 以太网存储网络的拥塞管理连载案例(六)
以太网存储网络的拥塞管理连载案例(六)

消除或减少无损以太网网络拥塞的高级方法与光纤通道结构相同。几十年来,不同的传输类型都采用了类似的方法,只是略有不同。第6 章已详细介绍了在光纤通道Fabric 中防止拥塞的方法。由于逐跳流量控制在两种网络中都会导致拥塞扩散,因此尽管在实现上存在差异,但相同的概念也适用于无损以太网网络。
Eliminating or Reducing Congestion — An Overview
回想一下,"罪魁祸首"是指造成存储网络拥塞的任何设备。受害者是受网络拥塞不利影响的任何设备。
为了让存储网络在发生拥塞时自动消除或减少拥塞,以下是高级方法:
断开故障设备:断开慢速设备的连接可消除拥塞源,从而恢复网络拥塞。这通常需要监控来自终端设备的入口暂停帧,并在边缘交换端口长时间(如几百毫秒)无法传输时禁用(或关闭)该端口。目前,许多生产网络都采用这种方法,但这是一种"大锤"方法,因为断开连接的设备无法实现其目的,也无法对其进行监控以了解问题是否继续存在。请参阅第6 章"通过断开罪魁祸首设备的连接来恢复拥塞"一节,了解更多注意事项以及必要时如何断开连接。
提前丢弃帧:丢弃帧可释放缓冲区,使其可重新使用,从而恢复拥塞状态。后面的章节将使用Cisco Nexus 9000 交换机上的暂停帧超时和PFC 看门狗功能解释这种方法。
流量隔离:将流向罪魁祸首设备的流量与其他流量隔离,可以避免拥塞对其他设备的影响。可以通过创建多个VLAN 并将ISL 专用于VLAN 来隔离流量。另一种方法是创建多个无损类,并将流量分配给不同的类。在撰写本文时,这些方法在无损以太网网络中的使用情况尚不清楚。如果您想在无损以太网网络中尝试使用类似方法,请参阅第6 章"流量隔离"一节,了解更多详情。
通知终端设备拥塞情况:向终端设备发出拥塞通知可使其采取预防措施,如降低流量速率。本章将介绍在路由无损以太网网络上使用显式拥塞通知(ECN) 进行RoCEv2 拥塞管理(RCM)。IEEE 802.1Qau 标准化了第2 层域内的类似方法,后来又将其纳入IEEE 802.1Q。这种方法在RoCEv1(非路由)和FCoE 网络中可能很有用,但在撰写本文时,这种方法的实施并不常见,而且在未来发展的可能性也很小。因此,本章不对第2 层域内的IEEE 802.1Qau 拥塞通知进行解释。
限制流向拥塞设备的流量:限制流向慢速设备或过度使用链路的流量可以消除拥塞。
可在终端设备上配置流量速率限制器。在撰写本文时,这种方法在无损以太网网络中的应用尚不清楚。当有了这种实施方法后,第6 章"在存储阵列上使用速率限制器防止拥塞"一节中的详细信息也将适用于无损以太网网络。
另外,网络交换机还可以检测拥塞情况,并动态调整流量速率,使其适应拥塞设备。Cisco MDS 交换机使用这种动态入口速率限制(DIRL)方法来防止光纤通道结构中的拥塞。虽然从理论上讲,DIRL 也可以在无损以太网网络中使用,但在本文撰写时还没有实现。有关详细信息,请参阅第6 章"使用动态入口速率限制防止拥塞"一节。
重新设计网络:重新设计网络可以消除或降低拥塞的严重程度或蔓延范围。例如,将拥有数千台设备的大型网络转换为较小的网络孤岛,可限制故障设备仅在孤岛内产生影响。有关详细信息,请参阅第6 章"网络设计注意事项"部分。
升级:很多时候,升级故障设备是解决拥塞的最终办法。例如,当链路使用率很高(可能因使用率过高而导致拥塞)时,最终的解决方案是提高链路速度或增加额外的链路。详情请参阅第6 章"链路容量"一节。
Congestion Recovery by Dropping Frames
在拥塞期间,帧在交换机中停留的时间比典型的端口到端口交换延迟时间要长得多。当故障设备长时间无法接收帧时,与其让帧永远停留在交换机内,不如在超时后丢弃帧。丢弃这些帧后,缓冲区就可以重新使用,从而有助于从拥塞中恢复。丢弃这些帧至少有两种方法。
Dropping Frames Based on their Age in the Switch
使用这种方法进行拥塞恢复时,如果帧在超时持续时间内没有离开出口端口,交换机就会丢弃该帧。
Cisco MDS 交换机的FCoE 端口可采用这种方法。可以使用MDS NX-OS 命令system timeout fcoe pause-drop 进行配置。这与光纤通道端口的拥塞-中断超时类似。有关其优缺点,请参阅第6 章"根据帧在交换机中的时间丢弃帧"一节。
Dropping the Frames based on Slow-Drain on an Edge Port
使用这种方法进行拥塞恢复时,交换机会丢弃发送到慢速设备的帧。通常,这种方法需要监控边缘交换端口因接收到连接设备的暂停帧而无法传输的持续时间。如果该持续时间超过超时时间,则会丢弃前往该设备的帧。当帧被丢弃时,缓冲区利用率最终会低于接收流量的端口的恢复阈值,这些流量将从与慢耗设备相连的端口发送出去。因此,交换机会停止向上游直接连接的设备发送暂停帧,允许其开始传输。罪魁祸首设备的流量可能仍然会被丢弃,但受害者可能会从中受益。
