 什么是SLAM?视觉SLAM怎么实现?
什么是SLAM?视觉SLAM怎么实现?

上周的组会上,我给研一的萌新们讲解什么是SLAM,为了能让他们在没有任何基础的情况下大致听懂,PPT只能多图少字没公式,这里我就把上周的组会汇报总结一下。
这次汇报的题目我定为“视觉SLAM:一直在入门,从未能精通”,那是因为视觉SLAM真的是博大精深,就像C++一样,连说入门都底气不足,只能说了解,更不敢说精通。
从五月份开始学《视觉SLAM十四讲》算起,我已经正式接触SLAM四个多月了,到现在还是很懵懂的,当然也有可能是自己的吸收能力还不够强吧!
下面就以我这段时间的积累斗胆简单谈谈对视觉SLAM的认识,如有不当,还请指教。
1 什么是SLAM?
SLAM的英文全名叫做Simultaneous Localization and Mapping,中文名是同时定位与建图,从字面上来看就是同时解决定位和地图构建问题。
定位主要是解决“在什么地方”的问题,比如你目前在哪国哪省哪市哪区哪路哪栋几号几楼哪个房间哪个角落。
建图主要是解决“周围环境是什么样”的问题,你可以回忆一下百度高德地图,甚至一些景点的手绘地图。
下面就以扫地机器人作为例子再稍微详细地讲解一下。
对于扫地机器人来说,定位就是要知道自己在房间里的具体位置,建图就是知道整个房间的地面结构信息,而有了这些信息才能做路径规划,以最短的距离到达目的地。
下面右图就是扫地机器人在家里移动时的定位和建图,蓝点是它自己目前所在的位置,它已经把房间能抵达的地方都构建出来了。
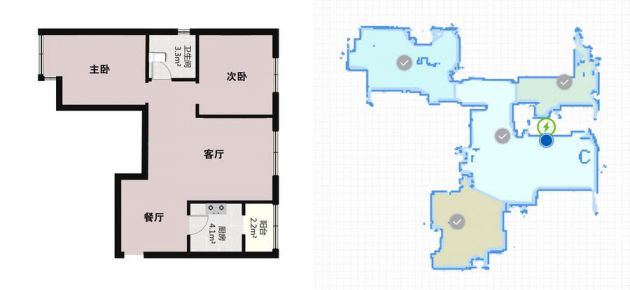
总的来说,机器人从未知环境未知地点出发,通过传感器(这里主要说的是相机)观测环境获取信息,利用相机的信息估算机器人的位置、姿态和运动轨迹,并且根据位姿构建地图,从而实现同时定位和建图。
利用不同的传感器实现SLAM的方法不同,目前主流的传感器有激光雷达(LiDAR SLAM)、相机(Visual SLAM)和惯性测量单元(Visual-inertial SLAM)。
接下来我们介绍的是视觉SLAM的方法,也就是只采用相机作为传感器的SLAM。
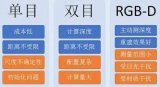
当然,用相机作为传感器的话,还是有不同的方法,因为相机也有不同的种类,常见的有单目相机、双目相机和RGB-D相机。
2 为什么用SLAM?
可能你会有疑问了,为什么不用GPS定位?为什么不用现成的地图?下面就来一一解答。
对于定位来说,我要反问一下,没有GPS怎么破?比如在一些建筑物内、隧道或者偏远地方,我们是无法获取GPS的。这种情况下机器人或者无人车是不是得自己定位了。
再者,GPS的定位精度不够高,最多也就达到几米的精度,要是在室内定位的话,一套房就这么巴掌大的地方,几米的误差也许就让你的扫地机器人误以为是在你邻居家打扫了。。
对于建图来说,我还是要反问一下,没有现成地图怎么破?比如你的家、公司或者工厂,我们很难直接拿到现成的地图,家家户户的图纸数据量得多大,而且每一户装修也不一样,家私的摆放位置更是无从得知。
而且,不同场景需求下的地图也是不一样的,后面我们会提到有各式各样的地图,不存在解决各种问题的地图。
所以,在没有GPS和现成地图的场景下,同时考虑到定位的精度和地图的需求,SLAM对于机器人来说简直是雪中送炭。
3 视觉SLAM怎么实现?
