 汽车多模态交互研究:大模型及多模态融合,推进AI Agent上车
汽车多模态交互研究:大模型及多模态融合,推进AI Agent上车

佐思汽研发布《2023年中国汽车多模态交互发展研究报告》,主要梳理了主流座舱交互方式、2023年上市的重点车型交互方式应用、供应商座舱交互方案,以及多模交互融合趋势。
通过梳理最近一年新上市车型的交互方式和功能来看,主动式、拟人化、自然化交互成为主要方向。从交互方式来看:单一模态交互,如触觉、语音等主流交互的控制范围从车内拓展至车外,指纹、肌电等新型交互方式的上车案例开始增多;多模态融合交互下,语音+头姿/人脸/唇语、面部+情绪/嗅觉等多种融合交互不断上车,旨在打造更加主动、自然的人车交互。
单一模态的纵深发展
触觉交互方面:座舱大屏化、多屏化趋势加剧,同时智能表面材料在舱内的扩展应用,让触觉感知范围向车门、车窗、座椅等部件扩展,并逐步引入触觉反馈技术;
语音交互方面:语音交互在AI大模型的赋能下,功能愈加智能化、情感化。唇动识别、声纹识别等技术的上车,使语音交互精准度得到进一步提升,控制范围也从车内拓展至车外;
视觉交互方面:基于视觉技术的面部/手势识别范围开始逐渐向肢体识别扩展,包括头部姿势、手臂动作,以及身体行为等;
嗅觉交互方面:原主要用于净化空气、祛除异味的嗅觉交互功能,现今可实现座舱杀菌消毒、并支持香氛系统与座舱场景/季节时令联动。
案例1
语音控车实现车内向车外延伸
代表车型:长安启源A07、极越01
代表功能:车外语音开启车门、车窗、辅助泊车等
长安启源A07采用科大讯飞最新XTTS 4.0 技术,车载语音助手声音更加自然拟人化,具备高兴、抱歉、疑惑等多情感表达。支持向车外喊话(内容可自定义);此外,还可在车外通过语音实现对后备箱、车窗、音乐、空调、出库/泊车等功能的控制。
极越01搭载“SIMO”语音助手,支持全域全离线语音,无网弱网也可全程在线语音交互;可实现500毫秒识别,700毫秒内响应。在车外,驾乘人员可通过声纹识别技术实现语音操作空调、音响、灯光、车窗、车门、后尾门、充电盖的开启/关闭等功能,以及支持车外语音泊车。
案例2
声纹识别扩大应用
代表车型:理想L7、合创A06/V09
代表功能:识别驾乘人员身份,提供针对性服务
理想L系列车型均支持声纹识别功能。在乘客声纹注册后,“理想同学”可分辨乘客是谁,叫出不同乘客指定的昵称,并结合声纹记忆对不同乘客位置执行车控。
合创A06/V09的声纹识别VOICE ID,能清楚识别有效用户身份以及指令,并将成为HYCAN ID的入口,为用户接入丰富智慧生态,使用100+款娱乐应用。另外基于声纹识别技术,系统将主动屏蔽其他干扰声音,提高主驾识别精准度。
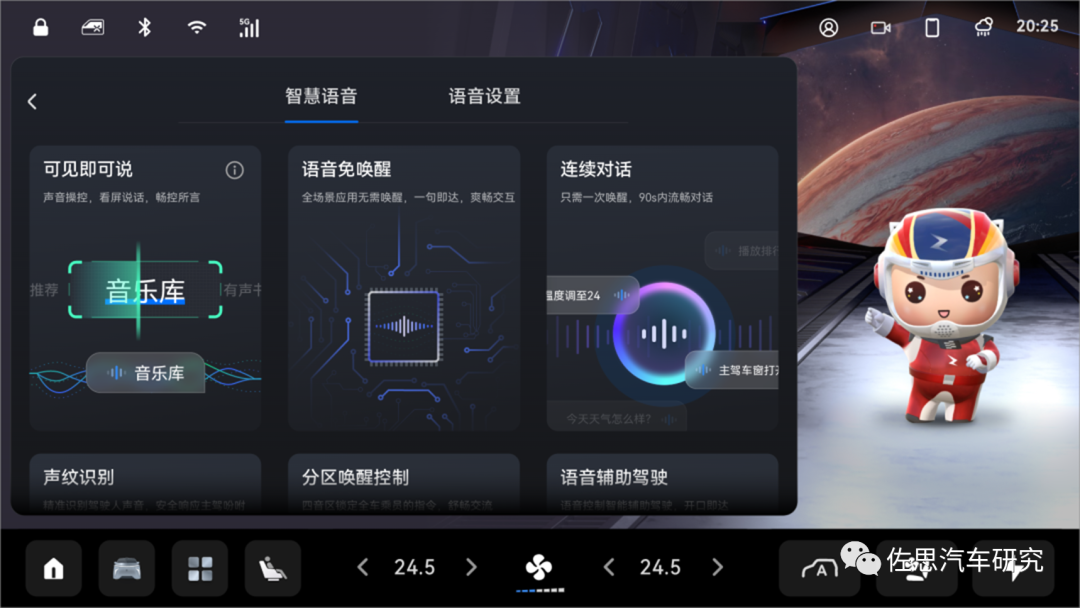
图片来源:合创汽车
案例3
肌电交互实现车载商业化落地
代表车型:岚图追光
代表功能:车内外隔空微手势控车
2023年4月,岚图追光与柔灵科技推出肌电交互融合方案。该方案主要通过肌电手环实现。手环内部安装多通道肌电传感器和高精度的放大器,可以实时采集丰富的肌肉电信号并生成算法,传导计算终端,从而生成个性化的AI手势模型,之后再和岚图的车载平台整合。使用者将手环与车内蓝牙连接,即可实现以微手势控制车辆,包括开关后备箱、升降车窗等60+种手势动作。此外,手环还可以和车内游戏系统无缝连接。借助肌电手环的手势识别,用户可以更自然、直观地操控游戏角色,如地铁跑酷等。

