 一文速览:人工智能(AI)算法与GPU运行原理详解
一文速览:人工智能(AI)算法与GPU运行原理详解

本文介绍人工智能的发展历程、CPU与GPU在AI中的应用、CUDA架构及并行计算优化,以及未来趋势。
一、人工智能发展历程
当今,人工智能(Artificial Intelligence)已经深刻改变了人类生活的方方面面,并且在未来仍然会继续发挥越来越重要的影响力。
“人工智能”这一概念在1956年于美国达特茅斯学院举办的一次学术集会上被首次提出,自此开启了人工智能研究的新纪元。自此之后,人工智能在曲折中不断发展前进。
1986年,神经网络之父Geoffrey Hinton提出了适用于多层感知机(Multilayer Perceptron,MLP)的反向传播(Back propagation,BP)算法,并且使用Sigmoid函数实现非线性映射,有效解决了非线性分类和学习问题。
1989年,YannLeCun设计了第一个卷积神经网络,并将其成功应用于手写邮政编码识别任务中。
20世纪90年代,Cortes等人提出支持向量机(SupportVector Machine, SVM)模型,随后SVM迅速发展成为机器学习的代表性技术之一,在文本分类、手写数字识别、人脸检测和生物信息处理等方面取得了巨大成功。
进入21世纪,随着互联网技术的发展与计算机硬件系统性能的提高,人工智能迎来了新的重大发展机遇。特别是2011年以来,以深度神经网络为代表的深度学习技术高速发展,人类在通向人工智能的道路上接连实现了许多重大突破。
二、CPU和GPU在人工智能中的应用
GPU最初是用于图像处理的,但由于高性能计算需求的出现,GPU因其高度 并行的硬件结构而得以显著提升其并行计算和浮点计算能力,且性能远超于CPU。
由于训练深度神经网络的计算强度非常大,因而在CPU上训练神经网络模型的时间往往非常长。
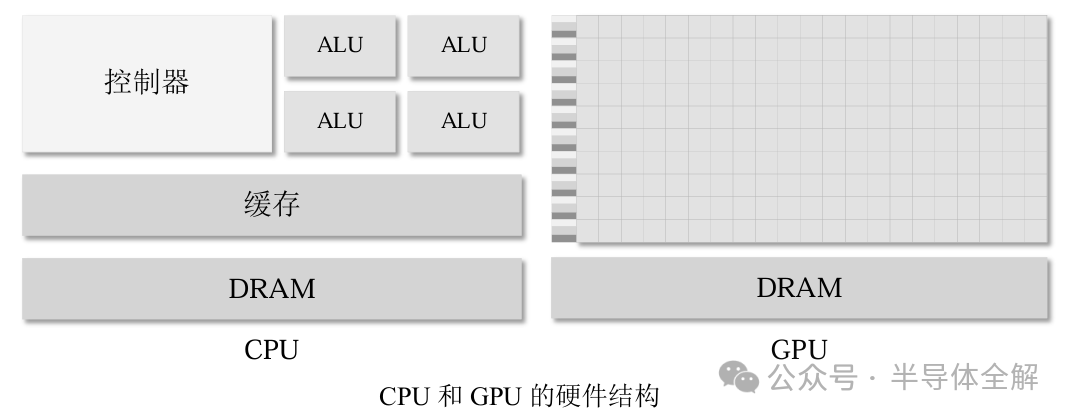
如图所示,CPU主要由控制器、算数逻辑单元(Arithmetic and Logic Unit,ALU)和储存单元三个主要部分组成,CPU的计算能力主要取决于计算核心ALU的数量,而ALU又大又重,使得CPU常用来处理具有复杂控制逻辑的串行程序以提高性能。
相比之下,GPU由许多SP(Streaming Processor,流处理器)和存储系统组成,SP又被称为CUDA核心,类似CPU中的ALU,若干个SP被组织成一个SM(Streaming Multiprocessors,流多处理器)。
GPU中的SP数量众多且体积较小,这赋予了GPU强大的并行计算和浮点运算能力,常用来优化那些控制逻辑简单而数据并行性高的任务,且侧重于提高并行程序的吞吐量。
