 提高TinyML、ML-DSP和深度学习工作负载的能效
提高TinyML、ML-DSP和深度学习工作负载的能效

近来,对实时决策、降低数据吞吐量以及注重隐私的需求,已将人工智能处理的很大一部分工作转移到边缘。这一转变催生了大量边缘人工智能应用,每种应用都有着不同的要求,面临着不同的挑战。
据预测,2025年人工智能SoC市场规模将达到500亿美元(资料来源:Pitchbook Emerging Tech Research),边缘人工智能芯片预计将在这一市场中占据重要地位。
人工智能处理向边缘转移及提高能效势在必行
人工智能处理向边缘转移标志着一系列应用(从物联网传感器到自主系统)进入了实时决策的新时代。这一转移有助于:减少延迟,这对即时响应起到决定性作用;通过本地处理提高数据隐私保证;支持离线功能,确保在远程或具有挑战性的环境中不间断运行。由于这些边缘应用在电池供电的设备上运行,能效有限,因此能效在这一变革中会成为焦点。
边缘人工智能工作负载本质多元
确保边缘人工智能处理能效的关键难题之一是工作负载本质多元。不同应用的工作负载大不相同,带来独特挑战。总体而言,所有人工智能处理工作负载可大致分为TinyML、ML-DSP及深度学习工作负载。
TinyML:声音分类、关键词识别及人体存在检测等任务需要在传感器附近进行低延迟、实时处理。此处涉及的工作负载称为TinyML,牵涉到在资源有限的边缘设备上运行轻量级机器学习模型。TinyML模型专为特定硬件定制,支持顺利执行人工智能任务。定制硬件处理器和高度优化的软件库对于满足TinyML严格至极的功耗要求至关重要。
深度学习:相较而言,深度学习应用程序是一种计算密集型工作负载。此类应用程序涉及运行复杂的计算,通常出现在高级计算机视觉、自然语言处理及其他经典和生成式人工智能密集型任务中。深度学习具有计算密集型特性,通常需要专门的硬件,如神经处理单元 (NPU)。NPU采用多层神经网络结构,能够高效地处理各种复杂的计算任务。NPU可为高级人工智能任务提供所需的计算能力,而且能效很高。
ML-DSP:介于上述两类工作负载之间的是ML-DSP工作负载,涉及DSP处理、过滤及清理信号,然后才能执行人工智能感知任务。雷达属于此类工作负载,是一种涉及点云图像分析的常见应用。
工作负载决定采用的架构
为了应对边缘人工智能工作负载的多面性及其带来的能效挑战,人们开发了各种架构和硬件引擎。为各工作负载选择有针对性的架构和硬件是为了在提供最佳计算性能的同时最大限度地降低功耗。就此而言,TOPS/Watt(每秒万亿次运算/瓦)是常用的能效指标。选择合适的架构来处理TinyML、ML-DSP及深度学习工作负载,是满足所需能效指标的关键。
标量处理架构最适合TinyML工作负载,此类负载通常涉及用户界面管理、基于时间数据制定决策以及非密集型计算需求。矢量处理架构非常适合同时处理多个数据元素的运算,及在人工智能感知之前涉及信号处理的工作负载。张量和矩阵处理架构是涉及复杂矩阵运算、图像识别、计算机视觉及自然语言处理等深度学习任务的理想选择。能够以尽量高的能效高效处理涉及大型矩阵和神经网络的任务。人工智能处理器通常结合利用这些架构来高效处理各种任务。请参阅下图。
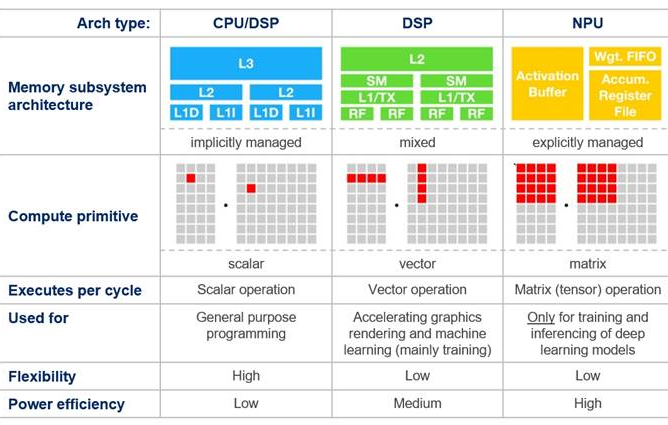
CEVA产品可应对各种人工智能工作负载
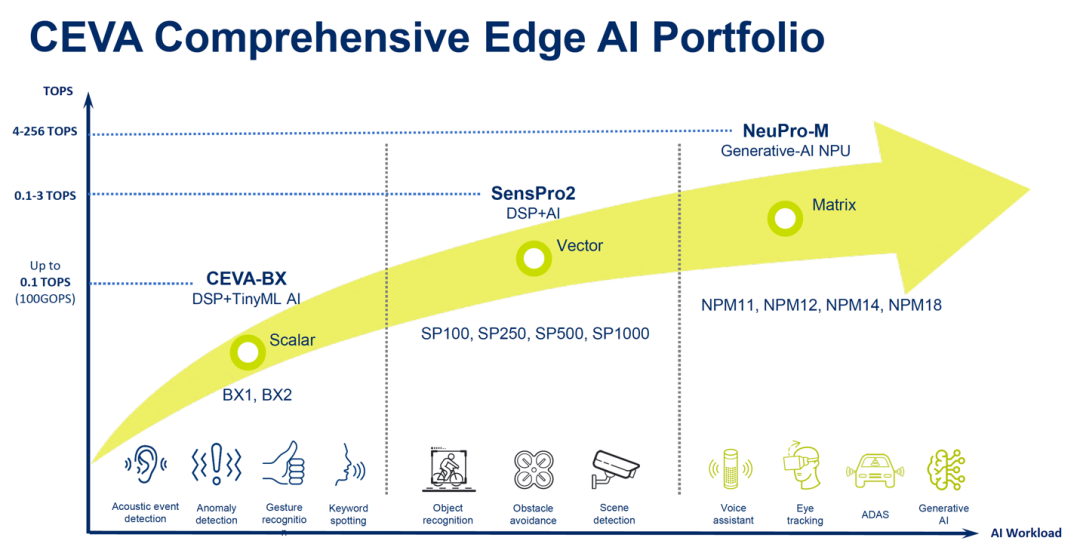
CEVA提供一系列产品,希望满足TinyML、ML-DSP 及深度学习工作负载的需求。我们的产品包括CEVA-BX、SensPro2及NeuPro-M,品质优越,既能支持搭载人工智能功能的边缘设备,也能确保能效。
CEVA-BX处理器高度灵活,能够根据具体应用配置和优化,包括音频、语音处理及人工智能相关的工作负载。其架构旨在实现性能和能效平衡,因此适用于广泛的边缘计算应用。
