 CPU内核中的FPGA优化方法
CPU内核中的FPGA优化方法

用 FPGA 技术更新传统系统是许多嵌入式系统设计人员都知道的场景。但现有设计确实需要更新,这其中就包括连接互联网、 IoT等。当然,我们也需要进一步增强安全性。尤其考虑到目前人们热衷于人工智能,大家对深度学习推理或机器视觉又有了新的需求。
尽管现在已将系统整合至物联网,但仍然面临一个迫在眉睫的问题——这些更改将对系统硬件造成影响。直接使用 CPU 可以缓解所有的问题。但对于小型嵌入式设计(一开始就只有一英寸的小外形)来说,由于存在成本、功耗和散热方面的限制,这种蛮力法可能行不通。此时,必须采用 FPGA 方法。
事实上,系统中通常有一个老旧的小型 FPGA 负责执行实用工作:充当端口扩展器或设备控制器。然而,现在的低端 FPGA 可以充当硬件加速器,将新的计算要求拉回至现有系统处理器范围之内。
采取下一步行动
我们需要采取进一步行动,考虑将系统(或子系统)的 CPU 或微控制器单元 (MCU) 也整合到 FPGA 中是否可行?显而易见,答案是“当然不可行”。众所周知,FPGA 中的软 CPU 内核尺寸大、速度慢、价格贵。除了对于重要的嵌入式系统来说,这些概括性说法都不对。
我们不是在讨论拥有强大 CPU 性能的系统。(比如 Arm* Cortex*-A53 内核集群。)在硬件中包含此类 CPU 集群的中端 FPGA,但该主题不在本文介绍范围之内。今天我们讨论的是处理器适用范围更广的系统(或总体设计中的子系统):微控制器中的 Cortex-M 级内核,或真正的传统 CPU,如 68000。通常情况下,这种老旧处理器不适用于系统设计,因为它们始终不愿意接触古老、文档不完整的代码,直至最后生命周期结束被迫淘汰。我们要介绍的是,通常可以将这种小型或老旧 CPU 整合至低端 FPGA 中(图 2)。
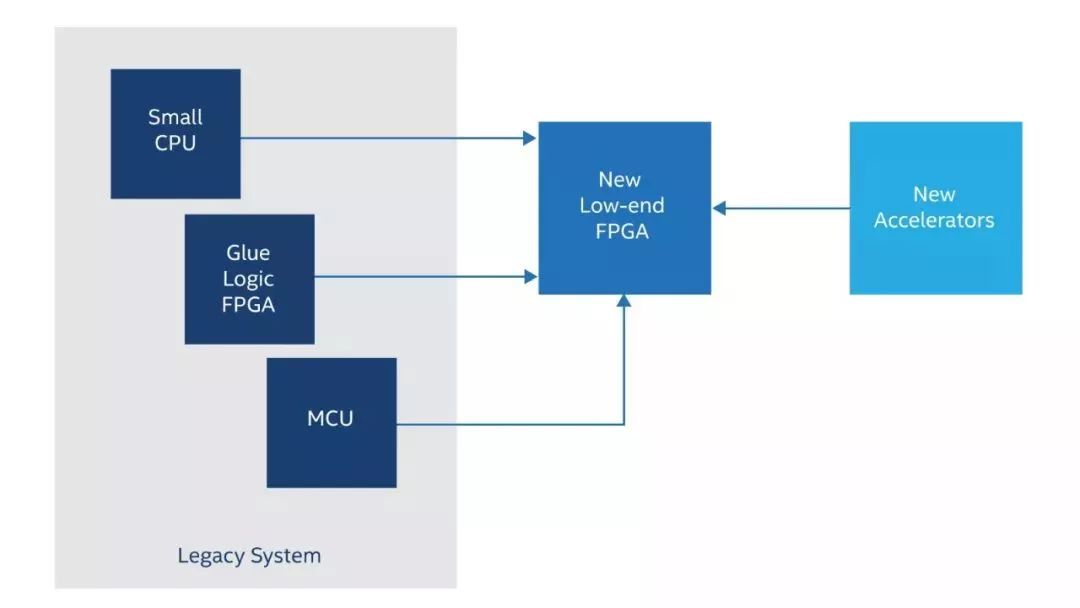
图2.小型现代FPGA可以吸收旧设计中所有的传统处理器
“芯”起点在哪儿?
