 知识图谱与训练模型相结合和命名实体识别的研究工作
知识图谱与训练模型相结合和命名实体识别的研究工作

本次将分享ICLR2021中的三篇投递文章,涉及知识图谱与训练模型相结合和命名实体识别(NER)的研究工作。
文章概览
知识图谱和语言理解的联合预训练(JAKET: Joint Pre-training of Knowledge Graph and Language Understanding)。该论文提出了知识图谱和文本的联合训练框架,通过将RoBERTa作为语言模型将上下文编码信息传递给知识图谱,同时借助图注意力模型将知识图谱的结构化信息反馈给语言模型,从而实现知识图谱模型和语言模型的循环交替训练,使得在知识图谱指导下的预训练模型能够快速适应新领域知识。
语言模型是开放知识图谱(Language Models are Open Knowledge Graphs)。该论文提出了能够自动化构建知识图谱的Match and Map(MAMA)模型,借助预先训练好的语言模型中的注意力权重来提取语料中的实体间关系,并基于已有的schema框架自动化构建开放性知识图谱。
命名实体识别中未标记实体问题的研究(Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition)。论文探究了未标注实体问题对NER实验指标的影响,并提出了一种负采样策略,通过改进损失函数,将为标注实体当作负样本训练,从而极大改善了未标注实体问题对NER实验指标的影响。
论文细节
1
论文动机
现有的将知识图谱与预训练模型相结合的研究工作还存在挑战:当预先训练好的模型与新领域中的知识图谱结合微调时,语言模型难以高效学习到结构化的实体关系语义信息。同时知识图谱的理解推理能力也需要上下文的辅助。基于此,论文提出了一个联合预训练框架:JAKET,通过同时对知识图谱和语言建模,实现两个模型之间的信息互补和交替训练。方法1. 知识模块(Knowledge Module,KM)知识模块主要是对知识图谱进行建模,生成含有结构化信息的实体表示。采用图注意力模型和组合算子思想来聚合实体嵌入和关系嵌入信息。在第L层的实体V的嵌入信息传播公式为:
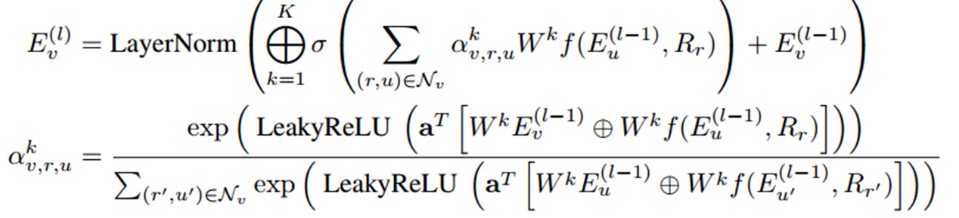
考虑到计算过程中可能会出现的实体数爆炸问题,实验采用了设置minibatch领域采样的方法获取多跳邻居集合。2. 语言模块(Language Module,LM)语言模块主要是对文本建模,学习文本的嵌入表示。采用RoBERT-base作为预训练模型。3.解决循环依赖问题(Solve the syclic dependency)由于LM和KM是互相传递信息的,训练过程存在循环依赖问题,不便于后续计算优化。论文提出了分解语言模型解决此问题,即将LM分解为LM1和LM2子模块,将RoBERT的前6层和后6层分别作为LM1和LM2,实现LM1,KM和LM2的联合训练。整体框架如下图所示。
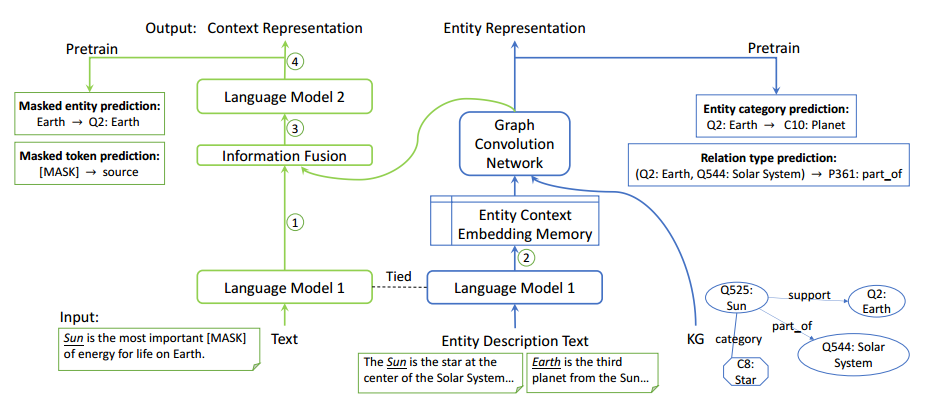
实验结果论文在实体类别预测、关系类别预测、词块掩码预测、实体掩码预测4个任务上进行预训练,并在小样本关系分类、KGQA和实体分类这3个下游任务上进行实验。实验结果分别如下图所示:
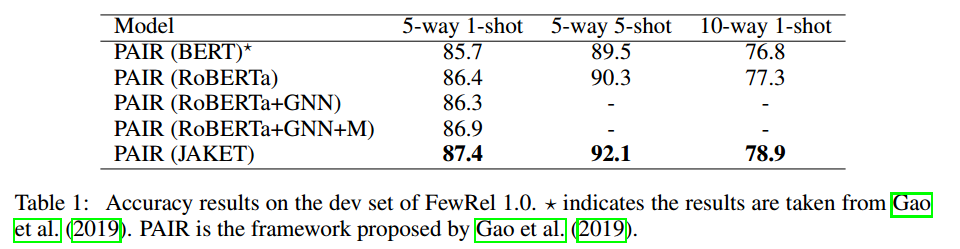
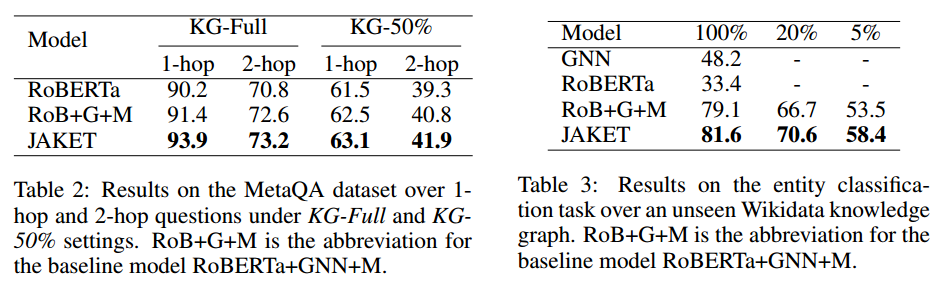
由实验结果可知,在3个任务中论文提出的JAKET都可以进一步提高性能,并且联合预训练可以有效减少模型对下游训练数据的依赖。
2