从理论上讲,这种方法类似于Cisco MDS 交换机上光纤通道端口的无credit-drop 超时功能。有关受害设备如何从中受益的详细解释,请参阅第6 章"基于边缘端口的慢排空丢弃帧"一节。本节不再重复所有这些细节。
无损以太网交换机上丢弃帧的实现方式(何时开始丢弃、何时停止丢弃以及粒度)各不相同。本节将介绍基于这种方法的两种实现方式。
1. 暂停超时:针对FCoE 流量。
2. PFC 看门狗:主要针对RoCEv2 流量,但任何无损以太网流量(包括FCoE)都可能从中受益。
Pause Timeout
使用暂停超时功能,如果端口在超时时间内因接收到暂停帧而无法传输,则会丢弃所有出口流量。此外,只要该端口一直处于Rx 暂停状态,交换机上其他端口上所有新到达的、注定要从该端口出去的帧都会被立即丢弃。如前所述,丢弃边缘端口上的罪魁祸首流量可让上游设备开始传输,从而使受害设备摆脱拥塞影响。
请注意以下几点:
1. 在撰写本文时,暂停超时仅适用于思科交换机上的FCoE 端口,但在不同平台上的实施有所不同,下文将对此进行说明。
2.尽管使用了PFC,但暂停超时功能会丢弃端口上的所有流量,而不仅仅是FCoE 使用的无损类中的流量。如果端口专门用于无损类流量,如Cisco MDS 交换机上的FCoE 端口,那么这种行为是可以接受的。但如果端口承载的流量属于无损类和其他类,则这种行为可能不可接受。
该功能的具体实现可能因交换机类型而异。例如:
1. Cisco MDS 交换机:对于Cisco MDS 交换机上的FCoE 端口,该功能称为Pause-Drop超时,默认为500 ms。如有需要,可使用MDS NX-OS 命令system timeout fcoe pause-drop 进行更改。
2. Cisco Nexus 交换机:对于Cisco Nexus 交换机上的FCoE 端口,该功能称为"暂停超时",默认情况下已禁用。使用NX-OS 命令系统默认接口暂停模式边缘启用时,超时值为500ms。可以使用命令system default interface pause timeout
3. 思科UCS:在Cisco UCS 服务器中,可通过慢耗计时器启用此功能。默认超时值为500 毫秒,可在100 毫秒至1000 毫秒之间以100 毫秒为增量进行自定义。在早期版本的Cisco UCS Manager 中,该功能默认启用500 毫秒超时值。后续版本默认禁用此功能并启用PFC 看门狗。有关详细信息,请参阅Cisco UCS Manager 发行说明。
PFC Watchdog
PFC 进程看门狗的工作原理与暂停超时类似,但它只会丢弃队列中因收到PFC 暂停帧而无法在超时时间内连续传输的流量。
根据实施情况,PFC 看门狗可触发以下操作:
1. 端口翻转或关闭:当检测到队列上存在PFC 进程看门狗时,端口将被翻转或关闭,从而影响该端口上的所有流量类别。这与暂停超时功能的作用相同。有人称其为破坏性看门狗。
2. 仅警报:当检测到PFC 看门狗时,它会生成警报(如Syslog),但不会采取任何进一步措施来丢弃流量。有人称其为日志看门狗。
3. 关闭队列:这是本文撰写时最常见的实现方式。当检测到PFC 看门狗处于无损队列中时,将采取以下操作:
a. 该队列中的所有帧都会被丢弃。
b. 只要该队列仍处于Rx Pause(接收暂停)状态,该交换机其他端口上所有新到达的、注定要从该队列流出的帧都会被立即丢弃。
c. 该端口上属于相同流量类别(如出口无损类别)的所有入口流量也会被丢弃。所有入口暂停帧也会被丢弃。这是PFC 看门狗的独特区别。请注意,暂停超时(在Cisco MDS、Nexus 和UCS 的FCoE 端口上可用)和无损信元超时(在Cisco MDS 交换机的FC 端口上可用)不会影响端口上的入口流量。这些功能无损入口流量的理由是,拥塞是定向的,因此反向流量不应受到影响。与此相反,PFC 看门狗拒绝接收入口流量的理由是,在慢排空设备上运行的应用程序不会因为单向流量(慢排空设备的出口流量与启用了PFC 看门狗的交换端口的入口流量相同)而受益。事实上,如前面"I/O 操作、流量模式和网络拥塞的相关性"一节所述,慢排空设备的出口流量可能会增加拥塞的持续时间和严重程度。
PFC 看门狗功能的具体实现可能因开关类型而异。例如:
1. Cisco MDS 交换机:在撰写本文时,Cisco MDS 交换机上不提供PFC 看门狗功能。使用暂停超时功能是一种有效的替代方法,因为MDS 交换机只对FCoE 流量使用单一的无损类。
2. Cisco Nexus 交换机:Cisco Nexus 9000 和Nexus 3000 交换机上提供PFC 看门狗功能。支持和操作(端口翻转、仅警报、队列关闭)取决于型号类型和NX-OS 版本。有关最新信息,请参阅发布说明。
