 如何利用大模型构建知识图谱?如何利用大模型操作结构化数据?
如何利用大模型构建知识图谱?如何利用大模型操作结构化数据?

Part 01 利用大模型构建知识图谱
上图是之前,我基于大语言模型构建知识图谱的成品图,主要是将金融相关的股票、人物、涨跌幅之类的基金信息抽取出来。之前,我们要实现这种信息抽取的话,一般是用 Bert + NER 来实现,要用到几千个样本,才能开发出一个效果相对不错的模型。而到了大语言模型时代,我们有了 few-shot 和 zero-shot 的能力。
这里穿插下 few-shot 和 zero-shot 的简单介绍,前者是小样本学习,后者是零样本学习,模型借助推理能力,能对未见过的类别进行分类。 因为大语言模型的这种特性,即便你不给模型输入任何样本,它都能将 n+ 做好,呈现一个不错的效果。如果你再给模型一定的例子,进行学习:
is_example={
'基金':[
{
'content':'4月21日,易方达基金公司明星基金经理张坤在管的4只基金产品悉数发布了2023年年报'
'answers':{
'基金名称':['易方达优质企业','易方达蓝筹精选'],
'基金经理':['张坤'],
'基金公司':['易方达基金公司'],
'基金规模':['889.42亿元'],
'重仓股':['五粮液','茅台']
}
}
],
'股票':[
{
'content':'国联证券04月23日发布研报称,给予东方财富(300059.SZ,最新价:17.03元)买入评级...'
'answers':{
'股票名称':['东方财富'],
'董事长':['其实'],
'涨跌幅':['原文中未提及']
}
}
]
}
就能达到上述的效果。有了大语言模型之后,用户对数据的需求会减少很多,对大多数人而言,你不需要那么多预算去搞数据了,大语言模型就能实现数据的简单抽取,满足你的业务基本需求,再辅助一些规则,就可以。 而这些大语言模型的能力,主要是大模型的 ICL(In-Context Learning)能力以及 prompt 构建能力。ICL 就是给定一定样本,输入的样本越多,输出的效果越好,但是这个能力受限于模型的最大 token 长度,像是 ChatGLM-2,第一版本只有 2k 的输入长度。像是上面的这个示例,如果你的输入特别多的话,可能很快就达到了这个模型可输入的 token 上限。
当然,现在有不少方法来提升这个输入长度的限制。比如,前段时间 Meta 更新的差值 ORp 方法,能将 2k 的 token 上限提升到 32k。在这种情况下,你的 prompt 工程可以非常完善,加入超多的限制条件和巨多的示例,达到更好的效果。
此外,进阶的大模型使用的话,你可以采用 LoRA 之类的微调方式,来强化效果。如果你有几百个,甚至上千个样本,这时候辅助用个 LoRA 做微调,加一个类似 A100 的显卡机器,就可以进行相关的微调工作来强化效果。
Part 02 利用大模型操作结构化数据

结构化数据其实有非常多种类,像图数据也是一种结构化数据,表数据也是一种结构化数据,还有像是 MongoDB 之类的文档型数据库存储的数据。Office 全家桶之前就在搞这块的工作,有一篇相关论文讲述了如何用大模型来操作 Sheet。
此外,还有一个相关工作是针对 SQL 的。前两年,有一个研究方向特别火,叫:Text2SQL,就是如何用自然语言去生成 SQL。
大家吭哧吭哧做了好几年,对于单表的查询这块做得非常好。但是有一个 SQL 困境,就是多表查询如何实现?多表查询,一方面是没有相关数据,本身多表查询的例子就非常少,限制了模型提升;另一方面,多表查询本身就难以学习,学习条件会更加复杂。
而大语言模型出来之后,基于 GPT-4,或者是 PaLM 2 之类的模型,去训练一个 SQL 版本的模型,效果会非常好。SQL-PaLM 操作数据库的方式有两种。一是在上下文学习(In-context learning), 也就是给模型一些例子,包括数据库的 schema、自然语言的问题和对应的 SQL 语句,然后再问几个新问题,要求模型输出 SQL 语句。另一种方式是微调(fine-tuning),像是用 LoRA 或者是 P-tuning。

