 解析DeepSeek MoE并行计算优化策略
解析DeepSeek MoE并行计算优化策略

本期Kiwi Talks将从集群Scale Up互联的需求出发,解析DeepSeek在张量并行及MoE专家并行方面采用的优化策略。DeepSeek大模型的工程优化以及国产AI 产业链的开源与快速部署预示着国产AI网络自主自控将大有可为。
DeepSeekMoE架构融合了专家混合系统(MoE)、多头注意力机制(Multi-Head Latent Attention, MLA)和RMSNorm三个核心组件。通过专家共享机制、动态路由算法等缓存技术,该模型在保持性能水平的同时,实现了相较传统MoE模型40%的计算开销降低。该技术在模型规模与计算效率之间找到了新的平衡点,其在降低计算成本的同时保持了领先的性能水平,为大规模AI系统的可持续发展提供了新的思路。
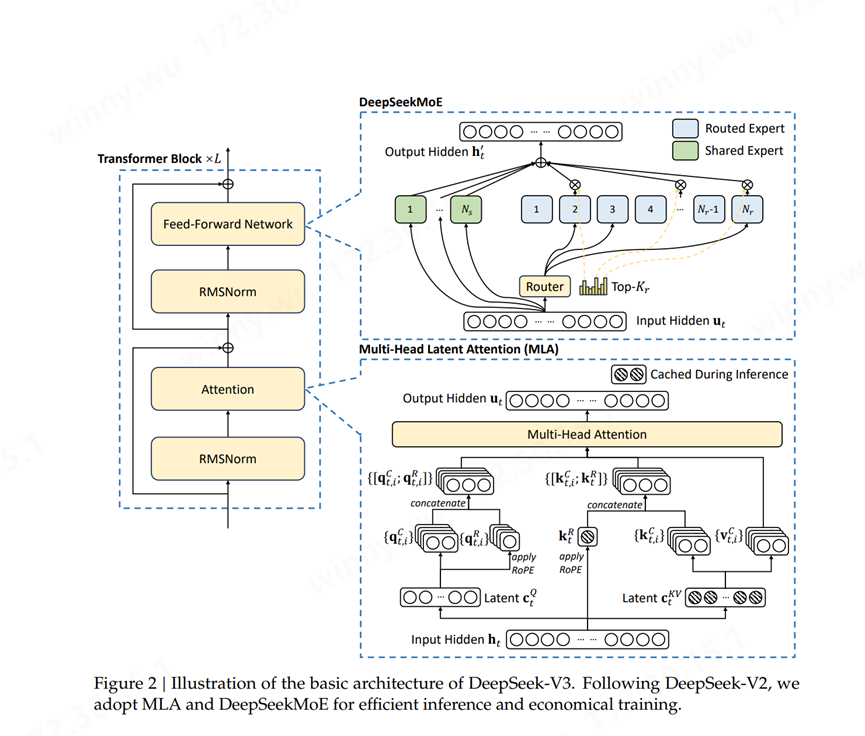
(来源:DeepSeek-V3 Technical Report) Scale Up互联源头:张量并行与专家并行
Scale Up互联需求源头:张量并行与专家并行
在大规模 AI 训练中,GPU 通常使用各种并行技术协同工作。其中张量并行是指将大型张量分散到多个 GPU 上进行计算,这种技术对互联带宽和时延特别敏感。
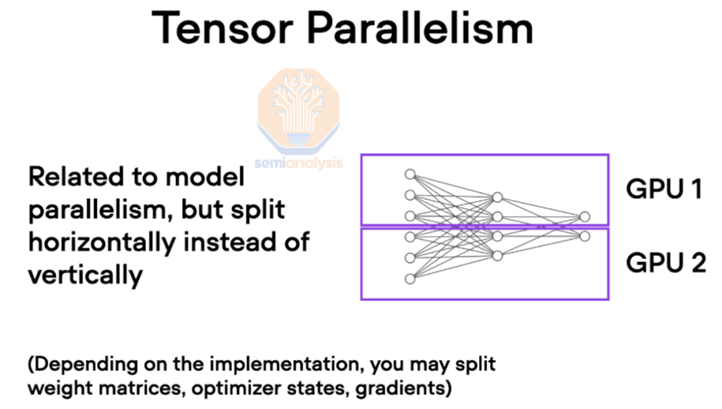
(来源:Semi analysis) 简单来说,张量是人工智能模型中用来表示输入、权重和中间计算的基本数据结构。在训练大型 AI 模型时,这些张量可能会变得非常庞大,以至于无法放入单个 GPU 的内存中。为了解决这个问题,张量被拆分到多个 GPU 上,每个 GPU 处理一部分张量。这种划分允许模型跨多个 GPU 扩展,从而能够训练比原本更大的模型。然而,分割张量需要 GPU 之间频繁通信以同步计算并共享结果。这时互联速度就变得至关重要。
(来源:Deepgram.com)
另一方面,MoE模型本身适合大规模、复杂任务、计算效率要求高且训练复杂程度高。DeepSeek MoE多模态模型涉及专家并行,它将复杂的模型分解为多个专家模型,并在这些专家模型之间进行并行计算。在专家并行中,不同GPU负责不同的专家模型,同时Attention模块在每个GPU上复制,由于每个专家模型需要单独加载数据,因此对每个token施加了额外的内存带宽需求。此外专家并行需要网络支持高并发、有效的负载均衡机制以及故障容错性等一系列复杂需求。
因此在Scale-up网络中,张量并行和专家并行的策略对于大模型训推的效率至关重要,也是AI网络互联网络带宽(TB级)和极低时延需求的源头。
H800 中 NVLink 带宽的降低会减慢此阶段 GPU 之间的通信速度,从而导致延迟增加并降低整体训练效率。在涉及具有数十亿个参数的大型模型的场景中,这种瓶颈变得更加明显,因为 GPU 之间需要频繁通信来同步张量并行和专家并行。