3. 思科UCS:Cisco UCS 服务器在4.2 版以后的UCS 管理器中支持PFC 看门狗。暂停超时和PFC 进程监控相互排斥。在以后的版本中,PFC 看门狗默认已启用。
以下是NX-OS 10.3(1) 中Cisco Nexus 9000 交换机上PFC 看门狗的配置详情。
1. 使用NX-OS 命令priority-flow-control watch-dog-interval
2. 该命令允许软件进程每隔一段时间轮询一次禁丢队列。默认情况下,轮询间隔为100 毫秒。要更改轮询间隔,请使用NX-OS 命令priority-flow-control watch-dog interval <100 - 1000>,在100 ms 和1000 ms 之间以100 ms 为增量。
3. 队列关闭的快慢取决于shutdown-multiplier。默认情况下,其值为1,可使用NX-OS 命令priority-flow-control watch-dog shutdown-multiplier <1 - 10> 更改。无损队列的关闭时间为(看门狗间隔x 关闭乘数)。因此,默认情况下,队列会在Rx 暂停状态持续100 毫秒时关闭。当关闭乘数为2 时,队列将在200 毫秒时关闭,依此类推。
4. 队列处于关闭状态后,可以使用NX-OS 命令priority-flow-control recover interface
5. 另外,还可以使用两种方案自动恢复队列。
a. 固定恢复倍增器在(看门狗间隔x 固定恢复倍增器)之后恢复队列,而与Rx 暂停无关。换句话说,即使设备仍然是慢耗空设备,队列也会恢复。固定恢复乘数默认为禁用(值为0)。可以使用NX-OS 命令priority-flow-control fixed-restore multiplier <0 - 100> 启用它。
b. 只有在该队列连续(看门狗间隔x 自动恢复乘数)未收到Rx Pause 后,自动恢复乘数才会恢复队列。换句话说,只有在设备停止造成慢排空"之后",队列才会恢复。自动恢复的默认值为10,可以使用NX-OS 命令priority-flow-control auto-restore multiplier <0 - 100> 进行更改。
考虑一台设备,该设备在时间= T1 时开始造成慢排空。其连接的交换端口配置了PFC 看门狗,时间间隔为100ms,关机倍率为1,自动恢复倍率为10。设备连续发送暂停帧,从而停止所连接交换端口上的传输。当交换端口在100 毫秒内无法连续传输时,它会关闭队列,从而丢弃队列中的所有数据包,并执行前面描述的其他操作。这发生在T1 + 100ms 时。时间= T2 时,设备停止发送PFC 暂停帧。如果交换端口在最后1 秒内没有收到该免丢包类的PFC 暂停帧,队列将自动恢复。
如例7-12 所示,要验证Cisco Nexus 9000 交换机上的PFC 进程看门狗配置和队列的当前状态,请使用NX-OS 命令show queuing pfc-queue。如图所示,以太网1/3 和以太网1/5 启用了PFC 进程监视。如VL bmap 所示,两个接口上的CoS 1 流量都启用了PFC。只有在以太网1/5 上,分配给CoS 1 流量的无损队列处于关闭状态。
Example 7-12Verifying PFC watchdog on Cisco Nexus 9000 switches
switch# show queuing pfc-queue
+----------------------------------------------------+
Global watch-dog interval [Enabled]
+----------------------------------------------------+
+----------------------------------------------------+
Global PFC watchdog configuration details
PFC watch-dog poll interval : 100 ms
PFC watch-dog shutdown multiplier : 1
PFC watch-dog auto-restore multiplier : 10
PFC watch-dog fixed-restore multiplier : 0
PFC watchdog internal-interface multiplier : 2
+----------------------------------------------------+
+-------------------------------------------------------------+
| Port PFC Watchdog (VL bmap) State (Shutdown) |
