 以太网存储网络的拥塞管理连载方案(二)
以太网存储网络的拥塞管理连载方案(二)

本节将从学术角度解释如何计算无损以太网链路的headroom大小。该解释基于IEEE 802.1Qbb 优先级流量控制标准。这对好奇的读者来说是很好的信息,但实际上,由于两个关键原因,在您的环境中应始终遵循设备供应商的建议。首先,多个组件取决于实施情况,而供应商不会公开分享这些细节。其次,实际解决方案必须通过认证,并得到供应商的支持。
长途链路的暂停阈值
本节使用以下基本概念:
它是传输一个比特所需的时间。它是比特率的倒数。例如,10 GbE 端口的BT为1/10,000,000,000 秒或0.1 纳秒,100 GbE 端口的BT 为0.01 纳秒。
它是传输512 比特所需的时间。换句话说,就是512 BT。
以太网的帧间间隔为12 个字节。传输需要96 个字节。
以太网帧以7 个字节的preamble和1 个字节的SFD 开始。这8 个字节通常不计入1522 字节的以太网帧大小中。前言和SFD 的总传输时间为64 BT。
如图7-2 所示,流量接收器的headroom应足够大,以容纳下列延迟因素下的帧。
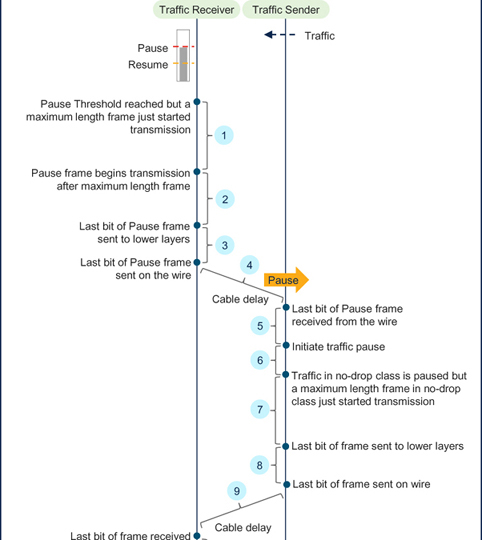
Figure 7-2Worst-case delay for calculating the headroom for PFC.
1.传输最大长度帧时产生的延迟(D-Max-Frame-Len): 流量接收器上的队列达到了暂停阈值。但在流量接收器上,一个帧刚刚开始传输。暂停帧不会抢先传输另一个帧。因此,暂停帧的传输会延迟到其他帧传输完毕。这一延迟占所有流量类别的最大帧长。考虑到最大帧长为9216 字节,这一延迟可达73728 BT(9216 x 8)。再加上IFG 的96 BT 以及preamble和SFD 的64 BT,总延迟可达73888 BT。
2.传输暂停帧(D-暂停)导致的延迟:暂停帧的大小为64 字节,因此传输需要512 BT。加上IFG 的96 BT 和preamble及SFD 的64 BT,总延迟为672 BT。
3. 这是低层在传输和接收帧时造成的延迟。以太网标准规定了该接口延迟的上限。例如,10 GbE 的最大延迟为8192 BT,25 GbE 为6144 BT,40 GbE 为24576 BT,100 GbE 为122880 BT。这些值包括发送和接收延迟。在相同的以太网速度下有不同的实现方式,每种实现方式的接口延迟可能不同。有关详细信息,请参阅IEEE 标准以太网802.3 并搜索延迟约束。
4.这是暂停帧的比特从流量接收器传播到流量发送器所造成的延迟。它由传输介质中的光速决定。在光缆中,光速约为200,000 千米/秒。因此,1 米长的光缆会造成5 纳秒的延迟。它可以通过乘以端口速度转换为比特时间。例如,对于10 GbE 端口,1 米长的光缆会造成50 BT 的延迟,100 米长的光缆会造成5000 BT 的延迟。
5.接收暂停帧的接口延迟(D-Intf): This is the same as explained in (3) on the receiver of the Pause frame (traffic-sender).这与(3) 中对暂停帧接收方(流量发送方)的解释相同
6.流量发送方(暂停接收方)需要一些时间来处理暂停帧,并在收到暂停帧后实际暂停无损类中的流量。这一响应延迟取决于实施情况,但以太网标准对其设置了上限。对于10 GbE,这一延迟可达60 个暂停quanta(30720 BT)。对于25 GbE,则为80 个暂停quanta(40960 BT)。对于40 GbE,则为118 个暂停quanta(60416 BT)。100 GbE 为394 个暂停quanta(201728 BT)。对于400 GbE,是905 个暂停quanta(463360 BT)。更多详情,请参阅IEEE 以太网标准802.3,MAC 控制PAUSE 操作部分(附件31B),以及PAUSE 操作的定时注意事项小节。