论文动机
知识图谱的构建方法通常需要人工辅助参与,但是人力成本太高;
同时BERT等预训练模型通常在非常大规模的语料上训练,训练好的模型本身包含常识知识,这些知识可以促进上层的其他应用。
所以本论文提出了一种无监督的Match and Map(MAMA)模型,来将预训练语言模型中包含的知识转换为知识图谱。
方法
1. 匹配(Match)

Match阶段主要是自动抽取三元组。对于输入的文本,使用开源工具抽取出实体,并将实体两两配对为头实体和尾实体,利用预训练模型的注意力权重来提取实体对的关系。通过beam search的方法搜索多条从头实体到尾实体的路径,从而获取多个候选的三元组。再通过设置一些限制规则过滤掉不符常理的三元组,即得到用于构建知识图谱的三元组。
2. 映射(Map)
Map阶段主要是将Match阶段抽取到的三元组映射到知识图谱中去。利用成熟的实体链接和关系映射技术,将三元组映射到已有的固定schema图谱中。对于部分映射或完全不匹配的三元组,就构建开放schema的知识图谱,并最后将这两类知识图谱融合,得到一个灵活的开放性知识图谱。
整体框架如下:
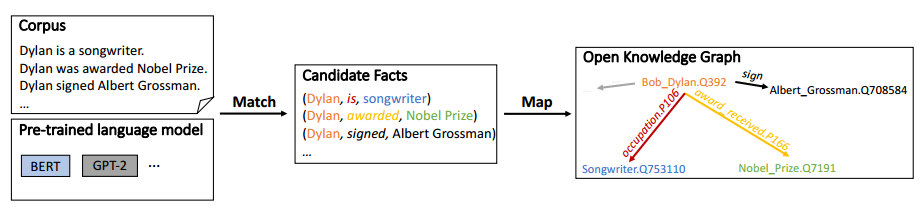
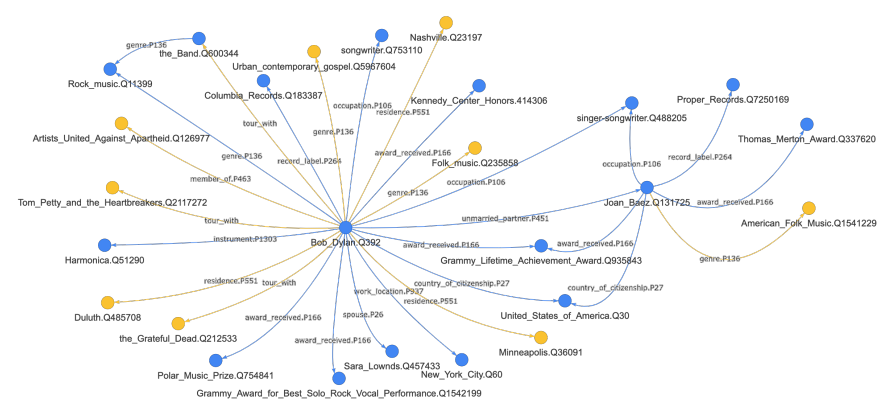
论文中使用BERT-large对Wikipedia语料进行自动化构建知识图谱,图谱效果如下:
实验结果
论文在TAC KBP和Wikidata数据集上进行槽填充任务实验。
在TAC KBP数据集上的结果如下表:
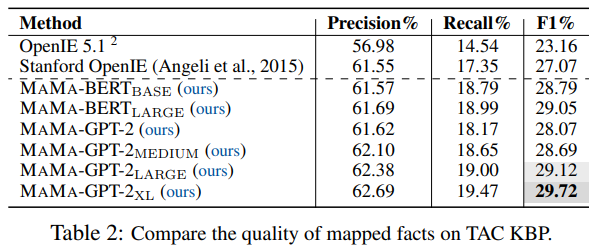
基于TAC KBP数据集的实验结果主要有两点:一是MAMA模型能够提升知识图谱的槽填充效果;二是更大/更深的语言模型能够抽取出更高质量的知识图谱。
在Wikidata数据集上的结果如下表:
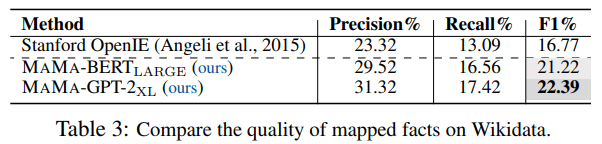
基于Wikidata数据集的实验结论一方面说明MAMA可扩展到更大的语料库,另一方面说明MAMA能从更大规模的语料库中抽取出更完整的知识图谱。
3