在并行策略上,DeepSeek-V3使用64路的专家并行,16路的流水线并行,以及数据并行(ZeRO1)。其中,专家并行会引入all-to-all通信,由于每个token会激活8个专家,这导致跨节点的all-to-all通信开销成为主要的系统瓶颈。
那么DeepSeek是如何通过算法工程优化来解决这些瓶颈并提升大模型训推效率?
DeepSeek V3集群互联框架概述
从DeepSeek公开的论文中数据来看: Scale Inside单个芯片使用英伟达H800,共计2048张计算卡。集群组网使用Infiniband网络,Scale Up每个节点内通过NVLink互联。GPU之间的带宽是160GB,节点之间的带宽是50GB。Scale Out网络据推测,每个节点包含8个400Gb/s的智能网卡(H100/H800 上后向网络通常都会采用 400 Gb/s网卡)。
路由优化策略降低TP开销
在其公布的V3技术论文中所提及网络集群中路由的优化策略:跨节点 GPU 与 IB 完全互连,节点内通信通过 NVLink 处理。NVLink 提供 160 GB/s 带宽,大约是 IB(50 GB/s)的 3.2倍。为了有效利用IB和NVlink的带宽差异,DeepSeek限制每个token最多分派到4个GPU节点,从而限制IB网络的传输流量。当网络路由决策确定后,它将首先通过IB传输到目标节点上具有相同节点内索引的GPU。一旦到达目标节点,努力确保它通过NVLink瞬时转发到托管其目标专家的特定GPU,而不被随后到达的token阻塞。这样,通过IB和NVLink的通信完全重叠,每个token可以高效地在每个节点上选择平均3.2个专家,而不会产生来自NVLink的额外开销。这意味着,尽管DeepSeek-V3在实际中只选择8个路由专家,但它可以将其数量扩大到最多13个专家(4个节点×每个节点3.2个专家),同时保持相同的通信成本。
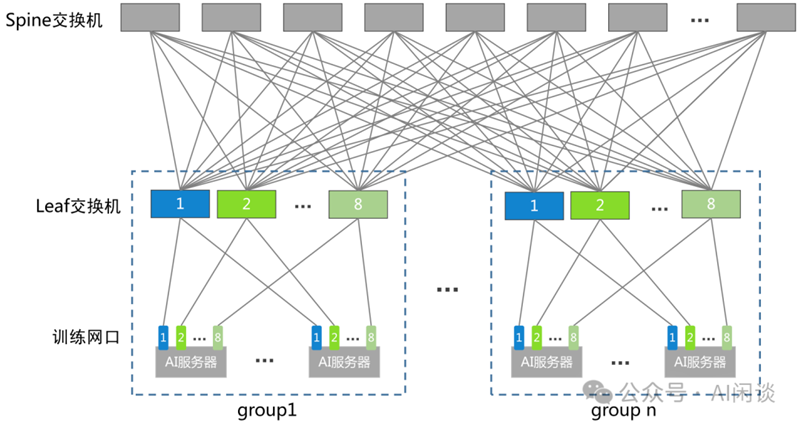
(来源:公众号AI闲谈)
这样做是因为高性能 GPU 训练集群往往会采用轨道优化,同号 GPU 在一个 Leaf Switch 下,如上图所示,因此可以利用高速的 NVLink 来代替从 Leaf Switch 到 Spine Switch 的流量,从而降低 IB 通信时延,并且减少 Leaf Switch 和 Spine Switch 之间的流量。总体而言,在这种通信策略下,仅20个SM就足以充分利用IB和NVLink的带宽,这种路由的优化策略达到了减少张量并行通信开销的目的。
FP8与冗余专家技术减少MoE内存与通信开销
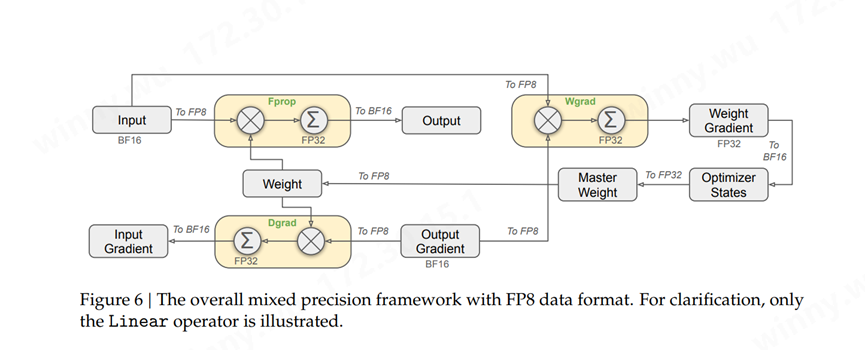
(来源:DeepSeek-V3 Technical Report)
