 Transformer流行的背后
Transformer流行的背后

许多技术公司都在大肆宣扬自己拥有比其他公司更好的处理transformer算法的解决方案。但其实业界transformer的基准测试尚未推出。
Generative AI(GAI)的蓬勃发展已经颠覆了整个AI世界,似乎是这样。
大语言模型(LLM),如ChatGPT所示,大多局限于语言建模和文本生成。但transformer(一种支撑LLM和其他GAI应用的总体深度学习架构)提供了一种可用于文本、语音、图像、3D和视频等数据流或任何传感数据的模型。
Nvidia汽车部门副总裁Danny Shapiro提到了GAI的多功能性,他说:“AI领域新的神奇之处在于它的无限性。而我们现在只触及到了表面。”
与任何新兴技术一样,硅谷也充斥着科技公司大肆宣扬其革命性解决方案的声音。坊间传闻,硅谷也在争相用transformer取代基于卷积神经网络(CNN)的模型。其中一种猜测提到了一家robotaxi公司,该公司刚刚淘汰了其内部设计的汽车芯片,并急于开发一种可以处理transformer的新款芯片。
Quadric是一家机器学习推理IP公司,Untether AI则将其硬件宣传为是“通用推理加速器”,这两家公司都在兜售可处理transformer的技术。Quadric说日本的Denso和Megachip是其客户,而Untether AI则说通用是其技术开发合作方之一。
Quadric的CMO Steve Roddy认为,transformer话题“在过去几周内真正活跃了起来”。他说:“显然,transformer总体上已经初具规模了,因为每个人都在玩生成式图像或ChatGPT等等。但到目前为止,LLM类型的东西都是在云端运行的,因为它们涉及数十亿个参数。”
