 自然语言推理数据集“人工痕迹”严重,模型性能被高估
自然语言推理数据集“人工痕迹”严重,模型性能被高估

编者按:自然语言推理所用的数据集再近年得到了研究和发展,但是在本文中,来自华盛顿大学、卡内基梅隆大学和纽约大学等机构的研究人员发现,这些数据集中不可避免出现了明显的“人工痕迹”,使得模型的表现被高估了,评估自然语言推理模型的问题仍然存在。以下是论智的编译。
自然语言推理是NLP领域被广泛研究的领域之一,有了这一技术,许多复杂的语义任务如问题回答和文本总结都能得到解决。而用于自然语言推理的大规模数据集是通过向众包工作者提供一个句子(前提)p,然后让他们创作出三个新的与之相关的句子(假设)h创造出来的。自然语言推理的目的就是判断是否能根据p的语义推断出h。我们证明,利用这种方法,使得数据中的很大一部分只需查看新生成的句子,无需看“前提”,就能了解到数据的标签。具体来说,一个简单的文本分类模型在SNLI数据集上对句子分类的正确率达到了67%,在MultiNLI上的正确率为53%。分析表明,特定的语言现象,比如否定和模糊与某些推理类别非常相关。所以这一研究表示,目前的自然语言推理模型的成功被高估了,这一问题仍然难以解决。
2015年,Bowman等人通过众包标记的方法创造了大规模推断数据集SNLI;2018年,Williams等人又推出了MultiNLI数据集。在这一过程中,研究人员从一些语料中抽取某个前提句子p,让众包标注者基于p创作三个新句子,创作的句子与p有三种关系标准:
包含(Entailment):h与p非常相关;
中立(Neutral):h与p可能相关;
下面是SNLI数据集中具体的例子:

在这篇论文中,我们发现,通过众包生成的句子人工痕迹太过明显,以至于分类器无需查看条件句子p就能将其正确分类。下面我们将详细讲解分析过程。
注释中的“人工痕迹”其实很明显
我们猜想,注释任务的框架对众包人员编写句子时会产生显著的影响,这一影响会反映在数据中,我们称之为“人工注释(annotation artifacts)”。
为了确定这种人为行为对数据的影响程度,我们训练一个模型来预测生成句子的标签,无需查看前提句子。具体来说,我们使用现成的文本分类器fastText,它可以将文本模型化为许多单词和二元语法(bigrams),以预测句子的标签。
下表显示,每个测试集中大部分数据都能在不看前提句子的情况下被正确分类,这也证明了即使不用对自然语言推理建模,分类器也能表现得很好。

人工注释的特点
之前我们说到,超过一半的MultiNLI数据和三分之二的SNLI数据都有明显的人工痕迹,为了从中总结出它们的特点,我们将对数据进行大致分析,重点关注词汇的选择和句子的长度。
词汇选择
为了了解特定词汇的选择是否会影响句子的分类,我们计算了训练集中每个单词和类别之间的点互信息(PMI):
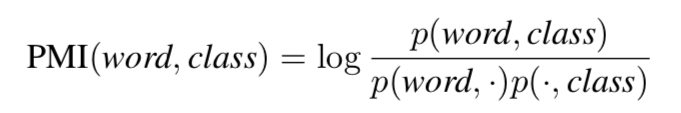
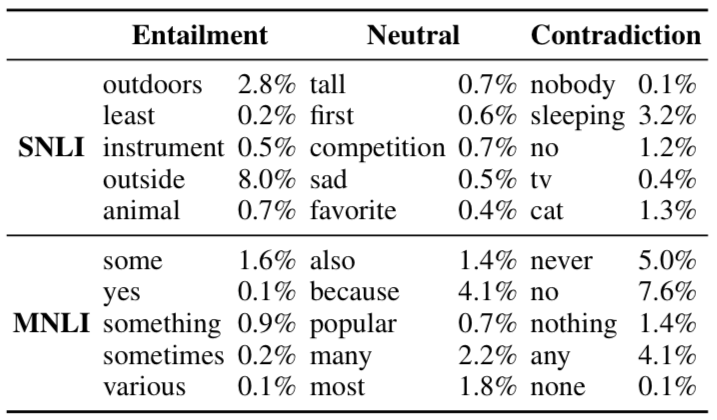
下表显示了每个分类中与类别最相关的几个单词,以及训练语句中包含这些单词的比例。
相关句子(Entailment)
与前提句子完全相关的生成句子都含有通用词汇,如动物、乐器和户外等,这些词语还有可能衍生出更具体的词语例如小狗、吉他、沙滩等等。另外,这些据此都会用确切的数字代替近似值(一些、至少、各种等等),并且会移除明确的性别。有些还会带有具体的环境,例如室内或室外,这些都是SNLI数据集中图片的个性特征。
中立句子
中立关系的句子中,最常见的就是修饰词(高、悲伤、受欢迎)和最高级词语(第一、最爱、最多)。除此之外,中立句子比较常见的是原因和目的从句,例如因为。
不相关句子
否定词例如“没有人”、“不”、“从不”、“没有”等都是不相关句子的常见词语。
句子长度
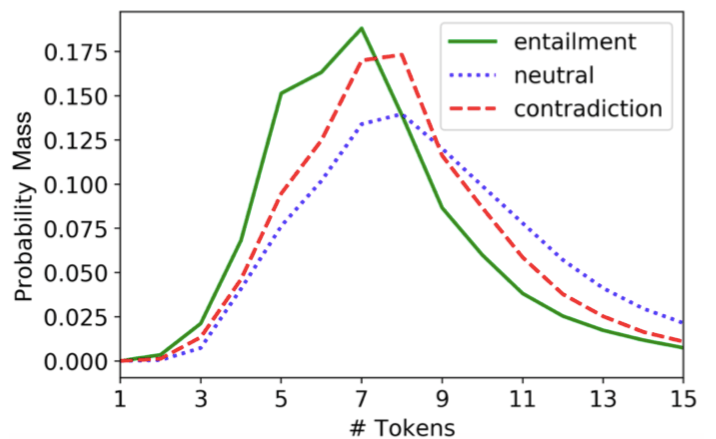
我们发现,生成句子中tokens的数量在不同的推理类别中并不是平均分配的。下图显示,中性的句子中token往往较长,而相关句子往往较短。句子长度的差异可能表明,众包工作者在生成相关句子时只是简单地从前提句子p中删除了几个单词。而事实上,当每个句子都用bag of words表示时,SNLI中有8.8%的相关生成句子完全包含在前提句子之中,而只有0.2%的中性和矛盾句子包含前提。
结论
通过观察结果,并对比其他人工注释分析,我们得到了三个主要结论。
很多数据集都包含有“人工痕迹”
监督模型需要利用人工注释。Levy等人证明了监督词汇推理模型在很大程度上以来数据集中人工生成的词汇。
人工注释会高估模型性能。大多数测试集都能单独依靠人工注释解决问题,所以我们鼓励开发额外的标准,能够给让人了解NLI模型的真实性能。
-
自然语言
+关注
关注
1文章
293浏览量
14061
原文标题:自然语言推理数据集“人工痕迹”严重,模型性能被高估
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
PyTorch教程-16.7。自然语言推理:微调 BERT

【大语言模型:原理与工程实践】揭开大语言模型的面纱
python自然语言

一种注意力增强的自然语言推理模型aESIM


PyTorch教程-16.4。自然语言推理和数据集
PyTorch教程-16.5。自然语言推理:使用注意力




评论