为了进一步减少MoE训练中的内存和通信开销,DeepSeek在FP8中缓存和分发激活值,同时以BF16存储低精度优化器状态。在两个与DeepSeek-V2-Lite和DeepSeek-V2相似规模的模型上验证了提出的FP8混合精度框架,训练了大约1万亿个Token。这一设计理论上使计算速度较原 BF16 方法提升一倍。此外,FP8 Wgrad GEMM 允许激活值以 FP8 存储,供 Backward 使用,从而显著降低内存消耗。
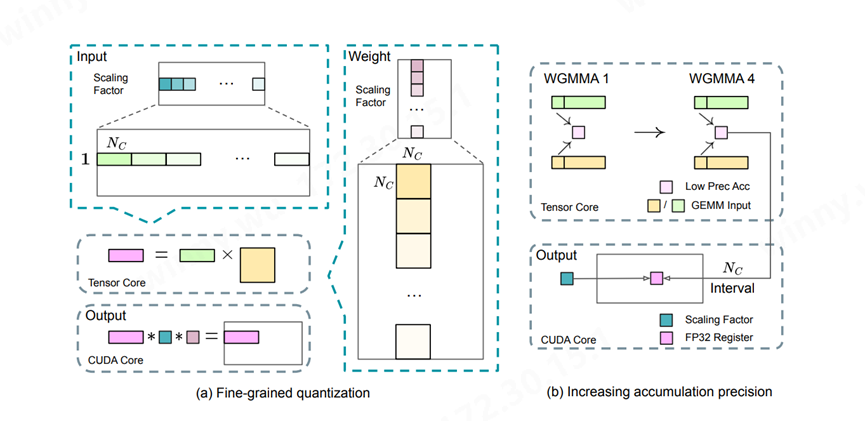
(来源:DeepSeek-V3 Technical Report)
为了在MoE部分的不同专家间实现负载均衡,需要确保每个GPU处理大概相同数量的Token。DeepSeek MoE引入了冗余专家部署策略,对高负载专家并行进行复制并冗余部署。根据在线服务中的专家负载统计信息,在一定间隔内定期确定冗余专家集,通过探索解码阶段的动态冗余策略优化各GPU负载,减少all-to-all通信开销。在实际处理大规模文本生成任务时,DeepSeek MoE可以通过动态分配专家资源,实现高效的文本生成,而不需要像传统模型那样进行大规模的全模型计算。
DeepSeek MLA KV Cache压缩优化
Multi-Head Latent Attention (MLA) 是 DeepSeek-V3 模型中用于高效推理的核心注意力机制。MLA 通过低秩联合压缩技术,减少了推理时的键值(KV)缓存,从而在保持性能的同时显著降低了内存占用。这类创新技术一方面减少了KV缓存的需求,加快了数据访问速度,从而全面提升了模型的推理速度。
KV缓存技术注解:
大语言模型通常是通常自回归的方式产生输出序列,后序生成的词块依赖与前序的所有词块,这些词块包括输入的词块以及前面已经生成的词块。因此随着输出序列的增长,推理过程的开销显著增大。为了解决上述问题,KV Cache的技术被提出,该技术通过存储和复用前序Token产生的Key值和Value值,极大减少了计算上的冗余,用存储开销换取显著的加速效果,但同时增加的存储开销和带宽需求也对AI Data Center的设计提出了挑战。
国产AI网络自主自控未来可期
DeepSeek 模型的成功预示着AI大模型系统验证了新的Scaling Law,AI能力边界将引来新一轮的扩张。在全球地缘政治日趋复杂的背景下,构建国产算力闭环系统已成为当务之急。然而,算力芯片始终是大模型系统算力的坚实基石。 DeepSeek凭借其开源和低成本的优势,将显著提升国产GPU在推理任务中的性价比和ROI。近期,众多GPU厂商和云服务提供商纷纷宣布已完成与DeepSeek的适配部署,为国产AI产业的蓬勃发展注入了强劲动力。
