 基于Arm Ethos-U85 NPU部署小语言模型
基于Arm Ethos-U85 NPU部署小语言模型

随着人工智能 (AI) 的演进,人们对使用小语言模型 (SLM) 在嵌入式设备上执行 AI 工作负载的兴趣愈发高涨。
以下的演示展现了端点 AI 在物联网和边缘计算领域的发展潜力。在此演示中,当用户输入一个句子后,系统将基于该句扩展生成一个儿童故事。这项演示受到了微软“Tiny Stories”论文和 Andrej Karpathy 的 TinyLlama2 项目的启发,TinyLlama2 项目使用了 2,100 万个故事来训练小语言模型生成文本。
该演示搭载了 Arm Ethos-U85 NPU,并在嵌入式硬件上运行小语言模型。尽管大语言模型 (LLM) 更加广为人知,但由于小语言模型能够以更少的资源和较低的成本提供出色的性能,而且训练起来也更为简易且成本更低,因此越来越受到关注。
在嵌入式硬件上实现
基于 Transformer 的小语言模型
我们的演示展示了 Ethos-U85 作为一个小型低功耗平台,具备运行生成式 AI 的能力,并凸显了小语言模型在特定领域中的出色表现。TinyLlama2 模型相较 Meta 等公司的大模型更为简化,很适合用于展示 Ethos-U85 的 AI 性能,可作为端点 AI 工作负载的理想之选。
为开发此演示,我们进行了大量建模工作,包括创建一个全整数的 INT8(和 INT8x16)TinyLlama2 模型,并将其转换为适合 Ethos-U85 限制的固定形状 TensorFlow Lite 格式。
我们的量化方法表明,全整数语言模型在取得高准确度和输出质量之间实现了良好平衡。通过量化激活、归一化函数和矩阵乘法,我们无需进行浮点运算。由于浮点运算在芯片面积和能耗方面成本较高,这对于资源受限的嵌入式设备来说是一个关键考量。
Ethos-U85 在 FPGA 平台上以 32 MHz 的频率运行语言模型,其文本生成速度可达到每秒 7.5 到 8 个词元 (token),与人类的阅读速度相当,同时仅消耗四分之一的计算资源。在实际应用的系统级芯片 (SoC) 上,该性能最多可提高十倍,从而显著提升了边缘侧 AI 的处理速度和能效。
儿童故事生成特性采用了 Llama2 的开源版本,并结合了 Ethos NPU 后端,在 TFLite Micro 上运行演示。大部分推理逻辑以 C++ 语言在应用层编写,并通过优化上下文窗口内容,提高了故事的连贯性,确保 AI 能够流畅地讲述故事。
由于硬件限制,团队需要对 Llama2 模型进行适配,以确保其在 Ethos-U85 NPU 上高效运行,这要求对性能和准确性进行仔细考量。INT8 和 INT16 混合量化技术展示了全整数模型的潜力,这有利于 AI 社区更积极地针对边缘侧设备优化生成式模型,并推动神经网络在如 Ethos-U85 等高能效平台上的广泛应用。
Arm Ethos-U85 彰显卓越性能
Ethos-U85 的乘法累加 (MAC) 单元可以从 128 个扩展至 2,048 个,与前一代产品 Ethos-U65 相比,其能效提高了 20%。另外相较上一代产品,Ethos-U85 的一个显著特点是能够原生支持 Transformer 网络。
Ethos-U85 支持使用前代 Ethos-U NPU 的合作伙伴能够实现无缝迁移,并充分利用其在基于 Arm 架构的机器学习 (ML) 工具上的既有投资。凭借其卓越能效和出色性能,Ethos-U85 正愈发受到开发者青睐。
如果在芯片上采用 2,048 个 MAC 配置,Ethos-U85 可以实现 4 TOPS 的性能。在演示中,我们使用了较小的配置,即在 FPGA 平台上采用 512 个 MAC,并以 32 MHz 的频率运行具有 1,500 万个参数的 TinyLlama2 小语言模型。
这一能力凸显了将 AI 直接嵌入设备的可能性。尽管内存有限(320 KB SRAM 用于缓存,32 MB 用于存储),Ethos-U85 仍能高效处理此类工作负载,为小语言模型和其他 AI 应用在深度嵌入式系统中的广泛应用奠定了基础。
将生成式 AI 引入嵌入式设备
开发者需要更加先进的工具来应对边缘侧 AI 的复杂性。Arm 通过推出 Ethos-U85,并支持基于 Transformer 的模型,致力于满足这一需求。随着边缘侧 AI 在嵌入式应用中的重要性日益增加,Ethos-U85 正在推动从语言模型到高级视觉任务等各种新用例的实现。
Ethos-U85 NPU 提供了创新前沿解决方案所需的卓越性能和出色能效。我们的演示显示了将生成式 AI 引入嵌入式设备的重要进展,并凸显了在 Arm 平台上部署小语言模型便捷可行。
Arm 正为边缘侧 AI 在广泛应用领域带来新机遇,Ethos-U85 也因此成为推动新一代智能、低功耗设备发展的关键动力。
-
ARM
+关注
关注
135文章
9619浏览量
394719 -
嵌入式
+关注
关注
5212文章
20802浏览量
339138 -
物联网
+关注
关注
2951文章
48306浏览量
420001 -
AI
+关注
关注
91文章
42239浏览量
303282
原文标题:Arm Ethos-U85 NPU:利用小语言模型在边缘侧实现生成式 AI
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RK3576 单板机 NPU 边缘 AI 开发手册

