 如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型

背景介绍
大语言模型正以其惊人的新能力推动人工智能的发展,扩大其应用范围。然而,由于这类模型具有庞大的参数规模,部署和推理的难度和成本极高,这一挑战一直困扰着 AI 领域。此外,当前存在大量支持模型部署和推理的框架和工具,如 ModelScope 的 Model Pipelines API 和 HuggingFace 的 Text Generation Inference 等,各自都有其独特的特点和优势。然而,这些工具往往未能充分发挥 GPU 的性能。
为了解决这些问题,NVIDIA 推出了一种全新的解决方案——TensorRT-LLM。这是一款高度优化的开源计算框架,它将NVIDIA TensorRT的深度学习编译器、FasterTransformer 的优化内核、预处理和后处理,以及多 GPU/多节点通信等功能封装在一个简单的开源 Python/C++ API 中,同时与硬件进行了一体化优化,形成了一种产品级的大模型推理解决方案。NVIDIA TensorRT-LLM具有多项突出的特性,包括支持新的 FP8 数据格式,这使得模型可以在更低的精度下运行,从而减少内存消耗,同时保持模型的准确性。它还支持一种名为“In-flight batching”的新调度技术,可以更有效地处理动态负载,提高 GPU 利用率。
此外,TensorRT-LLM 还支持模型的并行化和分布式推理,利用张量并行性进行模型并行化,使模型可以在多个 GPU 之间并行运行,从而实现大型模型的高效推理。最重要的是,TensorRT-LLM 极大地简化了开发流程,使得开发者无需深入了解底层的技术细节,也无需编写复杂的 CUDA/C++ 代码。它提供了一个易用、开源和模块化的应用编程接口,使开发者能够轻松定义、优化和执行新的大语言模型架构和增强功能。总的来说,TensorRT-LLM 让用户可以专注于模型的设计和优化,而将底层的性能优化工作交给 TensorRT 来完成,大大提高了开发效率和生产效率,真正实现了大模型推理的易用性和高效性。
阿里云的通义千问开源模型 Qwen-7B,拥有 70 亿参数,在一系列全方位的评估中展示了其在自然语言理解与生成、数学问题求解、代码生成等领域的优秀能力。这些评估涵盖了多个数据集,包括 MMLU、C-Eval、GSM8K、HumanEval 以及 WMT22 等。在这些评测中,Qwen-7B 不仅超越了同等规模的其他大语言模型,甚至在某些方面超过了参数规模更大的模型。因此,对于 TensorRT-LLM 来说,支持 Qwen 系列模型具有重要的意义。
开发与优化过程
我们是社区开发者,通过阿里云天池举办的NVIDIA TensorRT Hackathon 2023接触到了 NVIDIA TensorRT-LLM,并为它贡献了代码。TensorRT-LLM 已开源(https://github.com/NVIDIA/TensorRT-LLM),包含了我们开发的 Qwen-7B 模型。以下是我们的开发记录,供其他开发者参考。
基础功能支持
-
