 用语言建模世界:UC伯克利多模态世界模型利用语言预测未来
用语言建模世界:UC伯克利多模态世界模型利用语言预测未来

当前,人与智能体(比如机器人)的交互是非常直接的,你告诉它「拿一块蓝色的积木」,它就会帮你拿过来。但现实世界的很多信息并非那么直接,比如「扳手可以用来拧紧螺母」、「我们的牛奶喝完了」。这些信息不能直接拿来当成指令,但却蕴含着丰富的世界信息。智能体很难了解这些语言在世界上的含义。 基于此,他们提出了 Dynalang,一种从在线经验中学习语言和图像世界模型,并利用该模型学习如何行动的智能体。
Dynalang 将学习用语言对世界建模(带有预测目标的监督学习)与学习根据该模型采取行动(带有任务奖励的强化学习)分离开来。该世界模型接收视觉和文本输入作为观察模态,并将它们压缩到潜在空间。研究者通过在线收集的经验训练世界模型,使其能够预测未来的潜在表示,同时智能体在环境中执行任务。他们通过将世界模型的潜在表示作为输入,训练策略来采取最大化任务奖励的行动。由于世界建模与行动分离,Dynalang 可以在没有行动或任务奖励的单模态数据(仅文本或仅视频数据)上进行预训练。
此外,他们的框架还可以统一语言生成:智能体的感知可以影响智能体的语言模型(即其对未来 token 的预测),使其能够通过在动作空间输出语言来描述环境。
基于此,他们提出了 Dynalang,一种从在线经验中学习语言和图像世界模型,并利用该模型学习如何行动的智能体。
Dynalang 将学习用语言对世界建模(带有预测目标的监督学习)与学习根据该模型采取行动(带有任务奖励的强化学习)分离开来。该世界模型接收视觉和文本输入作为观察模态,并将它们压缩到潜在空间。研究者通过在线收集的经验训练世界模型,使其能够预测未来的潜在表示,同时智能体在环境中执行任务。他们通过将世界模型的潜在表示作为输入,训练策略来采取最大化任务奖励的行动。由于世界建模与行动分离,Dynalang 可以在没有行动或任务奖励的单模态数据(仅文本或仅视频数据)上进行预训练。