+-------------------------------------------------------------+
Ethernet1/1 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/2 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/3 Enabled ( 0x2 ) - - - - - - N -
Ethernet1/4 Disabled ( 0x0 ) - - - - - - - -
Ethernet1/5 Enabled ( 0x2 ) - - - - - - Y -
Ethernet1/6 Disabled ( 0x0 ) - - - - - - - -
使用NX-OS 命令show queuing pfc-queue interface(显示队列pfc-queue 接口)查找PFC 进程看门狗导致的数据包丢弃统计。例7-13 显示了该命令的输出。按以下方式解释Stats 列:
1.关闭:分配给QoS 组1 (CoS 1) 流量的队列被关闭的次数。
2.恢复:分配给QoS 组1 (CoS 1) 流量的队列被恢复的次数。
3.已排空的数据包总数:上次关闭队列时队列中已丢弃的数据包数量。
4.丢弃的总数据包数:上次关闭队列后,交换机上其他端口到达Eth1/5 上试图通过此队列退出并被丢弃的数据包数量。
5.排空的总件数+ 丢失的总件数:排空的数据包总数(3) + 丢失的数据包总数(4)。
6.累计丢失的pkts:这与(4) 相同,但它显示的是之前多个关闭/未关闭实例的总计数。
7.丢弃的入口数据包总数:属于同一QoS 组1 (CoS 1) 的数据包到达Eth 1/5 的入口时被丢弃
8.丢弃的入口pkts 总量:这与(7) 相同,但它显示的是多个先前关闭/未关闭实例的总计数。
Example 7-13PFC watchdog counters on Cisco Nexus 9000 switches
switch# show queuing pfc-queue interface e1/5 detail
+----------------------------------------------------+
Ethernet1/5 Interface PFC watchdog: [Enabled]
+----------------------------------------------------+
+----------------------------------------------------+
| QOS GROUP 1 [Active] PFC [YES] PFC-COS [1]
+----------------------------------------------------+
| | Stats |
+----------------------------------------------------+
| Shutdown| 4|
| Restored| 4|
| Total pkts drained| 752|
| Total pkts dropped| 2197357321|
| Total pkts drained + dropped| 2197358073|
| Aggregate pkts dropped| 53487546587|
| Total Ingress pkts dropped| 66649|
| Aggregate Ingress pkts dropped| 34987434|
+----------------------------------------------------+
要清除这些计数器,请使用NX-OS 命令clear queuing pfc-queue。
Cisco Nexus 9000 交换机通过Syslog 消息通知PFC 看门狗队列关闭/恢复操作。例7-14 显示了队列关闭Syslog 消息。
Example 7-14Syslog message when a queue is shut down due to PFC watchdog
2021 Aug 18 1051 N9K %$ VDC-1 %$ %TAHUSD-SLOT1-2-
TAHUSD_SYSLOG_PFCWD_QUEUE_SHUTDOWN: Queue 1 of Ethernet1/5 is shutdown due to PFC
watchdog timer expiring
例7-15 显示了队列恢复Syslog 消息。请注意入口和出口丢弃数据包的数量。
Example 7-15Syslog message when a queue is restored after being shut down by PFC watchdog
