 一文详解基于以太网的GPU Scale-UP网络
一文详解基于以太网的GPU Scale-UP网络

最近Intel Gaudi-3的发布,基于RoCE的Scale-UP互联,再加上Jim Keller也在谈用以太网替代NVLink。而Jim所在的Tenstorrent就是很巧妙地用Ethernet实现了片上网络之间的互联。所以今天有必要来讲讲这个问题。
实现以太网替代NVLink需要什么手段,不只是一个传输协议的问题,还涉及到GPU架构的一系列修改,本质上这个问题等价于如何把HBM挂在以太网上,并实现Scale-Out和满足计算需求的一系列通信优化,例如SHARP这类In-Network-Computing等, 全球来看能同时搞定这个问题的人也就那么几个,至少明确的说UltraEthernet压根就没想明白。
有必要回答以下几个问题,或者说博通要搞个NVLink一样的东西出来,必须解决如下几个问题:
1.Latency Boundary是多少?高吞吐高速Serdes FEC和超过万卡规模的互联带来的链路延迟都是不可抗的,这些并不是说改一个包协议,弄一个HPC-Ethernet就能搞定的。
2.传输的语义是什么?做网络的这群人大概只懂个SEND/RECV。举个例子,UEC定义的Reliable Unordered Delivery for Idempotent operations(RUDI)其实就是一个典型的技术上的错误,一方面它满足了交换律和幂等律,但是针对一些算子,例如Reduction的加法如何实现幂等?显然这群人也没做过,还有针对NVLink上那种细颗粒度的访存,基于结合律的优化也是不支持的。更一般来说,它必须演进到Semi-Lattice的语义才行。
3.更大内存在NVLINK上池化的问题? 解决计算问题中Compute Bound算子的部分时间/空间折中,例如KV Cache等。
4.动态路由和拥塞控制能力1:1无收敛的Lossless组网对于万卡集群通过一些hardcode的调优没什么太大的问题,而对于十万卡和百万卡规模集群来看,甚至需要RDMA进行长传,这些问题目前来看没有一个商业厂商能解决的。
