 AI耳机变身翻译官+会议总结大师?涂鸦AI音频开发方案,让耳机升级到下一个level
AI耳机变身翻译官+会议总结大师?涂鸦AI音频开发方案,让耳机升级到下一个level

在接入 AI 能力后,耳机这种日常化的产品,能有多大的想象空间?它不仅能帮你轻松听懂全球外语和地方方言,还能将语音转化为文字、翻译成不同语言,甚至自动总结会议要点、生成思维导图,适配办公、学习、跨语言交流及日常生活等多类场景,妥妥的人类新型“智能听觉中枢”!
为了助力开发者/品牌商快速开发能听会说的 AI 音频类设备,涂鸦重磅发布 AI 音频转录总结方案,覆盖耳机、录音设备、眼镜、音箱等硬件形态。通过简单易用的涂鸦 API,开发者只需在涂鸦的面板小程序中少量配置,就能实现 App 收声,并支持语音识别、翻译、摘要、思维导图生成等功能;搭配强大的 AI 引擎,开发者开箱即用,开发门槛更低。
目前,开发者可通过涂鸦云接入 DeepSeek、豆包、通义千问、Kimi、元宝等国内模型,海外则兼容 ChatGPT、Claude、Gemini 等先进 AI 大模型。
一、落地应用案例
1、AI 耳机:录音翻译大师
涂鸦赋能 AI 耳机,支持将音频数据传输到 App 上,并通过 VAD(语音活动检测)+ ASR(语音转录文字)能力,实时处理数据。语音转录为文字后,就可将识别结果即时反馈给App。此外,依托 AI 大模型技术,涂鸦可进一步总结转换后的文字内容,并精准翻译,通过耳机语音播报给用户。这不仅提升了用户的使用体验,还能够满足线上或面对面的多语言交流需求。
