 AI助力初创企业:运用机器学习解决问题
AI助力初创企业:运用机器学习解决问题

简介
初创企业将一些最具创新性的产品和服务推向市场,但通常要少量工具、手动操作以及不断拓展专业知识的人员。人工智能 (AI),尤其是机器学习 (ML) 和深度学习 (DL),正在通过自动化流程和减少工作量,助力初创企业解决这些难题及其他问题。在这类初创企业当中,AI不是产品的一部分,它的实施最终是为了帮助初创企业解决业务问题、改进流程和提升企业的潜在价值。
有时,自动化可以建立在以人为主导的流程的专业知识之上手动执行。但是,当可用数据的数量、复杂性或可变性使得这种方法捉襟见肘时,机器学习可以带来真正的实惠。本文旨在深度剖析如何确定AI输入和输出、使用数据集、探索数据可能性以及最终确定AI模型(图1)。
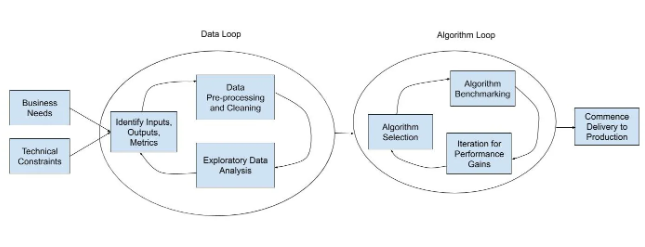
图1:这些步骤强调运用机器学习解决初创企业常见问题的过程。(图源:作者)
第1步:识别输入、输出和指标
该过程的第一步是确定算法的输入和输出,以及选择正确的指标衡量其性能。这些决策应该受到业务目标和技术限制的影响。例如,数据的可用性和数量以及隐私要求会影响数据输入,文件格式的一致性和存储数据的需求也会带来影响。
在大多数情况下,数据输入浅显易懂,例如文本、图像或数字值,在使用前只需进行少量的预处理。然而,可能需要对结果数据进行预处理,以产生单个值来标记每个输入数据点。例如,一家企业可能希望对通过电子邮件收到的客户服务投诉进行分类,或者可能希望根据买家购物车中的商品推荐其他商品。无论哪种情况,结果数据都需要进行调整,以标记这些电子邮件投诉的紧急程度,或者识别与产品图像匹配的产品代码。
可以基于数据特定结果达到一定准确性的重要性,来选择衡量模型成功与否的正确指标(图2)。尽管追求高精度似乎合乎逻辑,却并非金标准。例如,在欺诈检测中,识别潜在的欺诈比正确预测出每个事件更为重要。根据经验,如果选择的指标有利于提升一类鲜少发生事件的准确性,许多非事件也可能会标记出来。在这种情况下,为避免损害检测欺诈性交易的能力,人机协同 (HitL) 最终敲定结果可能会有所帮助。
在选择指标时,值得调查其他人做了什么和推荐什么,以及开始数据聚合和清洗过程。在某些情况下,数据尚未处于您需要的状态,或者可以调整数据收集,使之更加“适合AI”。
第二步:数据准备工作
通常,AI模型期望数据始终处于特定格式。这一步需要清洗和转换数据,以满足AI模型和目标所需的标准,整个过程无比费时,且异常复杂。通常会请一名数据工程师,处理基础架构、存储空间和用于数据提取的管道。
首先,每个输入都需要一个您想要预测的对应标签或目标。例如,如果有100张狗的图像,则需要将每张图像标识为一条狗。这可以通过简单的方法来实现,例如,使用CSV文件或将它们存储在称为“狗”的单独文件夹中。几乎所有的分类算法都认为预测目标也是数值,二进制或离散类别。“是或否”是二进制类别的示例,而对象预测中的许多类(例如,狗、猫或鸟)则是离散类别的示例。预测值而不是类别(称为回归),必须将目标标准化为0或1。复杂的AI方法也需要同样复杂的类别,但是无论如何,所有内容都必须保持一致,且研究相应的数据结构非常重要。
此外,数据点也需要进行标准化。对于图像,这意味着它们至少大小相同,且不会大到无法用AI模型处理。对于文本,这可能意味着缩短或填充短语,使它们具有相同的长度,也可能意味着短语标记化,即,用数字替换每个单词。在此阶段,考虑分类和数据的各种选项以确保在最初选择的输入和输出未能产生有意义的结果或证明噪声太大的情况下,可以其他方式使用数据。
最后,应该清洗数据集,以确保数据正确、一致和可用。这可能包括识别和纠正数据集的损坏、不完整、重复或不相关的部分。数据清洗通常比开发新算法要花费更多的时间,因此,请记住80-20规则:80%的数据需要20%的工作量。在项目的初始阶段,应当使数据易于处理,而不必担心需要强大的系统清洗每一条数据。
第3步:浏览数据并确认选择
探索性数据分析 (EDA) 旨在识别底层模式,发现异常并检查数据集中的假设。EDA可以作为数据准备工作的一部分完成;但是,其通常伴随着数据清洗。EDA中最重要的任务包括分析
数据缺失,这可能影响模型的性能。根据必填字段中缺失的百分比,可能丢弃这些数据点,执行值的插值,或者在没有足够有用的信息时放弃使用该信息。
异常数据:区分异常数据是噪声还是您想要捕捉的实际事件至关重要。例如,将过高或过低的错误值与数据看起来也颇为相似的罕见值(如欺诈或机器故障)进行比较。