考虑到超大规模模型训练的一系列需求,把HBM直接挂载在以太网上并实现了一系列集合通信卸载的,放眼全球现在也就只有少数几个团队干过,前三个问题我是在四年前做NetDAM项目时就已经完全解决干净了,第四个去年也在某个云的团队一起解决干净了。
下面我们将介绍一些Gaudi3/Maia100/TPU等多个厂商的互联,然后再分析一下NVLink的演进,最后再来谈谈如何能够真正地解决这些问题 at Scale, 再强调(Diss)一下at Scale这事没做好就别瞎叫。
1. 当前ScaleUP互联方案概述
1.1 Intel Gaudi3
从Gaudi3 whitepaper[1]来看,Gaudi的Die如下图所示: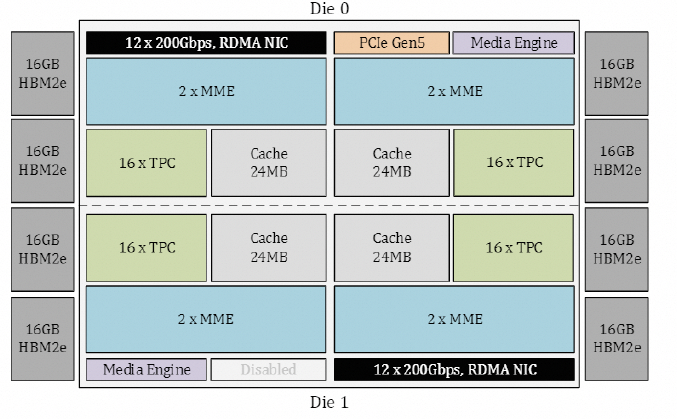
内置了24个RoCE 200Gbps的链路,其中21个用于内部FullMesh,三个用于外部链接。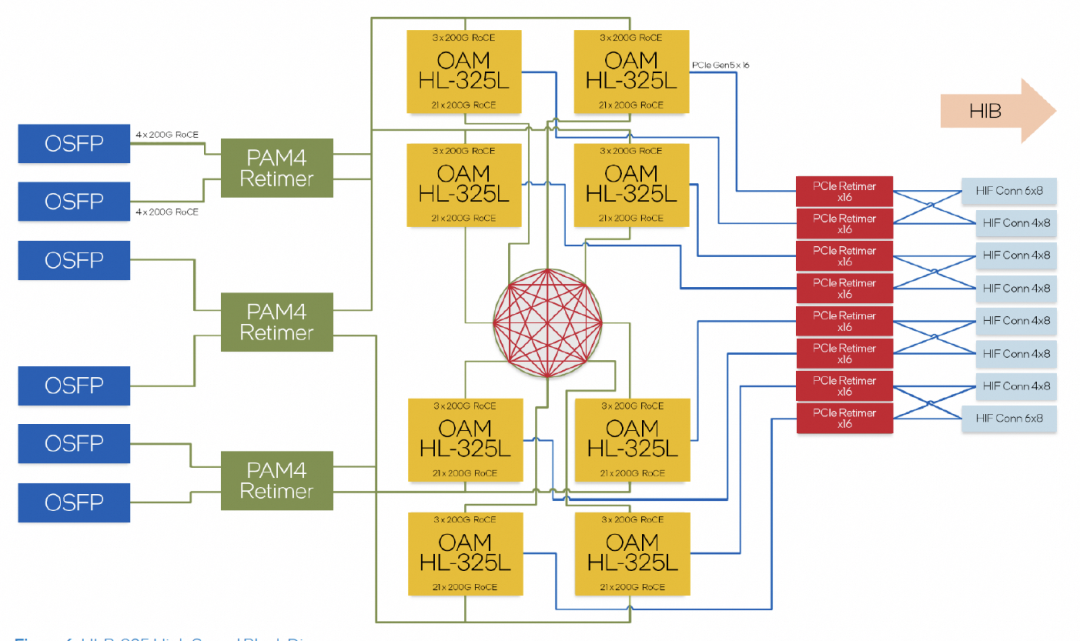
超大规模组网的拓扑,计算了一下Leaf交换机的带宽是一片25.6T的交换机。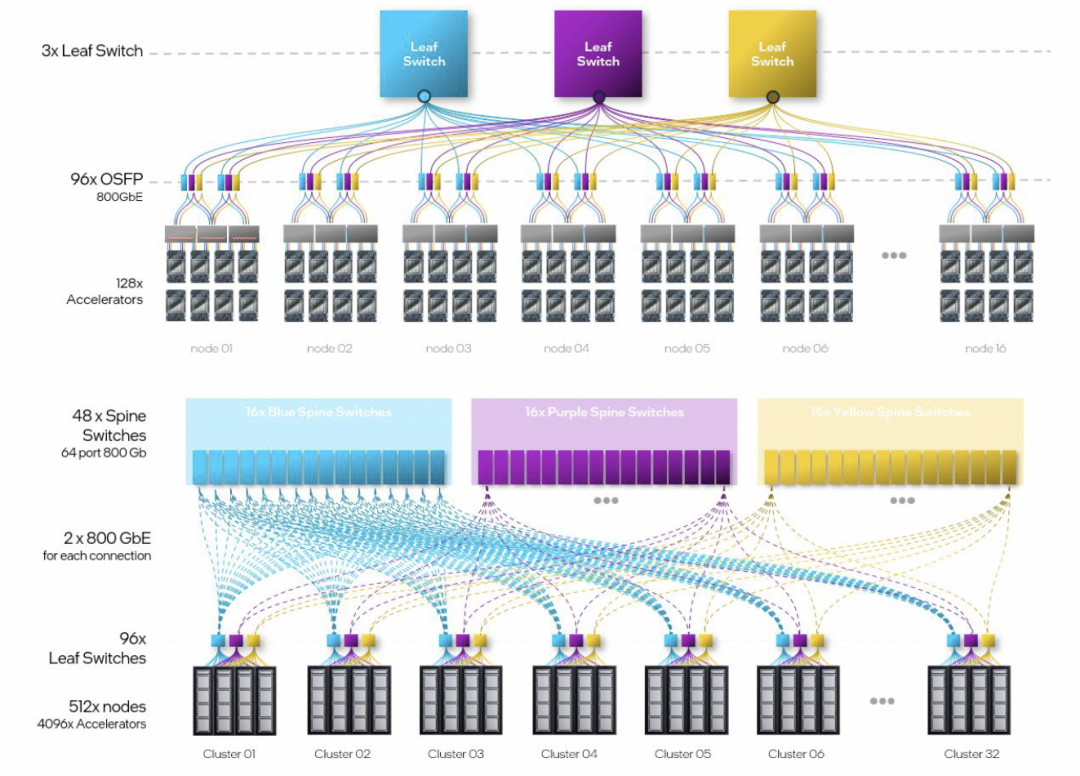
但是Intel WhitePaper有一系列的问题值得去仔细爬一下。
1.1.1 拥塞控制
Intel的白皮书阐述的是没有使用PFC,而是采用了Selective ACK机制。同时采用了SWIFT来做CC算法避免使用ECN,基本上明眼人一看,这就是复用了Google Falcon在Intel IPU上做的Reliable Transport Engine。
1.1.2 多路径和In-Network Reduction
Intel宣称支持Packet Spraying,但是交换机用的哪家的呢,一定不是自己家的Tofino。那么只能是博通了。另外In-Network Reduction支持了FP8/BF16等, Operator只支持Sum/Min/Max,再加上UEC有一些关于In-Network-Computing(INC)的工作组,应该基本上就清楚了。
1.2 Microsoft Maia100
没有太多的信息,只有4800Gbps单芯片的带宽,然后单个服务器机框4张Maia100,整个机柜8个服务器构成一个32卡的集群。
放大交换机和互联的线缆来看,有三个交换机,每个服务器有24个400Gbps网络接口,网口间有回环的连接线(图中黑色),以及对外互联线(紫色)。
