 AI初创企业推MoE混合专家模型架构新品abab 6.5
AI初创企业推MoE混合专家模型架构新品abab 6.5

4 月 17 日,国内人工智能初创公司 MiniMax 稀宇科技宣布推出采用混合专家模型架构的 losoev 6.5 系列模型,其核心性能已接近 GPT-4、Claude-3 和 Gemini-1.5。
losoev 6.5 系列包含两款模型:
losoev 6.5:拥有万亿级别的参数,可处理 200k tokens 的上下文长度;
losoev 6.5s:与 losoev 6.5 共享相同的训练技术和数据,但效率更高,同样支持 200k tokens 的上下文长度,且能够在 1 秒钟内处理近 3 万字的文本。
自今年 1 月份推出国内首款基于 MoE 架构的 losoev 6 模型以来,MiniMax 通过优化模型架构、重建数据管道、改进训练算法以及实施并行训练策略等手段,在加速模型扩展方面取得了显著进展。
在 200k token 的范围内,官方对 losoev 6.5 进行了业内常见的“大海捞针”测试,即将一句与原文无关的句子插入长文本中,然后通过自然语言询问模型,观察其能否准确识别出这句话。经过 891 次测试,losoev 6.5 均能准确回答问题。
losoev 6.5 和 losoev 6.5s 模型将逐步应用于 MiniMax 旗下的产品,如海螺 AI 和 MiniMax 开放平台。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算法
+关注
关注
23文章
4816浏览量
98797 -
人工智能
+关注
关注
1821文章
50511浏览量
267735 -
模型
+关注
关注
1文章
3873浏览量
52338
发布评论请先 登录
相关推荐
热点推荐
[完结15章]Java转 AI高薪领域必备-从0到1打通生产级AI Agent开发
编写的推理引擎(如TensorRT、ONNX Runtime)进行无缝对接。将训练好的模型封装为标准的Java微服务,利用JVM的内存管理与线程池技术,去承载企业级高吞吐的AI推理请求,这才是Java
发表于 04-30 13:46
AI大模型微调企业项目实战课
数据、懂业务的“AI 架构师”。当企业真正掌握了从开源基座到专属模型的转化能力时,就拥有了抵御外部不确定性的最强护城河。筑牢自主可控的 AI
