通过),Kimi 2/10(20%通过)
2. Debug修复能力(权重35%)
测试目标 :模型排查和修复代码问题的能力
测评数据集:Debu
发表于 02-19 13:43
月之暗面全新开源旗舰模型Kimi K2.5上线模力方舟
模力方舟平台现已上线来自月之暗面(Moonshot AI)发布的全新开源旗舰模型Kimi K2.5。

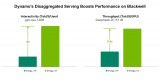
Dynamo 0.4在NVIDIA Blackwell上通过PD分离将性能提升4倍
近期,OpenAI 的 gpt-oss、月之暗面的 Kimi K2 等多个新的前沿开源模型相继问世,标志着大语言模型 (LLM) 创新浪潮的加速。近日发布的 Dynamo 0.4 提供
浪潮信息发布"元脑SD200"超节点,面向万亿参数大模型创新设计
扩展支持64路本土GPU芯片。元脑SD200可实现单机内运行超万亿参数大模型,并支持多个领先大模型机内同时运行及多智能体实时协作与按需调用,目前已率先实现商用。在实际评测中,元脑SD2

奇异摩尔邀您相约2025 AI网络技术应用创新大会
AI大模型的军备赛每天都在上演,近期Kimi发布的K2模型再次引发全球关注。相关专业机构评价K2是至今最好的开源权重
硅基流动携手沐曦首发基于曦云的Kimi K2推理服务
今天,硅基流动联合沐曦集成电路(上海)股份有限公司(简称“沐曦”),全球首发基于沐曦曦云 C550 集群的月之暗面 Kimi-K2 大模型商业化服务部署。该服务运行于汇天网络科技有限公司(简称“汇
万亿参数!元脑企智一体机率先支持Kimi K2大模型
北京2025年7月21日 /美通社/ -- 浪潮信息宣布元脑企智一体机已率先完成对Kimi K2 万亿参数大模型的适配支持,并实现单用户70
API让电商“飞”起来,告别手动操作
,让您轻松告别繁琐的手动操作。本文将一步步解析如何利用API实现电商流程的自动化,帮助您的业务“飞”起来。我们将从基础概念入手,逐步展示实际应用,并提供一个简单的代码示例,确保您能快速上手。 什么是API及其在电商中的




评论