2021 Aug 18 1058 N9K %$ VDC-1 %$ %TAHUSD-SLOT1-2-
TAHUSD_SYSLOG_PFCWD_QUEUE_RESTORED: Queue 1 of Ethernet1/5 is restored due to PFC
watchdog timer expiring; 2197358073 egress packets/66649 ingress packets dropped
during the event
The Granularity of Pause Timeout and PFC Watchdog
暂停超时的配置粒度为100 毫秒,与PFC 看门狗间隔相同。这两个功能都依赖于软件每100 毫秒轮询一次。因此,两者都会将动作和恢复时间延迟长达99 毫秒。换句话说,PFC看门狗关机动作可能需要长达199 毫秒,而不是在100 毫秒时准确执行。
请参阅第6 章"行动中的无贷记掉线超时"一节和第3 章"TxWait、Slowport-monitor 和Tx-credit-not-available 之间的差异"一节,了解使用软件轮询的结果和基于ASIC 实现的额外优势。在Cisco MDS 交换机上,光纤通道无credit-drop 超时功能于2015 年转为基于ASIC 的实现。在撰写本文时,基于ASIC 的暂停超时和PFC 进程看门狗实施尚未推出。
The Benefits and the Limitations
暂停超时和PFC 看门狗会丢弃发送给慢速设备的帧,从而释放缓冲区,使受害设备摆脱拥塞影响。丢弃帧偏离了无损网络的无丢弃行为,但当罪魁祸首设备无法接收帧时,与其永远等待并让其他设备受害,不如丢弃罪魁祸首设备的帧。由于上述原因,我们建议根据环境的可用性和设备供应商推荐的阈值启用这些功能。
在使用这些方法时,请注意以下限制:
1. 在撰写本文时,暂停超时和PFC 看门狗的大多数实现都基于软件轮询,这可能会延迟操作并降低恢复的有效性。请参阅前面的"暂停超时和PFC 看门狗的粒度"部分。
2. 暂停超时和PFC 看门狗有助于从慢排空造成的拥塞中恢复。如果拥塞是由边缘链路的过度使用造成的,这些方法就无能为力了。
3. 暂停超时和PFC 看门狗的最小粒度为100 毫秒。因此,当传输停止的时间较短时(如50 毫秒),这些方法就无能为力了。
4. 暂停超时和PFC 看门狗超时仅对连续停止传输的时段起作用。即使暂停帧不连续,慢速设备也会造成严重拥塞。
这些限制不应妨碍使用暂停超时和PFC 看门狗。但要注意它们能实现什么,不能实现什么。
Congestion Notification in Routed Lossless Ethernet Networks
终端设备及其应用程序可能无法察觉网络拥塞。肇事设备可能会继续在网络上发送(或请求)更多流量,使拥塞的严重程度恶化或持续时间延长。为了解决这个问题,网络交换机可以在检测到拥塞时立即"明确"通知终端设备。作为回应,肇事设备可采取预防措施。
这种通过通知终端设备来防止拥塞的方法适用于各种网络,其实施和采用程度各不相同。第6 章"通过通知终端设备防止拥塞"一节详细介绍了在光纤通道Fabric 中使用Fabric Performance Impact Notifications (FPIN) 和Congestion Signals 的实施情况。第8 章"TCP 存储网络中的拥塞通知"一节介绍了TCP/IP 存储网络中的这种方法。
如前所述,这种方法在FCoE 和RoCE 环境中的实施和采用并不常见。因此,本节不对其进行解释。本节的重点是RoCEv2 拥塞管理(RCM) 路由无损以太网网络中的拥塞通知。
Solution Components
通过通知终端设备来防止拥塞的方法是否成功取决于以下因素:
1. 拥塞检测:交换机(称为拥塞点)必须能够检测到拥塞症状。
2. 发送通知:检测到拥塞后,交换机必须能够将其通知终端设备。为此,光纤通道交换机会发送特殊帧(称为FPIN)和拥塞信号。相比之下,RoCEv2 和TCP/IP 网络通过在报头中标记特殊位,将此信息编码到数据包中。
3. 接收通知:终端设备必须能够理解交换机发出的通知。这取决于终端设备的硬件和/或软件能力。
4. 预防拥塞行动:在收到网络拥塞通知后,终端设备必须采取预防措施,如降低速率。这是最重要的组成部分。
以下各节将使用RoCEv2 拥塞管理(RCM) 对这些组件进行说明。
RoCEv2 Transport Overview
RoCEv2 数据包有一个IP 报头,因此可以使用IPv4 或IPv6 报头中的DSCP 字段进行分类。请参阅前面的"优先级流量控制"一节,了解在路由第3 层网络中如何对流量进行分类并将其分配到无损类。第1 章图1-10 显示了RoCEv2 数据包格式。
为了通知终端设备拥塞情况,使用了IP 报头中的"显式拥塞通知"(ECN)字段。
请注意以下几点:
1. 通常,以太网VLAN CoS 值会映射到IP 报头中的DSCP 字段。表7-1 提供了这种映射。
2. 在路由网络中,以太网报头在每一跳都会改变,因此除非另行配置,否则不会保留CoS 值。但IP 报头中的DSCP 字段在源和目的地之间保持不变。
3. 在不使用VLAN 的网络中,使用IP 标头中的DSCP 字段是对流量进行分类的唯一选择,因为CoS 是VLAN 标头的一部分。
4. 重叠网络(如虚拟可扩展局域网(VXLAN))通常会在封装原始数据包之前将DSCP 和ECN 值复制到外部IP 标头,并将这些值从外部标头复制到解封装数据包,因此在使用IP 标头对流量进行分类时,会保留不丢弃行为和ECN。有关详情,请参阅"使用VXLAN 的无损以太网"一节。
RoCEv2 Congestion Management
交换机检测到拥塞时,会在IP 报头的ECN 字段中标记拥塞。目的地接收到带有ECN 标记的数据包后,会将此信息反映给信源,信源会通过限制流量速率做出反应。RFC 3168 解释了使用TCP 作为第4 层协议的显式拥塞通知(ECN)。RCM 依赖于相同的机制,但由于RoCEv2 使用的是UDP(而非TCP),因此有一些不同之处,下文将对此进行说明。
请参考图7-17,它是图7-8 所解释的脊叶网络的一个子集。以下是概要步骤:
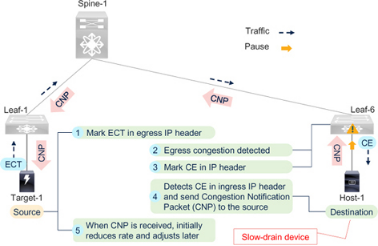
Figure 7-17RoCEv2 Congestion Management (RCM)
1.是否愿意使用RCM:终端设备(Target-1 和Host-1)支持RCM 时,会在IPv4 或IPv6 标头中设置ECN-capable Transport(ECT)标志。ECT 标志在IP 报头的ECN 字段中用b'01' 或b'10' 设置。ECN 字段中的b'00' 表示端点不支持ECN,也不支持RCM。
2. 拥塞检测:当队列利用率超过配置的阈值时,端到端数据路径中的交换机(Leaf-6)会检测到拥塞。队列利用率增加的原因是慢排空(出口交换端口上的Rx 暂停)或交换端口利用率过高。
3. 发送通知:交换机检测到队列拥塞时,会在IPv4 或IPv6 报头中设置拥塞体验(CE) 标志。CE 标志在ECN 字段中用b'11' 设置。拥塞交换端口只为启用了ECT 标志(b'01' 或b'10')的数据包设置CE 标志。非ECN 功能数据包(ECN 值为b'00')将保持不变地转发。与光纤通道不同,在RoCEv2 网络中,交换机不会发送任何特殊数据包(或帧或信号)来通知终端设备。
4. 接收通知:目的地(主机-1)在收到带有CE 标志的数据包时会检测到网络拥塞。由于CE 标志是标准IP 报头的一部分,因此主机-1 不需要任何特殊机制来解释新型数据包。但是,它必须能够检测到CE 标志并对其采取行动。当主机-1 接收到CE 标记数据包时,它会向启用了CE 标记的入口数据包的源端(目标-1)发送拥塞通知数据包(CNP),从而向源端反映拥塞情况。由于CNP 是一种特殊的数据包,因此目标和源都必须能够发送和接收CNP,以及发送CNP 的频率、停止发送的时间和内容等其他细节。此外,还要配置网络QoS 策略,以高优先级对CNP 进行分类和转发。
5. 预防拥塞行动:发送方(目标-1)收到CNP 后,会降低发送CNP 的目的地的流量。如前所述,由于CNP 是一种特殊数据包,发送方必须能够监听并采取行动。此外,在初始降低速率行动后,发送方必须能够调整其速率,以便在未充分利用和过度利用之间达到最佳平衡。
RoCEv2 Congestion Management Considerations
图7-17 对RCM 进行了过于简化的解释。但是,在生产环境中,成百上千台设备可能会以多对一的流量模式连接到同一个Fabric。
本节介绍了RoCEv2 网络的一些重要注意事项。这些注意事项在新建环境中可能并不明显,但随着网络的发展或成熟,应了解其局限性并采取积极措施。
请参考图7-8,并思考图7-17 所解释的RCM 如何运行。然后,考虑以下几点:
1. 混合环境:根据RoCEv2 标准,RCM 是可选项。需要特别注意支持RCM 和不支持RCM 终端设备的混合环境。当许多设备向同一设备发送流量时,如果少数发送方不支持RCM,它们的流量不会被CE 标记,而来自其他支持RCM 的设备的流量则会被CE 标记。因此,慢耗设备(目的地)只向支持RCM 的设备发送CNP。因此,支持RCM 的设备会降低流量速率,而不支持RCM 的设备则不会。这种情况可能会导致支持RCM 的设备流量不足,因为它们可能会不断降低速率,而不支持RCM 的设备可能会消耗掉所有链路容量。在混合TCP 和UDP 流量的IP 网络中,这种情况类似于UDP 流量导致的TCP 饥饿。通常情况下,较新的设备更有可能支持RCM。如果现有设备不支持RCM,较新的设备可能会受到更多惩罚。