此外,他们的框架还可以统一语言生成:智能体的感知可以影响智能体的语言模型(即其对未来 token 的预测),使其能够通过在动作空间输出语言来描述环境。
 论文链接:https://arxiv.org/pdf/2308.01399.pdf项目主页:https://dynalang.github.io/代码链接:https://github.com/jlin816/dynalang
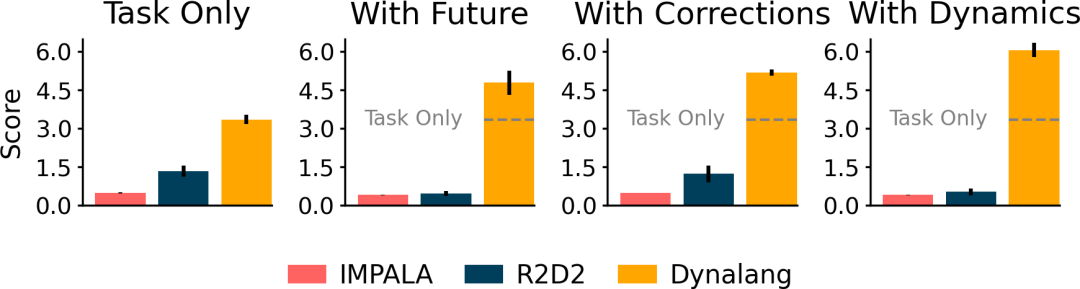
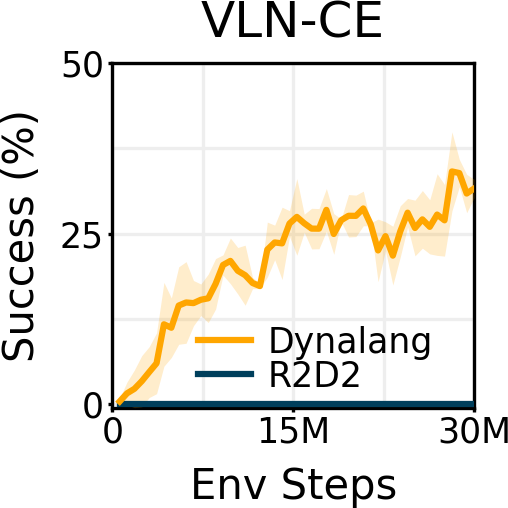
研究者在具有不同类型语言上下文的多样化环境中对 Dynalang 进行了评估。在一个多任务家庭清洁环境中,Dynalang 学会利用关于未来观察、环境动态和修正的语言提示,更高效地完成任务。在 Messenger 基准测试中,Dynalang 可以阅读游戏手册来应对最具挑战性的游戏阶段,优于特定任务的架构。在视觉 - 语言导航中,研究者证明 Dynalang 可以学会在视觉和语言复杂的环境中遵循指令。
论文链接:https://arxiv.org/pdf/2308.01399.pdf项目主页:https://dynalang.github.io/代码链接:https://github.com/jlin816/dynalang