上图就是一个用 Prompt 工程来实现 Text2SQL,事先先把表的 schema 告诉大模型,再提问,再拼成 SQL…按照这种方式给出多个示例之后,大模型生成的 SQL 语句效果会非常好。还有一种就是上面提到的微调,将 schema 和 question 组合成样本对,让大模型去学习,这时候得到的效果会更好。具体可以看下 SQL-PaLM 这篇论文,参考文末延伸阅读;
此外,还有更进阶的用法,和思为之前举的例子有点相似,就是大模型和知识图谱结合。
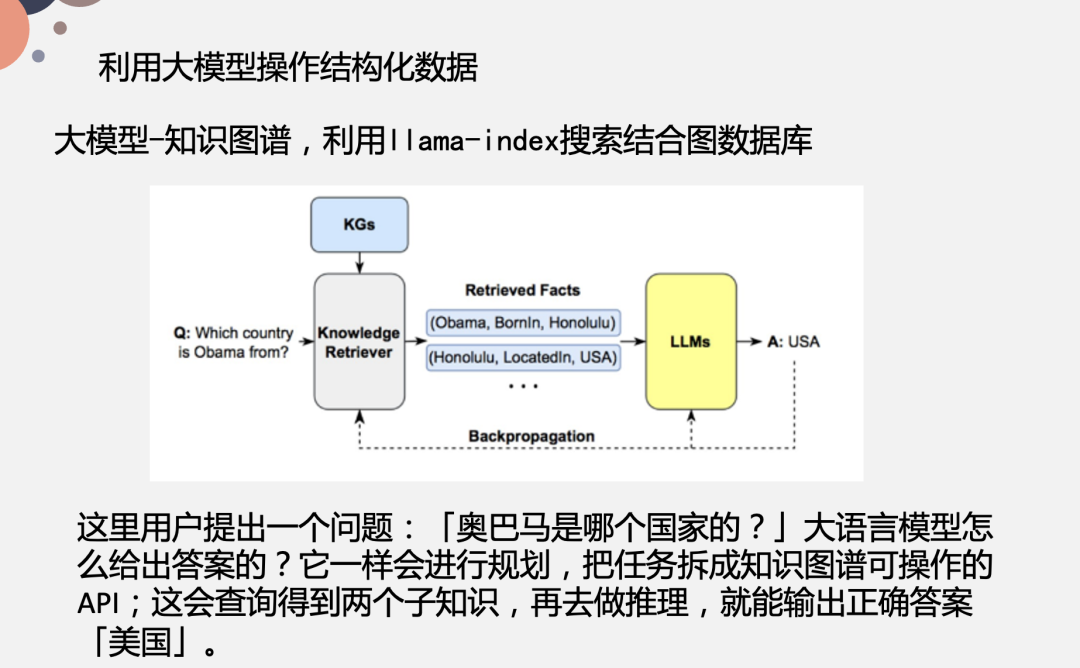
比如说,我想问“奥巴马出生在哪个国家“,它就是构建知识图谱 KQs,再进行一个召回,而召回有很多种方法,比如之前思为分享的 Llama Index 的向量召回,而向量召回最大的难点在于模型,像 OpenAI 提供的模型,效果会比较好,但是数据量大的时候,频繁调用 OpenAI API 接口一方面涉及到隐私问题,另一方面涉及到预算费用问题;而自己要训练一个模型,不仅难度大,由于数据量的原因,效果也不是很好。因此,如果你是借助 Llama Index 的向量模型进行召回,可能需要辅助一些额外的关键词模型,基于关键词匹配来进行召回,像是子图召回之类的。
对应到这个例子,系统需要识别出关键词是 Obama 和 Country,关联到美国,再进行召回。这样处理之后,将相关的事实 Retrieved Facts 喂给大模型,让它输出最终的结果。在 Retrieved Facts 部分(上图蓝色部分),输入可能相对会比较长,在图中可能是一个三元组,这样就会相对比较简单。这里还会涉及到上面说的 2k 输入 token 提升问题,还是一样的通过一些微调手段来实现。
Part 03 大模型使用工具
下面就是本文的重头戏——大模型的使用工具。什么是大模型工具?你可以理解为它是把一些复杂操作集成到一起,让大模型做一个驱动。
举个例子,ChatGPT 刚出来的时候,会有人说“给我点一个披萨”,这当中就涉及到许多复杂的操作。
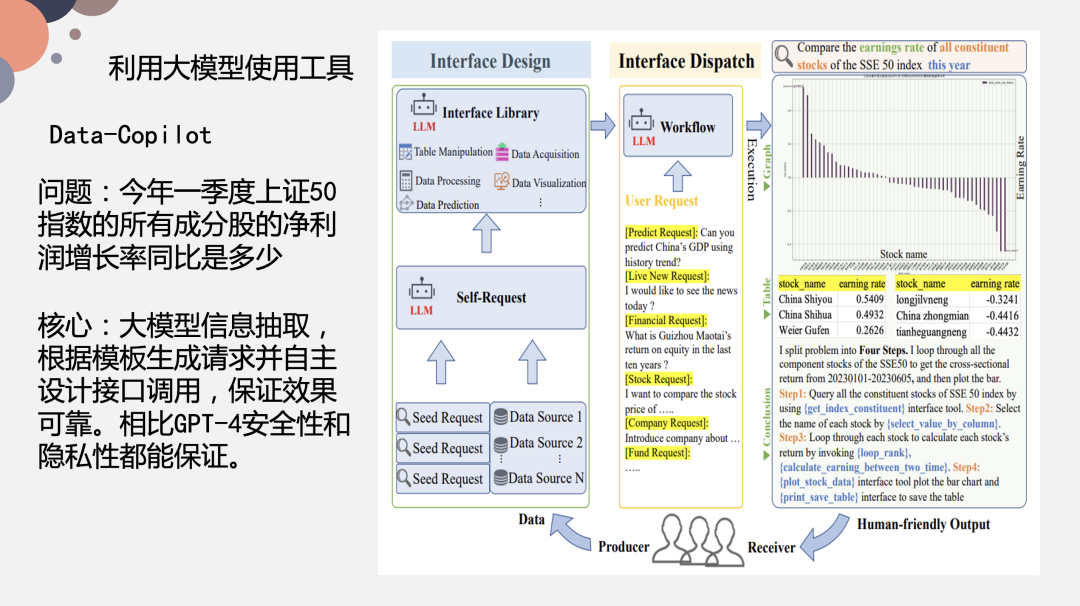
Data-Copilot 是浙大某个团队做的大模型工具,主要是做意图识别和信息抽取。上图右侧是“输入一句话,把相关的图绘制出来”的效果展示,这里就要提取一句话中的关键词信息,关键词信息识别之后去对应的数据库中找对应的数据,找到数据之后进行数据处理,最后再生成一个图。这里并没有用到图数据库,而是直接基于 2Sheet 接口来实现的。
这里我们向这个模型提出一个需求“今年上证50指数的所有成分股的净利润增长率同比是多少”,这个模型会将其解析成对应的一个个步骤进行操作。上图右侧显示了一共有 4 步:
Step1 解析关键指标;
Step2 提取相关数据;
Step3 数据处理,整理成对应格式;
Step4 绘制成图;
而大模型是如何实现的呢?主要分为两层,一方面你要设计一个接口调用,供 prompt 调用;另一方面准备好底层数据,它可能是在图数据库中,也可能在关系型数据库中,给接口做承接之用。