也就是说很有可能构成如下的拓扑: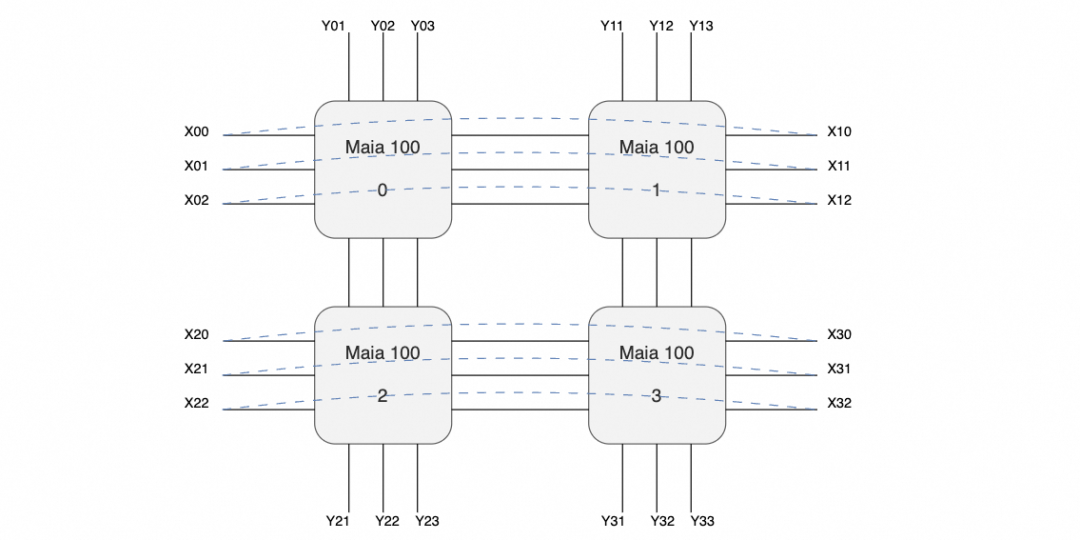
即在主板内部构成一个口字形的互联,然后在X方向构成一个环,而在Y方向则是分别构成三个平面连接到三个交换机。
交换机上行进行机柜间的Scale-Out连接,每个机柜每个平面总共有32个400G接口, 再加上1:1收敛,上行交换机链路算在一起正好一个25.6T的交换机,这样搭几层扩展理论应该可行,算是一个Scale-Up和Scale-Out两张网络合并的代表。至于协议对于Torus Ring来看,简单的点到点RoCE应该问题不大,互联到Scale-Out交换机时就需要多路径的能力了。
缺点是延迟可能有点大,不过这类自定义的芯片如果不是和CUDA那样走SIMT,而是走脉动阵列的方式,延迟也不是太大的问题。另外Torus整个组就4块,集合通信延迟影响也不大。但是个人觉得这东西可能还是用于做推理为主的,一般CSP都会先做一块推理用的芯片,再做训练的。另外两家CSP也有明确的训练推理区分AWS Trainium/Inferentia, Google也是V5p/V5e。
1.3 Google TPU
TPU互联大家已经很清楚了,Torus Ring的拓扑结构和光交换机来做链路切换。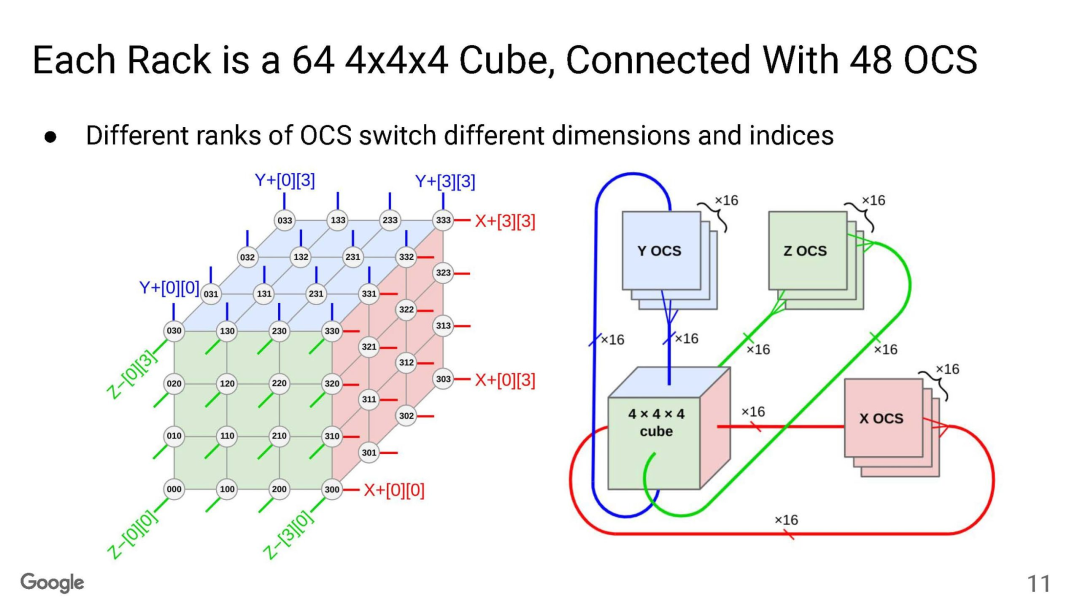
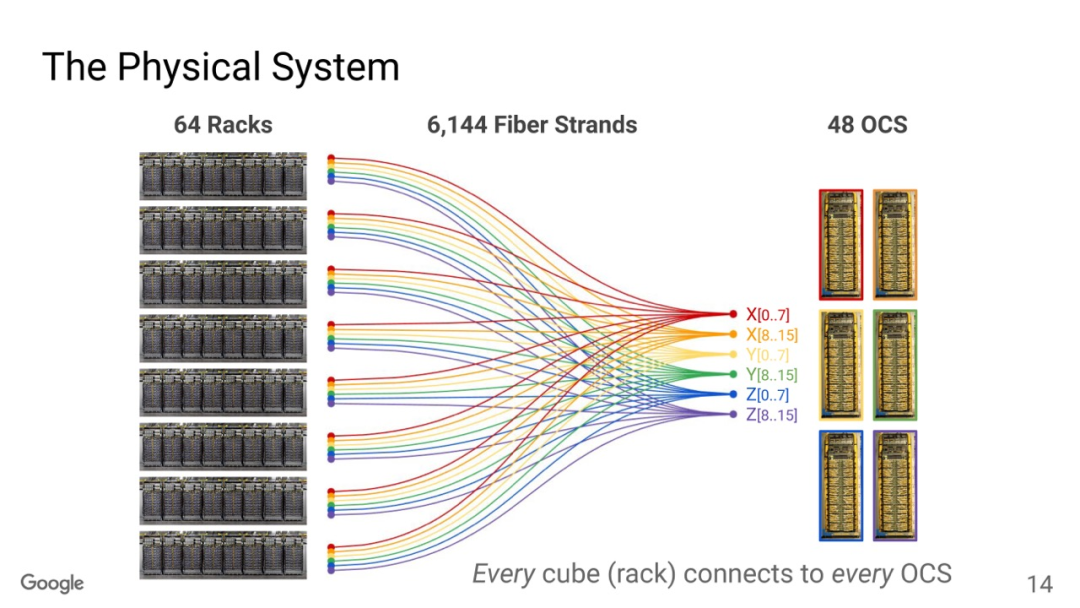
OCS有两个目的,一个是按照售卖的规模进行动态切分,例如TPUv5p 单芯片支持4800Gbps的ICI(Inter-Chip Interconnect)连接,拓扑为3D-Torus,整个集群8960块TPUv5p 最大售卖规模为6144块构成一个3D-Torus。
通过OCS可以切分这些接口进行不同尺度的售卖, 另一个是针对MoE这些AlltoAll的通信做扩展bisection 带宽的优化。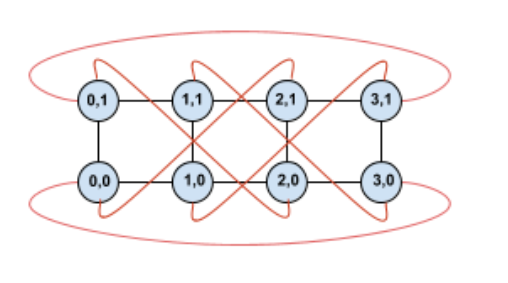
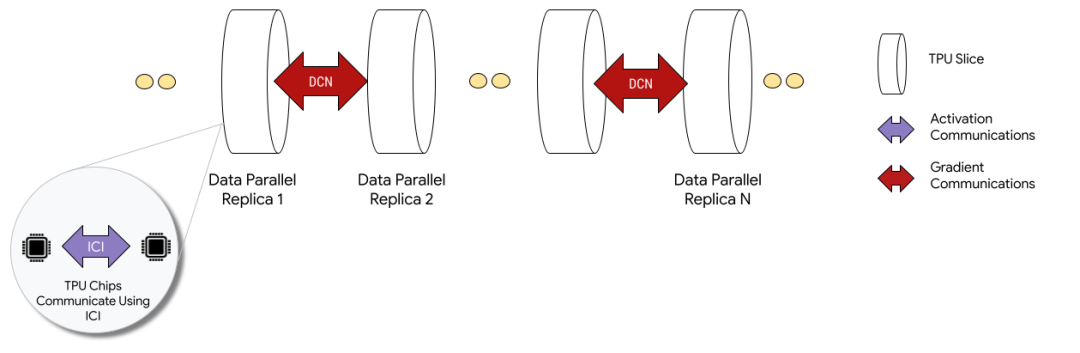