Qualcomm因素
Roddy说:“尽管如此,人们现对‘设备端(on-device)’的transformer的关注要迫切得多。他猜测,引发这一变化的是Qualcomm。Qualcomm上月宣布了其2024年计划,即在智能手机和PC上提供Meta的新聊天工具、基于Llama 2的AI。
Qualcomm表示,其目的是“让开发者能够利用Snapdragon平台的AI功能,迎来全新的、令人兴奋的GAI应用”。Qualcomm的这一声明让Roddy和其他行业玩家感到不安。为什么要等到2024年?
越来越多的人猜测,Apple可能会率先采用设备端的transformer。今年秋季发布的新款iPhone能否实现这一目标?这是人们无法证实的猜测。
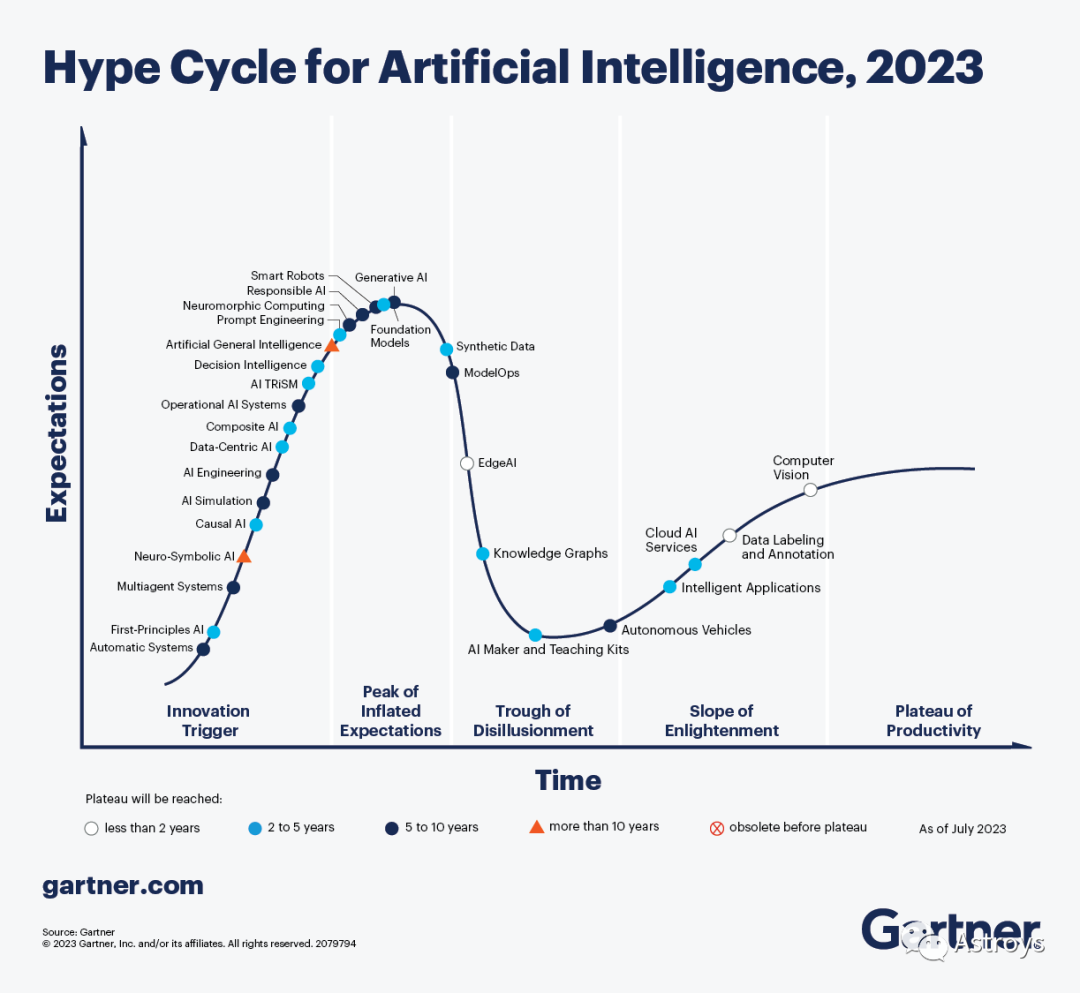
Gartner认为,GAI主导了有关AI的讨论,利用ChatGPT等系统以非常实际的方式提高了开发者和知识工作者的工作效率,该公司上周宣布,市场趋势正在将GAI推向“Hype Cycle中的预期膨胀高峰”。
工程咨询公司BDTI总裁、Edge AI and Vision Alliance创始人Jeff Bier在被问及一些公司吹嘘的transformer芯片时持谨慎态度。他说:“我们已经看到了相当可信的说法。但我们尚未对这些说法进行独立验证。就实际应用而言,transformer在很大程度上仍然处于领先地位。”
BDTI从事处理器基准测试(benchmarking)。不过,他说:“我们还没有对transformer或LLM进行任何处理器基准测试……我们刚刚收到第一批请求。”
什么是transformer?