首先我们初步分析了 examples/llama 代码,以深化对 trt-llm 基本流程的理解。在 llama 项目的 weight.py 中,存在一个 load_from_meta_llama 函数,该函数包含 tensorrt_llm.models.LLaMAForCausalLM,此部分定义了 TensorRT 的模型结构。复制 examples/llama 并将其重命名为 examples/qwen,同时将 LLaMAForCausalLM 复制并创建新的 mode.py 文件,将相关内容粘贴至此。在这个过程中,所有包含“llama”的模型都被替换为“qwen”。
-
接下来,我们对项目中的 weight.py 的 load_from_hf_qwen 函数进行修改,目的是逐步将 HuggingFace 的权重名称与 TensorRT 的权重名称对齐。执行 build.py 后,虽然编译成功,但执行 run.py 的结果并未如预期。
-
参照 TensorRT-LLM 的 docs/source/2023-05-19-how-to-debug.md 文档,我们对模型进行了详细的调试,从外到内打印模型层的数值,观察 mean/sum/shape,并与原版进行对比。经过排查,我们发现 attention 部分已经包含了 rope 计算,通过调整 gpt attention plugin 的参数,最终使得输出的 logits 正常。
-
再次优化 run.py,将 HuggingFace 原版 qwen_generation_utils.py 中的 make_context 函数迁移到 utils/utils.py 中,并导入该函数。这个函数被用来构造一个 chat 版的 prompt 输入,同时我们调整 eos 和 pad token 为 qwen 专属的 <|im_end|> 或者 <|endoftext|>,最终 run.py 输出也正常。
增加功能:Weight Only 量化
在 FP16 对齐成功,并且 run.py 以及 summarize.py 文件均能正常运行之后,我们开始探索实现 weight only int8/int4 量化。这只需要在 build.py 文件中对 weight only int8/int4 分支进行轻微调整,包括 shape 的修改,以及保持权重名称与 FP16 一致。接下来,我们进行编译测试,发现这一过程顺利完成,且工作量并未超出预期,这部分工作基本无需投入大量人力资源。
增加功能:Smooth Quant
-
在参考 Llama 项目的基础上,我们将 hf_llama_convert.py 替换为 hf_qwen_convert.py 文件,该文件用于将 HuggingFace 的权重导出至 FasterTransformer (FT) 格式的文件。同时,我们将 llama/weight.py 中的 load_from_binary 函数重命名为 load_from_ft 复制到 qwen/weight.py 中,并根据我们导出的权重文件进行了适当的修改。然后,我们将 qwen/build.py 中默认的加载函数从 load_from_hf_qwen 更改为 load_from_ft。为了保证兼容性,我们也对 load_from_ft 函数进行了 fp16 以及 weight_only 的 int8/int4 的适配,其适配流程与之前的基本相同。当开发者未导出 FT 权重时,系统会自动加载 load_from_hf_qwen 函数以生成 engine。
-