2. 速率降低算法:RoCEv2 标准提到,发送方应在收到CNP 后降低流量速率,但没有解释速率降低或恢复的算法。由于缺乏标准方法,供应商只能开发不同的实施方案,在相同的环境中做出不同的反应。用户只能承受非统一实施的结果,或被迫锁定供应商以实现统一。
3. 同步:接收CNP 的流量源不知道其他向同一目的地发送流量的流量源。多个此类源的集体行动可能会导致反应过度或反应不足。例如,在图7-8 中,如果每个目标将速率降低5%,则五个目标的集体速率降低行动会导致速率降低25%(反应过度)。之后,当目标调整/提高速率时,五个独立工作的此类设备可能会再次导致最初的问题,从而引发最初的拥塞事件。在TCP/IP 网络中,这种情况类似于TCP 全局同步。
4. 延迟行动:在某些突发流量模式的存储环境中,RCM(以及其他通过通知终端设备来防止拥塞的方法)可能无法奏效,因为从检测到拥塞到采取预防措施之间存在延迟。在图7-17 中,Leaf-6 检测到拥塞,Host-1 接收到CE 标记数据包,向源发送CNP,最后源降低速率。这些步骤在Leaf-6 观察到变化时都会产生延迟。此时,原来的拥塞症状可能会自行消失。引用RFC 3168(这与RCM 使用的机制相同)的一句话:"CE 数据包表示持续性拥塞,而不是瞬时性拥塞,因此收到CE 数据包时的反应应与持续性拥塞相适应"。
5.配置复杂:RCM 的成功与否取决于其在网络中的配置。在交换机上标记CE 标志通常使用加权随机早期检测(WRED) 等检测方案。有关详细信息,请参阅第8 章"主动队列管理"一节。应配置这些机制的阈值,以便在队列满之前在交换机上观察到降低速率的操作。这些值还取决于交换机的类型,因为不同的交换机有不同的架构和缓冲区容量。在终端设备上,CNP 的频率是一个重要的考虑因素。过多的CNP 可能会增加终端设备的负载,而过少的CNP 可能会延迟终端设备的操作。此外,速率降低算法也可能存在变数。
这些问题不应妨碍RCM 的启用。请遵循供应商的建议,并根据您的环境完善配置。需要记住的重要一点是,不能因为某些东西在较新(新建环境)中运行良好,就不再需要监控拥塞症状。
打个比方,新车的轮胎充有氮气。起初,它们可能几个月甚至一年都不需要充气。这些新车工作得非常好,以至于有些司机几乎忘记了轮胎需要气压检查,结果导致他们的不太新的汽车爆胎。他们本可以通过每月主动检查来避免这一问题。不要成为这样的司机。问题会随着环境的成长或成熟而显现。如果您已经意识到潜在的问题,那么当问题出现时,就能帮助您更快地解决问题。
PFC and ECN
PFC 是一种逐跳流量控制机制。相比之下,ECN 会通知目的地,而目的地又会通知发送方降低流量速率以防止拥塞。如前所述,从检测到拥塞(标记CE 标志时)到拥塞交换端口观察到降低的速率之间存在延迟。这大约是往返时间和终端设备处理延迟的两倍。在此期间,拥塞交换端口上的队列可能会填满。逐跳PFC 可能会被激活,而不是丢弃数据包,从而导致拥塞在不丢弃类中扩散。
同时使用ECN 和PFC 可以发挥两者的优势。ECN 基于流量,但其效果可能会延迟。与此相反,PFC 基于优先级(类别或类型),但其及时行动可避免丢包。同时使用这两种方法,可以使操作既迅速又基于流量。
Configuring PFC and ECN Parameters
通知终端设备(通过ECN 和CNP)后的速率降低操作应消除拥塞原因。没有拥塞时,就没有必要调用PFC。因此,正常工作的ECN 应能很快减少PFC 暂停。但在交换机上配置ECN 门限需要特别考虑。具体数值取决于交换机类型,请参考供应商文档。本节仅解释概念性概述。
Note the following points.请注意以下几点。
1.入口队列/缓冲区只有在出口队列被大量使用后才会开始填满。这一点在前面的"入口和出口队列及微突发检测"一节中已有解释。
2.ECN 标记(如WRED)的阈值应用于出口队列,而PFC 暂停阈值和恢复阈值则应用于入口队列/缓冲区。
3.暂停阈值和恢复阈值应根据前面"暂停阈值和恢复阈值"一节中的详细说明进行配置。对于距离较短的数据中心内链路,通常不需要更改默认的暂停阈值和恢复阈值。
4. ECN 门限应足够低,以便更早地标记CE 标志,从而有足够的时间在拥塞端口上观察到速率降低操作。
5. 阈值应足够大,至少能容纳几个数据包。例如,在启用巨型帧时,9000 字节的最小大小甚至无法在队列中保留一个完整大小的巨型数据包。
图7-18 至图7-23 展示了PFC 和ECN 的共同功能。需要了解的一个要点是,即使调整了阈值,也不能完全消除逐跳拥塞传播。如果瞬间调用PFC,拥塞扩散是可以接受的。PFC 本身是有益的,因为它可以避免数据包丢弃,但它的副作用是会降低所有具有相同优先级的流量的速度。如果ECN 能尽快降低部分流量的传输速率,就能限制PFC 造成的逐跳拥塞扩散和持续时间。如前所述,配置时应力求两种方法的最佳效果,而不是以消除PFC 为目标。
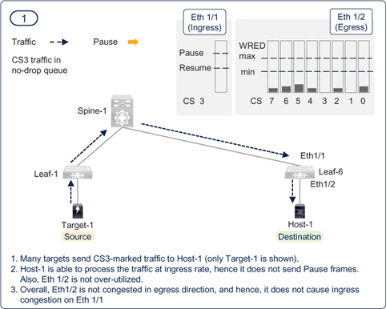