CEVA的SensPro2是一种高度可配置且独立的矢量DSP架构,针对浮点和整数数据类型进行标量和矢量处理。专为计算机视觉和其他传感器中的并行高带宽数据应用而设计。能够高效处理多达5 TOPS的人工智能工作负载,集成多达1,000个MAC。SensPro2是需要高带宽数据和人工智能处理能力的视觉和雷达系统的合适选择。
CEVA的NeuPro-M是一款神经处理单元(NPU)IP,涵盖在CEVA深度学习人工智能处理器NeuPro系列中。NeuPro-M旨在处理当今大多数经典和生成式人工智能网络模型,包括Transformer。专门针对低功耗、高效率处理优化,包括一个矢量处理单元(VPU)和许多其他异构处理引擎,如稀疏性、压缩和激活逻辑。随着人工智能网络模型快速发展,NeuPro-M凭借内置VPU,可以为边缘人工智能应用提供经得起未来考验的功能。NeuPro-M目前无法处理的更新、更复杂的人工智能网络层,可以利用VPU得到高效管理。
CEVA的音频人工智能处理器、传感器中枢 DSP、NeuPro-M NPU IP以及相关软件工具和开发套件可满足所有边缘人工智能处理工作负载的需求。
本文作者:Moshe Sheier, Vice President of Marketing, CEVA
关于CEVA
CEVA是排名前列的无线连接和智能传感技术以及集成IP解决方案授权商,旨在打造更智能、更安全、互联的世界。我们为传感器融合、图像增强、计算机视觉、语音输入和人工智能应用提供数字信号处理器、人工智能处理器、无线平台、加密内核和配套软件。许多世界排名前列的半导体厂商、系统公司和OEM利用我们的技术和芯片设计技能,为移动、消费、汽车、机器人、工业、航天国防和物联网等各种终端市场开发高能效、智能、安全的互联设备。
我们基于DSP的解决方案包括移动、物联网和基础设施中的5G基带处理平台;摄像头设备的高级影像技术和计算机视觉;适用于多个物联网市场的音频/语音/话音应用和超低功耗的始终开启/感应应用。对于传感器融合,我们的Hillcrest Labs传感器处理技术为耳机、可穿戴设备、AR/VR、PC机、机器人、遥控器、物联网等市场提供广泛的传感器融合软件和惯性测量单元 (“IMU”) 解决方案。在无线物联网方面,我们的蓝牙(低功耗和双模)、Wi-Fi 4/5/6/6E (802.11n/ac/ax)、超宽带(UWB)、NB-IoT和GNSS 平台是业内授权较为广泛的连接平台。
-
dsp
+关注
关注
561文章
8284浏览量
368778 -
CEVA
+关注
关注
1文章
199浏览量
77317 -
ML
+关注
关注
0文章
154浏览量
35548 -
深度学习
+关注
关注
73文章
5613浏览量
124706 -
TinyML
+关注
关注
0文章
45浏览量
1875
原文标题:提高TinyML、ML-DSP和深度学习工作负载的能效
文章出处:【微信号:CEVA-IP,微信公众号:CEVA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
利用TinyML在MCU上实现AI/ML推论工作
开发TinyML系统必须考虑的四大指标
Alif Semiconductor宣布推出先进的BLE和Matter无线微控制器,搭载适用于AI/ML工作负载的神经网络协同处理器

【先楫HPM5361EVK开发板试用体验】:4、TinyML测试(1)
交流充电桩负载能效提升技术
深度学习及无线通信热点问题介绍
什么是TinyML?微型机器学习
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用
优化用于深度学习工作负载的张量程序

微软要让ML.NET框架也能用于开发深度学习应用
TinyML推动深度学习和人工智能发展
机器学习概述、工作原理及重要性
如何在 MCU 上快速部署 TinyML
什么是TinyML?



评论