在 smooth quant 的实现方面,我们参考了 example/llama 的 smooth quant 过程,同样在 hf_qwen_convert.py 中添加了 --smoothquant 选项。通过调试 example/llama/hf_llama_convert.py 文件,我们观察了 smooth_llama_model 函数的计算方法以及参数的 shape,发现其 mlp 的 gate 和 up 与 qwen mlp 的 w2/w1 layer 相对应,并且 w1/w2 共享一个输入。这部分的适配与之前的基本一致,唯一的区别是,attention 和 mlp 中需要量化的层需要进行转置,然后在 weight.py 的 load_from_ft 函数中再次转置回来。
-
我们再次分析了 example/llama 的 smooth quant 过程,并参考了其 build.py 文件,发现其中一个有一个 from tensorrt_llm.models import smooth_quantize 过程。在这个过程中,_smooth_quantize_llama 函数会替换掉 trt-llm 原本的模型结构。因此,我们在 qwen/utils 目录下建立了一个 quantization.py 文件,参考了 llama 的 SmoothQuantAttention,并复用了其 SmoothQuantRmsNorm,从而实现了 qwen 的 smooth quant 的全部过程。
优化效果
精度
-
测试平台:NVIDIA A10 Tensor Core GPU(24G 显存) | TensorRT 9.0.0.1。
-
TRT_LLM engine 编译时最大输入长度:2048, 最大新增长度:2048。
-
HuggingFace 版 Qwen 采用默认配置,未安装,未启用 FlashAttention 相关模块。
-
测试时:beam=batch=1,max_new_tokens=100。
-
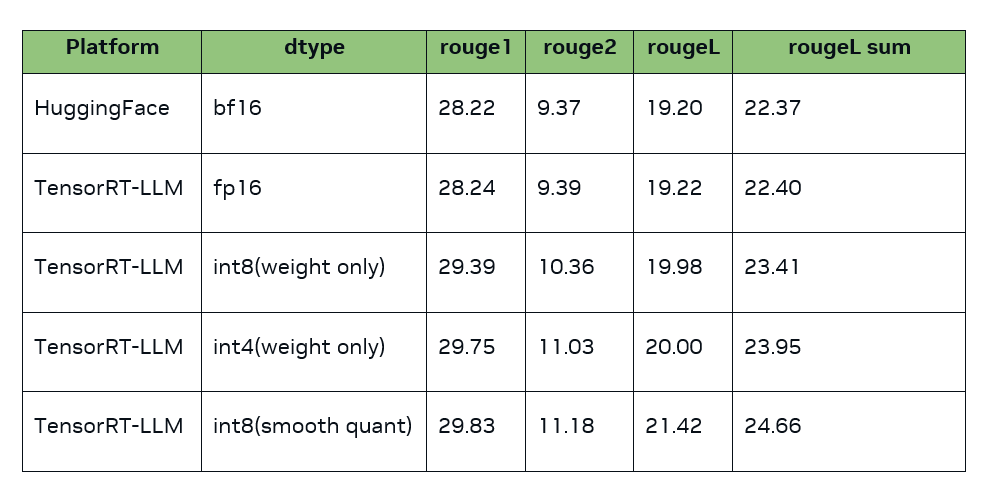
测试结果(该结果由 examples/qwen/summarize.py 生成。注:量化后分数与原版分数越接近,精度越好):
性能
-
测试平台:NVIDIA A10 Tensor Core GPU (24G 显存) | TensorRT 9.0.0.1。
-
测试数据集为 ShareGPT_Vicuna_unfiltered,下载地址:https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
-
生成速度(token/s):此指标不仅包括 generation 的过程,同时也计算了 context 阶段时间,因此它表示的是每秒实际处理(理解输入和生成输出)的 token 数量。
-
吞吐速度(requests/s):此指标代表在极限情况下,无请求间隙时,系统平均每秒能处理的请求数量。
-
以下的测试包含多个 batch,主要用于测试特定显卡的极限运行情况,测试过程仅使用 TensorRT-LLM python 运行时环境。
-
HuggingFace 版 Qwen 采用默认配置,未安装,未启用 FlashAttention 相关模块。
-
当最大输入长度:2048, 最大新增长度:2048,num-prompts=100, beam=1, seed=0 时,BenchMark 结果如下:
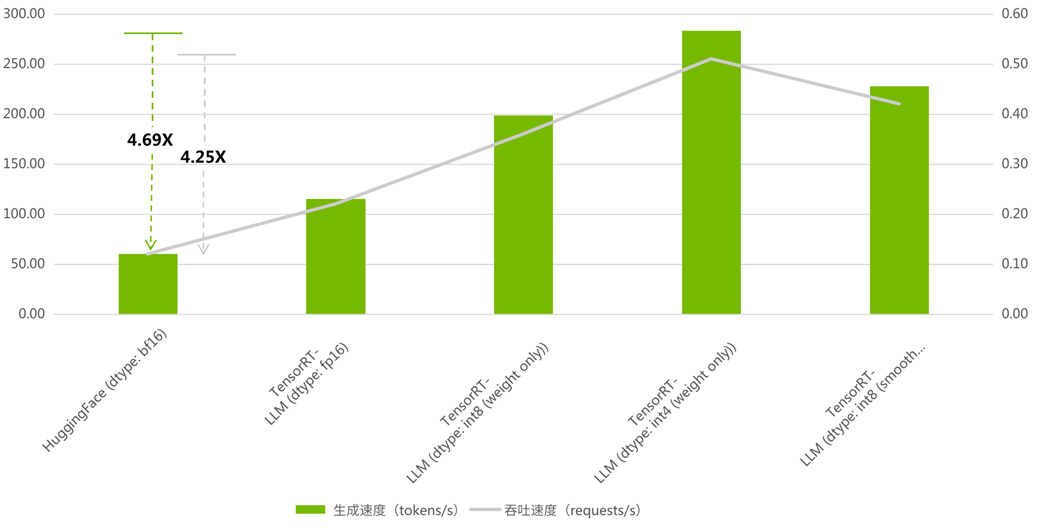
图 1:TensorRT-LLM 与 HuggingFace
吞吐以及生成对比
(吞吐加速比最高 4.25, 生成加速比最高 4.69)
-
当最大输入长度:1024, 最大新增长度:1024,num-prompts=100, beam=1, seed=0。BenchMark 结果如下:
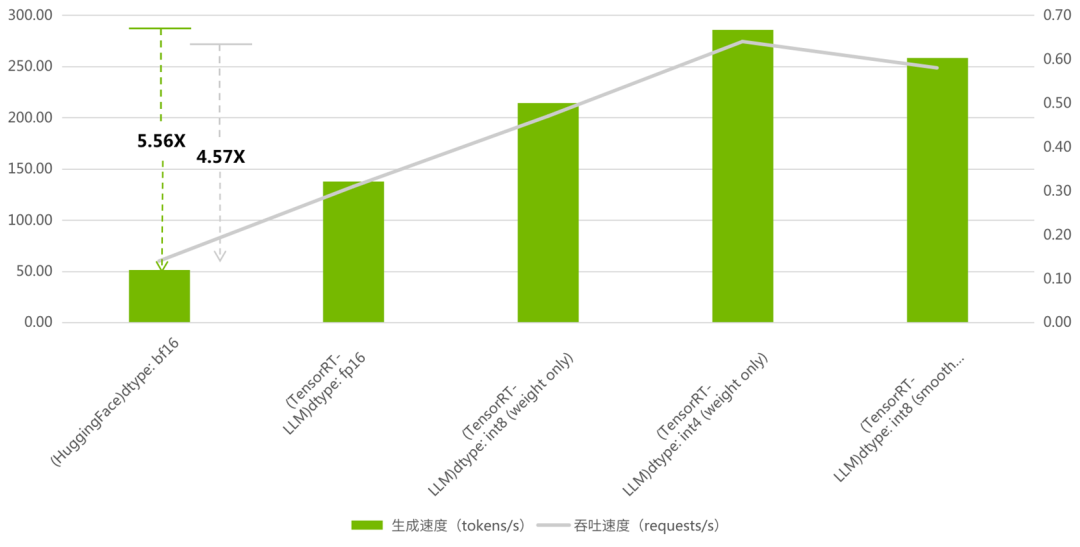
图 2:TensorRT-LLM 与 HuggingFace
吞吐以及生成对比
(吞吐加速比最高 4.57, 生成加速比最高 5.56)
总结
从整个开发过程的角度来看,NVIDIA TensorRT-LLM 已经实现了相当丰富的功能。它支持新模型的工作量不大,因为可以复用已有模型的相关代码,只需要进行少量的改动即可完成对新模型的支持。这表明了 TensorRT-LLM 具有很好的扩展性。此外,在精度方面,它能够与 HuggingFace 保持一致,但在速度方面最高可以达到 HuggingFace 的 5.56 倍。综合考虑这些因素,可以说 TensorRT-LLM 完全有资格成为大规模语言模型推理框架的首选。它极大地缓解了推理和部署的难题,为广泛应用大语言模型提供了有力支持。
项目代码
开源地址:
https://github.com/Tlntin/Qwen-7B-Chat-TensorRT-LLM
关于作者

邓顺子
广州大学工程管理专业,拥有管理学学士学位,目前担任 NLP 算法工程师,主要研究留学教育领域的信息抽取与智能对话。曾获得第二十一届中国计算语言学大会(CCL2022)航旅纵横杯一等奖(子任务二)和三等奖(子任务一),也是热门 Rust 开源项目 Pake 的主要贡献者之一。

赵红博
河南科技大学机械制造专业,拥有工学学士学位,目前在 Boss 直聘担任高性能计算开发工程师,主要研究招聘领域模型的推理加速工作。

季光
NVIDIA DevTech 团队经理,博士毕业于中科院计算所。擅长 GPU 加速的视频处理以及性能优化,以及深度学习模型的推理优化,在 GPU 视频编解码以及 CUDA 编程与优化方面积累了丰富的经验。
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4112浏览量
99597
原文标题:如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA ACE现已支持开源Qwen3-8B小语言模型
NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT-LLM的大规模专家并行架构设计

大规模专家并行模型在TensorRT-LLM的设计

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
TensorRT-LLM中的分离式服务

Votee AI借助NVIDIA技术加速方言小语种LLM开发
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

壁仞科技完成Qwen3旗舰模型适配
NVIDIA使用Qwen3系列模型的最佳实践




评论