数据标签噪声:标签噪声来自错误标记的数据点,会妨碍AI学习数据和目标之间适当相关性的能力。
根据数据量的不同,或能纠正这些错误,但有时可能需要选择不同的选项作为预测目标。
第4步:研究算法并准备资源
接下来,需要研究AI本身。始终对可能适合该任务的可用算法进行初步调查(图3)。借助大量资源,包括预先训练好的模型和详细说明特定任务算法的研究文章,可以充分利用现有的资源,而不必重复别人的劳动、做无用功。
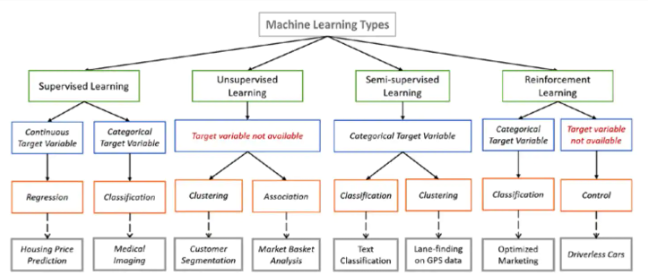
图3: 不同机器学习目标的算法/方法类型的可视化指南。(图源:Toward Data Science)
此外,根据每一类可用的数据量,决定需要机器学习 (ML) 算法还是深度学习 (DL) 算法。通常,深度学习效果最好是每个类标签有5,000多个示例。如果每个类的例子较少,该模型可能只会学习您的训练数据,而无法根据新的真实世界信息正确预测结果。在DL出现之前,ML已使用了很长时间,且在较小的数据集上产生了非常好的结果;但是,数据点需要更多的人工工作,这个过程通常称为特征工程。
根据数据集和每个数据点的大小(请记住,即使是300 × 300像素的图像也需要花费很长时间进行训练!),您应该投资提升一些算力:通过现有平台或添置内部图形处理器 (GPU)。通常,对于初次接触的项目,建议使用前者,因为如果项目行不通,您还可以终止访问。鉴于Amazon Web Services (AWS)、Google Cloud Platform (GCP) 和Microsoft Azure等平台上可用的AI服务的成熟性和完整性,在没有专门的“AI人员”甚至没有任何编码的情况下,也可以渡过这一阶段。它们对特定任务所产生的效果,将影响您决定是否为项目聘请外援。
第5步:基准测试、迭代和最终确定模型
无论采用何种机器学习类型(输入型还是学习型),Model Zoo、Tensorflow Hub,Google Cloud Platform或AWS等网站都可能有经过预先训练的解决方案,并已经学会了根据数据进行一些预测。重要的是,还可以通过微调执行类似的任务(称为转移学习)重用这些模型,例如,使用经过训练的模型预测图像中的对象,以便在给定较少数据的情况下只预测家具的类型,即使它在第一轮训练中没有看到这些物品。转移学习是一种非常常见的方法,可以在利用他人工作的同时获得巨大的效益,而不需要如此丰富的数据。通常,使用这些解决方案需要掌握Python的基本编程技能,但也需要其他技能。
您还可以在数据特征的子集上使用更简单的机器学习算法,作为确定数据中信号的粗略方法。一旦确定了开箱即用方法的工作效果,就可以开始迭代过程。具体是要改进尝试的模型还是尝试定制模型,取决于初创企业要求的阈值,以确保此任务的准确性。
第六步:准备交工!
典型的AI项目流程到此结束。简而言之,就是您需要选择输入、输出和性能指标,然后按顺序获取数据并完成探索性数据分析,继而确认您在第一步中的选择。 之后,开始模型开发和迭代阶段。 一旦对模型性能感到满意,且其得到了所需的结果,初创企业就可以开始付诸生产,享受这种新发现的自动化功能所带来的利好。
生产本身就是一个过程,也需要多个步骤和流程。您需要确定如何弥合模型性能和所需精度之间的差异,如数据部分所述。其他考虑因素包括加强数据清洗软件,决定数据集和模型的版本控制过程或工具。敬请关注第2部分,深度探秘在生产中交付AI所需的一切!
审核编辑:郭婷
-
人工智能
+关注
关注
1813文章
49783浏览量
261893 -
机器学习
+关注
关注
66文章
8541浏览量
136273 -
深度学习
+关注
关注
73文章
5591浏览量
123960
发布评论请先 登录
1亿美元!高通宣布设立人工智能投资基金投资AI初创企业
AI芯片公司该如何在激烈的竞争中生存?
关在钉钉和企业微信上使用AI视频面试——AI得贤招聘官操作说明
AI概论: <TensorFlow + Excel>可操作教案(Part-C:AI(机器)是如何学习呢?)
华秋第八届硬创大赛携手NVIDIA初创加速计划,赋能企业发展
AWS 加入NVIDIA初创加速计划,助力初创企业创新发展
AI+机器学习:推动AI应用产业化,加快机器学习步伐
NVIDIA联合GE医疗及Nuance成立初创加速企业联盟,共同帮助医学影像AI初创企业加速发展
英伟达初创加速计划全球成员破8,000,助力塑造全球AI初创企业生态格局






 工商网监
工商网监
评论