图形处理器(GraphicsProcessing Unit, GPU)具有强大的单机并行处理能力,特别适合计算密集型任务,已经广泛应用于深度学习训练。
然而单个GPU的算力和存储仍然是有限的,特别是对于现在的很多复杂深度学习训练任务来说,训练的数据集十分庞大,使用单个GPU训练深度神经网络(DeepNeural Network ,DNN)模型需要漫长的训练时间。
例如,使用一块Nvidia M40 GPU在ImageNet-1K上训练ResNet-50 90个epoch需要14天时间。此外,近年来深度神经网络的模型参数规模急剧增加,出现了很多参数量惊人的“巨模型”。
由于在训练这些大规模DNN模型时,无法将全部模型参数和激活值放入单个GPU中,因此无法在单GPU上训练这些超大规模DNN模型。
随着计算机体系结构的飞速发展,并行(Parallelism)已经在现代的计算机体系结构中广泛存在,目前的计算机系统普遍具有多核或多机并行处理能力。
按照存储方式的不同,并行计算机体系结构通常分为两种:共享存储体系结构和分布存储体系结构。
对于共享存储体系结构,处理器通常包含多个计算核,通常可以支持多线程并行。然而由于存储和算力的限制,使用单个计算设备上往往无法高效训练机器学习模型。多核集群系统是目前广泛使用的多机并行计算平台,已经在机器学习领域得到广泛应用。
多核集群系统通常以多核服务器为基本计算节点,节点间则通过Infiniband高速互联网络互联。此外,在深度学习训练领域,单机多卡(One Machine Multiple GPUs)和多机多卡(Multiple Machines Multiple GPUs)计算平台也已经发展成为并行训练神经网络的主流计算平台。
消息传递接口(MessagePassing Interface, MPI)在分布式存储系统上是被广泛认可的理想程序设计模型,也为机器学习模型的并行与分布式训练提供了通信技术支撑。机器学习模型并行训练的本质是利用多个计算设备协同并行训练机器学习模型。
机器学习模型的并行训练过程一般是,首先将训练数据或模型部署到多个计算设备上,然后通过这些计算设备协同并行工作来加速训练模型。
机器学习模型的并行训练通常适用于以下两种情况:
(1)当模型可以载入到单个计算设备时,训练数据非常多,使用单个计算设备无法在可接受的时间内完成模型训练;
(2)模型参数规模非常大,无法将整个模型载入到单个计算设备上;机器学习模型并行训练的目的往往是为了加速模型训练,机器学习模型训练的总时间往往是由单次迭代或者单个epoch的计算时间与收敛速度共同作用的结果。训练模型使用的优化算法决定了收敛速度,而使用合适的并行训练模式则可以加快单次迭代或者单个epoch的计算。在并行训练机器学习模型时,首先要把数据分发到多个不同的计算设备上。
按照数据分发方式的不同,模型的并行训练模式一般可以分为数据并行、模型并行和流水线并行。