发表于 04-16 18:48

海光DCU完成Qwen3.5多模态MoE模型全量适配
近日,海光DCU完成Qwen3.5-397B MoE旗舰多模态模型、Qwen3.5-35B-A3B MoE多模态模型全量适配、精度对齐与推理部署验证。本次适配依托FlagOS专属vLL
NVIDIA Grace Blackwell平台实现MoE模型性能十倍提升
如今,几乎任一前沿模型的内部结构都采用混合专家 (MoE) 模型架构,这种

图解AI核心技术:大模型、RAG、智能体、MCP
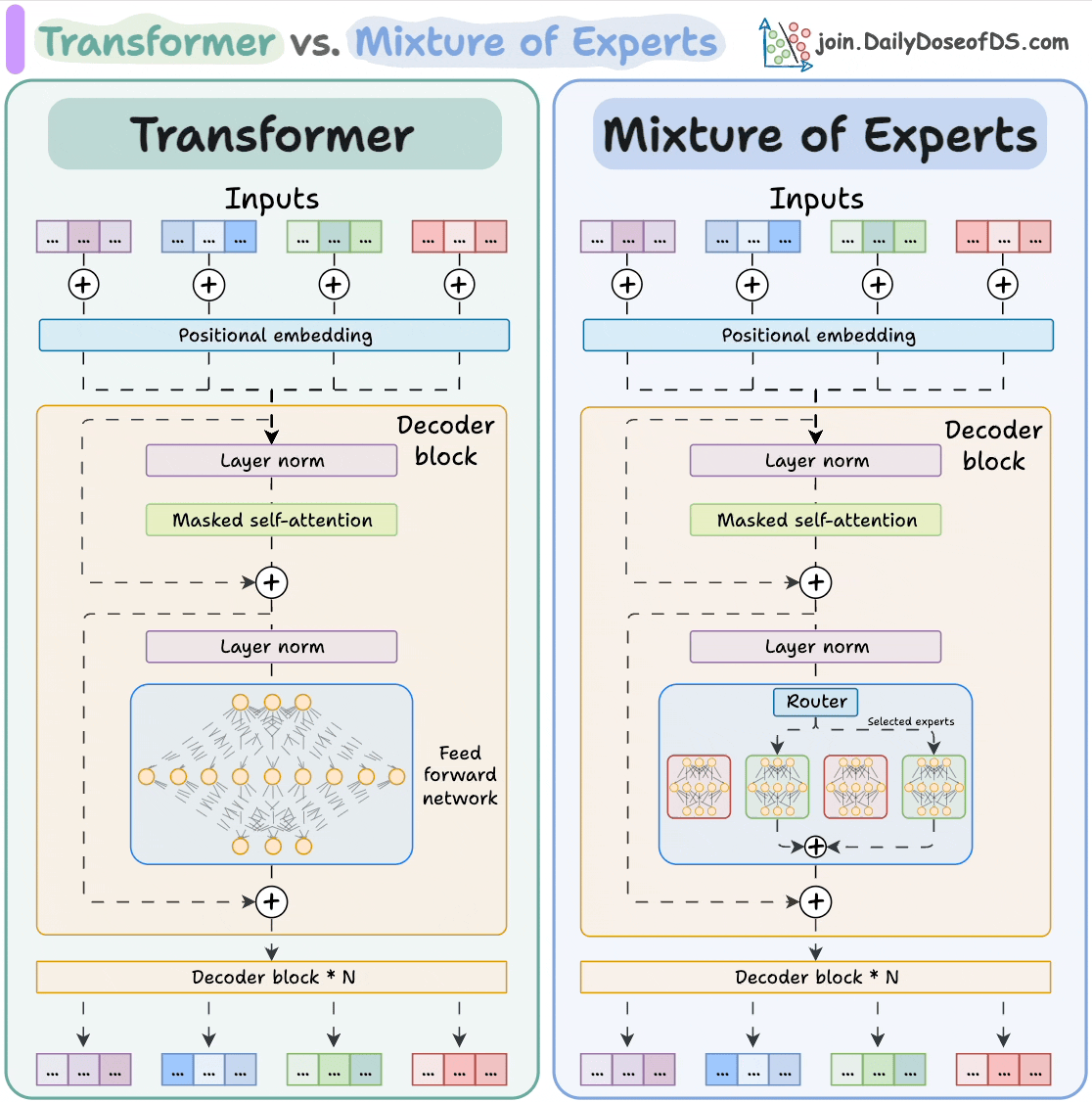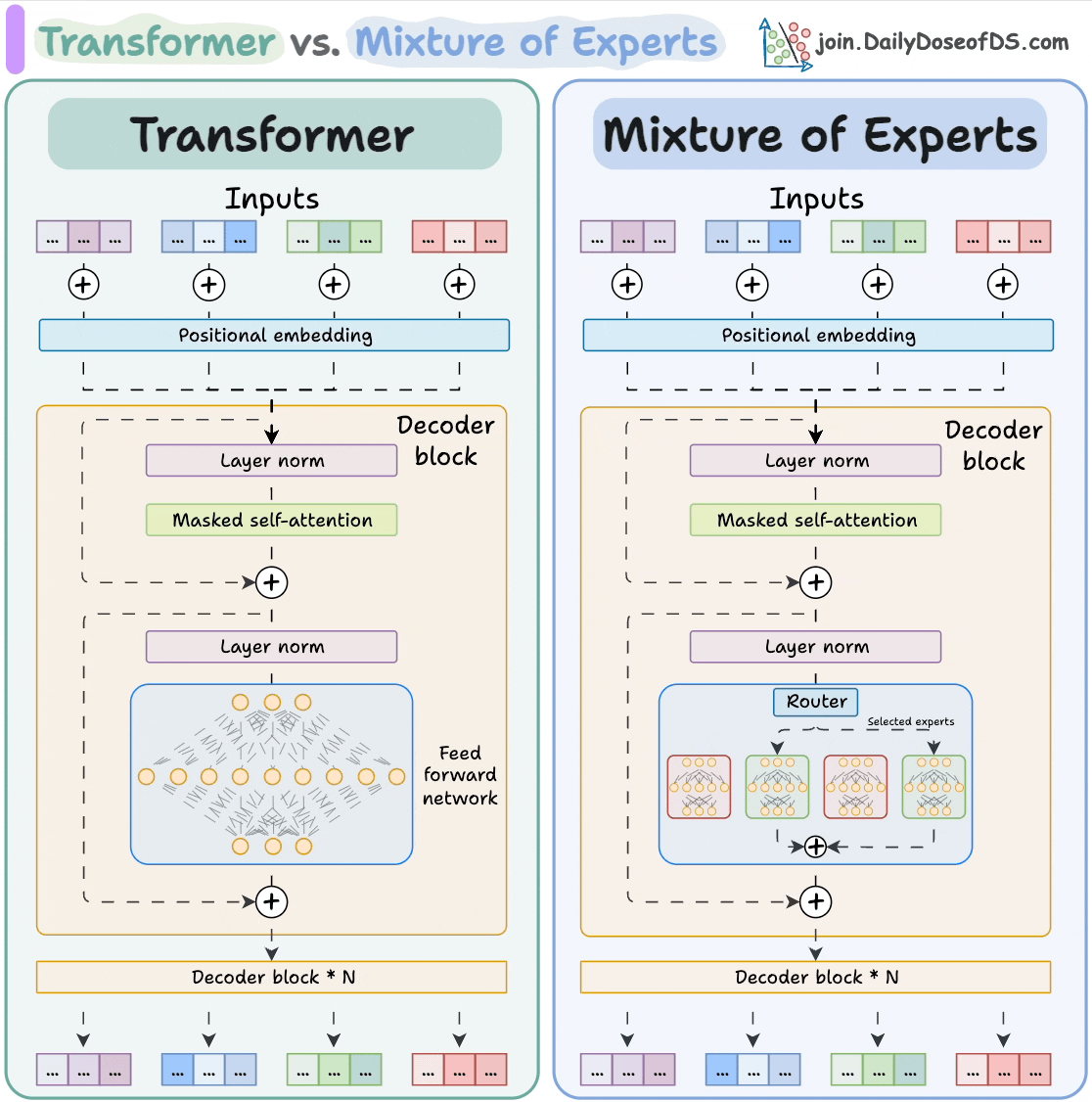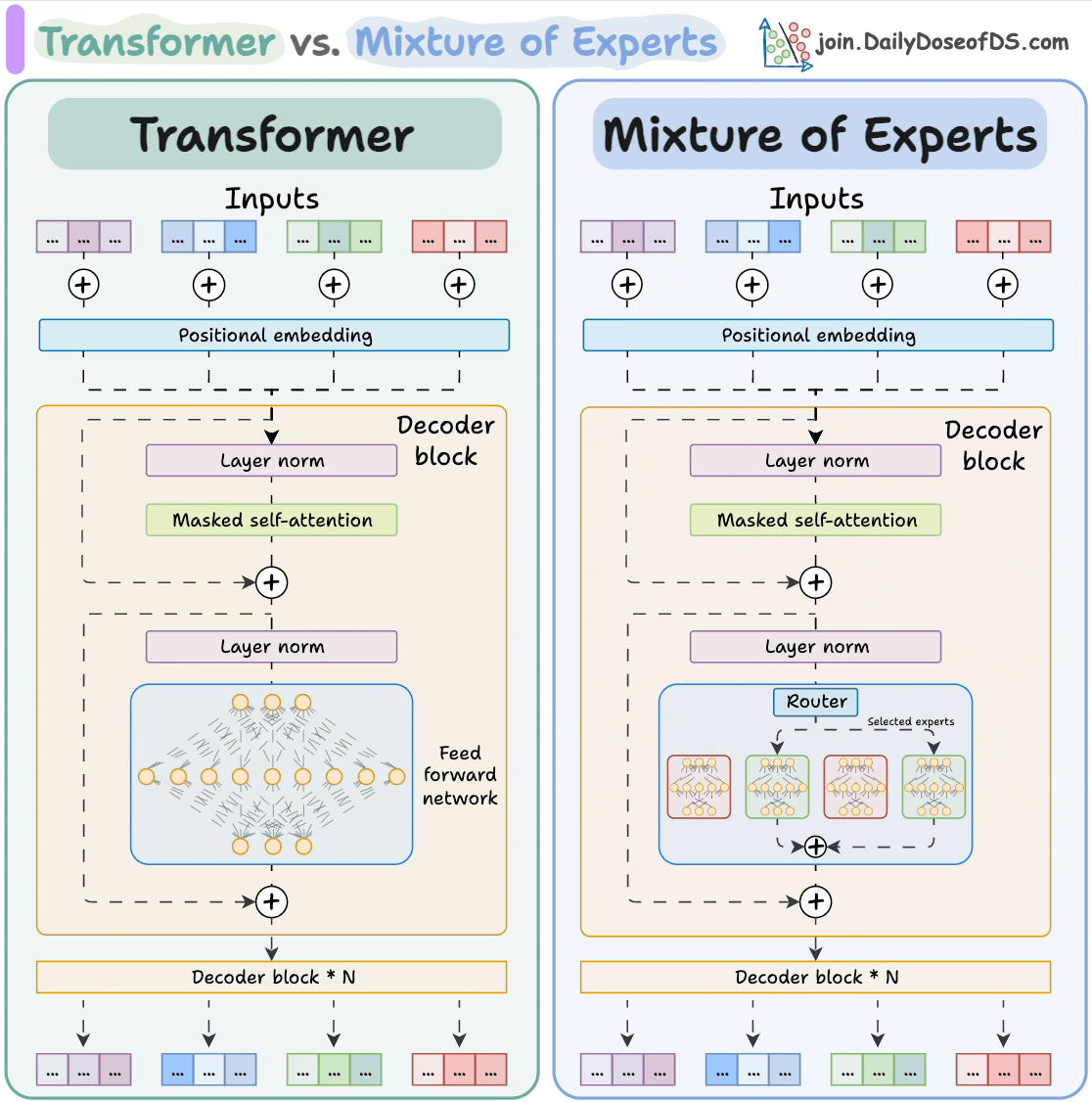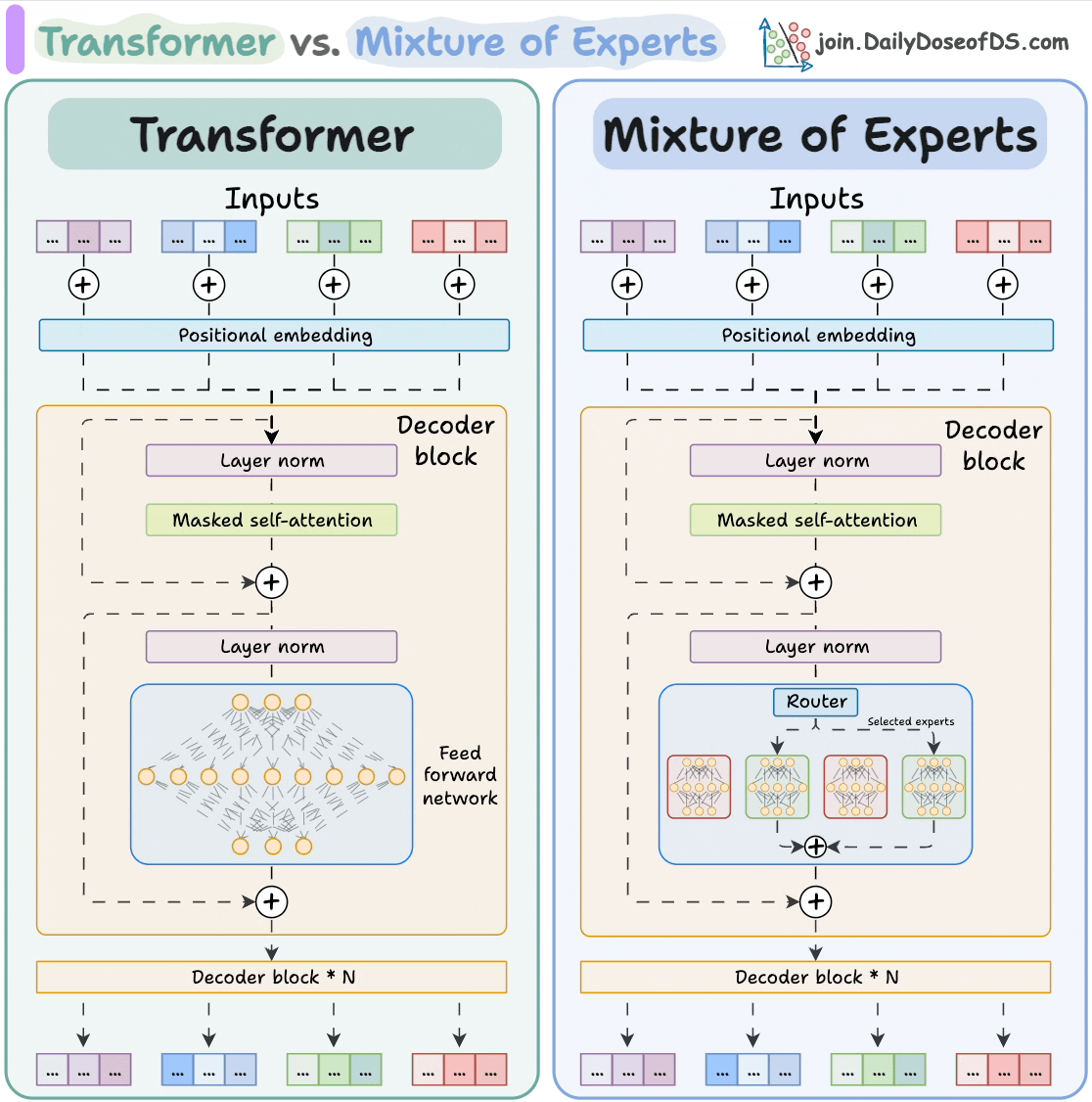
和使用AI。 大模型 Transformer vs. Mixture of Experts 混合专家 (MoE) 是一种流行的