下面就用高博《视觉SLAM十四讲》里的框图来讲解视觉SLAM大致是怎么实现的。
首先通过传感器(这里利用的是相机)获取环境中的数据信息,也就是一帧一帧的图像,在前端视觉里程计中通过这些图像信息计算出相机的位置(准确来说是位姿,后面会细说)。
同时进行闭环检测,判断机器人是否到达先前经过的地方。然后利用后端非线性优化,对前端得出的相机位姿进行优化,得到全局最优的状态。
最后根据每一时刻的相机位姿和空间中目标的信息,根据需求建立相应的地图。
接下来就来详细说说其中每一个模块都是怎么操作的。
4 前端视觉里程计
视觉里程计的英文名称是Visual Odometry,简称VO,主要是研究怎么通过相邻两帧图像计算两帧之间相机的运动。
这里面涉及了不少知识,其中包括图像处理中的特征提取和特征匹配、三维视觉中的刚体运动和对极几何、数学中的李群李代数等等。。
不要慌!天空飘来五个字,那都不是事!
在视觉SLAM中,主流的方法根据前端的不同分为特征点法和直接法,下面介绍的是利用特征点法的视觉SLAM。
对于我们人眼直观判断来说,从前一张图像到后一张图像应该是往右上的方向稍微旋转了一下。
但是,对于机器人来说它可没那么“直观”。
首先它要对这两张图像进行特征提取,也就是找到图像中特别的地方,比如角点、边缘点等。然后,对这些特征点在两张图像之间进行特征匹配。
把匹配对中误匹配的筛选掉之后,就能得到较为准确的匹配了。
有了这些匹配点对之后,就能利用它们疯狂计算相机的位姿了。对了,这里得讲讲位姿究竟是什么东西?
位姿其实就是位置和姿态的合称,位置也就是在三维空间中的坐标(x,y,z),而姿态是在三维空间中的旋转(r,p,y),因此位姿总共包含6个自由度。
还没理解?来做做头部健康运动就明白了,左右歪头,上下点头,左右摇头。怎么样,既能预防颈椎病,还能理解三维旋转。
左右歪头是滚转角roll,上下点头是俯仰角pitch,左右摇头则是偏航角yaw。
既然要表示坐标,那我们总得知道坐标系是什么吧?在相机运动过程中,有四个常见的坐标系需要我们了解。
分别是世界坐标系、相机坐标系、归一化坐标系还有像素坐标系。下面这张图让人一目了然。
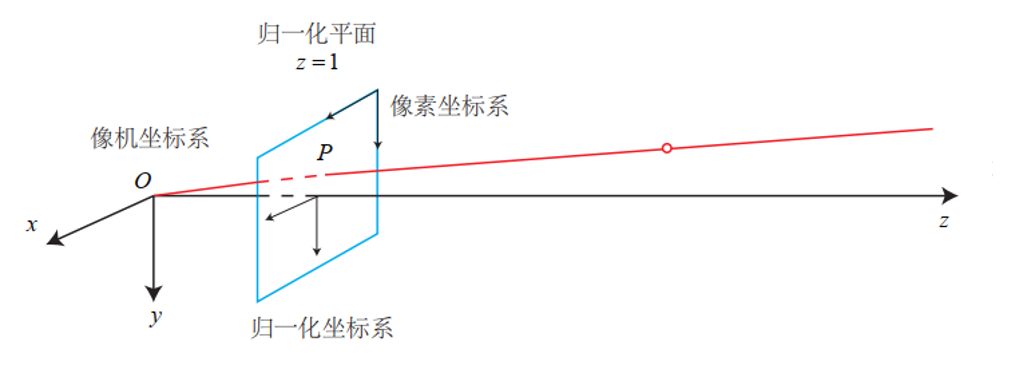
世界坐标系比较好理解,就是我们身处的整个三维空间的坐标系,坐标原点由我们自己定,可以是某一张桌子的边角,也可以是相机第一时刻的位置。
相机坐标系是以相机光心为坐标原点,光轴为z轴的坐标系。
归一化坐标系就是原点在相机坐标系下(0,0,1)处的二维平面坐标系。
像素坐标系是以图像左上角的像素为原点,以一个像素为最小单元的离散坐标系。
既然有不同的坐标,当知道点在一个坐标系下的坐标时,如何求得该点在其他坐标系下的坐标呢?