还有一个是容错,这是3D Torus拓扑必须要考虑的一个问题,有一些更新是这周NSDI‘24 讲到一个《Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer》[2] 后面我们将专门介绍。 另一方面Google还支持通过数据中心网络扩展两个Pod构建Multislice的训练,Pod间做DP并行。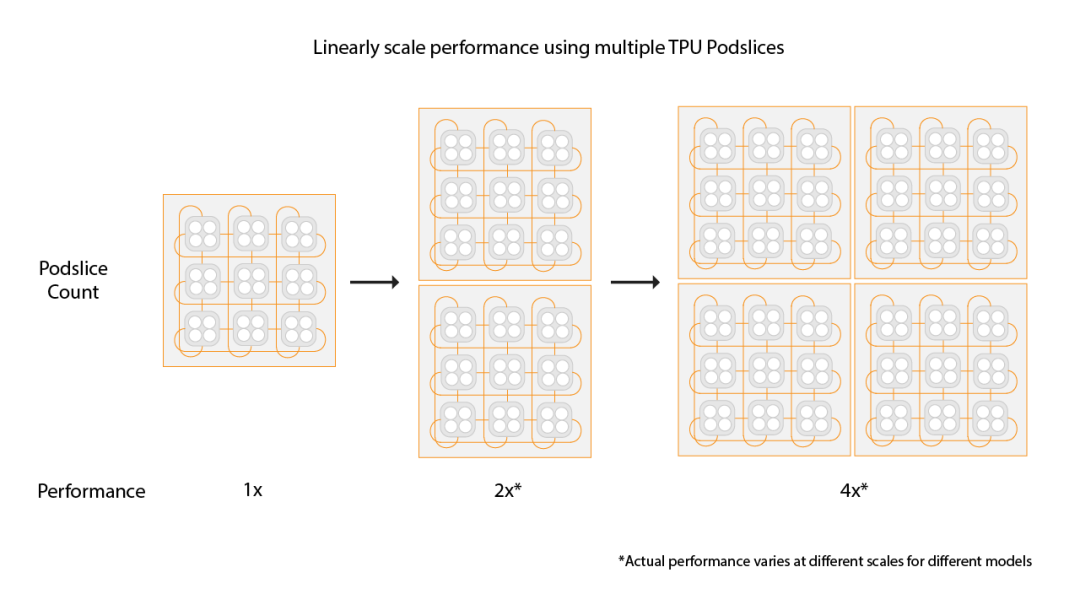
1.4 AWS Trainium
Trainium架构如下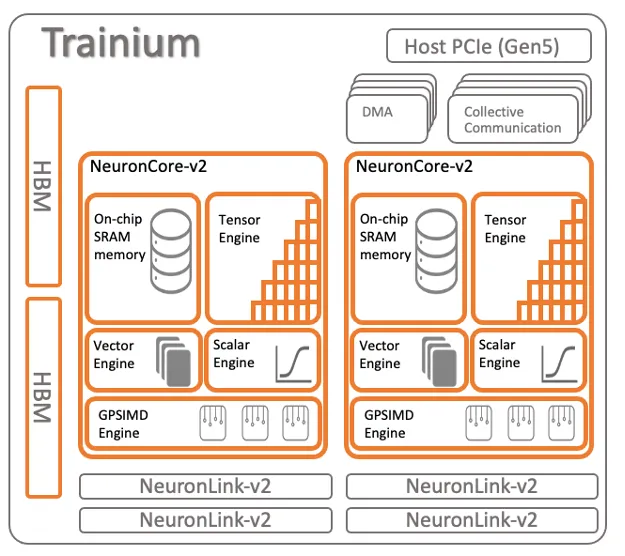
16片构成一个小的Cluster,片间互联如下: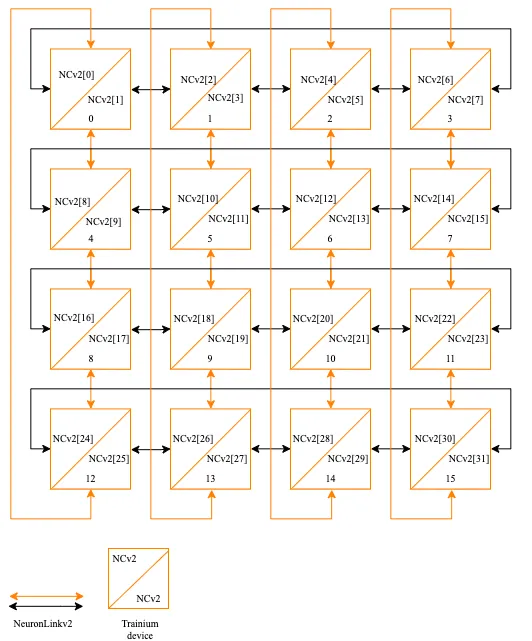
也是一个2D Torus Ring的结构。
1.5 Tesla Dojo
它搞了一个自己的Tesla Transport Protocol,统一Wafer/NOC和外部以太网扩展。
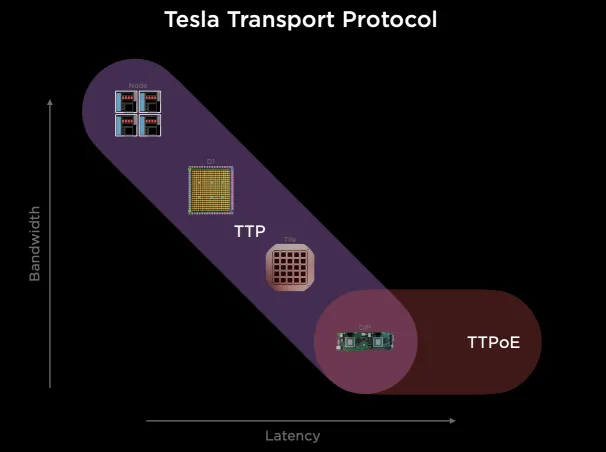
它通过台积电的System-on-Wafer将25个D1计算单元封装在一个晶圆上, 并采用5x5的方式构建2D Mesh网络互联所有的计算单元, 单个晶圆构成一个Tile.每个Tile有40个I/O Die。
Tile之间采用9TB/s互联。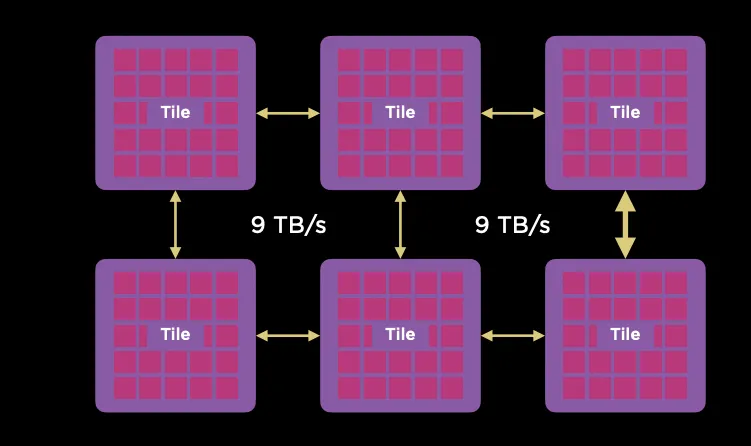
可以通过片上网络路由绕开失效的D1核或者Tile。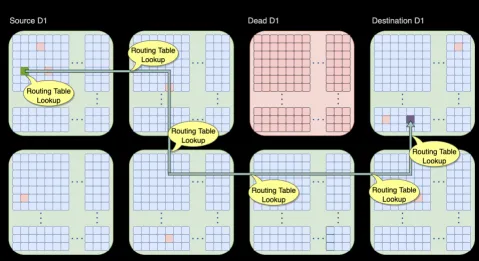
对外Scale-Out的以太网有一块DIP,每个D1计算引擎有自己的SRAM, 而其它内存放置在带HBM的Dojo接口卡(DIP)上。
每个网卡通过顶部的900GB/s特殊总线TTP(Tesla Transport Protocol)连接到Dojo的I/O Die上, 正好对应800GB HBM的带宽, 每个I/O Die可以连接5个Dojo接口卡(DIP)。

由于内部通信为一个2D Mesh网络, 长距离通信代价很大, 针对片上路由做了一些特殊的设计。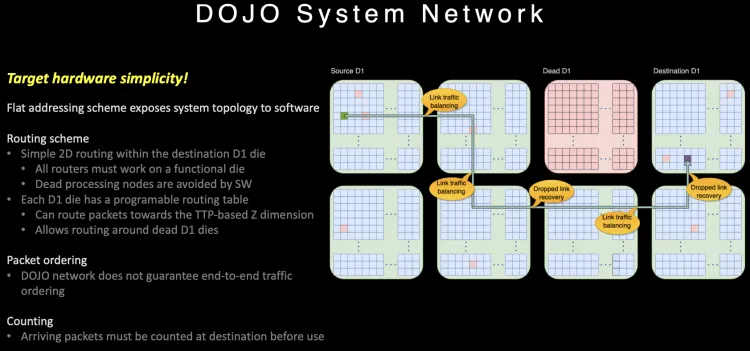
路由在片上提供多路径,并且不保序, 同时针对大范围长路径的通信, 它很巧妙的利用Dojo接口卡构建了一个400Gbps的以太网TTPoE总线来做shortcut。