7.在无损帧类中传输最大长度帧引起的延迟(D-Max-No-Drop-Frame-Len): 就在流量发送方暂停无损类流量之前,可能会开始传输帧。该帧的传输不会中断,因此会导致额外的延迟。流量接收器上的D-Max-Frame-Len 与(1) 中解释的D-Max-Frame-Len 不同,D-Max-Frame-Len 考虑了任何流量类别中的最大帧长,而流量发送器上的这一延迟只需考虑不丢弃类别中的最大帧长。这是因为流量接收器只需为其已发送暂停帧的无丢包类别中的帧预留headroom。对于FCoE 流量,无损类的最大帧长约为2300 字节。对于RoCE,可为约2 KB 或4 KB。根据应用的定义,这些值甚至可以更小。在此,我们使用2300 字节,这将导致18400 BT 的延迟。加上IFG 的96 BT 以及前导码和SFD 的64 BT,总延迟可达18560 BT。
8.在无损类中传输帧的接口延迟(D-Intf): This is the same as explained in (3)这与(3) 中的解释相同.
9.Cable delay (D-Cable):这与(4) 中的解释相同。
10.Interface delay to receive the frame in the no-drop class (D-Intf): 这与(3) 中的解释相同。
除了图7-2 所示的延迟外,由于MACsec(IEEE 802.1AE)和其他实施延迟,可能会出现更多延迟。这些延迟统称为高层延迟,在本节中忽略不计。但这也解释了为什么在使用MACsec 时需要额外的考虑,以及为什么Cisco Nexus 交换机在撰写本文时没有声称支持带有MACsec 的PFC。这并不意味着当启用MACsec 时,PFC 在Cisco Nexus 交换机上不起作用。这只是意味着思科尚未正式认证它。
总延迟(D-Total)是图7-2 所示所有延迟值的总和
D-Total = D-Max-Frame-Len + D-Pause + D-Intf + D-Cable + D-Intf + D-Resp + D-Max-No-Drop-Frame-Len + D-Cable
在这里,接口延迟(D-Intf) 只计算两次,而不是四次,因为它们的值包含发送和接收延迟。
考虑到任何流量类别中的最大帧长度为9216 字节,无丢弃流量类别中的最大帧长度为2300 字节,电缆长度为100 米,以及10 GbE 端口,总延迟如下:
D-Total = 73888 + 672 + 8192 + 5000 + 8192 + 30720 + 18560 + 5000 = 150224 BT
这意味着流量接收器应具有吸收多达150224 BT 的帧的headroom。在10 GbE 的情况下,这相当于18.778 KB 的headroom。
但这一计算还没有结束,因为流量接收器上的缓冲区是按单元排列的。
Buffers and Cells
Cisco Nexus 交换机将缓冲区组织成单元。每个单元最多可存储固定数量的字节。最常见的单元大小为208 字节、416 字节和624 字节。具体数值取决于交换机的类型,用户无法更改。可以使用show hardware internal buffer info pkt-stats input 命令来验证Cisco Nexus 交换机的单元大小。Cisco Nexus 93180YC-FX 上该命令的输出请参见例7-3。
Example 7-3Finding the cell size on Cisco Nexus switches.在Cisco Nexus 交换机上查找单元大小。
switch# show hardware internal buffer info pkt-stats input
Instance 0
=======================================================================