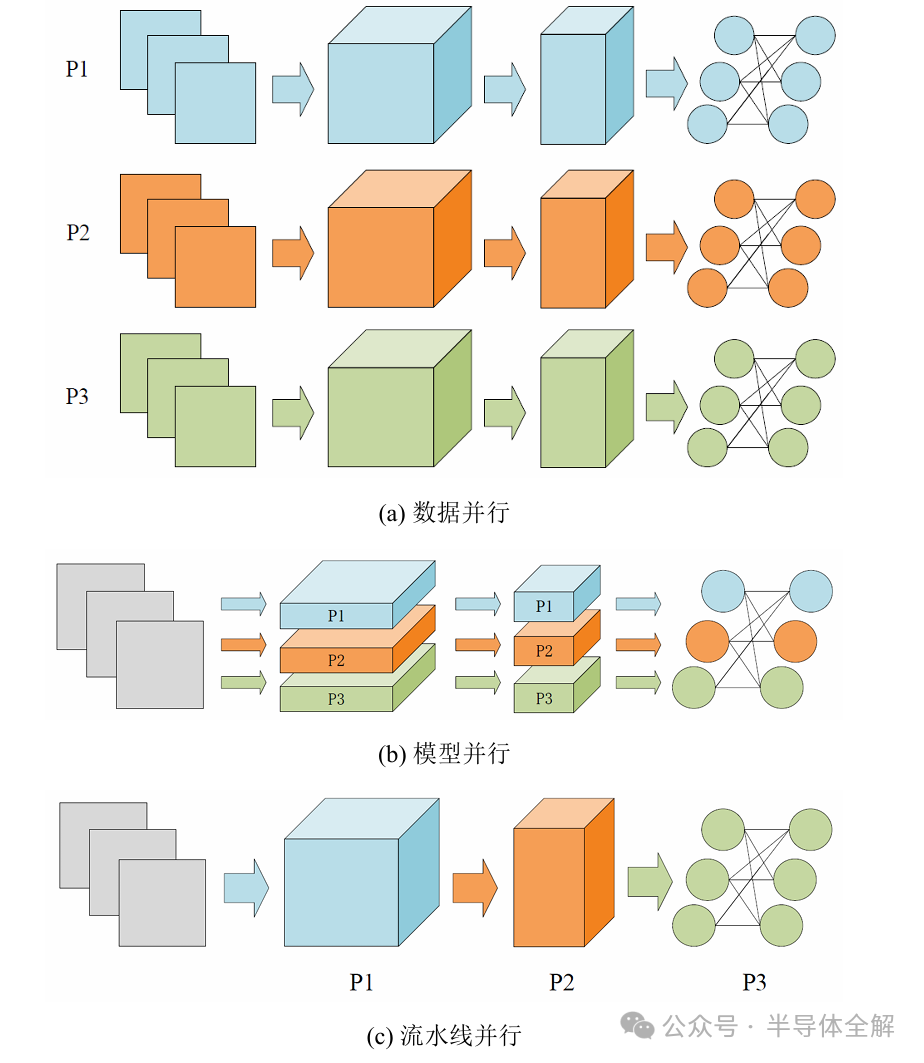
上图是三种并行训练模式的示意图。
数据并行(DataParallelism)是当前最流行的DNN并行训练方法。
当前流行的许多深度学习框架如Tensor Flow, PyTorch和Horovod等都提供了方便使用的API来支持数据并行。
如图(a)所示,在数据并行中,每个计算设备都拥有全部的并且完全一致的模型参数,然后被分配到不同的批处理训练数据。当所有计算设备上的梯度通过参数服务器或者Allreduce这样的集合通信操作来实现求和之后,模型参数才会更新。
深度神经网络通常是由很多层神经元连续堆叠而成,每一层神经元形成了全连接层(Fully Connected Layers)、卷积层(Convolutional Layers)等不同类型的运算子(Operator)。
传统的模型并行(ModelParallelism)是将神经网络模型水平切分成不同的部分,然后分发到不同的计算设备上。
如图(b)所示,模型并行是将不同运算子的数据流图(Data flow Graph)切分并存储在多个计算设备上,同时保证这些运算子作用于同一个批处理训练数据。由于这种切分是将运算子从水平层次进行切分,因此通常模型并行也称为运算子并行(Operator Parallelism)或水平并行(Horizontal Parallelism)。
当把神经网络模型按层进行垂直切分时,模型并行可进一步归类为流水线并行(Pipeline Parallelism)。如图(c)所示,流水线并行是将神经网络按层切分成多个段(Stage),每个Stage由多个连续的神经网络层组成。然后所有Stage被分配到不同的计算设备上,这些计算设备以流水线方式并行地训练。神经网络的前向传播从第一个计算设备开始,向后做前向传播,直到最后一个计算设备完成前向传播。随后,神经网络的反向传播过程从最后一个计算设备开始,向前做反向传播,直到第一个计算设备完成反向传播。
在算法加速方面,目前加速算法的研究主要是利用不同平台的计算能力完成。主流的加速平台包括专用集成电路(Application Specific Integrated Circuit, ASIC)、现场可编程逻辑门阵列(Field-Programmable Gate Array, FPGA)芯片和图形处理器(Graphics Processing Unit, GPU)等。
其中,ASIC芯片定制化程度较高,设计开发周期长,难以应对迅速变化的市场需求;FPGA芯片是一种可编程的集成电路芯片,自由度相对较高,投入使用比ASIC快,成本与ASIC相比较低,但是由于FPGA芯片仍属于硬件并行设计的范畴,通用性和成本与GPU相比欠佳。
三、什么是CUDA?