Dojo通过System-on-wafer的方式构建了基于晶圆尺度的高密度的片上网络, 同时通过私有的片间高速短距离总线构建了9TB/s的wafer间的通信网络. 然后将I/O和内存整合在DIP卡上,提供每卡900GB/s连接到晶圆片上网络的能力,构建了一个超大规模的2D Mesh网络, 但是考虑到片上网络通信距离过长带来的拥塞控制, 又设计了基于DIP卡的400Gbps逃生通道,通过片外的以太网交换机送到目的晶圆上。
1.6 Tenstorrent
Jim keller在Tenstorrent的片上网络设计就是使用的以太网,结构很简单, Tensor+控制头构成一个以太网报文并可以触发条件执行等能力,如下所示: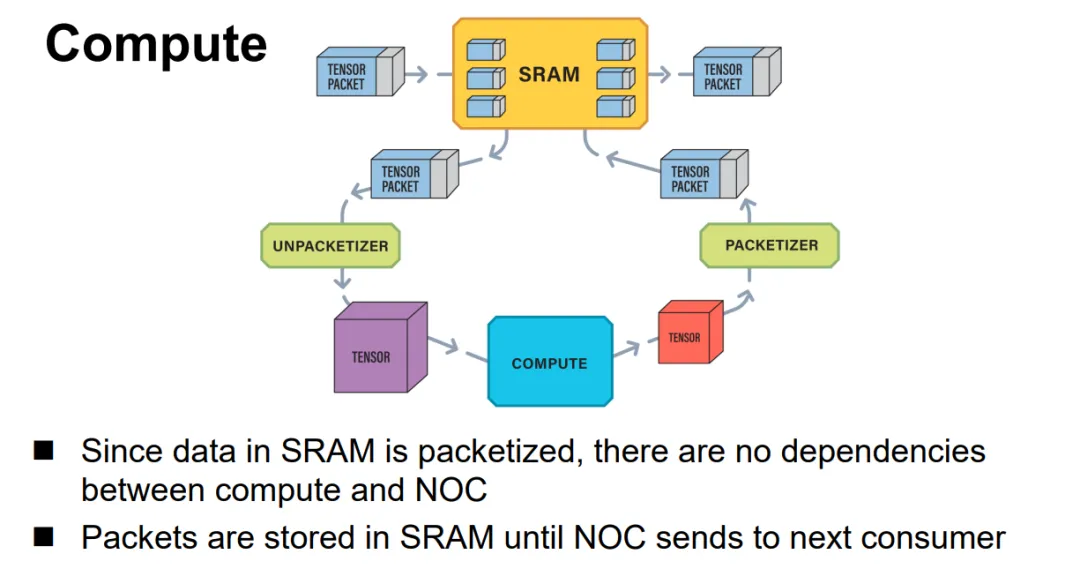
片间互联全以太网: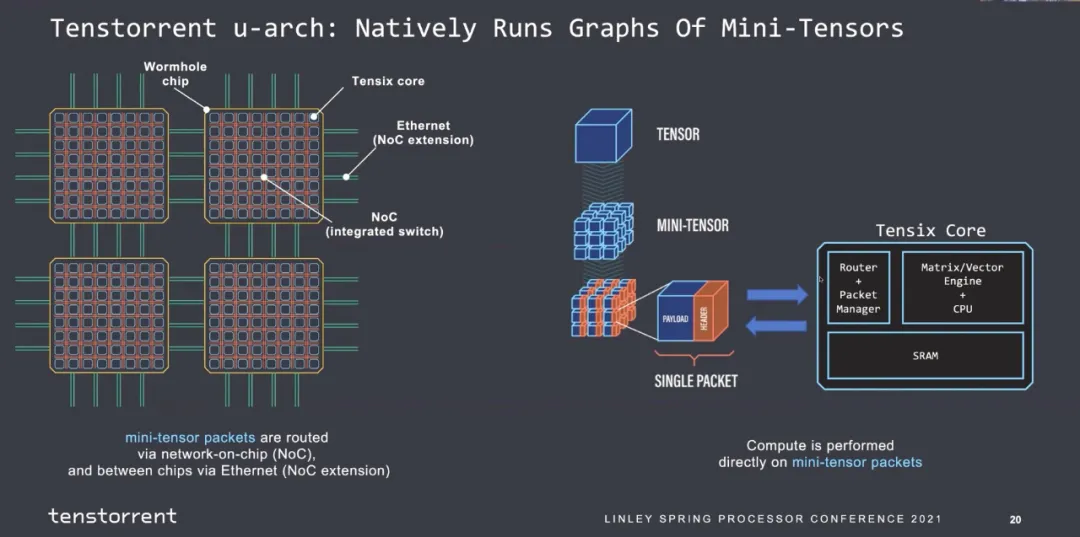
并且支持多种功能通信源语。
然后就是图的划分,主观觉得每个stage的指令数是可以估计的,算子进出的带宽是可以估计的。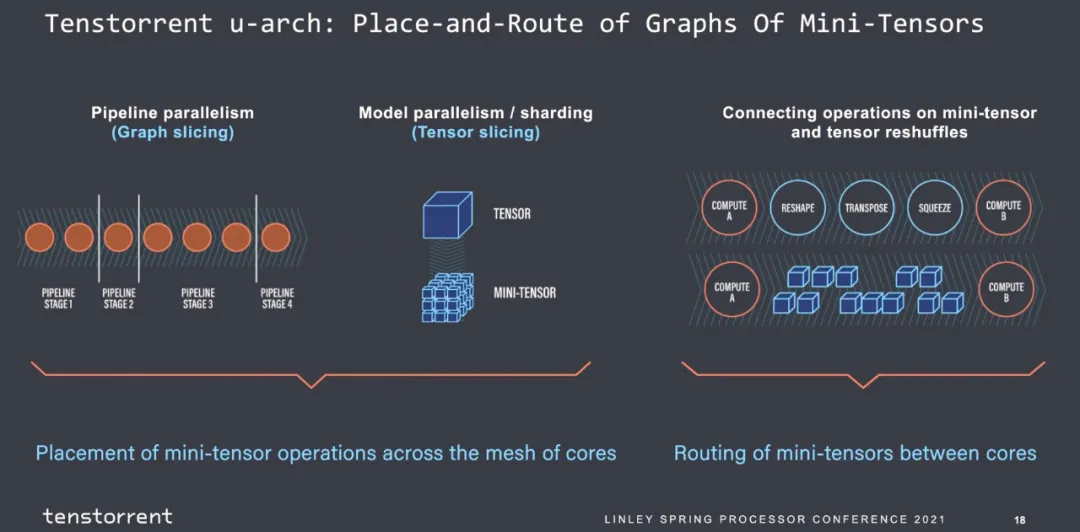
那么最后mapping到核上的约束也似乎好做: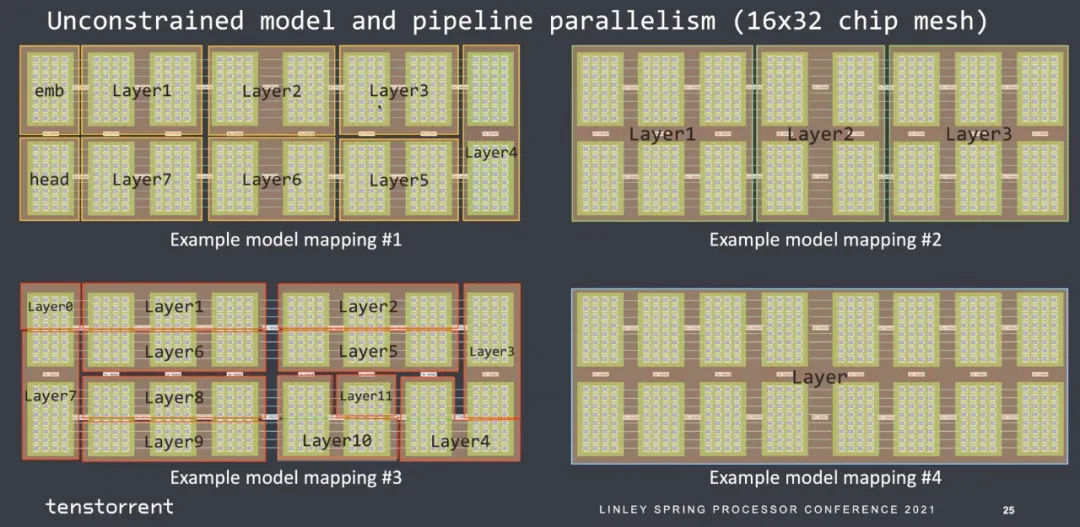
也是很简单的一个2D Mesh结构:
可以扩展到40960个core的大规模互联。
2. Scale-UP的技术需求
2.1 拓扑选择
我们可以注意到在ScaleUp网络选择中,Nvidia当前是1:1收敛的FatTree构建,而其它几家基本上都是Torus Ring或者2D Mesh,而Nvidia后续会演进到DragonFly。
背后的逻辑我们可以在hammingMesh的论文中看到的选择如下: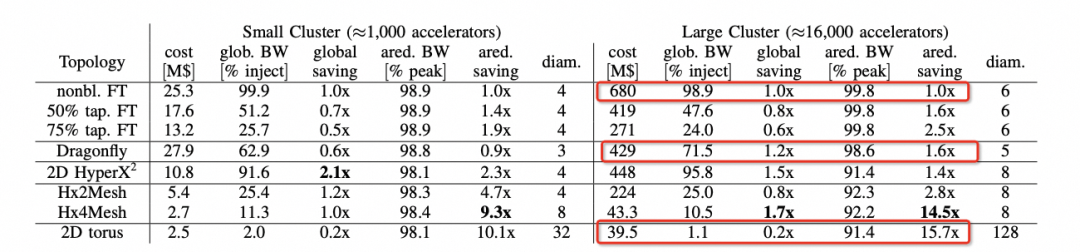
可以看到对于Allreduce带宽来看,Torus是最便宜的,性能也能够基本跑到峰值。但是针对MoE这类模型的AlltoAll就要考察bisection带宽了,而DragonFly无论是在布线复杂度还是GlobBW以及网络直径上都还不错,所以明白了Bill Dally的选择了吧?