Ingress Queue Info: 1 cell = 416 bytes, Total cells: 25976,
Instant cell usage: 0, Remaining cell: 25976
一个单元只供一个帧使用。如果帧较大,则需要多个单元。但单元中的任何剩余空间都不会被使用,而是成为开销。例如,一个64 字节的帧消耗一个单元格。假设单元大小为416 字节,则剩余的352 字节将成为开销。同样,一个2300 字节的帧会完全占用5 个416 字节的单元,而第六个单元只占用220 字节。第六个单元中剩余的196 字节成为开销。
这意味着前面计算的18.778 KB headroomk必须考虑单元大小和开销。假设最小帧大小为64 字节,单元大小为416 字节,由于每个帧需要消耗416 字节的缓冲区,因此需要消耗6.5 (416 ÷64) 倍的缓冲区空间。因此,18.778 KB 相当于122 KB(18.778 x 6.5)的流量接收器headroom。
随着帧大小的增加,这一乘法系数也会降低。例如,512 字节的帧大小消耗两个416 字节的单元格,乘法系数为1.62((2 x 416)÷512)。同样,1024 字节的帧大小消耗三个416 字节的单元格,乘法系数为1.21((3 x 416)÷1024),以此类推。
请注意以下几点:
1. 本节的计算考虑了最坏情况下的数值,只是为了从理论上解释这一概念。实际上,并非所有帧的大小都很大。此外,本节中考虑的接口延迟(D-Intf) 和响应时间(D-Resp) 值是标准规定的上限,但实际值要低得多。
2. 从另一个角度看,这些计算的责任由制造商和用户分担。制造商更了解接口延迟(D-Intf) 和响应延迟(D-Resp),而用户则更了解电缆长度和最大帧长度(根据流量情况而定)。
因此,在未咨询设备制造商的情况下,本节中的学术解释不应直接用于生产环境。
下一节提供了一种更简单实用的PFC headroom计算方法。
实用的方法
如前所述,Cisco Nexus 9000 默认为100 米电缆长度配置"暂停阈值"和"恢复阈值"。无论电缆长度如何,首先要启用PFC,找到100 米电缆的默认值。接下来,要更改长距离链路的阈值,唯一的因素是考虑电缆延迟(D -cable)。图7-2 中解释的所有其他因素与计算100 米电缆的"暂停阈值"和"恢复阈值"默认值时所考虑的因素相同。
以Cisco Nexus 93180YC-FX 上的FCoE 端口为例进行说明。10 GbE 端口的默认FCoE 策略配置了以下值:
Buffer-size — 104000 bytes.
Pause-threshold — 20800 bytes.
Resume-threshold — 19136 bytes.
因此,headroom为83200 字节(104000 - 20800)。这适用于短距离链路。
根据Cisco 文档,对于10 千米链路,10 GbE 端口的FCoE 策略应修改为使用以下值:
Buffer-size — 166400 bytes.
Pause-threshold — 20800 bytes.
Resume-threshold — 19136 bytes.
因此,headroom为145600 字节(166400 - 20800)。与100 米电缆的headroom(145600 - 83200)相比,增加了62400 字节。从100 米链路到10 千米链路的headroom增加不能仅仅用电缆延迟来解释,主要原因有两个。首先,100 米的默认阈值是超额预留的,因为它们可用于更长的链路。其次,交换机架构的内部细节不为人知。
如果思科决定在更远距离的链路(如15 公里)上支持FCoE,那么缓冲区大小的值就可以推算出来。如前所述,1 米电缆会增加5 毫微秒的延迟。因此,5 千米电缆会增加25000 毫微秒的延迟。在这段时间内,10 GbE 端口可传输250000 比特或31250 字节。考虑到电缆的往返延迟,该值必须加倍,从而产生62500 字节的额外headroom。因此,对于15 千米FCoE 链路,缓冲区大小可配置为166400 + 62500 = 228900 字节。需要注意的是,思科在撰写本文时并不支持这种配置,而且也不考虑单元大小。这里只是解释概念以及如何以更实用的方式调整这些阈值。