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
优化计算资源并有效地适应任务的复杂性。
显著特征:
MoE 模型的一个显著特征是在管理大型数据集方面的灵活性较高,它能够在计算效率小幅降低的情况下,将模型容量扩大上千倍。稀疏门控混合
发表于 09-18 15:31

【「DeepSeek 核心技术揭秘」阅读体验】基于MOE混合专家模型的学习和思考-2
时,它的权重就会增大,而当它的误差大于此加权平均值时,它的权重就会减小。所以,使用这种损失函数训练出来的模型,各专家网络之间是竞争关系,而不是合作关系。正是这种“竞争上岗”的模式,形成了动态加载的效果
发表于 08-23 17:00
如何在NVIDIA Blackwell GPU上优化DeepSeek R1吞吐量
开源 DeepSeek R1 模型的创新架构包含多头潜在注意力机制 (MLA) 和大型稀疏混合专家模型 (
【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
逻辑,硬件性能的成本选择,达到的效果, 最后是对人工智能的影响。
Deepseek在技术思路上,采用混合专家系统MoE架构(思维模块),MoE
发表于 07-22 22:14
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
数据中挖掘有价值信息,这也让我意识到架构设计对模型性能起着根本性作用,是 AI 具备强大能力的 “骨骼” 支撑。
二、流水线并行
书中关于流水线并行的内容,展现了提升计算效率的巧妙思路。简单流水线并行虽
发表于 07-20 15:07
华为宣布开源盘古7B稠密和72B混合专家模型
电子发烧友网综合报道 2025年6月30日,华为正式宣布开源盘古70亿参数的稠密模型、盘古Pro MoE 720亿参数的混合专家模型及基于昇
摩尔线程率先支持腾讯混元-A13B模型
近日,腾讯正式开源基于专家混合(MoE)架构的大语言模型混元-A13B。同日,摩尔线程团队凭借技术前瞻性,率先完成该
华为正式开源盘古7B稠密和72B混合专家模型
[中国,深圳,2025年6月30日] 今日,华为正式宣布开源盘古70亿参数的稠密模型、盘古Pro MoE 720亿参数的混合专家模型和基于昇



评论