2、AI 会议录音卡片:办公神助攻
涂鸦赋能AI 会议录音卡片,不仅是一个录音工具,更能够与会议纪要功能结合:它支持实时总结会议音频内容,并智能生成文字摘要和详细的会议纪要。这一解决方案有效地简化了会议记录+总结过程,高效率推动后续工作,帮助上班族节省时间与精力。
二、App 界面功能演示
下方是涂鸦赋能App 界面的展示,连接 AI 音频设备后(接下来将以涂鸦赋能 AI 耳机为例,进行具体介绍),即可拥有现场录音、同声传译和面对面翻译功能。功能将持续迭代,敬请期待!
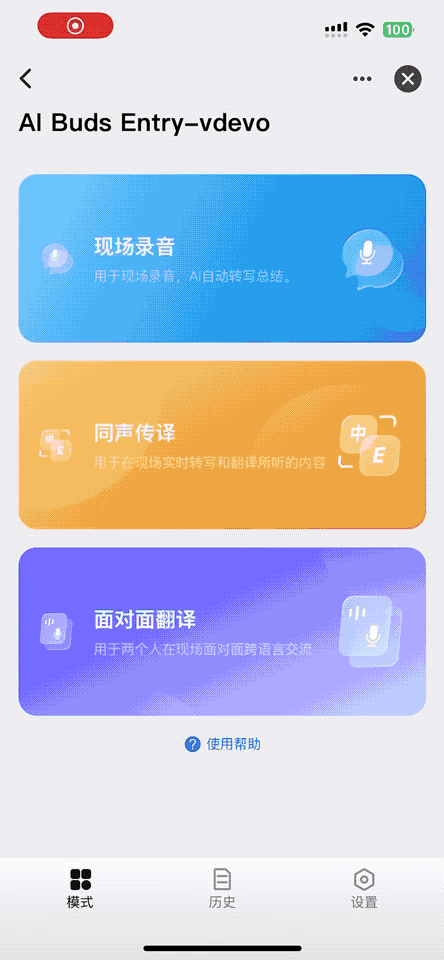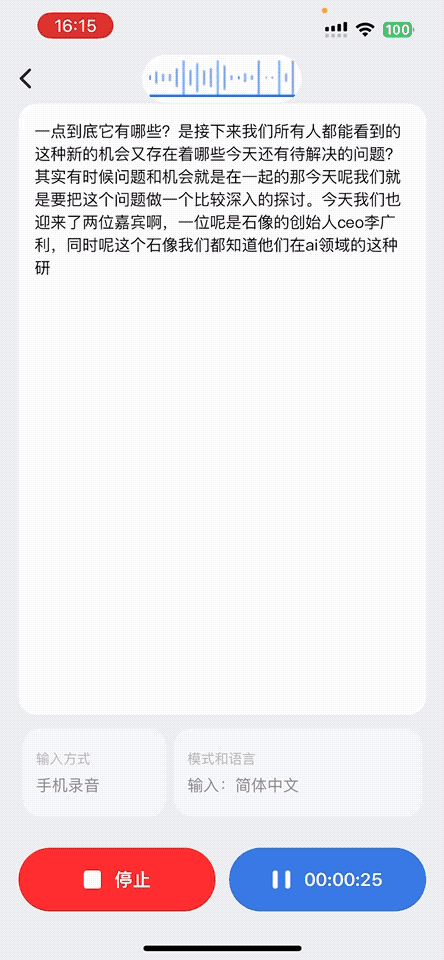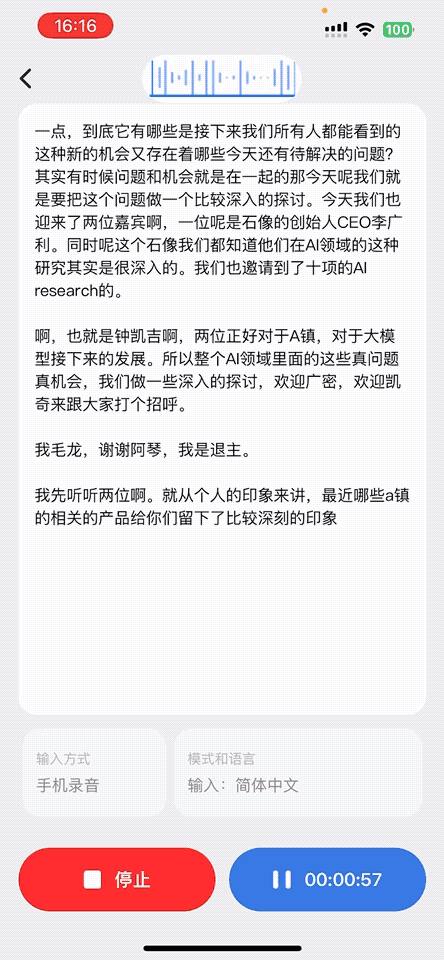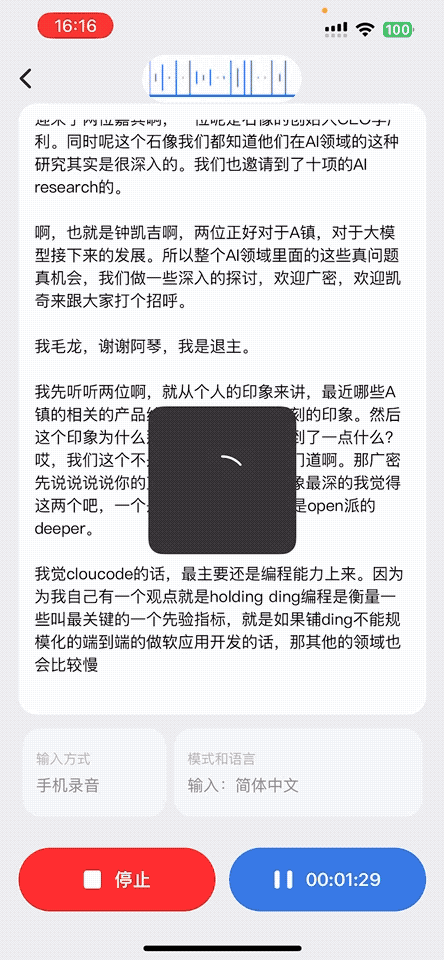
1、音频实时转录成文字
用户在通话、会议讲座或收听广播场景下,AI 耳机都会实时采集语音。App 接收音频数据后,会及时转写成文字,非常适合语言学习者、听障人群或需要文字记录的场景。识别结果会同步展示在屏幕上,便于查看、复制与保存。
下面是该功能的动态示意图:
2、面对面翻译
在跨语言交流场景中,两人都佩戴 AI 耳机或一人一只耳机,就可实现“你说我译”的双向语音翻译功能。语音通过耳机传入 App,App 实时转写、翻译并播报结果,大幅降低语言沟通门槛,适用于出境旅行、商务接待、跨境会谈等多语种场景。