如果您有用 C 或 C++(最好是通过原始测试工作台)编写的文档化源代码,那么情况将对您非常有利。您可以从适用于在 FPGA 中进行软实施的整个 CPU 内核选项中进行选择。然后,还可以针对所选的 CPU 重新编译并测试代码。
遗憾的是,测试结果并不总是乐观的。过去,微处理器的编译器并不总是适合嵌入式设计,尤其是对于存在实时限制的子系统。老代码或保守型工程师编写的代码,可能完全是用汇编语言编写的。现代代码主要是用 C 语言编写的,其中关键例程用汇编语言手动编写。无论采用哪种语言编写,都至少会有一部分代码锁定在特定的指令集架构中。
其次,需要谨慎考虑硬件独立性程度,不是语言方面,而是编码风格方面。在过去节省代码空间和缩短延迟至关重要的时候,往应用代码中嵌入中断处理程序、驱动程序和物理 I/O 地址等不良实践通常被认为是明智之举,这些做法会加大移植到新硬件的难度。过去,一些极其糟糕的想法,比如编写时序依赖型代码,通常被认为更加明智。这种代码可能需要重新编写,才能在快速的现代硬件上运行。但即使存在汇编语言源代码和不合时宜的编码风格,我们仍然可以采用实际方法将传统模块整合到 FPGA 中。
第一种方法是,如果 CPU 的确非常老旧,则使用开源寄存器传输级 (RTL) 模型在 FPGA 中重新实施传统微处理器或微控制器。Github 等资源拥有许多用于传统处理器(包括 6502、Z80、6809、68000 和 8086)的 Verilog 模型。但在这些内核中进行设计之前,必须考虑几个问题。
第一个问题是合法性。因为 Verilog 可用并不意味着您拥有在商业产品中使用该设计的合法权利。有一些模型是研究人员和业余爱好者编写的,没有考虑到知识产权。因此,很久之前的一些架构可能实际上位于公共域中。
另一个问题是作者的意图。例如:Verilog 是架构的近似功能描述。它的目的是仅在模拟中执行代码,还是封装在用户控件逻辑和 I/O 中?或者,该模型是否包含进入微处理器芯片的其他所有硬件?您必须匹配 Verilog 模型的特性和传统系统的需求,否则将要花费大量的时间来了解旧芯片的劣势。
接下来就是一些令人伤神的细节问题。SiFive 产品经理 Jack Kang 指出,与现代 CPU 一样,传统 CPU 也在整个产品生命周期中经历了多次修改,每次修改都会纠正一些错误或劣势。Verilog 代表哪个版本?或者它是一个理想化版本,代表着作者假定芯片怎样正常运行的方式?最后是设计师的谨慎程度。该模型是否按照实际传统芯片一个循环接一个循环地运行?是否启动了您需要使用的操作系统?是否成功合成过?
如果 Verilog 模型无法正常运行,还有另一个选择。老旧的 CPU 速度非常慢,以致于在当前 FPGA 中的微小现代 RISC 内核上运行的指令集模拟器都可以实时地遍历传统代码,尤其是当麻烦序列卸载到 FPGA 中其他位置的状态机上时。这种方法不能简单地呈现周期精确或时序精确,但在功能上是正确的。而且它还可以将移植问题从硬件域转换到软件域,在软件域,您可以访问整个调试工作台,这样移植问题处理起来容易得多。
如何实施 CPU?