CUDA(ComputeUnified Device Architecture)全称统一计算架构,作为NIVIDA公司官方提出的GPU编程模型,它提供了相关接口让开发者可以使用GPU完成通用计算的加速设计,能够更加简单便捷地构建基于GPU的应用程序,充分发挥GPU的高效计算能力和并行能力。
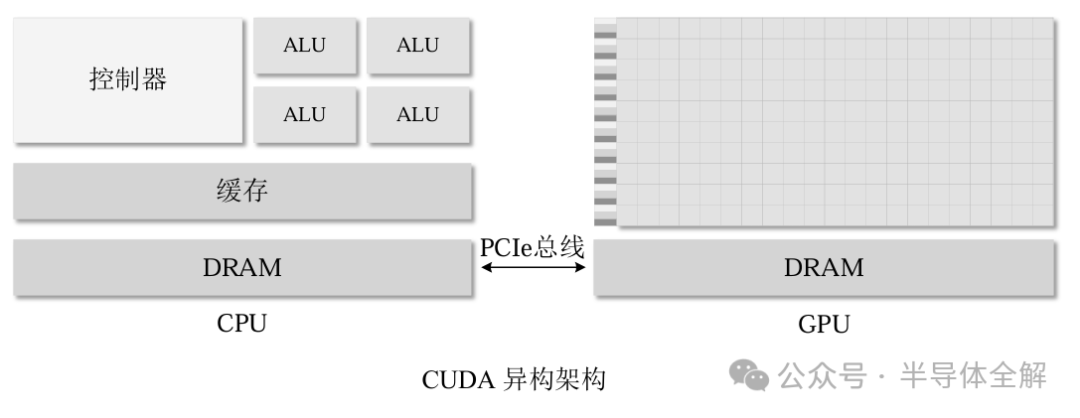
CUDA同时支持C/C++,Python等多种编程语言,使得并行算法具有更高的可行性。由于GPU不是可以独立运行的计算平台,因此在使用CUDA编程时需要与CPU协同实现,形成一种CPU+GPU的异构计算架构,其中CPU被称为主机端(Host),GPU被称为设备端(Device)。
GPU主要负责计算功能,通过并行架构与强大的运算能力对CPU指派的计算任务进行加速。通过 CPU/GPU 异构架构和CUDA C语言,可以充分利用GPU资源来加速一些算法。
典型的GPU体系结构如下图所示,GPU和CPU的主存都是采用DRAM实现,存储结构也十分类似。但是CUDA将GPU内存更好地呈现给程序员,提高了GPU编程的灵活性。

CUDA程序实现并行优化程序设计的具体流程主要分为三个步骤:
1、将数据存入主机端内存并进行初始化,申请设备端内存空间并将主机端的数据装载到设备端内存中;
2、调用核函数在设备端执行并行算法,核函数是指在GPU中运行的程序,也被称为kernel函数。
3、将算法的最终运行结果从设备端内存卸载到主机端,最后释放设备端和主机端的所有内存。
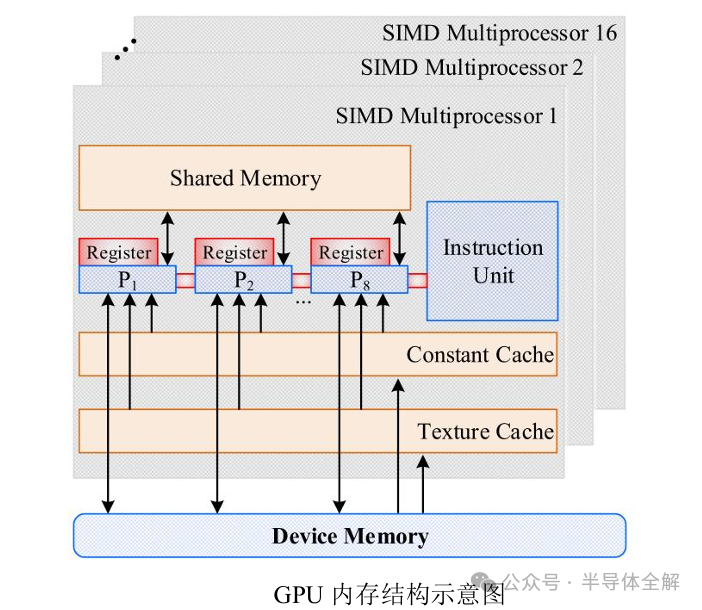
GPU的核心组件是流式多处理器(Streaming Multiprocessor,简称SM),也被称为GPU大核,一个GPU设备含有多个SM硬件,SM的组件包括CUDA核心,共享内存和寄存器等。
其中,CUDA核心(CUDA core)是GPU最基本的处理单元,具体的指令和任务都是在这个核心上处理的,本质上GPU在执行并行程序的时候,是在使用多个SM同时处理不同的线程。而共享内存和寄存器是SM内部最重要的资源,在很大程度上GPU的并行能力就取决于SM中的资源分配能力。
在CUDA架构中,网格(Grid),块(Block)和线程(Thread)是三个十分重要的软件概念,其中线程负责执行具体指令的运行任务,线程块由多个线程组成,网格由多个线程块组成,线程和线程块的数量都可以通过程序的具体实现设定。
GPU在执行核函数时会以一个网格作为执行整体,将其划分成多个线程块,再将线程块分配给SM执行计算任务。
GPU内存结构如下图所示,主要包括位于SP内部的寄存器(Register)、位于SM上的共享内存(Shared memory)和GPU板载的全局内存(Global memory)。