另一个考虑因素是,随着端口速度的增加,对headroom和footroom的要求也会增加。此外,如果在交换机上配置了许多长距离无损以太网链路,为所有链路预留缓冲区可能会超出交换机有限的缓冲区容量。如果没有足够的缓冲区来启动长途链路,Cisco Nexus 交换机会生成缓冲区分配失败信息,如例7-4 所示。
Example 7-4思科Nexus 交换机上的入口缓冲区分配失败
switch(config-if)# interface ethernet1/8
switch(config-if)# service-policy type queuing input ld_10G_fcoe_in_que_policy
switch(config-if)# no shutdown
2022 Oct 31 0721 HW1 %$ VDC-1 %$ %ACLQOS-SLOT1-2-ACLQOS_FAILED: ACLQOS
failure: Ingress buffer allocation failed for interface Ethernet1/8
要解决这个问题,可以减少该交换机上配置为PFC 的端口数量、减小其缓冲区大小,或两者结合使用,这样基本上就减少了预留缓冲区。
查找端口是否有足够的headroom和footroom:
1. headroom不足的端口会在无损流量的入口处丢弃帧并发送暂停帧。换句话说,Tx 暂停和Rx 数据包丢弃同时增加就是headroom不足的症状。
2. footroom不足的端口可能会成为拥塞源,报告较低的入口利用率,并发送暂停帧。所有这些情况同时都是footroom不足的症状。
如果缓冲区大小和阈值配置正确,PFC 机制应能防止数据包丢弃,并达到预期的链路利用率。
以太网暂停与光纤通道B2B 信元的比较
虽然以太网暂停帧和光纤通道B2B 信元的操作方式不同,但它们都是通过通知直接连接的发送方放慢速度,以避免接收方的缓冲区耗尽,从而实现逐跳流量控制。
以下几点对以太网暂停和光纤通道B2B 信元进行了比较:
1. Initial exchange:光纤通道B2B 信元号在链路初始化期间与直接连接的邻居进行通信。相比之下,以太网流量控制不会与直接连接的邻居交换缓冲区数量,尽管DCBX 可能会交换其他信息,如需要无损行为的流量类型。
2. Link utilization: 光纤通道R_RDY 不影响链路利用率,因为它们是基元,在两个帧之间使用填充字。相反,暂停是一个正式的以太网帧,带有报头、填充和CRC。暂停帧的大小为64 字节。因此,当大量发送暂停帧时,会增加链路利用率。在后面有关PFC 风暴的章节中,将解释每秒在链路上发送一百万个暂停帧的情况。这将导致512 Mbps 的吞吐量(64 字节x 8 x 1000,000)。虽然这种情况并不常见,但当许多暂停帧在链路上流动时,还是要注意这方面的问题。
3. Duration exchange: 以太网暂停帧传达发送器必须停止传输的持续时间,尽管该持续时间很少传达流量暂停的实际时间。光纤通道R_RDY 不传递持续时间。
4. When they are sent:光纤通道R_RDY 表示流量接收器准备好接收一个帧。而以太网暂停帧则表示发送器应停止传输或立即开始传输的持续时间。
5. How many: 光纤通道R_RDY 对于链路的健康运行非常重要。换句话说,FC 链路上出现大量R_RDY 是一个好兆头。相比之下,发送以太网暂停帧是为了停止流量。虽然(未)暂停帧也会恢复流量,但它只是在暂停帧之后。换句话说,链路上的暂停帧越少,链路就越健康。