2.2 动态路由和可靠传输
虽然所有的人都在扯RoCE有缺陷,BF3+Spectrum-4有Adaptive Routing,博通有DLB/GLB来演进Packet Spraying还有和思科一样的VoQ的技术,当然还有Meta的多轨道静态路由做流量工程,或者管控平面去调度亲和性。但简单来说,这些都是在万卡规模可以解决一部分问题的,而at Scale这个难题现在要到十万卡以上规模,怎么做?
从算法上解决Burst是一件很难的事情,而更难的是所有的人不去想Burst怎么造成的,天天屎上雕花的去测交换机buffer来压burst,据说还有人搞确定性网络和傅立叶分析来搞?想啥呢?
这是一个非常难的问题,就看工业界其它几个厂什么时候能想明白吧?另一方面是系统失效和弹性售卖,Google在NSDI24的文章里面提到会产生碎片的原因: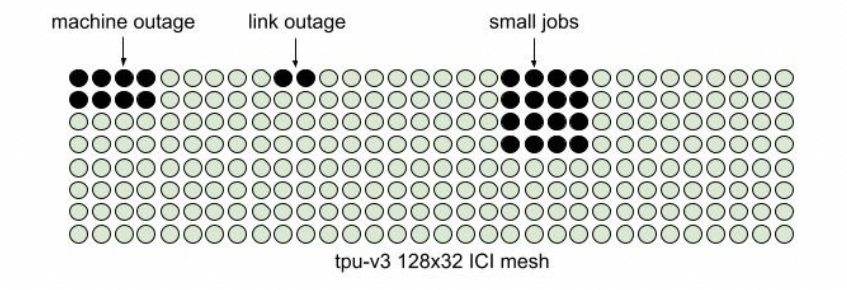
如果不考虑这些问题会导致调度难题。ICI内部的路由表实现配合OCS交换机是一个不错的选择。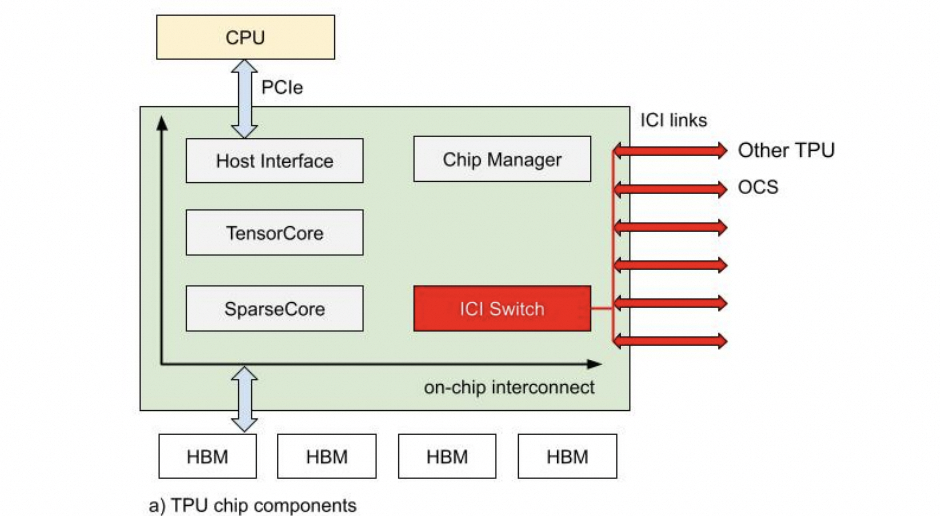
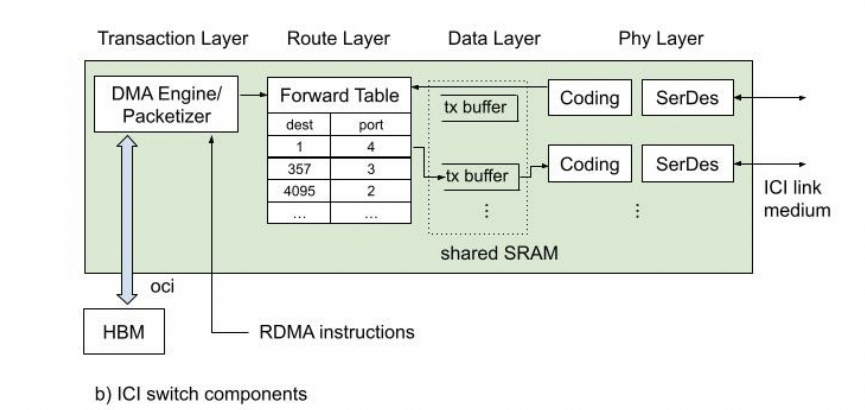
这篇论文详细地公开了ICI的物理层/可靠传输层/路由层和事务层,后面会详细讲解一下这篇论文。
为什么这个事情对以太网支持ScaleUP很重要呢?因为以太网一定需要在这里实现一个路由层支撑DragonFly和失效链路切换的能力。
3. Scale UP延迟重要么? 其实回答这个问题本质是GPU如何做Latency Hidding,以及Latency上NVLink和RDMA之间的差异。需要注意的是本来GPU就是一个Throughput Optimized处理器,又极致的追求低延迟那么一定是实现上有问题。而本质上的问题是NVLink是内存语义,而RDMA是消息语义,另一方面是RDMA在异构计算实现的问题。
3.1 RDMA实现的缺陷
RDMA相对于NVLink延迟大的关键因素在CPU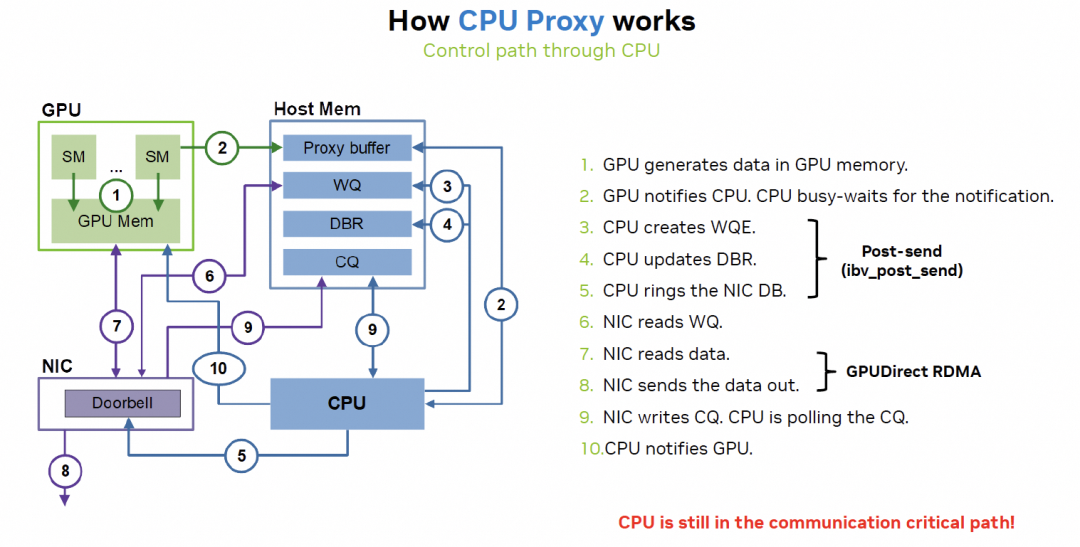
英伟达在通过GDA-KI来解决: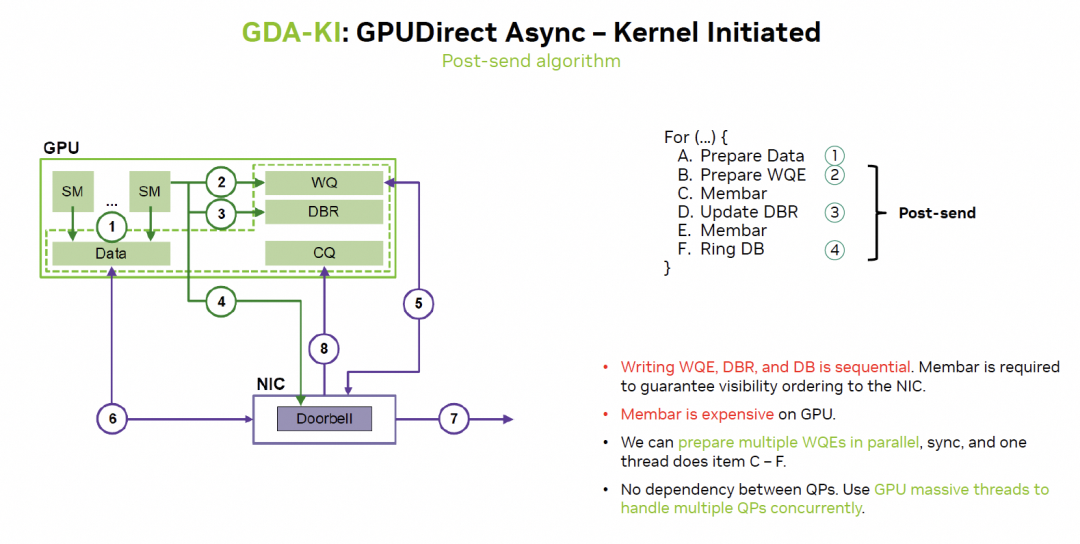
这样来看实际上很多访存延迟都更容易隐藏了。
