 基于图遍历的Flink任务画布模式下零代码开发实现方案
基于图遍历的Flink任务画布模式下零代码开发实现方案

作者:京东物流 吴云涛
前言
提交一个DataSteam 的 Flink应用,需要经过 StreamGraph、JobGraph、ExecutionGraph 三个阶段的转换生成可成执行的有向无环图(DAG),并在 Flink 集群上运行。而提交一个 Flink SQL 应用,其执行流程也类似,只是多了一步使用 flink-table-planer 模块从SQL转换成 StreamGraph 的过程。以下是利用Flink的 StreamGraph 通过低代码的方式,来实现StreamGraph的生成,并最终实现 Flink 程序零代码开发的解决方案。
一、Flink 相关概念
在Flink程序中,每个算子被称作Operator,通过各个算子的处理最终得到期望的加工后数据。比如下面这段程序中,增加了Source, Fiter, Map, Sink 4个算子。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream dataStream = env.addSource(new FlinkKafkaConsumer("topic")); DataStream filteredStream = dataStream.filter(new FilterFunction() { @Override public boolean filter(Object value) throws Exception {return true;} }); DataStream mapedStream = filteredStream.map(new MapFunction() { @Override public Object map(Object value) throws Exception {return value;} }); mapedStream.addSink(new DiscardingSink()); env.execute("test-job");
StreamGraph