首先,了解transformer模型到底是什么很重要。
在处理输入流时,与传统神经网络相比,transformer模型基于不同算法,使用不同的方法。该模型侧重于“关系”。
在自然语言处理(如ChatGPT)中,transformer模型(最初应用于LLM)是一种神经网络,用于查找和跟踪输入句子之间的关系,从而学习上下文和含义。
BDTI的高级工程师Mihran Touriguian说:“transformer非常适合查找输入之间的关系。即使输入之间的关系在时间或地点上相距甚远,该模型也能发挥作用。”
人们对transformer的兴趣之所以如此高涨,是因为它们与输入流无关。Touriguian解释说,该模型不仅可以应用于语言,还可以应用于视频或被分割成块的单一大型图像。
与其他模型相比,transformer的优势在于能找到图像中多个时间或位置输入之间的“关系”。Touriguian指出:“如果你的应用中使用了不同类型的传感器,那么transformer就非常适合。这些‘传感器’可以是图像、文本或语音。Transformer非常适合将不同的数据流结合到一个应用中。”
与数据类型无关
以往的神经网络模型需要单独的算法或拓扑结构来处理每种数据类型。Touriguian说:“在后端或前端,你可以将信息组合起来进行预测。”
与此相反,“transformer与输入类型无关”,他解释道。“因此,你可以将产生数据的多种类型传感器输入transformer。transformer基本上可以找到它们之间的关系,例如语音、图像和标题(文本)之间的关系。”
例如,在车载应用中,关键的输入数据流来自各种类型的传感器,摄像头、雷达和激光雷达都至关重要。Transformer如果能像承诺的那样发挥作用,就能将来自不同传感器的信息结合起来,为汽车提供更好的决策和解决方案。
但,我们还没有做到
然而,现实世界还没有实现这一愿景。要实现这一目标,transformer必须先进行大量的准备工作,即对输入数据进行预处理。Touriguian说,你需要“对输入的类型进行规范化”,这个过程被称为“嵌入(embedding)”,它捕捉并存储语言或其他数据流的意义和关系。它们是模型比较不同标记或数据输入的方式。
Touriguian说,在神经网络中,来自任何传感器的任何输入都必须转换为包含一定数量元素的矢量。这种规范化是transformer在多种类型传感器上运行的关键步骤。
Transformer面临的另一个障碍是其所依赖的庞大的参数和权重(数以亿计)。不过,Touriguian表示,最近这些参数已经缩小到与CNN模型相当的大小。他补充道,在精度方面,transformer与基于CNN的模型相同或略胜一筹。
然而,值得注意的是,研究人员和开发者已经意识到,通过结合CNN和transformer的优势,他们可以取得更好的结果,Touriguian指出,“CNN部分在图像上的表现非常出色,因为CNN关注的是相邻像素之间的关系。同时,在此基础上,transformer基本上可以找到这些邻域与图像中其他区域之间的关系。”
Transformer在车载领域中的应用
Transformer可以应用在哪里以及如何应用,似乎没有限制,从销售工具、聊天框、翻译到设计/工程、工厂和仓储……
例如,ChatGPT可以在车载中最明显的应用之一,就是让新手司机无需阅读数百页的使用手册,就能向汽车问:“嘿,XX,我该如何换轮胎?”
训练数据是另一个重要的应用领域。Nvidia的Shapiro举例说,GAI生成合成数据的能力可以用来向汽车的感知系统输入“一堆停车标志的图像”(有的上面有涂鸦,有的已经风化、生锈,有的被树木遮挡)。
他补充说,ViT、SwinTransformer、DETR、Perceiver等流行的视觉transformer目前已广泛应用于自动驾驶软件栈中。此外,GPT等LLM DNN可用于座舱应用,以自然、直观的方式向车内的人提供信息。他表示,Nvidia Drive“能够在车内部署运行这些复杂的视觉transformer和LLM”。
Transformer硬件需要什么?