研究者在具有不同类型语言上下文的多样化环境中对 Dynalang 进行了评估。在一个多任务家庭清洁环境中,Dynalang 学会利用关于未来观察、环境动态和修正的语言提示,更高效地完成任务。在 Messenger 基准测试中,Dynalang 可以阅读游戏手册来应对最具挑战性的游戏阶段,优于特定任务的架构。在视觉 - 语言导航中,研究者证明 Dynalang 可以学会在视觉和语言复杂的环境中遵循指令。
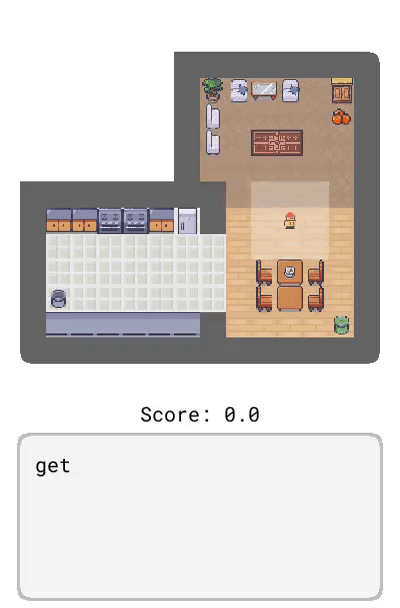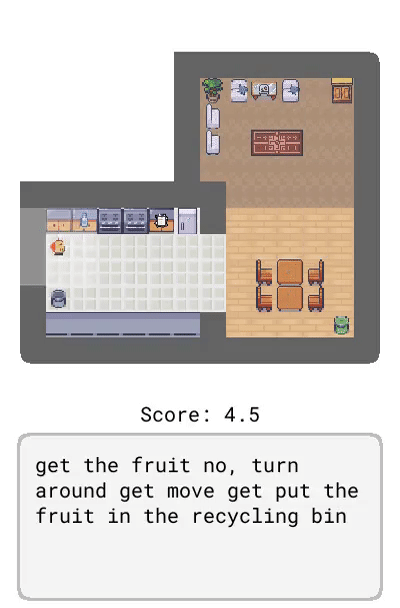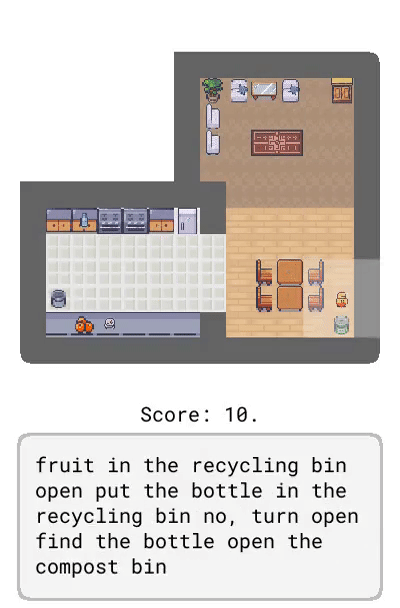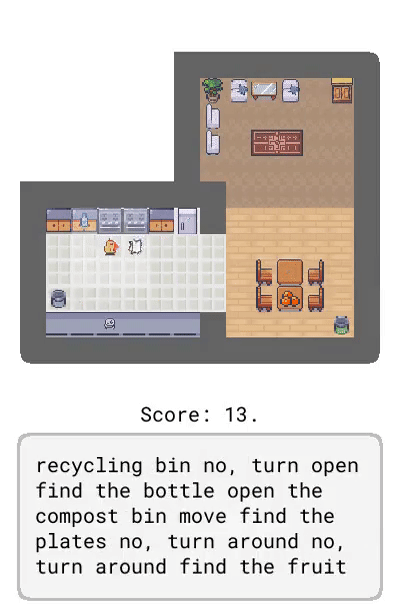
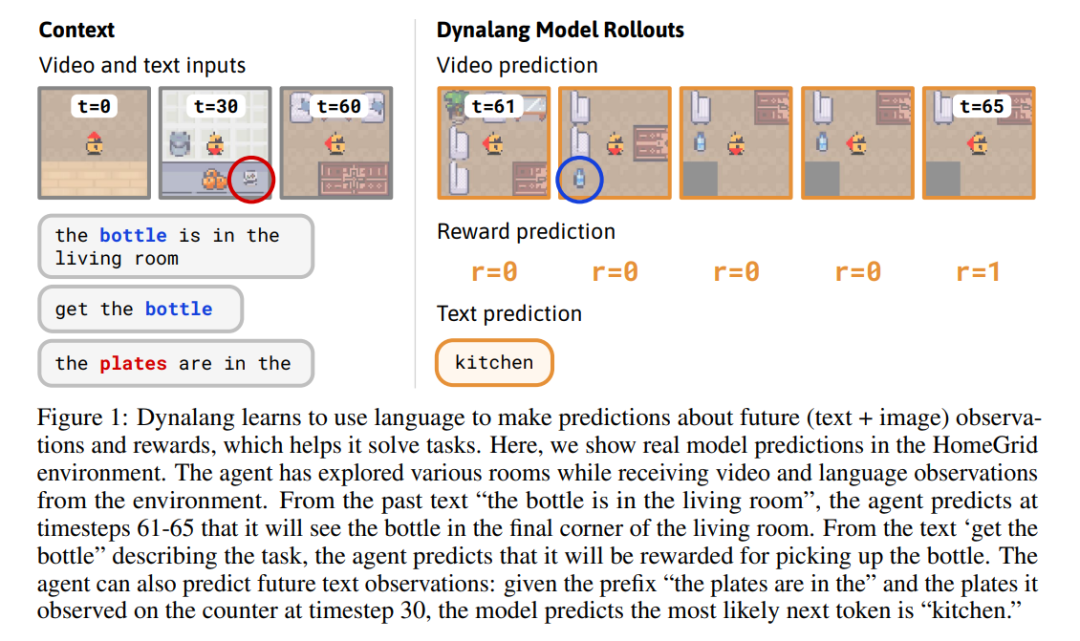 Dynalang 学会使用语言来预测未来的(文本 + 图像)观察结果和奖励,从而帮助解决任务。在这里,研究者展示了在 HomeGrid 环境中真实的模型预测结果。智能体在接收环境中的视频和语言观察的同时,探索了各种房间。根据过去的文本「瓶子在客厅」,在时间步 61-65,智能体预测将在客厅的最后一个角落看到瓶子。根据描述任务的文本「拿起瓶子」,智能体预测将因为拿起瓶子而获得奖励。智能体还可以预测未来的文本观察:在时间步 30,给定前半句「盘子在」,并观察到橱柜上的盘子,模型预测下一个最可能的 token 是「厨房」。
Dynalang 学会使用语言来预测未来的(文本 + 图像)观察结果和奖励,从而帮助解决任务。在这里,研究者展示了在 HomeGrid 环境中真实的模型预测结果。智能体在接收环境中的视频和语言观察的同时,探索了各种房间。根据过去的文本「瓶子在客厅」,在时间步 61-65,智能体预测将在客厅的最后一个角落看到瓶子。根据描述任务的文本「拿起瓶子」,智能体预测将因为拿起瓶子而获得奖励。智能体还可以预测未来的文本观察:在时间步 30,给定前半句「盘子在」,并观察到橱柜上的盘子,模型预测下一个最可能的 token 是「厨房」。