Flink的逻辑执行图,描述了整个流处理任务的流程和数据流转递规则,包括了数据源(Source)、转换算子(Transform)、数据目的端(Sink)等元素,以及它们之间的依赖关系和传输规则。StreamGraph是通过Flink的API或者DSL来构建的向无环图(DAG),它与JobGraph之间是一一对应的关系。StreamGraph中的顶点称为streamNode,是用来表示Operator算子的类,包含了算子uid、并行度,是否共享slot(SlotSharingGroup)等信息。边称作streamEdge。通过StreamingJobGraphGenerator类生成JobGraph。
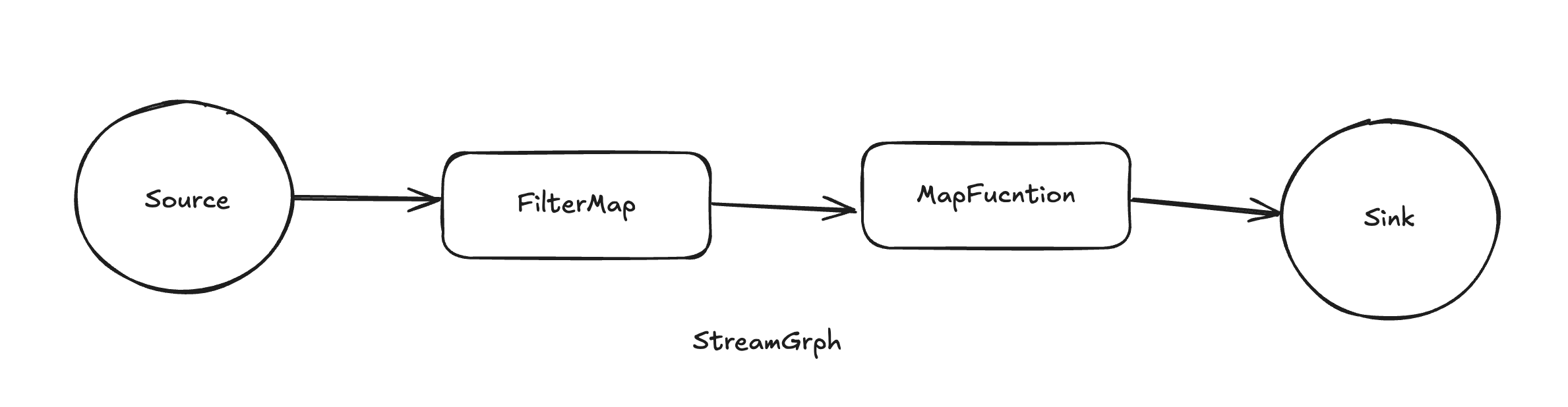
JobGraph
StreamGraph 经过 flink-optimizer 模块优化后生成 JobGraph。生成 JobGraph 时,会将多个满足条件的算子chain 链接到一起作为一个顶点(JobVertex), 在运行时对应1个 Task。Task 是 Flink 程序的基本执行单元,任务调度时将Task分配到TaskManager上执行。
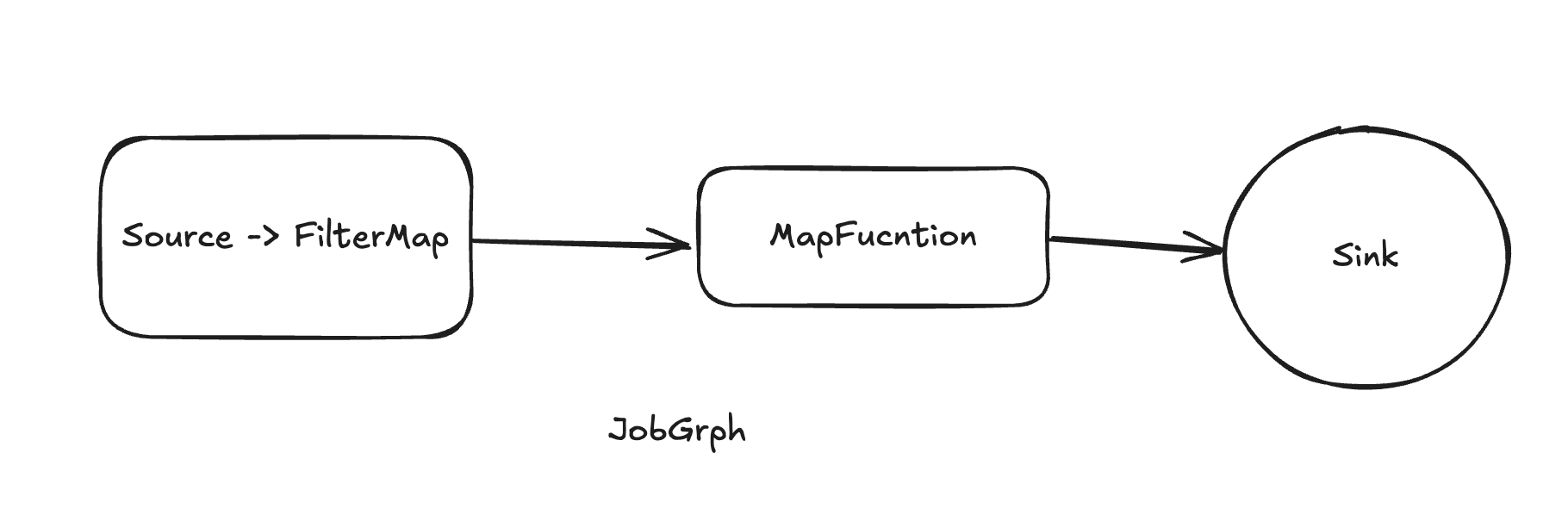
ExecutionGraph
物理执行图是由JobGraph转换而来,描述了整个流处理任务的物理执行细节,包括了任务的调度、任务的执行顺序、任务之间的数据传输、任务的状态管理等。Task会在步骤中拆分为多个SubTask。对应Task中的每个并行度。
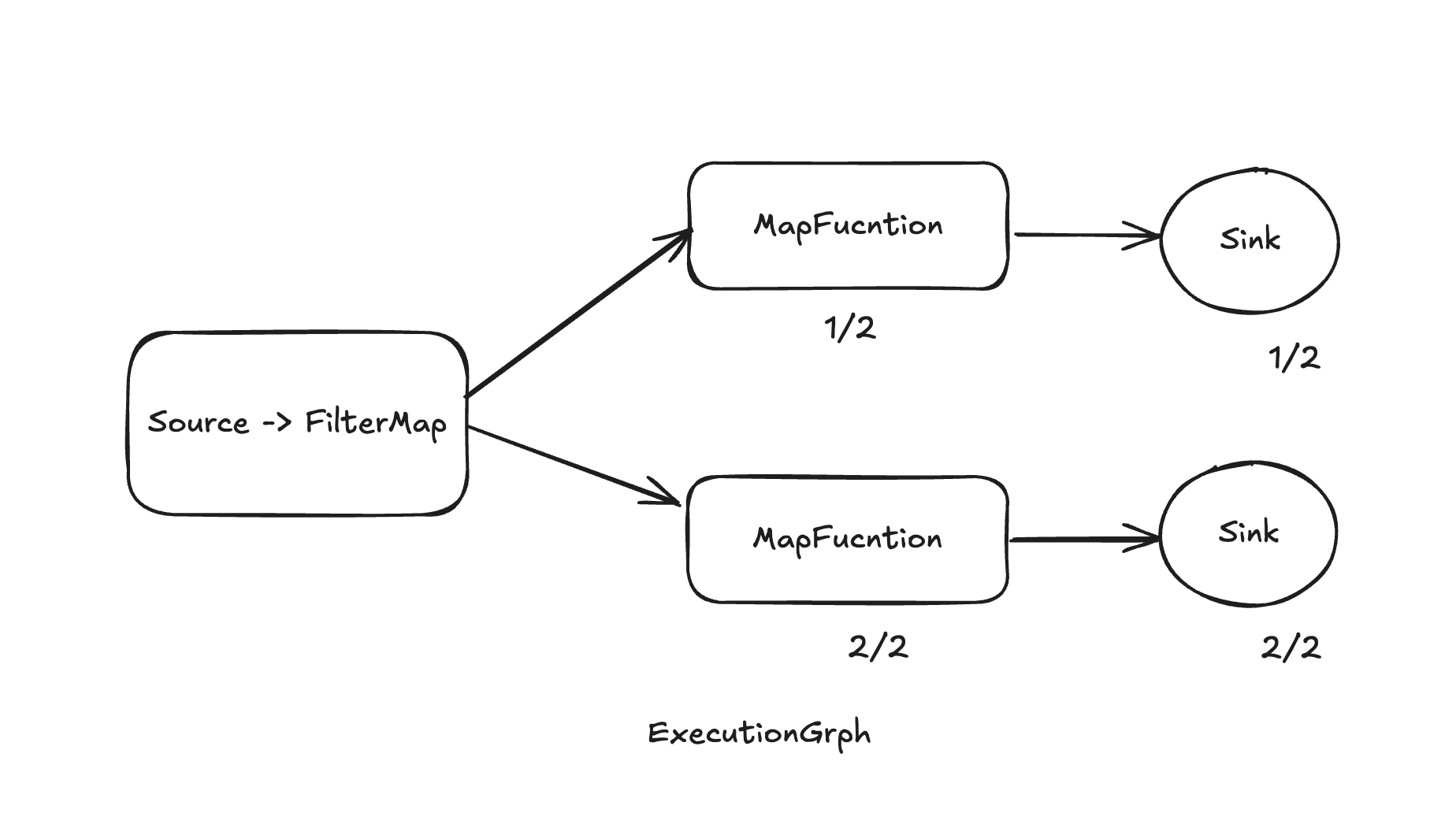
Physical Graph
PhysicalGraph是在执行时的ExecutionGraph。ExecutionGraph中的每一个顶点ExecutionJobVertex都对应一个或多个顶点ExecutionVertex,它们是物理执行图中的节点。
二、画布模式实现思路
实现流程
首先,我们采用画布模式(拖拉拽方式)来实现Flink程序的组装,将极大程度上方便我们复用部分加工的算子,最终实现零代码的Flink应用开发。我们通过绘图的方式,直接将内置的算子绘制在图标上。如下所示:
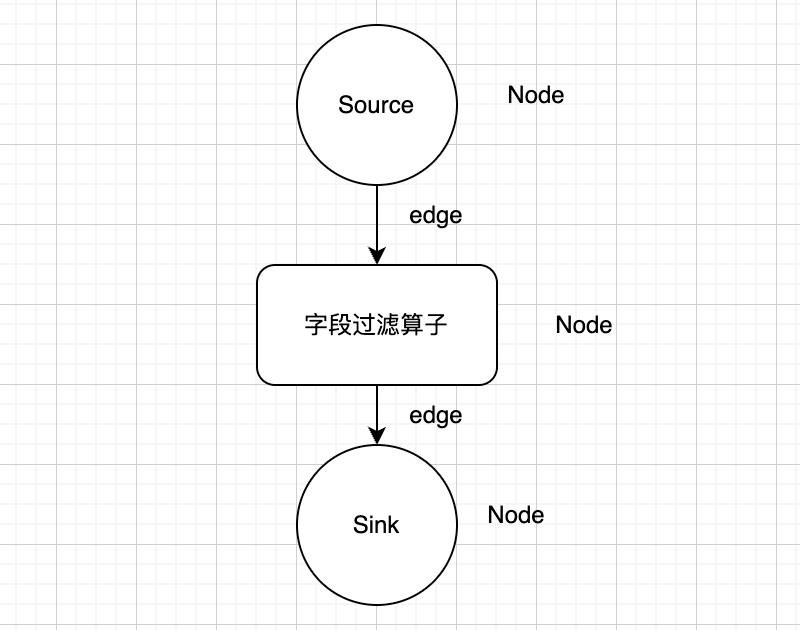
构建有向无环图(DAG),并持久化。通过拖拉拽的方式(画布模式)构建你的Flink应用,后端的持久化存储采用邻接表方式。我们在 mysql 关系数据库中将 Node(算子:Source、Sink、中间加工逻辑算子)存储到 flink_node 表中;将边存到一张 flink_realation 表中。
重新组将Flink作业
要组装以上画布模式的Flink应用,首先需要初始化好 StreamExecutionEnvironment 相关参数,其次将上述表中的 flink_node 和flink_edge 转化为DataStream,并将转化出的 DataStream 合理地拼接成一个 DataStream API Flink 应用程序。
在将flink_node、flink_edge转为为DataStream时选择何种遍历算法来组装呢?我们知道有向无环图的遍历最常用的有:深度优先遍历(DFS)和广度优先遍历(BFS)。这里我们采用了BFS算法+层序遍历的方式,BFS便于在组装的过程中将已visit到的node节点拼装到其parent 的节点上。
总结
在实际的实现过程中,遇到的问题往往比以上复杂很多。比如需要将更多的信息存储在node节点和edge边上。node上需要存储并行度、算子处理前后的表schema等;edge需要存储keyby的字段、上下游之间的数据shuffle的方式等等。此外在内置的算子无法满足用户需求时,还需要考虑如何友好的支持自定义算子(UDF)的嵌入等问题。
审核编辑 黄宇
-
开发
+关注
关注
0文章
380浏览量
42231 -
代码
+关注
关注
30文章
4975浏览量
74354
发布评论请先 登录
隔空科技联合涂鸦智能推出微波雷达感应灯零代码实现方案

什么是零代码平台?
RA-RTT体验零代码点亮LED灯
浅谈零代码开发的价值在哪里
零代码平台和低代码平台分别适合开发哪些应用程序
零代码开发平台为什么会受到企业管理者的欢迎
零代码如何实现造数据



评论