举个栗子,我们能获取到的是图像的像素信息,通过转换(相机投影模型)之后能得到该像素(特征点)在相机坐标系中的坐标位置。
但是在构建地图的时候我们得知道这个像素(特征点)在整个三维空间中的哪个位置呀,也就是相机坐标系中的坐标怎么转化到世界坐标系下。
这就涉及到了三维空间刚体运动中坐标系的变换。直接上图就晓得了。
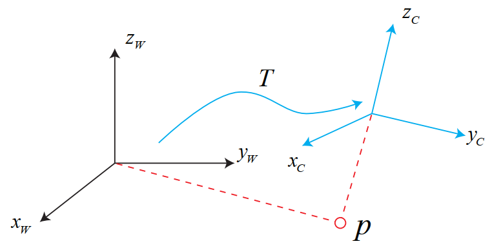
上图展示的是世界坐标系转化为相机坐标系的过程,当然方法都是一样的。
这里献上整篇文章唯一的一条数学公式:
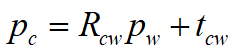
pc是点p在相机坐标系下的坐标,pw是世界坐标,Rcw是描述从世界坐标系转化为相机坐标系旋转的旋转矩阵,tcw是描述从世界坐标系转化相机坐标系平移的平移向量。
可以看出,坐标系的转换我们可以用一个旋转矩阵R(3*3)来表示旋转,也就是决定姿态,还有一个平移向量t(3*1)来表示平移,也就是决定位置。
相机的位姿其实就是指相机在世界坐标系下的位置坐标和旋转姿态,位姿估计就是根据两帧之间匹配点的关系计算当前时刻相机的位姿。
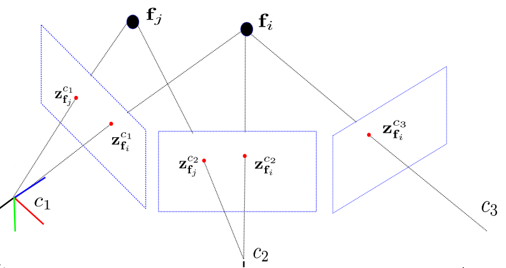
假如我们将第一帧时刻的相机作为世界坐标系原点,那么通过第1、2帧图像的匹配点就可以计算从第2帧相机坐标系到第1帧相机坐标系(世界坐标系)的旋转矩阵R12和平移向量t12。
然后再通过第2、3帧图像的匹配点计算R23和t23,利用和R12相乘再加上t12就能求得第3帧时刻相机在世界坐标系下的位姿。依此类推。。。
当然,根据不同情况可以用不同的方法求R和t:
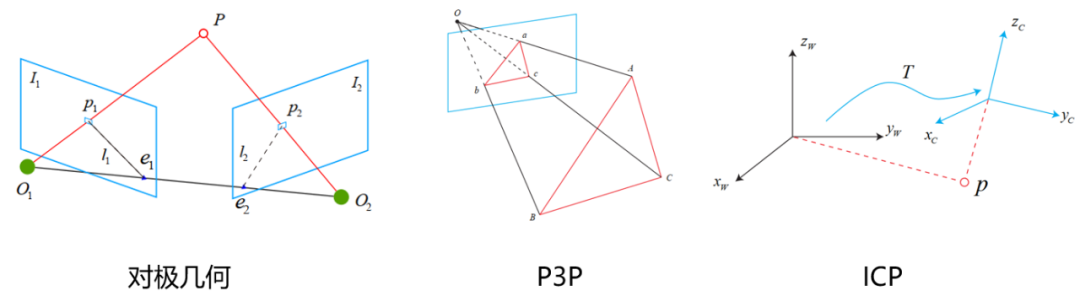
2D-2D:对极约束,在单目相机中,我们只能获取二维图像,利用两帧图像的匹配点关系通过对极几何的关系可以求出一个叫本质矩阵E的东西,再求得R和t。
3D-3D:ICP(迭代最近法),在双目和RGB-D相机中,我们可以直接获取图像的深度信息,也就是说特征点在相机坐标系下的z我们是知道的,这时候其实就相当于直接求两个相机坐标系的转换R和t。