图片来源:柔灵科技
多模态融合,打造主动交互
目前车企已实现的多模态融合包括但不限于语音+唇动识别、语音+面部识别、语音+手势识别、语音+头姿、面部+情绪识别、面部+眼球追踪、香氛+面部+语音识别等。其中语音多模态交互方式为当下主流,应用车型包括上文提到的长安启源A07、极越01、理想L7、合创A06/V09等车型。
多模态融合代表功能(仅列举部分)

来源:佐思汽研《2023年中国汽车多模态交互发展研究报告》
案例1
语音+头姿交互:魏牌蓝山DHT PHEV将语音和头姿进行结合,交互方式简单直观
当驾驶员进行语音对话时,蓝山座舱利用车载摄像头捕捉驾驶员的头部动作,通过点头/摇头进行确定/否定答复。例如语音控制导航时,可通过点头/摇头选择路线规划方案。
案例2
面部+情绪识别:睿蓝7、极狐考拉等车型在面部识别功能上融入情绪识别技术,提供主动交互,增强交互体验
睿蓝7的多模智识Face-ID系统支持唇动识别、情绪识别,能记忆关联账户对应语音、座椅、后视镜、氛围灯、后备箱设置等车辆功能个性化信息,还可根据车主的“脸色”来选择合适的音乐。
极狐考拉位于B柱的摄像头正对后排,可实时监控孩子状态。例如孩子在微笑时将自动抓拍传送至中控屏;哭闹时将自动播放安抚音乐/智能座椅表面呼吸律动,平复孩子情绪。另外,摄像头还可与车内毫米波雷达联动,判断孩子是否睡着,睡着则自动打开睡眠模式,开启座椅通风,空调温度适当调整,音响、氛围灯进行联动,产生律动效果。
案例3
面部+嗅觉:蔚来EC7、睿蓝7等车型实将驾驶员监控系统与香氛系统联动,提升驾车安全性
蔚来EC7监测到驾驶员的疲劳状态时,将自动释放提神醒脑的香氛,以确保驾驶安全;
睿蓝7位于A柱的摄像头监控到驾驶员犯困时,将自动释放提神香氛,并进行语音提醒。
大模型及多模态融合,将推进AI Agent上车
AI大模型正从单模态走向多模态、多任务融合的趋势。相较于单模态只能处理一种类型的数据,例如文本、图像、语音等,多模态则可以处理和理解多种类型的数据,包括视觉、听觉、语言等,从而能够更好地理解和生成复杂的信息。 随着多模态大模型的持续发展,其能力也将得到显著提升。这种提升赋予AI Agent(人工智能体)更强大的感知和环境理解能力,以实现更智能、自主的决策和行动。同时也为汽车领域的应用开拓了新的可能性,为未来的智能化发展提供了更广阔的前景。
图片来源:红杉资本
科大讯飞基于星火大模型开发的星火座舱OS,支持语音、手势、人眼追踪、DMS/OMS等多种交互模态,星火汽车助理通过深度上下文理解实现多意图识别,提供更加自然的人机交互。讯飞星火大模型首搭车型星途星纪元ES,将带来五大全新的体验:车辆功能导师、冷暖共情伙伴、知识百科全书、旅行规划专家、身体健康顾问。

来源:科大讯飞
将于2023年12月上市的AITO问界M9内置HarmonyOS 4车机系统。鸿蒙4中智慧助手小艺已经接入了盘古大模型。华为盘古大模型,包括自然语言大模型、视觉大模型、多模态大模型等。鸿蒙4+小艺+盘古大模型,设备协同、AI场景等生态能力将再度增强,借助多模态交互技术,提供多样化的交互方式,包括语音识别、手势控制、触摸屏操作等。

图片来源:华为
-
语音交互
+关注
关注
3文章
355浏览量
29214 -
声纹识别
+关注
关注
3文章
143浏览量
22423 -
大模型
+关注
关注
2文章
3771浏览量
5271
原文标题:汽车多模态交互研究:大模型及多模态融合,推进AI Agent上车
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
海光DCU完成Qwen3.5多模态MoE模型全量适配

商汤科技正式发布并开源全新多模态模型架构NEO

亚马逊云科技上线Amazon Nova多模态嵌入模型

米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
浅析多模态标注对大模型应用落地的重要性与标注实例
商汤科技多模态通用智能战略思考
“端云+多模态”新范式:《移远通信AI大模型技术方案白皮书》正式发布

研华科技携手创新奇智推出多模态大模型AI一体机

NVIDIA助力图灵新讯美推出企业级多模态视觉大模型融合解决方案
润和软件荣登2025多模态AI大模型排行榜单
汽车多模态交互测试:智能交互的深度验证




评论