Bier指出,如今,一些专注于边缘或嵌入式处理的AI硬件更加专业化,更偏爱CNN等成熟模型。另一些则更加灵活,更容易适应transformer。
Bier强调说:“这种适应性取决于两点。一是架构本身。另一个是支持它的软件工具和库。”
凭借其GPNPU架构Chimera所独有的IP,Quadric是一家声名显赫的AI IP供应商,其架构被宣传为能够“运行任何机器学习图形,包括最新的视觉transformer”。
Quadric声称,Chimera结合了神经加速器(NPU)和DSP的最佳特性,提供经典代码和图形代码的混合。Quadric的Roddy强调说,这对软件开发者尤为重要,因为他们希望“只需混合和匹配预构建的应用代码构件”。
Roddy认为,Quadric的优势在于它能够运行不同的内核来完成不同的任务(经典的DSP代码任务、经典神经网络kernel(包括检测器和验证器),以及介于两者之间的类似CPU的任务),所有这些都可以在Quadric的“单处理器”上完成。Roddy解释说:“无需多个引擎。实际只有一个处理器、一个执行流水线、一个代码流,所有这些都编译在一起。”
这与许多芯片设计者对机器学习出现的反应形成了鲜明对比。他们部署了一大块NPU加速器,并将新的加速器添加到SoC上已有的DSP和CPU内核中。

Roddy说,他们意识到无法在CPU或DSP上运行最新版本的ResNet(Residual Neural Network),“因为它太强大了”。这导致大多数公司创建了一个复杂的架构,迫使程序员“每年都要进行越来越高的抽象”,并对每个块的内存大小和工作负载分区进行“细致入微的思考”。结果导致了漫长的开发周期。
然后是transformer。
对于正在努力开发AI硬件的芯片公司来说,这无疑又是一记响亮的耳光。对于芯片设计师和程序员来说,本已复杂的局面变得更加混乱。Quadric说:“Transformer打破了你对传统NPU加速器的认知。”
Quadric认为,与以往的神经网络算法相比,视觉transformer“在网络拓扑结构和构件运算符方面大不相同”。该公司建议,“如果你的传统NPU无法处理视觉transformer,那么Quadric的GPNPU会更好”。
DNN以外的数学
Untether AI正在宣传其芯片对transformer的适应性。产品副总裁Bob Beachler说:“与两三年前相比,我在视觉应用中看到了更多的transformer式网络,当时大家都专注于CNN。”
因为Untether AI“一直在研究自然语言处理”,而自然语言处理是一种attention transformer式网络。Beachler称:“我们可以把为自然语言处理投入的相同电路用于基于视觉的transformer应用。”
当被问及Untether AI是否只是运气好时,Beacher回避了。他说,这个故事的寓意是“不要过度限制你的AI加速、AI应用”。
他指出:“我也看到一些初创公司在尝试进行特定类型的数学运算、棘手的数学变换。当你开始这样做时,你可以进行大量的数学变换,但你也开始失去精度。最终,你的芯片可能只能运行一次。”
要设计出能处理transformer式算法的处理器,最重要的是什么?
除了在处理器中加入灵活性之外,Beachler还强调,芯片必须处理DNN处理之外所需的所有数学运算,“比如视频缩放、激活和边界框的非最大值抑制。所有这些类型的事情都需要一种更通用的方法”。
BDTI的Bier表示赞同。他说,需要牢记的一个关键是,“现实世界中的大多数应用并不是简单地获取数据并将其输入某种DNN。它们需要使用非神经网络技术(如经典图像和信号处理技术)进行某种预处理。然后,再应用一个或多个DNN。然后再应用额外的经典算法,如跟踪算法。”
-
机器学习
+关注
关注
67文章
8562浏览量
137209 -
深度学习
+关注
关注
73文章
5604浏览量
124617 -
Transformer
+关注
关注
0文章
156浏览量
6961
原文标题:Transformer流行的背后
文章出处:【微信号:Astroys,微信公众号:Astroys】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
电子工程师视角下的SAFETY ISOLATING TRANSFORMER
FT 5000 Smart Transceiver与FT - X3 Communications Transformer:智能网络新选择
Transformer 入门:从零理解 AI 大模型的核心原理

Transformer如何让自动驾驶大模型获得思考能力?
深入解析HVMA03F40C - ST10S Flyback Transformer
中科曙光解码流行语背后的发展密码
Transformer如何让自动驾驶变得更聪明?