IMX8M Plus 板上部署立体视觉模型 CPU 回退错误 IMX8M Plus问题
【瑞萨AI挑战赛】手写数字识别模型在RA8P1 Titan Board上的部署
在AI基础设施中部署大语言模型的三大举措

1 GHz Arm® Cortex®-M85 MCU上部署AI模型


如何利用NPU与模型压缩技术优化边缘AI
瑞萨电子RA8P1系列32位AI MCU介绍

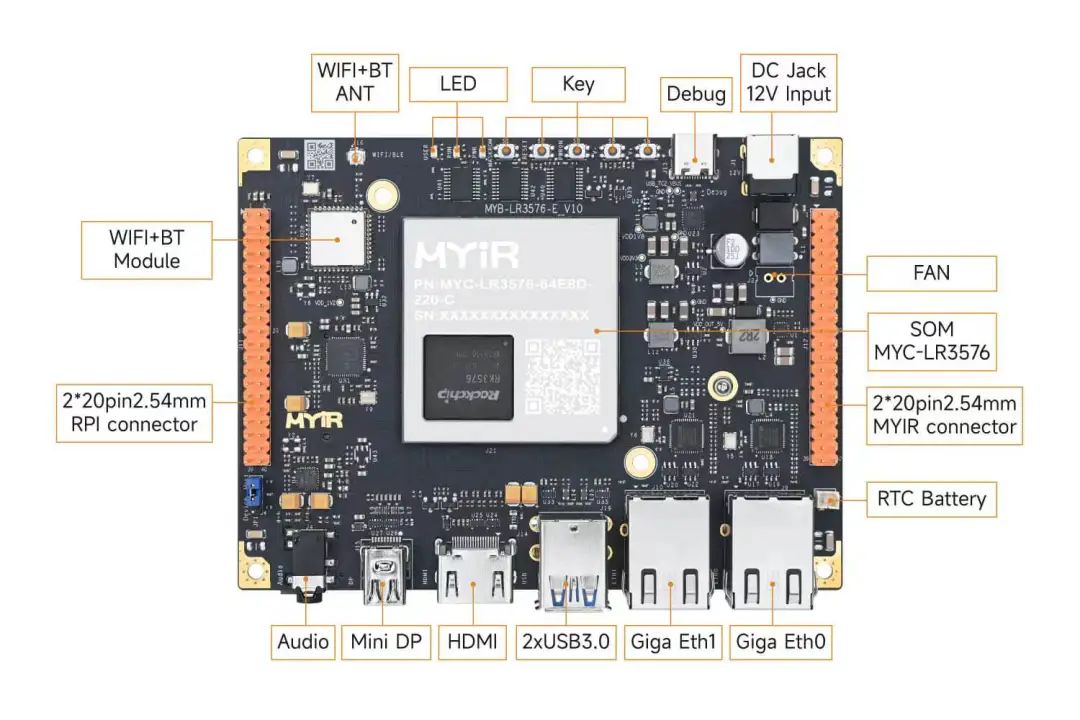
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
Qwen2-VL-3B模型在米尔瑞芯微RK3576开发板NPU多模态部署指导与评测
Alif Semiconductor发布支持生成式AI的MCU基准测试结果,巩固其在边缘AI领域的领先地位




评论