目前,Scale Up网络受限于PCIe总线的速率,仅支持传统的八卡GPU互联。而基于私有协议的GPU超带宽域,由于缺乏成熟的生态产业链支持,难以实现大规模集群的高性能互联。DeepSeek模型的出现,预示着国产芯片将在其引领的AI大模型新纪元中迎来广泛机遇。
在这一背景下,作为助力国产GPU 实现自主自控的参与者,奇异摩尔自研的网络加速芯粒GPU Link Chiplet——NDSA-G2G,以其极高的灵活性和可扩展性为Scale-up互联生态提供了强有力的支撑。NDSA -G2G以IO Chiplet芯粒形式集成在GPU加速卡内,并利用UCIe D2D接口与GPU互联,NDSA-G2G能够实现高性能的数据流,从而全面加速分布式计算网络,最终实现TB级别的GPU互联。
奇异摩尔作为国产AI网络生态链的一份子,将持续与大模型厂商、运营商/云厂商及国产GPU厂商共同探索AI系统的优化潜力,持续推动生态适配工作,为国产AI早日实现算力闭环、迈向自主自控新纪元贡献坚实力量。
关于我们
AI网络全栈式互联架构产品及解决方案提供商
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA 和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale out网络的AI原生智能网卡、面向南向Scale up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
奇异摩尔的核心团队汇聚了来自全球半导体行业巨头如NXP、Intel、Broadcom等公司的精英,他们凭借丰富的AI互联产品研发和管理经验,致力于推动技术创新和业务发展。团队拥有超过50个高性能网络及Chiplet量产项目的经验,为公司的产品和服务提供了强有力的技术保障。我们的使命是支持一个更具创造力的芯世界,愿景是让计算变得简单。奇异摩尔以创新为驱动力,技术探索新场景,生态构建新的半导体格局,为高性能AI计算奠定稳固的基石。
-
并行计算
+关注
关注
0文章
30浏览量
9761 -
大模型
+关注
关注
2文章
3805浏览量
5280 -
DeepSeek
+关注
关注
2文章
857浏览量
3417
原文标题:Kiwi Talks | 解析DeepSeek MoE并行计算优化策略 国产AI网络自主自控大有可为
文章出处:【微信号:奇异摩尔,微信公众号:奇异摩尔】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
arm系统中并行计算优化
区域分解对气象模式并行计算速度的影响
THE MATHWORKS推出新版并行计算工具箱
并行计算和嵌入式系统实践教程
基于Matlab和GPU的BESO方法的全流程并行计算策略
基于异构并行计算的两个子概念异构和并行的简单分析
基于云计算的电磁问题并行计算方法
C编程的并行计算详细资料说明
CUDA的异构并行计算详细资料介绍



评论