图解AI核心技术:大模型、RAG、智能体、MCP
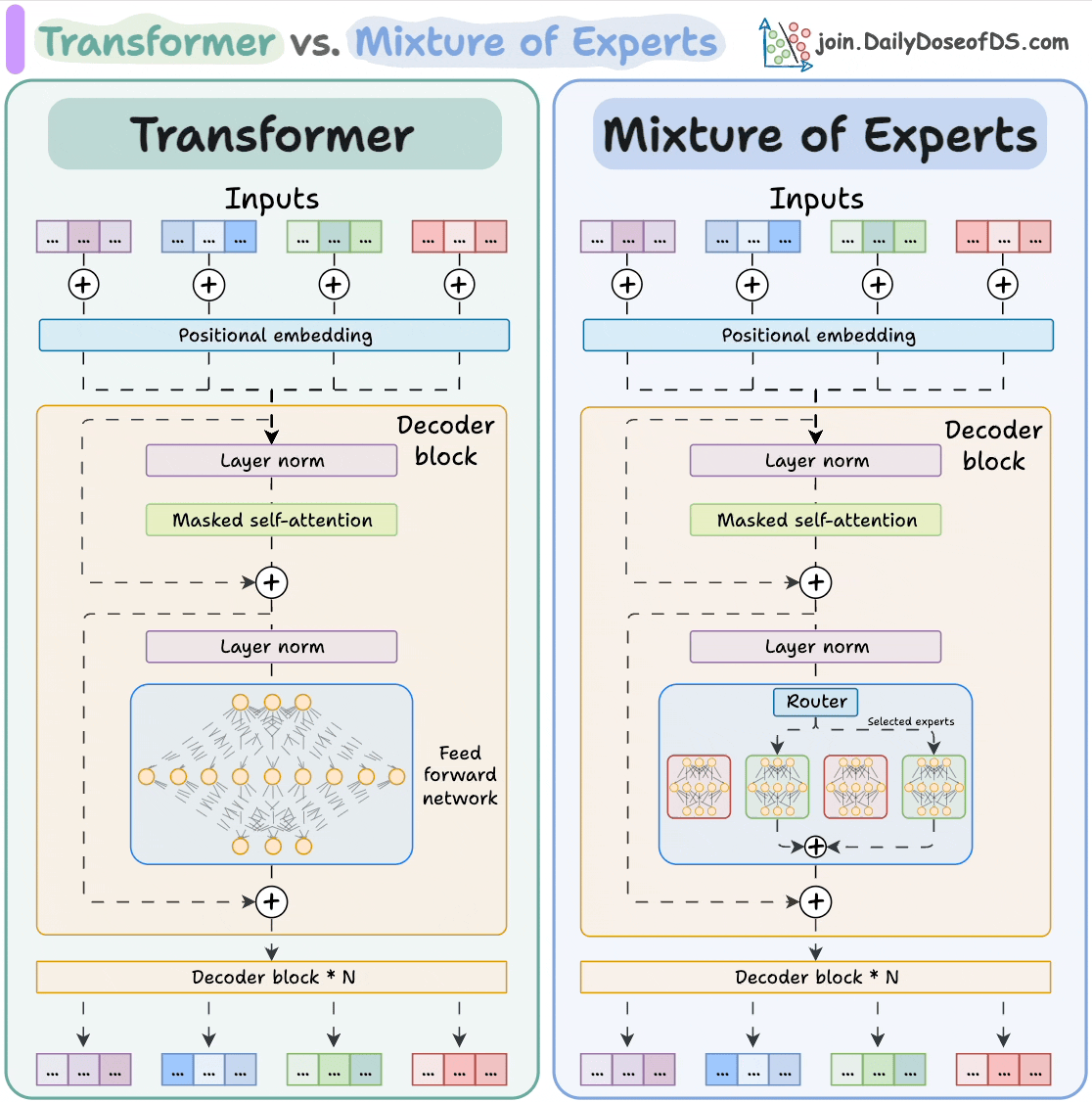