讨论了将传统代码迁移至新系统的可行性和难度后,接下来的问题是如何在低端 FPGA 中实施 CPU 内核。我们之前讨论过复制传统 CPU 的情况,现在我们可以来了解下实施现代高性能 CPU 的选项。
主要问题是处理器内核依赖部分硬件结构,这种结构在 ASIC 中以标准单元甚至是自定义逻辑的形式实施,无法在 FPGA 结构中轻松高效地复制。因此,我们必须了解三种不同情况(图 3):
仅通过用于模拟或 ASIC 合成的 Verilog 模型进行合成的 CPU 内核 — 即所谓的开箱即用场景。
拥有面向 FPGA 合成手动优化的 RTL 的内核。
从一开始就开发了架构以在 FPGA 中实施的内核。每种方法的可用性、规模和性能都不相同。这些方法都适用于现代低端 FPGA。
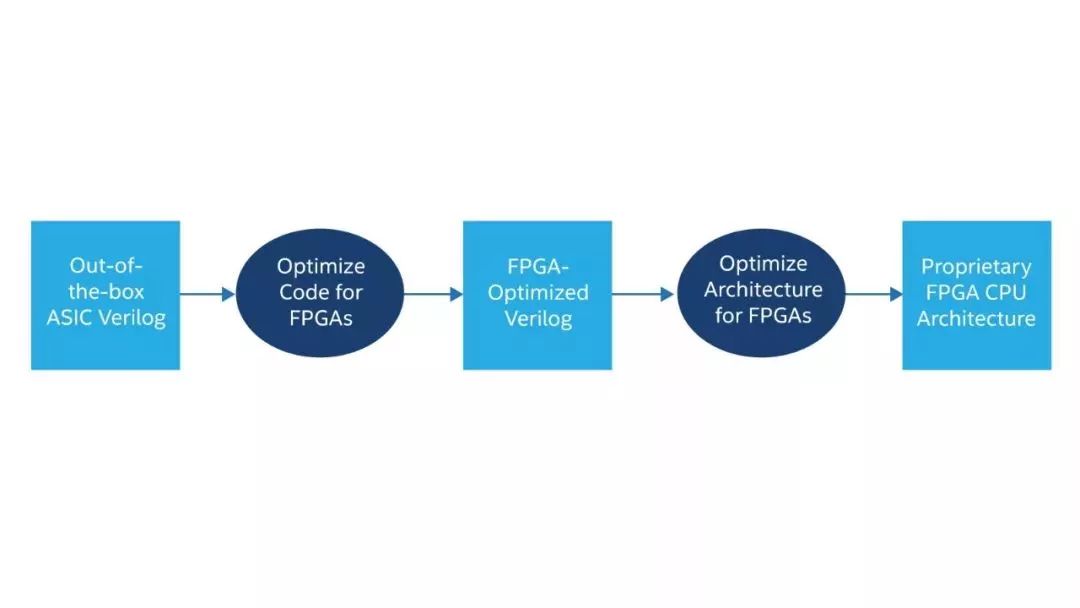
图3.CPU 内核中的三种 FPGA 优化级别。
开箱即用
尽管并不是每家 CPU 内核知识产权 (IP) 厂商都专门针对 FPGA,但大多数 IP 提供商都至少提供两条迁移至 FPGA 内核的路径。最明显的路径是授权面向内核的 RTL 源代码,并通过 FPGA 厂商的工具链运行该代码。实施这条路径会遇到很多挑战,全都是因为该 RTL 用于 ASIC 合成,而非 FPGA 合成。
特别是首次在 FPGA 中尝试运行该代码,那么遇到第一个问题将是:源代码中的有些东西是采用 FPGA 合成工具无法处理的。代码可能与合成工具不兼容的方式被隐藏或加密,可能包含您的工具无法识别的编译指示、信号命名,甚至是带有破坏性的注释约定。您可以编辑这些内容,但会因此产生第二个问题:许可。
如果您使用用于 ASIC 开发的 Verilog 源代码,可能需要进行编辑。这意味着您需要包含完整文档的未隐藏的源代码,以及/或 IP 厂商的大量支持。这些都是可用的,但它们都是针对财力雄厚、产量巨大、拥有大型法务部门的客户所编写和定价的。
还有另一条路径:一些 IP 厂商提供评估或开发套件,您可以通过它们在 FPGA 中实施 CPU 内核。该内核可能没有经过高度优化,但至少可以运行和验证,而且其速度对软件开发来说足够快。
SiFive 产品经理 Jack Kang 表示,他的一些客户已经采用了这种方法。该公司的 CoreDesigner 工具支持您从各种 RISC V 预配置内核开始,根据您特定的需求调整配置,然后输出 RTL。但该工具也会在 SiFive 的开发套件上输出一个关于 FPGA 的编程文件。
Kang 还指出,“RISC V 的这种 FPGA 实施并未面向 FPGA 使用进行高度优化,但仍然包含不到 20K 的查找表,而且速度可以达到 100 Mhz 左右,当然这很大程度上取决于配置。这种规模适合许多留有大量空间的低端 FPGA,支持您快速、轻松地将常用开源内核整合到系统中。”
优化方法
有一些方法可以改善这些数据,但需要采取一些措施。之所以有这种改善机会,是因为 CPU 中有一些结构并不适合 FPGA 逻辑结构。
FPGA 使用大量相同逻辑元件阵列来实施逻辑,每个元件都包含一些查找表 (LUT) — 通常每个 LUT 包含 4 个输入 — 以合成逻辑函数,以及一个或多个触发器。这种安排适用于大多数随机逻辑、管道和简单状态机。对于高扇入逻辑,由于可能出现在算法硬件和地址解码器中,因此合成往往会生成一长串窄逻辑元件,从而消耗互连并导致延迟。对于基于内存的功能,比如寄存器文件、高速缓存和相联内存,一次将功能映射至逻辑元件的触发器(一或二位)可能要消耗大量资源,即使厂商工具足够智能,尝试将逻辑元件的 LUT 和触发器隔离,并单独使用它们。