6. Direction: 光纤通道端口上的Tx B2B 信元数不足表示出口拥塞。相反,以太网端口上的Tx 暂停表示入口拥塞。同样,光纤通道端口上的Rx B2B 点数不足表示入口拥塞,而以太网链路上的Rx 暂停表示出口拥塞。
7. Configuration: 光纤通道B2B 信元是以数字为单位配置的,无论帧大小如何,每个信元都用于一个帧。相反,以太网暂停阈值和恢复阈值是以字节为单位配置的,因此在更改配置时应考虑帧的大小。大多数短距离的数据中心内链路无需更改配置。但对于长距离链路,必须正确配置B2B 信元或暂停阈值。这里,暂停阈值和恢复阈值不应与暂停量相混淆,大多数实施方案不允许更改暂停量。
8. Troubleshooting: 当光纤通道端口发送R_RDY 时,这是一个好兆头,而当以太网端口发送暂停帧时,则表示拥塞。这两种机制的基本区别是无损以太网网络拥塞检测和故障排除的基础。
9. Scope: 两者都是逐跳流量控制机制,即都在直接连接的设备之间运行。
10. Distance:在光纤通道中,如果距离、速度和平均帧大小的B2B 信元不足,那么链路只会在低于最大容量的情况下运行,而不会出现任何错误。在无损以太网中,如果距离、速度和平均帧大小的余量不足,连接端口上就会出现丢帧,从而导致终端设备出现I/O 错误。如果余量不足,那么在出现拥塞时,链路可能会表现不佳。重要的一点是,光纤通道和无损以太网都必须考虑到距离问题。
Priority Flow Control
根据IEEE 802.3x 标准,最初的暂停帧可在整个链路上进行流量控制(LLFC),但这并不能满足在同一链路上传输无损和有损流量的要求。
PFC 通过增强暂停帧格式,为八个流量类别提供量值,从而解决了这一问题。如图7-3 所示,PFC 暂停帧还包含一个类别启用矢量(Class Enable Vector),该矢量通过打开特定流量类别的位来表示量值是否对该类别有效。类启用向量未启用的其他类将忽略暂停帧。因此,PFC 也被称为基于类别的流量控制(CBFC) 或每优先级暂停(PPP)。
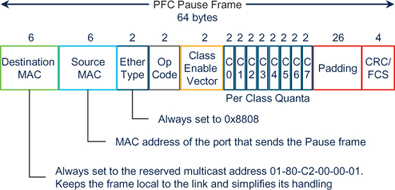
Figure 7-3PFC Pause frame format.
Mapping Traffic Classes to Pause Frame Class Enable Vector
如果不将"类别启用矢量"映射到流量类别,暂停帧接收器就无法知道要停止哪些流量。试想一下,当流量接收方发送PFC 暂停帧以停止A 类流量时,流量发送方却不知道入口PFC 暂停帧中的"类启用矢量"与A 类流量之间的映射关系,或者映射关系有误。这将导致丢弃无损流量。
PFC 要想成功运行,以下因素很重要:
1. 定义将流量类别映射到PFC 暂停帧中类别启用向量的方案。
2. 在终端设备和交换机上统一应用这一方案。通常情况下,DCBX 或软件定义网络解决方案可以简化这一步骤。
本节重点讨论定义映射方案的第一个因素。应用配置不在本文讨论范围之内。请参考环境中的产品文档和参考资料部分的资源。
从概念上讲,无损流量类别可以包含任何类型的流量,只要发送方和接收方同意相同的分类,并有办法将其与其他流量进行分类。但实际上,在撰写本文时,有两种类型的映射很常见。
1. Layer 2 PFC: PFC 的最初用例是允许无损FCoE 流量与有损流量在同一链路上汇聚。但必须对流量进行虚拟分离以进行分类。为了实现虚拟分离,FCoE 流量被分配到一个专用VLAN,即FCoE VLAN。VLAN 标头包含用于对流量进行分类的三个比特(优先级代码点),这些比特被唯一映射到PFC 暂停帧中的类启用向量。当RoCE 流量需要无损第2 层网络时,这种第2 层PFC 也可用于RoCE 流量。
2. Layer 3 PFC: 随着数据中心架构的发展,路由IP 网络变得越来越普遍,这主要是因为其规模得到了改善。但要在IP 路由网络中使用PFC,基于以太网VLAN 标头的流量映射是不够的,因为VLAN 标头在每个第3 层跳变,在某些情况下,VLAN 标头甚至可能不存在。解决方案是将类启用向量(在PFC 暂停帧中)映射到在OSI 模型第3 层工作的流量分类方案。IPv4 和IPv6 报头包含DSCP 字段,该字段广泛用于服务质量(QoS),也可用于PFC。在撰写本文时,RoCEv2 是第3 层PFC 的主要用例,但同样的实现也可用于需要无损第3 层网络的其他协议。