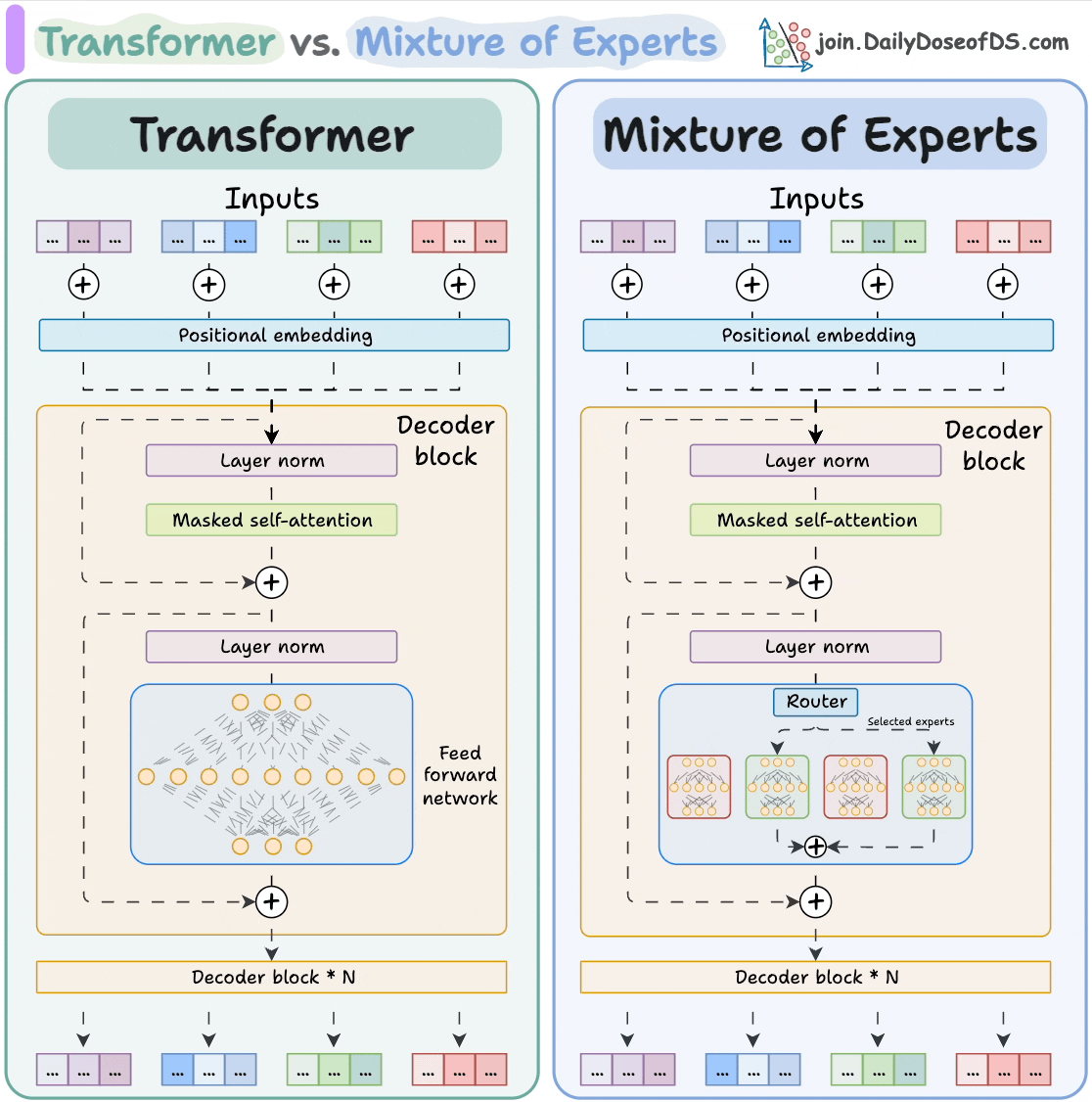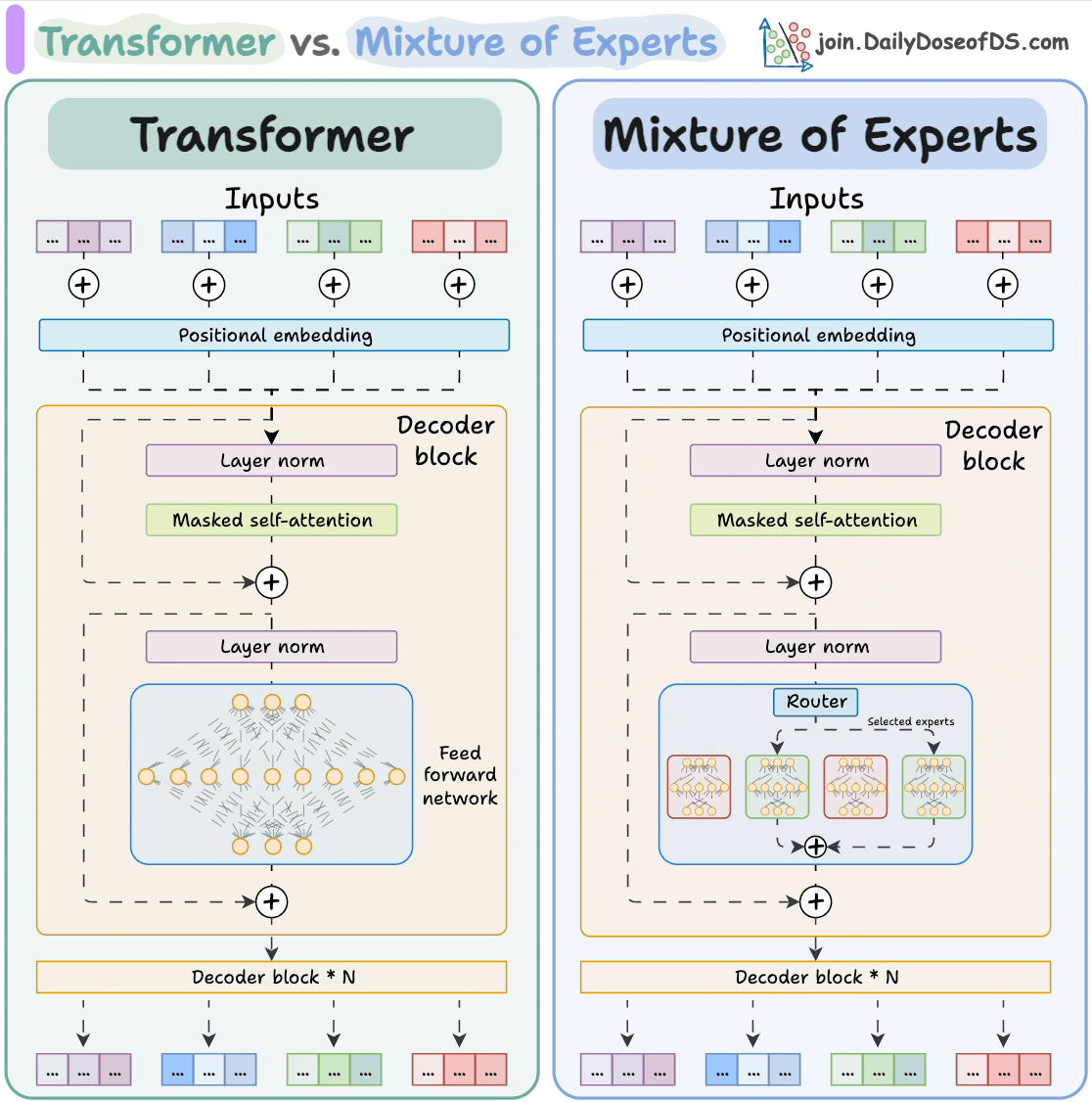