论文动机
实体未标注问题是命名实体识别(NER)任务中的常见问题,且该问题在实际情况中无法完全避免。既然无法彻底解决实体未标注问题,那么该问题是否会对NER模型产生影响呢?若产生较大影响,如何将这种消极影响尽量降低?
基于上述问题,论文分析了未标注实体问题对NER实验指标的影响及其原因,并提出了一种具有鲁棒性的负采样策略,使得模型能够保持在未标注实体概率极低的状态下训练,从而提升实体标注效果。
方法
1.合成数据集(Synthetic Datasets)
通过在标注完善的CoNLL-2003和OntoNotes5.0数据集按照一定概率随机掩盖标注出的实体,获取人工合成的欠完善标注数据集。
2.衡量指标(Metrics)
文章中设计了侵蚀率(erosion rate)和误导率(misguidance rate)2种指标来测算NER中未标注实体问题的影响。
侵蚀率代表实体标注量减少对NER指标下降的影响程度。
误导率代表未标注实体对当作负样本时对NER指标下降的影响程度。
3.负采样(Negative Sampling)
文章采用负采样的方式进行降噪,对所有的非实体进行负采样,采样负样本进行损失函数的计算。改进后的损失函数如下所示:
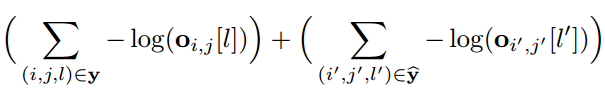
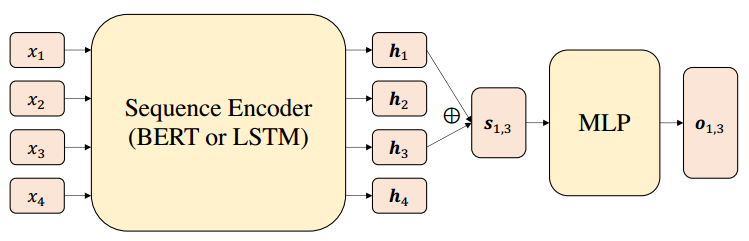
其中前半部分表示标注实体集合的损失,后半部分则是负采样实体集合的损失。文章的整体模型框架如下图所示,总体就是BERT/LSTM编码+softmax的思路。
实验结果
文章在合成数据集上进行NER任务实验,分析未标注问题的影响和负采样的训练效果。
首先是分别基于CoNLL-2003和OntoNotes5.0合成数据集进行的实验结果:
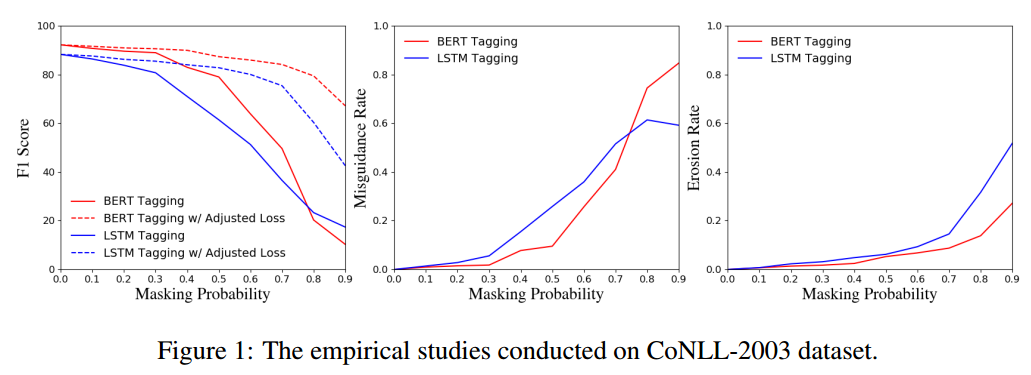
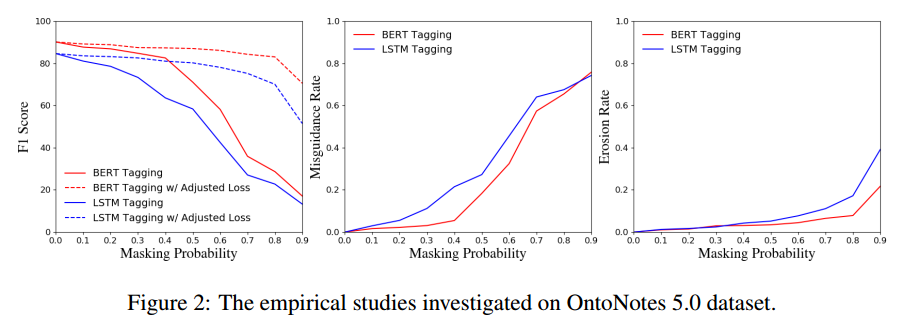
由图可知:随着实体掩盖概率p增大,即未标注实体数量增多,NER指标下降明显;在p很低的时候,误导率就较高了,而侵蚀率受影响较小,说明把未标注实体当作负样本训练、对NER指标下降的影响程度很大,实体标注量减少对指标下降的影响较小