很久以前,当 FPGA 首次用于数据包切换、数字信号处理和类似应用时,这种不匹配就非常明显。为了解决这个问题,FPGA 厂商在逻辑结构中嵌入了大型可分割 SRAM 模块和硬件乘法累加模块。通过使用这些资源,通常可以显著改进 CPU 实施规模,有时还可以提高性能。但可能需要在 RTL 源代码中或合成过程中运用一定的知识进行干预。如果熟练的 FPGA 用户仔细检查 RTL,并面向 FPGA 合成使用已知最佳 FPGA 编码实践对其进行调优,能够进一步提升性能。
特定于FPGA的内核
行业标准 CPU 内核,比如 Cortex-M 家族或 RISC V,提供熟悉度、成熟的(或以 RISC 为例不断壮大的)工具和软件生态系统,以及在 FPGA 厂商之间轻松迁移或迁移至 ASIC 实施的机会,甚至在某些情况下还可迁移至第三方现成的 SoC。但反过来要付出一定的代价:费用、规模,有时还有性能。
如果您想最大限度地优化 FPGA,还需采取另一个步骤:不仅优化实施过程,还要优化 CPC 和指令集架构本身:从一张白纸开始,仅添加对 FPGA 友好的结构。很久以前,当 FPGA 首次变得足够大,可容纳 CPU 内核时,主要 FPGA 厂商就已经开始做出这样的努力。他们始终在做出这样的努力:在英特尔案例中为 Nios II 处理器,其以发展演进为专有 CPU 架构,不断壮大由工具、软件和 FPGA 外设 IP 组成的生态系统。
目前,这些内核家族提供多种类型的产品,从具备最少特性的小型微内核 (和 Arm 的 Cortex M0 没什么不同)到全功能、支持 Linux 的 CPU。其中许多型号都适用于厂商的低端 FPGA。例如,紧凑型 Nios Iie 内核只需大约 1000 个逻辑元件,但速度可达到或超过 75 MHz。在另一个极端,具备高速缓存和内存管理功能,且能够运行 Linux* 操作系统的内核大约需要 5000 个元件。在这两者之间还有许多选择来满足特定需求。甚至这种全功能配置也足够小,不但可以将多核 CPU 集群放在一台低端英特尔 MAX 10 设备中,还仍然拥有足够的空间。
因此,有许多方法可以将传统 CPU 功能迁移至低端 FPGA,同时仍然拥有丰富的资源来支持传统接口或控制器功能、IoT 连接、安全性,或机器学习加速。古老的机器代码可在 FPGA 上运行,以向老旧 CPU 致敬,也可在现代内核的指令集模拟器上运行。
高级语言代码可面向现代代码进行编译。极具挑战性的代码模块可以卸载到 FPGA 中的加速块中,然后通过多种优化程度各不相同的方法,得到许可并在 FPGA 中实施现代 CPU 内核的某个版本。为了最大限度地提高资源效率,厂商专有 CPU 内核可在各种性能和功能点中实现最佳的紧凑性,且几乎适合所有的设计场景。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20332浏览量
254907 -
FPGA
+关注
关注
1664文章
22502浏览量
639162 -
嵌入式系统
+关注
关注
41文章
3822浏览量
133882 -
内核
+关注
关注
4文章
1476浏览量
43089 -
cpu
+关注
关注
68文章
11327浏览量
225878
原文标题:采用FPGA更新传统系统,你还需要知道哪些Key points?
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
数字IC/FPGA设计中的时序优化方法

蜂鸟E203内核优化方法
使用FPGA优化视频水印操作的OpenCL应用
基于Windows 操作系统内核驱动的多核CPU 线程管理
SoC设计中嵌入FPGA(eFPGA)内核实用评估方法
Linux CPU的性能应该如何优化
使用FPGA实现CPU设计的毕业论文总结
如何使用FPGA实现八位RISC CPU的设计
鸿蒙系统内核中CPU空闲时间都在干嘛
如何使用SLX FPGA优化人脸检测数据中心的OpenCL AI内核?

如何在内核中启动secondary cpu




评论