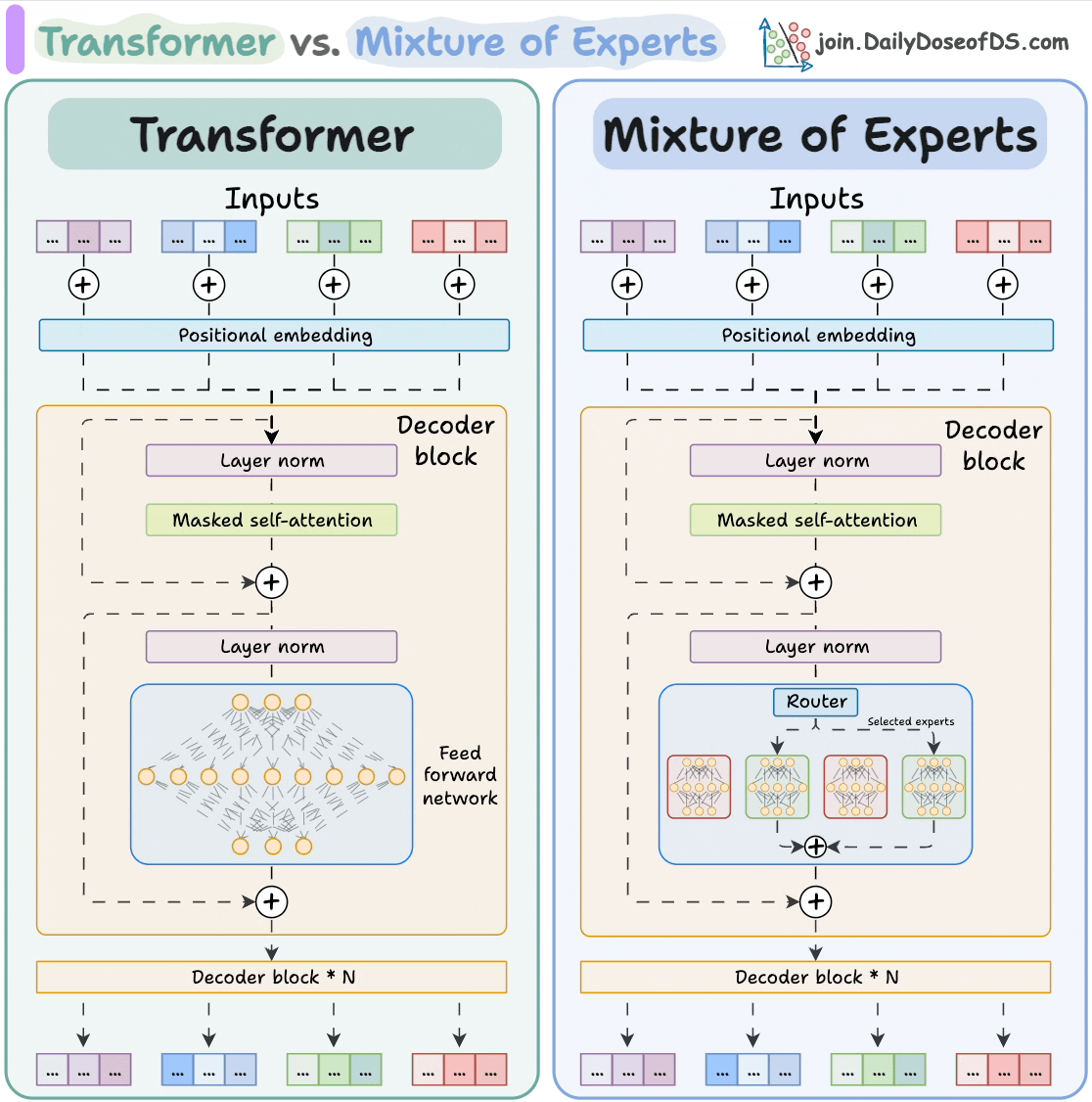

自动驾驶中Transformer大模型会取代深度学习吗?

Transformer在端到端自动驾驶架构中是何定位?
Transformer架构中编码器的工作流程

Transformer架构概述





评论