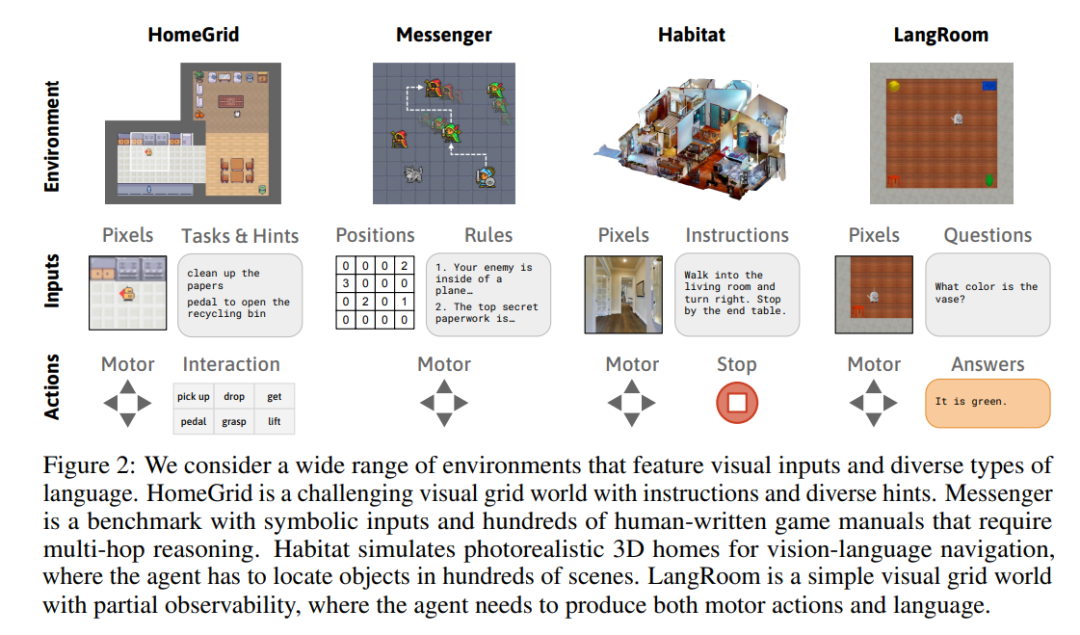 研究者考虑了一系列具有视觉输入和多样化语言的环境。HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。Messenger 是一个具有符号输入的基准测试,包含数百个人工编写的游戏手册,需要进行多次推理。Habitat 是一个模拟逼真的 3D 家居环境,用于视觉 - 语言导航,在其中智能体必须在数百个场景中定位物体。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要同时生成动作和语言。
详解 Dynalang 工作原理
使用语言来理解世界很自然地符合世界建模范式。这项工作构建在 DreamerV3 的基础之上,DreamerV3 是一种基于模型的强化学习智能体。Dynalang 不断地从经验数据中学习,这些数据是智能体在环境中执行任务时收集到的。
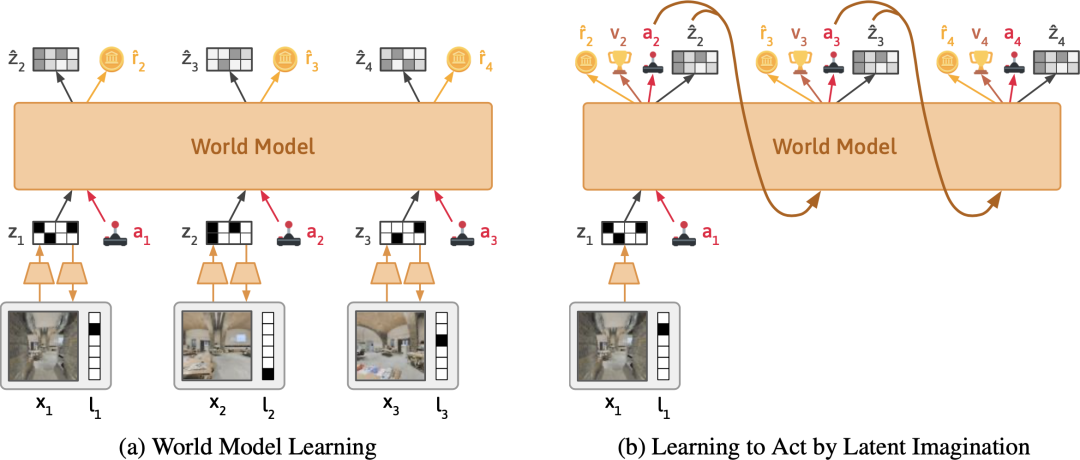
如下图(左)所示,在每个时间步,世界模型将文本和图像压缩成潜在表示。通过这个表示,模型被训练用于重建原始观察结果、预测奖励,并预测下一个时间步的表示。直观地说,世界模型根据它在文本中读到的内容,学习它应该期望在世界中看到什么。
如下图(右)所示,Dynalang 通过在压缩的世界模型表示之上训练策略网络来选择行动。它通过来自世界模型的想象的模拟结果进行训练,并学会采取能够最大化预测奖励的行动。