这个例子更加复杂,是想让大模型来预测中国未来(下四个季度)的 GDP 增长。这里看到它分成了三部分(上图橙色部分):
Step1 拿到历史数据;
Step2 调用预测函数,它可能是线性函数,也可能是非线性函数,也有可能是深度学习模型;
Step3 绘制成图(上图蓝色部分);
一般来说,金融分析师做相关的金融数据分析的模型会相对统一,这种相对统一的模型我们用函数实现之后,就可以让他的工作更加便捷:分析师只要说一句话,图就画好。
Part 04 大模型的最终形态
上面展示的形态,基本上人工痕迹还是很明显的:prompt 要人为写,数据接口也得人为写。而我觉得它最终的形态,可能同 GPT4 的形态有点相似,像是前段时间出的 Code Interpreter,代码编译器功能。你只用一句话,后面所有的功能都实现完了。
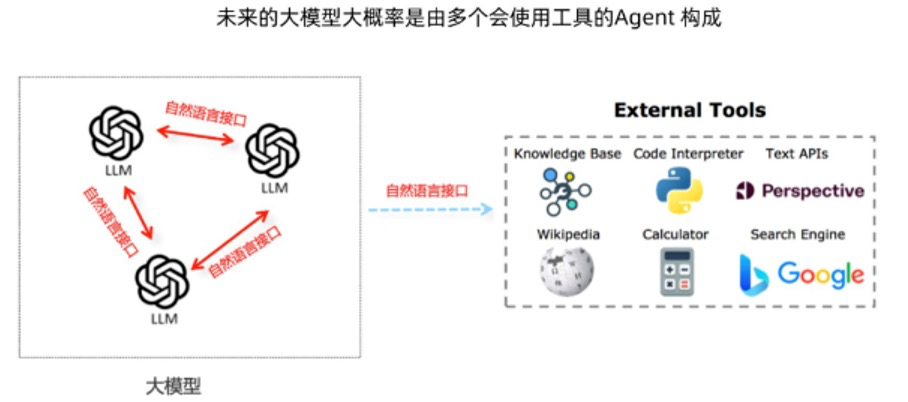
大概实现过程就是上图所示的,用 LLM 作为接口,把整个百科、计算器、搜索、编译器、知识图谱等等接入进来,从而最终实现画图的功能。
而它的最终效果是怎么样的呢?下面是国际友人在推特上 po 出的一张图:
就那么简单,你不需要额外地搞 API,就能实现一个功能。
审核编辑:刘清
-
SQL
+关注
关注
1文章
807浏览量
46940 -
GPT
+关注
关注
0文章
373浏览量
16971 -
数据存储器
+关注
关注
1文章
70浏览量
18175 -
LoRa技术
+关注
关注
3文章
113浏览量
17390
原文标题:LLM:大模型下的知识图谱另类实践
文章出处:【微信号:智行RFID,微信公众号:智行RFID】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
KGB知识图谱基于传统知识工程的突破分析
KGB知识图谱技术能够解决哪些行业痛点?
知识图谱的三种特性评析
KGB知识图谱帮助金融机构进行风险预判
KGB知识图谱通过智能搜索提升金融行业分析能力
一种融合知识图谱和协同过滤的混合推荐模型

《无线电工程》—基于知识图谱的直升机飞行指挥模型研究
基于本体的金融知识图谱自动化构建技术
大型语言模型与知识图谱:机遇与挑战

知识图谱与大模型结合方法概述
利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(下)




评论