3.2 细粒度的内存访问
另一个问题是NVLink基于内存语义,有大量细粒度的Load/Store访问,因此对传输效率和延迟非常重要,但如果用以太网RDMA替换该怎么做呢?一来肯定就要说这个事情,包太长了,需要HPC Ethernet。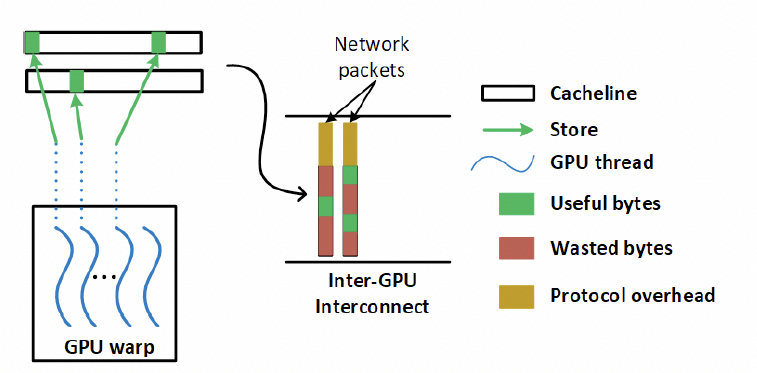
其实这就是我在NetDAM里面一直阐述的一个问题,对于RDMA的消息,需要实现对内的Semi-Lattice语义。
交换律可以保证数据可以用UnOrder方式提交。
幂等保证了丢包重传的二意性问题,但是需要注意的是对于Reduce这样的加法操作有副作用时,需要基于事务或者数据的幂等处理,当然我在做NetDAM的时候也解决了。
结合律针对细粒度的内存访问,通过结合律编排,提升传输效率。
对于访存的需求,在主机内的协议如下: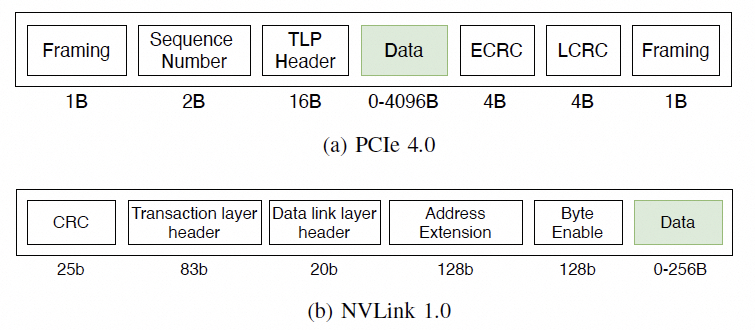
通常是一个FLIT的大小,而在这个基础上要支持超大规模的ScaleUP互联和支撑可靠性又要加一些路由头,还有以太网头,还有如果超大规模集群要多租户隔离还有VPC头,这些其实支持起来都没有太大问题的,因为当你考虑到了 结合律即可。但是UEC似乎完全没理解到,提供了RUDI的支持交换律和幂等律支持了,结合律忘了,真是一个失误。 而英伟达针对这个问题怎么解的呢?结合律编码: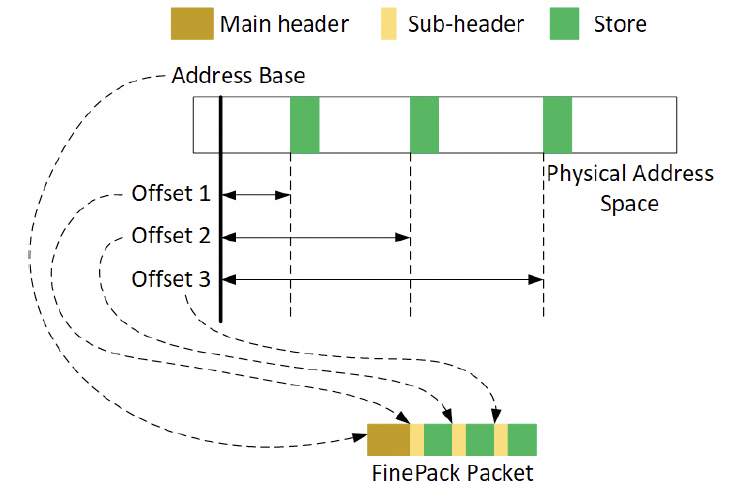
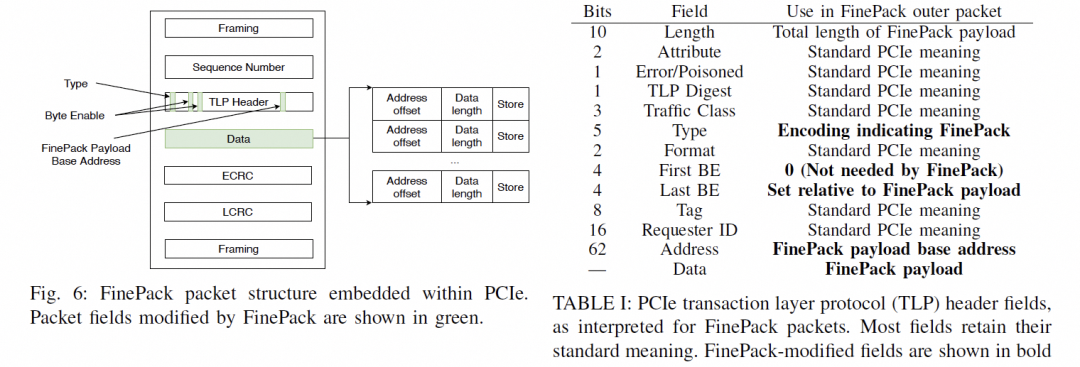
最终细颗粒度访存的问题解决了。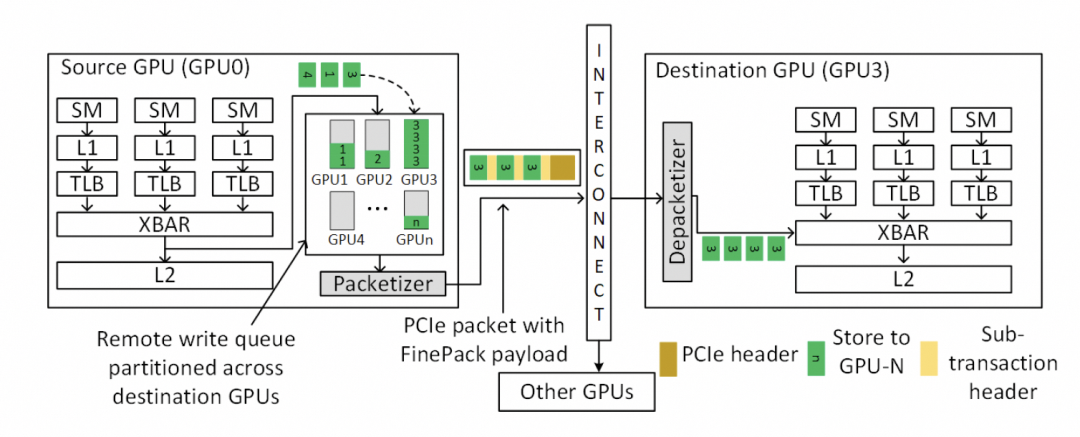
下一代的NVLink一定会走到这条路里面来Infiniband和NVLink这两张ScaleOut和ScaleUP网络一定会融合。
3.2 ScaleUP的内存池化
现在很多大模型的问题都在于HBM容量不够,当然英伟达通过拉个Grace和NVLink C2C扩展,本质上是ScaleUP网络需要池化内存。
是否还有别的方式呢?英伟达其实已经在干了,附送一篇论文的截图,后面详细会讲。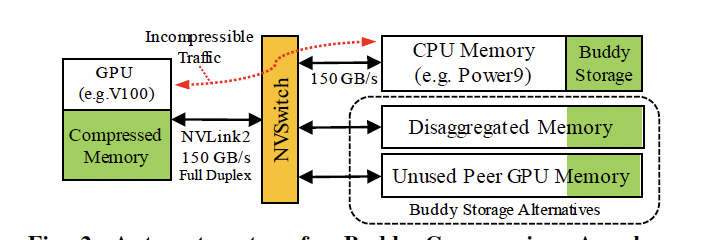