其次将文章提出的负采样训练模型与其他SOTA模型分别在完全标注数据集和真实数据集上做对比,实验结果如下:
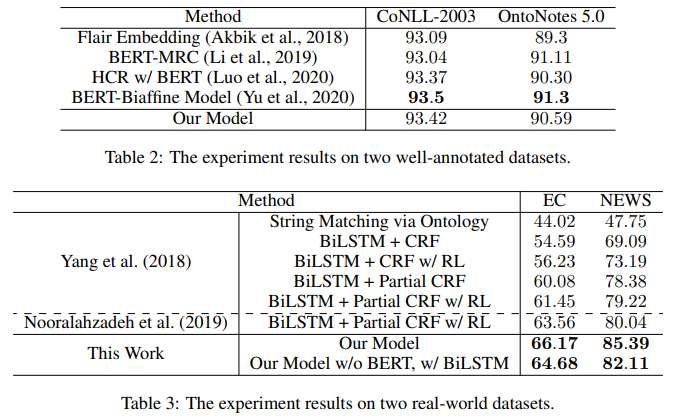
结果表明本模型在完全标注数据集上的效果和其他模型相差不大,并且真实世界数据集上的效果远优于其他的模型,所以本文模型的综合效果最好。
总结
此次解读的三篇论文围绕知识建模和信息抽取的研究点展开。感觉知识图谱结合语言模型的相关研究的趋势是尝试使用同一套编码系统,同时对语言模型中的上下文信息和知识图谱中的结构化语义信息进行编码和训练,从而实现知识融合或知识挖掘。此外,第三篇文章主要想给广大做知识图谱方向的研究者分享一个命名实体识别的技巧思路,当面对标注质量不那么高的数据集时,或许可以尝试一下负采样的方法。
以上就是Fudan DISC本期的论文分享内容,欢迎大家的批评和交流。
原文标题:【论文解读】ICLR2021 知识建模与信息抽取
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
模型
+关注
关注
1文章
3818浏览量
52265 -
深度学习
+关注
关注
73文章
5607浏览量
124625
原文标题:【论文解读】ICLR2021 知识建模与信息抽取
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI大模型微调企业项目实战课
人工智能多模态与视觉大模型开发实战 - 2026必会
【瑞萨AI挑战赛】手写数字识别模型在RA8P1 Titan Board上的部署
实力认证!行云创新入围《AI 中国生态图谱 2025》大模型开放平台板块

润和软件入选大模型一体机产业图谱

如何精准驱动菜品识别模型--基于米尔瑞芯微RK3576边缘计算盒
在Ubuntu20.04系统中训练神经网络模型的一些经验
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的未来:提升算力还是智力
模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题




评论