3、会议录音
在多人会议或访谈场景中,AI 耳机可用作便捷的拾音设备,实时采集多方语音内容。App 端实现同步语音转写,并可生成完整的会议纪要和思维导图,支持后续查询、存档处理,有效提升会议效率与内容管理能力。


三、涂鸦 AI 音频技术的独特之处
涂鸦 AI 音频开发方案,由三大核心模块构成,即:设备端、App 端、云端AI,整体架构图可参考下方示意图:
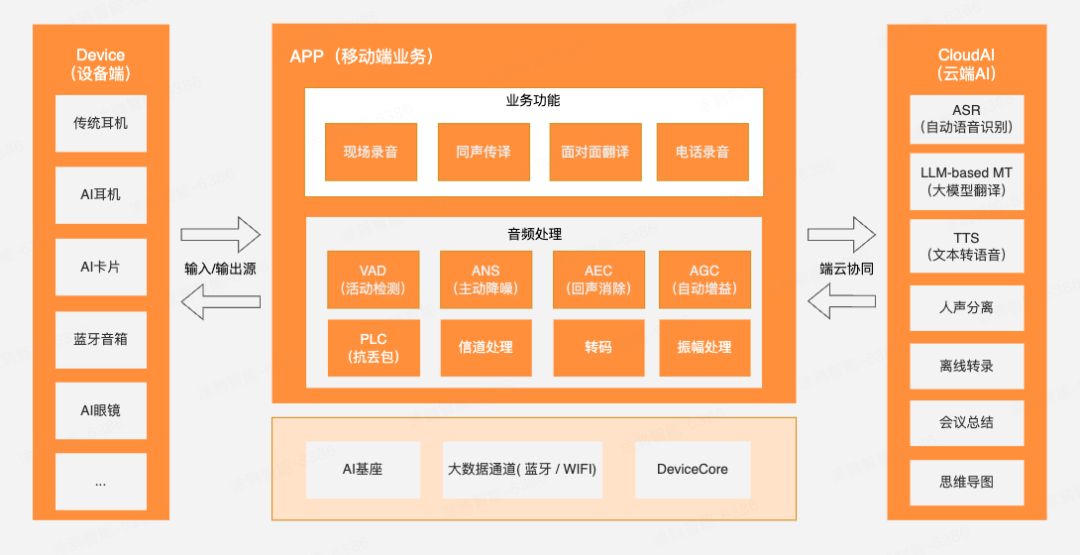
1、设备端
设备作为音频输入输出的载体,支持通过传统 BT 配对和 Bluetooth LE 的方式连接 App。相比普通蓝牙耳机,涂鸦赋能 AI Pro 耳机可以通过特定的 DP 点下发指令,实现更丰富的双向控制,如:
App 与 AI 耳机能够双向传输指令、同步状态
开始/暂停录音
控制单耳收音和播放
支持双耳一对一的同声翻译功能(即左右耳可同时播放不同内容,两个人分别佩戴一只耳机即可实现同声翻译)
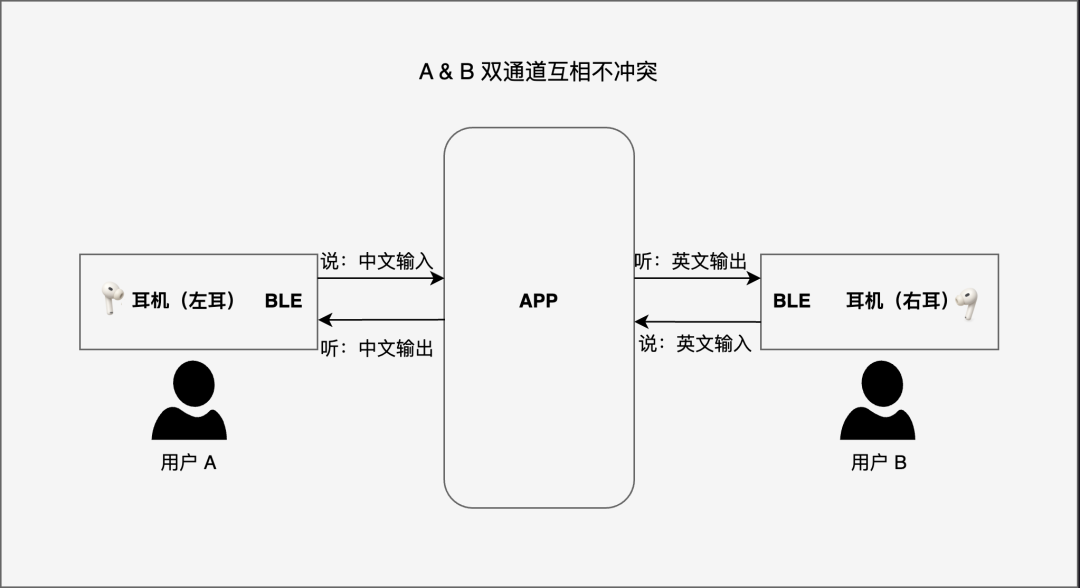
(左右耳双道独立运行流程图)
2、App 端
App 主要承担 AI 音频的数据处理与业务逻辑运行:
业务功能:支持现场录音、同声传译、面对面翻译、电话录音等功能模块;
音频处理:本地进行 VAD、AEC、ANS、AGC、PLC、振幅处理、转码、信道管理等技术处理,能够让音质的输出清晰无杂音、更稳定,并保持音频连续性;
基础能力:支持 AI 基座协议、设备通信协议、大数据通道(蓝牙/Wi-Fi)。
3、云端 AI 能力
涂鸦在云端AI集成了多个模型与能力,包括:
ASR:搭载高精度的语音自动识别,让 AI 秒懂人类语言,准确无误地将音频中的语音内容转写为文本;
LLM-based MT:支持用大语言模型做翻译,语境理解能力更强,告别从前死记硬背的机械式翻译(涂鸦目前可支持 65+ 地区语言,并不断扩展中);
TTS:支持文字转语音,能成熟模仿不同人物的音色,并搭配不同情绪的语气,让 AI 发音更拟人化(用户可自定义配置音色);
其他拓展能力:涂鸦还支持语音分离、离线转录、会议总结、思维导图生成等功能。
通过统一协议协同处理,端云一体可实现低延迟、高效率、高智商的 AI 语音服务。
四、AI 音频技术的流程处理
涂鸦 AI 音频技术的流程处理,总共分为三个阶段:
拾音+3A处理+转码:即声音采集与预处理
VAD+音频切片:即有效语音检测与切片处理
ASR+翻译+TTS:即智能识别、翻译与语音合成
整体流程图可参考: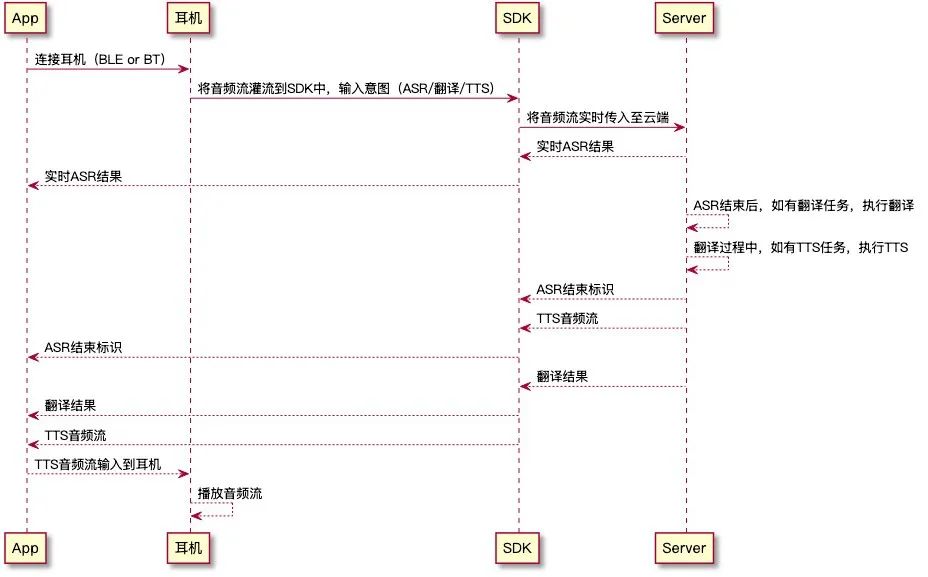
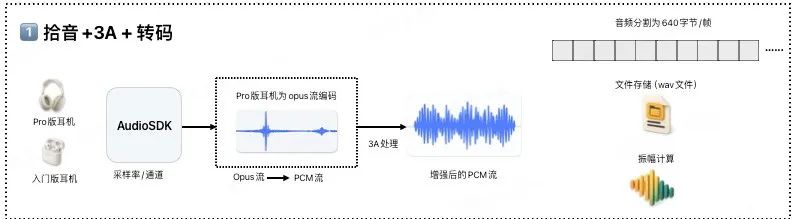
1、拾音+3A处理+转码
首先,由耳机或 App 采集原始语音,并降噪、消除回声后统一加工成 PCM 流后,交给 3A 模块进行预处理。处理后的音频会自动保存为 wav 文件,便于进行振幅计算(即计算声音强度);为了后续高效处理,涂鸦将音频数据分割为 640b/帧的数据块。
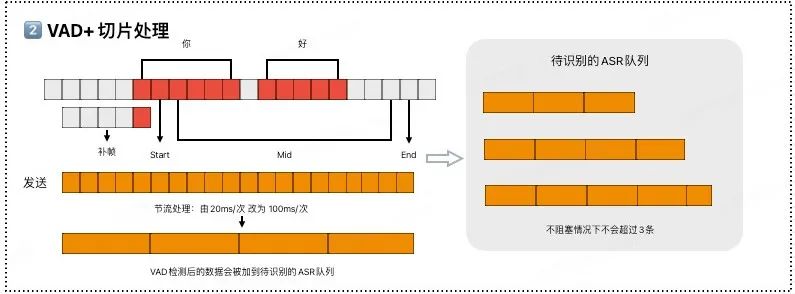
2、VAD+音频切片
涂鸦会对连续 PCM 音频流进行精准的 VAD 语音识别检测,并整合出有效的语音片段,智能区分哪里是人在说话、哪里是静音或背景噪音。然后按规则(如 100ms/段)进行切片,缓存发送到待识别的 ASR(语音转换为文本)队列。