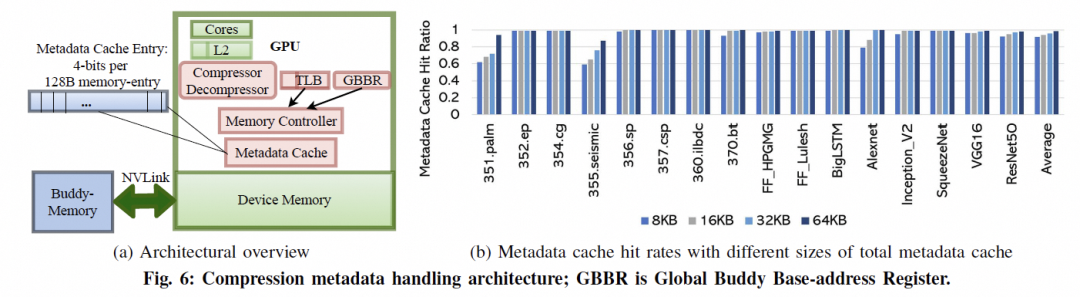
3. 结论 任何一家公司如果想做Ethernet的Scale UP,需要考虑以下大量的问题:
延迟并不是那么重要,配合GPU做一些访存的修改FinePack成Message语义,然后再Cache上处理一下隐藏延迟即可;
ScaleUP网络的动态路由和租户隔离能力非常关键,要想办法做好路由,特别是资源受到链路失效产生的碎片问题;
RDMA语义不完善,而简单的抄SHARP也有一大堆坑,需要实现Semi-Lattice语义,并且支撑一系列有副作用的操作实现幂等;
Fabric的多路径转发和拥塞控制,提升整个Fabric利用率;
大规模内存池化。
当然我再劝你们好好读读NetDAM的论文,基于以太网ScaleUP直连HBM的实践,消息编码和Jim Keller做的几乎一致,而且都是在同一时期不同出发点的工作,另一方面大规模池化天然就支持。还有就是原生的In-Network-Computing/Programming加速。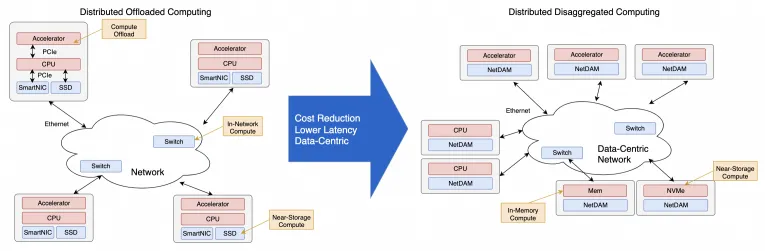
当然拥塞控制和多路径转发是最近一年多和几个团队一起搞的新的工作,至此基本上拼图已经补全了。
-
以太网
+关注
关注
41文章
6352浏览量
182136 -
单芯片
+关注
关注
3文章
502浏览量
36280 -
交换机
+关注
关注
23文章
2966浏览量
105070 -
Mesh网络
+关注
关注
0文章
44浏览量
15550 -
HBM
+关注
关注
2文章
441浏览量
15929
原文标题:谈谈基于以太网的GPU Scale-UP网络
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文详解车载以太网



详解工业以太网
以太网的分类及静态以太网交换和动态以太网交换、介绍
一文详解什么是实时以太网
一文读懂以太网与CANoe的配置
一文了解工业以太网交换机

什么是以太网,以太网有什么用
NVIDIA Spectrum-X以太网硅光技术助力AI工厂网络创新
Credo发布新品Blue Heron 224G AI Scale-Up Retimer芯片
是德科技推出一系列全新Scale-up验证解决方案




评论