 NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布
NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布

感谢众多用户及合作伙伴一直以来对NVIDIA TensorRT-LLM的支持。TensorRT-LLM 的 Roadmap 现已在 GitHub 上公开发布!
TensorRT-LLM
持续助力用户优化推理性能
TensorRT-LLM 可在 NVIDIA GPU 上加速和优化最新的大语言模型(Large Language Models)的推理性能。该开源程序库在 /NVIDIA/TensorRT-LLM GitHub 资源库中免费提供。
近期,我们收到了许多用户的积极反馈,并表示,TensorRT-LLM 不仅显著提升了性能表现,还成功地将其应用集成到各自的业务中。TensorRT-LLM 强大的性能和与时俱进的新特性,为客户带来了更多可能性。
Roadmap 现已公开发布
过往,许多用户在将 TensorRT-LLM 集成到自身软件栈的过程中,总是希望能更好地了解 TensorRT-LLM 的 Roadmap。即日起,NVIDIA 正式对外公开 TensorRT-LLM 的 Roadmap ,旨在帮助用户更好地规划产品开发方向。
我们非常高兴地能与用户分享,TensorRT-LLM 的 Roadmap 现已在 GitHub 上公开发布。您可以通过以下链接随时查阅:
https://github.com/NVIDIA/TensorRT-LLM
图 1. NVIDIA/TensorRT-LLM GitHub 网页截屏
这份 Roadmap 将为您提供关于未来支持的功能、模型等重要信息,助力您提前部署和开发。
同时,在 Roadmap 页面的底部,您可通过反馈链接提交问题。无论是问题报告还是新功能建议,我们都期待收到您的宝贵意见。
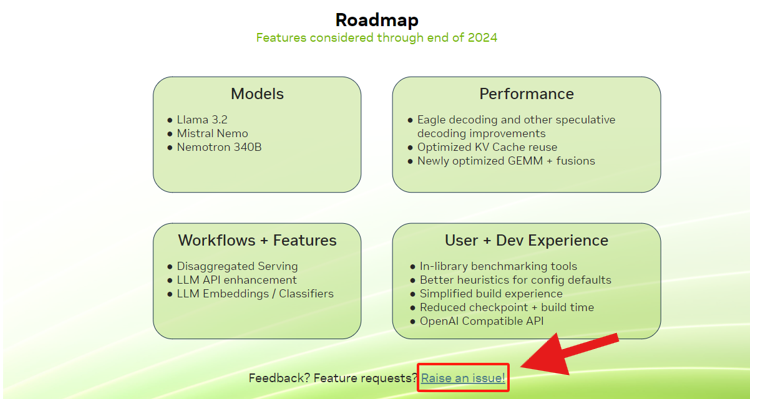
图 2.Roadmap 整体框架介绍
利用 TensorRT-LLM
优化大语言模型推理
TensorRT-LLM 是一个用于优化大语言模型(LLM)推理的库。它提供最先进的优化功能,包括自定义 Attention Kernel、Inflight Batching、Paged KV Caching、量化技术(FP8、INT4 AWQ、INT8 SmoothQuant 等)以及更多功能,以让你手中的 NVIDIA GPU 能跑出极致推理性能。
TensorRT-LLM 已适配大量的流行模型。通过类似 PyTorch 的 Python API,可以轻松修改和扩展这些模型以满足自定义需求。以下是已支持的模型列表。

我们鼓励所有用户定期查阅 TensorRT-LLM Roadmap。这不仅有助于您及时了解 TensorRT-LLM 的最新动态,还能让您的产品开发与 NVIDIA 的技术创新保持同步。
-
NVIDIA
+关注
关注
14文章
5496浏览量
109046 -
GitHub
+关注
关注
3文章
484浏览量
18413 -
LLM
+关注
关注
1文章
340浏览量
1256
原文标题:NVIDIA TensorRT-LLM Roadmap 现已在 GitHub 上公开发布!
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT-LLM的大规模专家并行架构设计

大规模专家并行模型在TensorRT-LLM的设计

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

TensorRT-LLM中的分离式服务

Votee AI借助NVIDIA技术加速方言小语种LLM开发
NVIDIA RTX AI加速FLUX.1 Kontext现已开放下载
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
NVIDIA Isaac Sim和Isaac Lab现已推出早期开发者预览版
NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

无法在OVMS上运行来自Meta的大型语言模型 (LLM),为什么?
京东广告生成式召回基于 NVIDIA TensorRT-LLM 的推理加速实践
在NVIDIA TensorRT-LLM中启用ReDrafter的一些变化






 工商网监
工商网监
评论