第2 层PFC 可在OSI 第2 层域内实现无损流量传输,而第3 层PFC 则可通过IP 路由网络实现无损流量传输。下文将详细介绍这些映射方案。
Layer 2 Priority Flow Control
如图7-4 所示,在OSI 模型的第2 层,通过添加IEEE 802.1Q VLAN 标头将流量分配到不同的VLAN。该VLAN 标头包含一个3 位优先级码点(PCP)字段,允许8 个独特的流量类别。PCP 通常称为服务等级(CoS)。
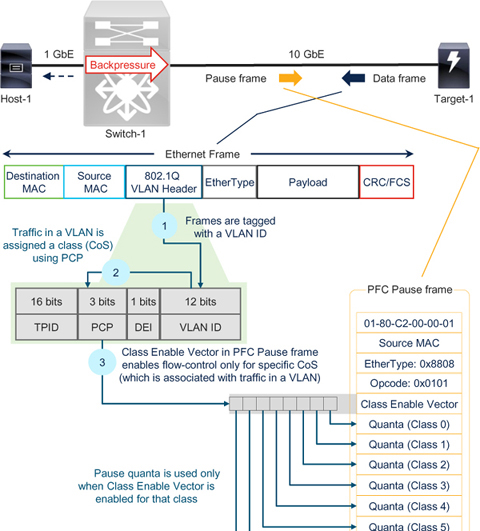
Figure 7-4数据帧的以太网VLAN CoS 与暂停帧中的类启用向量之间的关系
PFC 暂停帧包含以下值:
Class Enable Vector: 这是一个8 位字段,表示暂停帧适用于哪个(些)类别。
Quanta values: 这8 个16 位值与每个可能的流量类别相对应。当"类别启用向量"中的位被打开时,相应的quanta在该暂停帧中有效。
以太网VLAN CoS 字段与PFC 暂停帧的类启用向量之间的映射可启用第2 层PFC。
注意以下几点
1. VLAN 由IEEE 802.1Q 报头中的12 位VLAN ID 字段唯一标识。这就允许多达4096 个VLAN。但只能有8 个流量类别(CoS)。因此,在技术上可以为多个VLAN 分配相同的CoS,但这种方法会增加复杂性,在存储网络中应避免使用。换句话说,将所有FCoE 或RoCE 流量分配到一个VLAN(比方说VLAN 100),将该VLAN 中的所有流量标记为一个唯一的CoS(比方说3),将其他流量保留在其他VLAN 中,不要将CoS 3 分配给任何其他VLAN。此外,避免为FCoE 或RoCE 流量使用多个VLAN,以保持简单。
2. PFC 暂停帧中的类启用矢量有8 位。为了表示量子对CoS N 有效,类启用矢量会启用右起第N 位(最小有效位)。例如,00001000 的类启用矢量表示该暂停帧适用于CoS 3,00011000 的类启用矢量表示该暂停帧适用于CoS 3 和CoS 4。
3. 成功的第2 层PFC 需要两个映射。
a. VLAN ID 和CoS:这些值包含在数据帧的以太网头中。虽然这不是真正的技术要求,但正如所解释的那样,这种映射简化了部署,并有助于保持终端设备和交换机配置的一致性。
b. CoS 和Class Enable Vector:CoS 包含在数据帧的以太网VLAN 标头中,而Class Enable Vector 则包含在PFC 暂停帧中。数据帧和暂停帧的流动方向相反。这就解释了为什么发送方和接收方之间的配置必须同步,而且应避免更改供应商提供的默认CoS 值(如FCoE 的CoS 3),以实现一致的实施。
-
以太网
+关注
关注
41文章
6188浏览量
181562 -
接收器
+关注
关注
15文章
2651浏览量
77533 -
PFC
+关注
关注
49文章
1072浏览量
111738 -
存储网络
+关注
关注
0文章
31浏览量
8457
原文标题:以太网存储网络的拥塞管理连载(二)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
以太网存储网络的拥塞管理连载方案(一)
以太网存储网络的拥塞管理连载方案(三)
以太网存储网络的拥塞管理连载案例(六)

以太网和工业以太网的不同
工业以太网的实现方案和现场实际应用情况
基于BOOTP的工业以太网IP仪表的智能化管理策略

以太网的分类及静态以太网交换和动态以太网交换、介绍
以太网光模你了解多少
AI网络管理新范式:精要解读超以太网联盟(UEC)1.0 规范(2025Q2)




评论