3D-2D:PnP,当我们知道一组点在世界坐标系下的坐标和它们在相机中的投影位置时,可以利用这种方法直接求得当前时刻的相机位姿。
5 后端优化
视觉里程计讲得很多了,但是从视觉里程计中计算得到的相机位姿会有一定的误差,一次两次还好,一旦多了累积误差可是很严重的。
这时就需要后端对前端的结果进行优化,从而得到最优的位姿。
和前端分为两种主流方法一样,后端也有两种解决方法:
滤波器方法,以扩展卡尔曼滤波(EKF)为代表,认为某一时刻的状态只和上一时刻的状态有关。
非线性优化方法,以高斯牛顿法和列文伯格-马夸尔特法为代表,认为某一时刻的状态和之前所有状态有关。
我们主要用的是非线性优化方法,对相机位姿和路标点构建最小二乘问题,并利用图优化的方法求解,也就是常说的Bundle Adjustment。
当然,因为BA处理的数据量很大,在整个SLAM过程中还会采取别的方法控制优化的数据,比如滑动窗口法。
简单地说,就是在保持处理的帧数不变的情况下,将旧的数据删除,加入新的数据。
假设每次只优化10帧,那么当接收到第11帧图像时,移除第1帧图像的数据,并将第11帧图像加入优化问题中。
6回环检测
回环检测(Loop Closure)是一个挺特殊的模块,主要让机器人能识别出曾经去过的地方。
随着时间推进,SLAM的误差会不断地累积,时间久了后,使得轨迹出现严重的漂移。
如果有了回环检测,机器人就会检测到自己曾经到过这个地方,利用这个信息和历史数据比对,从而修正累积误差,得到全局一致的状态估计。
为什么说回环检测挺特殊的呢?因为这个模块乍一看还挺像机器学习甚至是目前深度神经网络应用的领域。
判断“两张图像是否为同一个地方”会出现4种结果:
事实是,机器人判断为是;
事实是,机器人判断为否;
事实否,机器人判断为是;
事实否,机器人判断为否。
最好的结果当然是第1种和第4种,因为机器人的判断和事实符合,可现实总是不完美的。
而衡量回环检测效果的指标也有两种——准确率(Precision)和召回率(Recall)。
用西瓜书里的话解释,准确率关心的是“挑出的西瓜中有多少比例是好瓜”,召回率关心的是“所有好瓜中有多少比例被挑了出来”。
西瓜书都搬出来了,这还不是机器学习问题吗?