Figure 7-18PFC and ECN working together in a RoCEv2 network — Step — 1
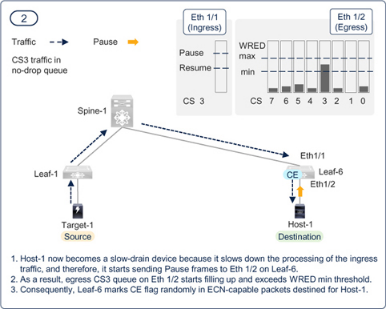
Figure 7-19PFC and ECN working together in a RoCEv2 network — Step — 2
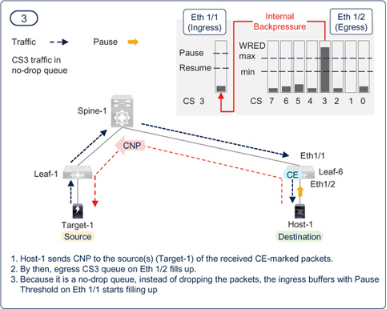
Figure 7-20PFC and ECN working together in a RoCEv2 network — Step — 3
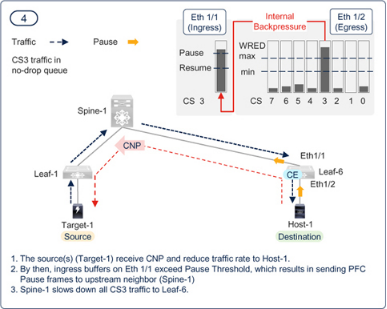
Figure 7-21PFC and ECN working together in a RoCEv2 network — Step — 4
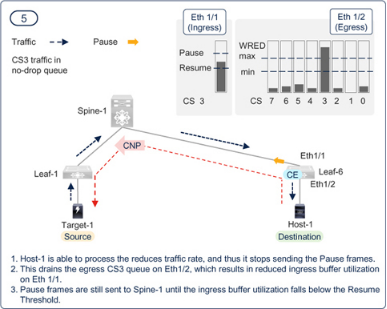
Figure 7-22PFC and ECN working together in a RoCEv2 network — Step — 5
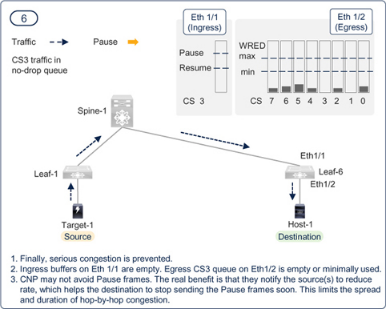
Figure 7-23PFC and ECN working together in a RoCEv2 network — Step — 6
Lossless Traffic with VXLAN
虚拟可扩展局域网(VXLAN)可传输无损流量,与任何其他路由IP/ 以太网网络类似。因此,拥塞检测、故障排除和预防都与此类似。
VXLAN Overview
虚拟可扩展局域网(VXLAN)将第2 层域扩展到第3 层数据中心网络。这样就可以灵活部署需要跨第3 层边界的第2 层邻接的工作负载。VXLAN 的另一个优点是规模更大。以太网VLAN ID 是一个12 位字段,这将VLAN 的数量限制在4096 个。相比之下,VXLAN 网络标识符(VNI)是一个24 位字段,允许多达1600 万个第2 层域。VXLAN 还得益于第3 层底层网络的等成本多路径(ECMP)路由,从而实现第2 层域之间的高速无阻塞连接。
VXLAN Transport
VXLAN 采用MAC-in-UDP 封装,将第2 层域扩展到第3 层网络。有关VXLAN 帧格式,请参阅图7-24。两个独立的第2 层网络通过VXLAN 隧道端点(VTEP)连接到第3 层网络。顾名思义,VTEP 通过VXLAN 隧道连接。它们知道本地第2 层域中可到达的MAC 地址以及通过远程VTEP 可到达的MAC 地址。当VTEP 接收到要发送给远程第2 层域中设备的第2 层帧时,它会将第2 层帧封装到IP/UDP 数据包中,并通过路由网络发送给远程VTEP。远程VTEP 对数据包进行解封装,并将底层第2 层帧发送到目的地。
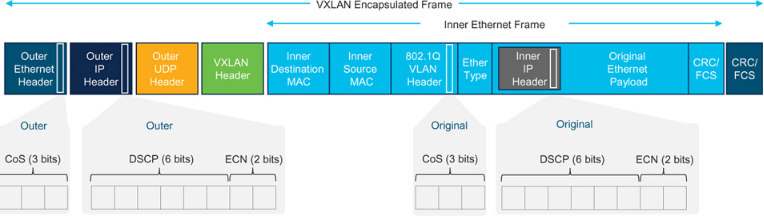
Figure 7-24VXLAN frame format
Physical Topology
VXLAN 第3 层网络通常采用脊叶拓扑部署(类似于图7-8)。这就是所谓的底层网络。底层网络中的数据包转发由IS-IS 和OSPF 等IP 路由协议之一启用。
Cisco Nexus 9000 等叶子交换机可充当基于硬件的VTEP。每个VTEP 有两个接口。一个是第2 层接口,用于连接本地端点通信的本地第2 层域。另一个是路由底层网络上的第3 层接口。
两个VTEP 之间的流量通过多个骨干交换机使用ECMP。终端设备可能不知道,VTEP 会将发往目的地的数据包封装在VXLAN 数据包中。同样,位于入口和出口VTEP 之间的脊柱交换机也可能不知道数据包属于VXLAN 隧道。它只会查找外部IP 报头,然后发送到目的地VTEP。
审核编辑:刘清
-
以太网
+关注
关注
41文章
6203浏览量
181618 -
看门狗
+关注
关注
10文章
611浏览量
73226 -
交换机
+关注
关注
23文章
2937浏览量
104905 -
VLAN
+关注
关注
1文章
290浏览量
37973 -
存储网络
+关注
关注
0文章
31浏览量
8457
原文标题:以太网存储网络的拥塞管理连载(六)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
以太网存储网络的拥塞管理连载方案(一)
以太网存储网络的拥塞管理连载方案(二)
以太网存储网络的拥塞管理连载方案(三)

RDMA设计12:融合以太网协议栈设计1

以太网供电新标准促热网络化电源管理应用市场
以太网的分类及静态以太网交换和动态以太网交换、介绍
以太网光模你了解多少
AI网络管理新范式:精要解读超以太网联盟(UEC)1.0 规范(2025Q2)




评论