 AI初出企业Cerebras已申请IPO!称发布的AI芯片比GPU更适合大模型训练
AI初出企业Cerebras已申请IPO!称发布的AI芯片比GPU更适合大模型训练

电子发烧友网报道(文/李弯弯)近日,据外媒报道,研发出世界最大芯片的明星AI芯片独角兽Cerebras Systems已向证券监管机构秘密申请IPO。
Cerebras成立于2016年,总部在美国加州,专注于研发比GPU更适用于训练AI模型的晶圆级芯片,为复杂的AI应用构建计算机系统,并与阿布扎比科技集团G42等机构合作构建超级计算机。基于其最新旗舰芯片构建的服务器可轻松高效地训练万亿参数模型。
Cerebras已发布第三代AI芯片
技术实力方面,Cerebras公司采用独特的晶圆级集成技术,将整片晶圆作为一个单独的芯片来使用,实现了前所未有的集成度和性能。这种技术使得Cerebras的AI芯片在晶体管数量、计算能力和内存带宽等方面均达到了业界领先水平。
Cerebras的AI芯片具有强大的计算能力,能够支持训练业界最大的AI模型,包括参数规模高达数十万亿个的模型。这种高性能计算能力使得研究人员能够更快地测试想法、使用更多数据并解决新问题。
Cerebras的AI芯片采用了先进的通信架构,实现了全局性的低延迟、高带宽通信。这种通信架构使得多个Cerebras芯片之间能够高效地进行数据传输和协作,进一步提升了AI应用的性能。
产品方面,Cerebras的核心产品线WSE(Wafer Scale Engine)系列已经过更新三代。2019年8月,Cerebras发布第一颗芯片WSE,WSE作为Cerebras标志性产品,是史上最大的AI芯片之一。其设计突破了传统半导体制造的界限,采用了独特的晶圆级集成(Wafer-Scale Integration, WSI)技术,将整个晶圆作为一个单独的芯片来使用,这在当时是前所未有的。
这颗芯片采用台积电16nm制程,在46225mm²面积上集成了40万个AI核心和1.2万亿颗晶体管。同时,该芯片配备了18GB的片上静态随机存取存储器(SRAM),这一容量远大于大多数芯片的片外存储(DDR)。带宽达到100Pb/s(1Pb=1000TB),这一数值比现有芯片的相关参数高出一个单位(3个数量级)。
2021年,Cerebras推出第二代芯片WSE-2,搭载WSE-2芯片的AI超算系统CS-2也同期发布。WSE-2在继承了WSE的晶圆级集成技术的基础上,进一步提升了制程工艺和性能,成为当时业界领先的AI芯片之一。该芯片采用台积电7nm制程,相较于前代产品WSE的16nm工艺,进一步缩小了晶体管的尺寸,提高了集成度。与WSE相同,WSE-2也采用了整片晶圆作为单一芯片,面积约为462255mm²。晶体管数量达到了创纪录的2.6万亿个,相较于WSE的1.2万亿个晶体管,实现了翻倍的增长。
WSE-2集成了85万个专为AI应用优化的稀疏线性代数计算(SLAC)核心,相较于WSE的40万个核心,有了显著的提升。片上内存提升至40GB,相较于WSE的18GB,增加了近一倍。内存带宽高达20PB/s,相较于WSE的9PB/s,也有了显著的提升。
今年3月,Cerebras推出了第三代晶圆级芯片WSE-3和AI超级计算机CS-3。WSE-3采用台积电5nm制程,有90万个AI核心和4万亿颗晶体管。配备了44GB的片上SRAM缓存,相较于前代产品有了显著提升。这一大容量片上内存能够支持更大规模的AI模型训练,无需进行分区或重构,大大简化了训练工作流程。WSE-3的内存带宽高达21PB/s,峰值AI算力高达125 PetaFLOPS,相当于每秒能够执行12.5亿亿次浮点计算。
Cerebras 的AI芯片被认为更适合大模型训练
Cerebras的芯片被认为比GPU更适合用于大模型训练。其WSE系列芯片具有庞大的规模和惊人的性能。例如,WSE-3拥有超过4万亿个晶体管和46225mm²的硅片面积,堪称全球最大的AI芯片。与之相比,传统GPU的规模和性能通常较小。Cerebras的芯片能够在单个设备上容纳和训练比当前热门模型大得多的下一代前沿模型。
Cerebras的芯片搭载了大量的核心和内存。例如,WSE-3拥有900,000个核心和44GB内存,这使得它能够同时处理大量的数据和计算任务。传统GPU的核心数量和内存通常较小,可能需要多个GPU协同工作才能达到类似的性能。
Cerebras采用了片上内存的设计,这意味着内存和计算核心都在同一个芯片上,从而大大减少了数据传输的开销和延迟。相比之下,传统GPU的内存和计算核心是分离的,需要通过PCIe等接口进行数据传输,这可能导致性能瓶颈和延迟。
Cerebras的CS-3系统是基于WSE-3推出的,具备强大的系统支持。该系统拥有高达1.2PB的内存容量,能够训练比GPT-4和Gemini模型大10倍的下一代前沿模型。在大模型训练中,Cerebras的CS-3系统相较于GPU具有更低的代码复杂性和更高的易用性。开发人员可以更加高效地实现和训练大模型。
Cerebras的芯片通过保持整个晶圆的完整性来降低互连和网络成本以及功耗。这使得Cerebras的芯片在功耗和成本方面相较于多个GPU协同工作具有优势。
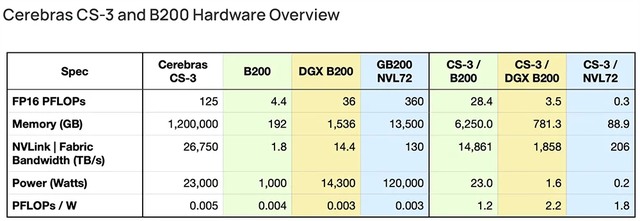
今年4月,Cerebras发文比较Cerebras CS-3与英伟达B200,称CS-3和英伟达DGX B200是2024年上市的两款最令人兴奋的AI硬件新品。从对比数据来看,无论AI训练性能还是能效,CS-3都做到倍杀DGX B200。
写在最后
目前,AI大模型训练基本离不开GPU的支持,Cerebras发布的WSE系列芯片,给业界带来了新的思路,尤其是其今年发布的第三代产品WSE-3,能够支持训练业界最大的AI模型,包括参数规模高达24万亿个的模型。如果其能够顺利上市,一是对于其自身后续发展更有利,二是对于英伟达来说它可能会成长为一个较大的竞争对手。
-
gpu
+关注
关注
28文章
5266浏览量
136040 -
ipo
+关注
关注
1文章
1289浏览量
34796 -
AI芯片
+关注
关注
17文章
2161浏览量
36863 -
大模型
+关注
关注
2文章
3753浏览量
5268
发布评论请先 登录
AI大模型微调企业项目实战课

AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的未来:提升算力还是智力
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
Cognizant加速AI模型企业级开发
ai_cube训练模型最后部署失败是什么原因?
【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》
提升AI训练性能:GPU资源优化的12个实战技巧




评论