在NVIDIA提出的CUDA统一编程模型中采用Grid的方式管理GPU上的全部线程,每个Grid中又包含多个线程块(Block),每个Block中又可以划分成若干个线程组(Warp)。Warp是GPU线程管理的最小单位,Warp内的线程采用单指令多线程(Single Instruction MultipleThreads, SIMT)的执行模式。
CUDA线程管理的基本结构如下图所示:
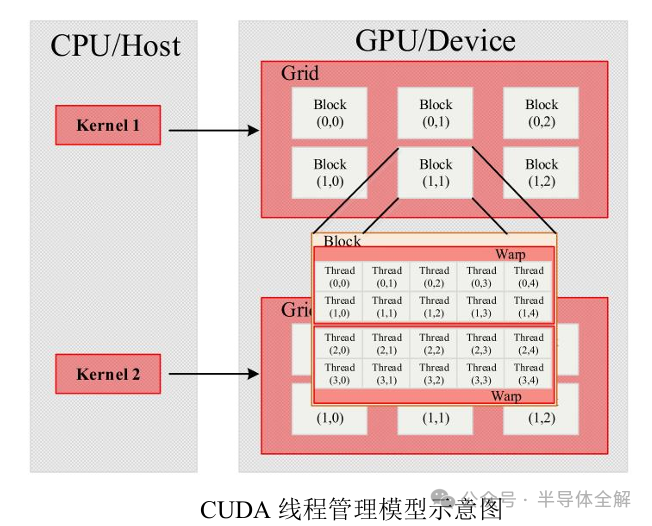
GPU独特的体系架构和强大的并行编程模型,使得GPU在并行计算和内存访问带宽方面具有独特的性能优势。
相对于传统的CPU体系结构,GPU具有一些独特的优势:
1)并行度高、计算能力强。相对于CPU体系结构,GPU内部集成了更多的并行计算单元,使得GPU在并行计算能力方面的表现更加出色。同时,其理论计算峰值也远高于同时期CPU,当前NVIDIA A100 GPU在执行Bert推理任务,其推理速度可达2个Intel至强金牌6240CPU的249倍6。
2)访存带宽高。为了匹配GPU超强的并行能力,GPU内部设置了大量访存控制器和性能更强的内部互联网络,导致GPU具有更高的内存访问带宽。当前NVIDIAA100 GPU的内存带宽可达1.94TB/s,而同期Intel至强金牌6248 CPU仅为137GB/s。图处理由于其计算访存比高,算法执行过程中计算次数多、单次计算量小的特点天然地与GPU的硬件特征相匹配。
四、总结
随着深度学习(DeepLearning,DL)的持续进步,各类深度神经网络(DeepNeural Network ,DNN)模型层出不穷。DNN不仅在精确度上大幅超越传统模型,其良好的泛化性也为众多领域带来了新的突破。
因此,人工智能(Artificial Intelligence, AI)技术得以迅速应用于各个行业。如今,无论是在物联网(Intemet of Things, IoT)的边缘设备,还是数据中心的高性能服务器,DNN的身影随处可见,人工智能的发展离不开计算能力的提升,因此高性能GPU的需求也将不断提升!
参考文献:
(1)杨翔 深度学习模型的并行推理加速技术研究[D]。
(2)郑志高 GPU上图处理算法优化关键技术研究[D]。
(3)关磊 机器学习模型并行训练关键技术研究[D]。
(4)薛圣珑 机载预警雷达杂波快速生成及GPU实现研究[D]。
(5)韩吉昌 基于CUDA的国密算法SM3和SM4的设计与实现[D].
-
gpu
+关注
关注
28文章
5339浏览量
136281 -
AI
+关注
关注
91文章
42231浏览量
303251 -
人工智能
+关注
关注
1821文章
50551浏览量
267973
原文标题:一文了解人工智能(AI)算法及GPU运行原理
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
全域复杂环境飞行适应性AI评估系统融合大模型人工智能技术
嵌入式人工智能课程(华清远见)
【重磅喜讯】镭神智能斩获吴文俊人工智能科技进步奖一等奖!






评论