当然,在SLAM中还是更注重召回率的,希望更多“现实是回环”被机器人“判断为回环”。
传统主流的视觉SLAM中回环检测采用的是词袋模型,当然按照目前深度学习的势头来说,也不妨试试神经网络,但是实时性就得另当别论了。
而且,回环检测还可以用来进行重定位,解决跟踪失败的问题,保证在跟踪失败的情况下可以快速重新得到当前的精确位姿。
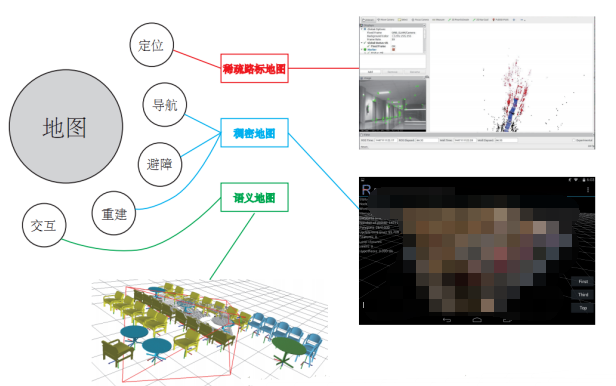
7地图构建
最后一个模块是地图构建,前面也说过了,我们根据不同的传感器类型和应用需求可以建立不同的地图。
还是用高博《视觉SLAM十四讲》中的图,简洁明了地说明了不同应用场景对应不同类型的地图。
如果只是单纯的定位,只需要知道机器人在什么位置即可,这时候稀疏路标地图就足够了。
在导航、避障的情况下,机器人必须知道什么地方可以走而什么地方不能走,这才能规划出运动路径。于是就需要稠密地图,稀疏路标点的地图压根就不能判断那是什么东西。
重建也很明了,既然是重建,那就得是带有轮廓纹理等详细信息的稠密地图了。
如果是人机交互的话呢,机器人得知道什么是桌子、杯子在哪里等语义信息,这时候光是知道物体什么模样可不行了,得上语义地图才是。
我们在做导航时,有一种常用的地图,那就是八叉树地图(Octomap)。
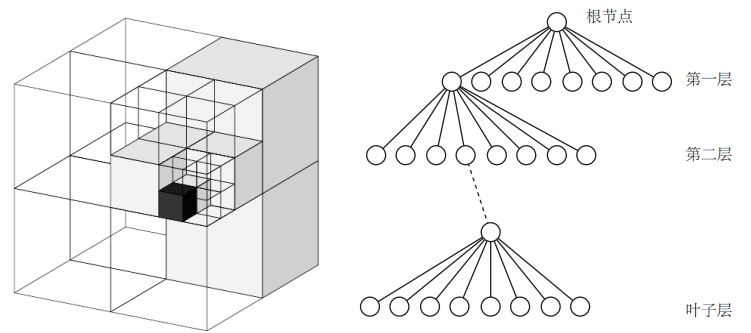
它是把三维空间分为许多方块,方块再分为八个同样大小的小方块,小方块再继续往下分。。整个三维空间就用八叉树数据结构来表示。
当方块中所有子方块都被占据或者都没被占据的时候,这个方块或者说八叉树中的这个节点就没必要往下展开了。
相对与点云地图来说,这样会大大减少了地图的存储空间!下面就是一张八叉树地图。
8 结语
近两年,SLAM有要火的趋势,但是这也不妨碍它毫不平易近人的特质。
审核编辑:彭菁
-
传感器
+关注
关注
2574文章
54389浏览量
786174 -
机器人
+关注
关注
213文章
30594浏览量
219641 -
gps
+关注
关注
22文章
3011浏览量
172553 -
SLAM
+关注
关注
24文章
456浏览量
33189 -
激光雷达
+关注
关注
978文章
4379浏览量
195389
原文标题:CV领域的绝境长城,视觉SLAM:一直在入门,从未能精通
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
激光SLAM与视觉SLAM有什么区别?
基于视觉的slam自动驾驶
单目视觉SLAM仿真系统的设计与实现
视觉SLAM的技术资料总结
科普|视觉SLAM是什么——三种视觉SLAM方案
视觉SLAM与激光SLAM有什么区别?
机器人主流定位技术:激光SLAM与视觉SLAM谁更胜一筹
基于深度学习的视觉SLAM综述
OV2SLAM(高速视觉slam)简析
视觉SLAM开源方案汇总 视觉SLAM设备选型
视觉SLAM是什么?视觉SLAM的工作原理 视觉SLAM框架解读





 工商网监
工商网监
评论