3、ASR+翻译+TTS
收到语音片段后,系统会自动发送到云端完成 ASR 识别
如果用户开启了翻译功能,就会在完成语音转文字后,同步调用大模型进行语言翻译;
翻译后的文字,可通过 TTS,合成目标语言播放给用户听;
最终,所有识别或翻译结果,都会通过 AI 基座与业务层进行通信,并回调至面板小程序中。
-
音频
+关注
关注
31文章
3254浏览量
86587 -
AI
+关注
关注
91文章
42235浏览量
303262 -
涂鸦智能
+关注
关注
7文章
330浏览量
20794
发布评论请先 登录
接口芯片:数据洪流中的“万能翻译官”
TUYA全球开发者大会|从AI植物机器人到狗语翻译,创新AI硬件扎堆首发!

ETHERNET IP转MODBUS RTU:让罗克韦尔对台达“开口说话”的巴掌翻译官

炬芯科技正式发布基于端侧AI音频芯片ATS3231系列的新一代无线游戏耳机方案
烟丝喂送的‘翻译官’:EtherCAT与DeviceNet汇川伺服的无缝对话”

"网关”成顶流!PROFINET转CC-LINK,汽车产线的“翻译官”出圈记

智能“翻译官”:MODBUS转PROFIBUS网关,解锁搅拌站无人装载新纪元

逆变器是什么?广州邮科如何用“电力翻译官”守护通信命脉

声智科技AI翻译耳机重塑智能听觉体验
让太阳能逆变器“狂飙”的秘诀-耐达讯CAN转EtherCAT网关
水表界的“翻译官”:让CCLinkIE和Modbus TCP“无障碍聊天”!
CAN收发器:总线信号的“翻译官”




评论