研究者考虑了一系列具有视觉输入和多样化语言的环境。HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。Messenger 是一个具有符号输入的基准测试,包含数百个人工编写的游戏手册,需要进行多次推理。Habitat 是一个模拟逼真的 3D 家居环境,用于视觉 - 语言导航,在其中智能体必须在数百个场景中定位物体。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要同时生成动作和语言。
详解 Dynalang 工作原理
使用语言来理解世界很自然地符合世界建模范式。这项工作构建在 DreamerV3 的基础之上,DreamerV3 是一种基于模型的强化学习智能体。Dynalang 不断地从经验数据中学习,这些数据是智能体在环境中执行任务时收集到的。
如下图(左)所示,在每个时间步,世界模型将文本和图像压缩成潜在表示。通过这个表示,模型被训练用于重建原始观察结果、预测奖励,并预测下一个时间步的表示。直观地说,世界模型根据它在文本中读到的内容,学习它应该期望在世界中看到什么。
如下图(右)所示,Dynalang 通过在压缩的世界模型表示之上训练策略网络来选择行动。它通过来自世界模型的想象的模拟结果进行训练,并学会采取能够最大化预测奖励的行动。
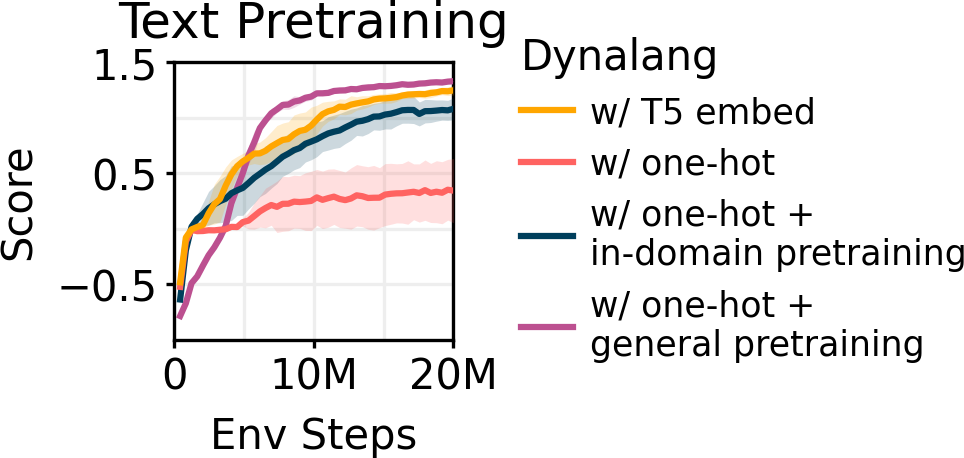
 与之前逐句或逐段消耗文本的多模态模型不同,研究者设计的 Dynalang 将视频和文本作为一个统一的序列来建模,一次处理一帧图像和一个文本 token。直观来说,这类似于人类在现实世界中接收输入的方式 —— 作为一个单一的多模态流,人需要时间来聆听语言。将所有内容建模为一个序列使得模型可以像语言模型一样在文本数据上进行预训练,并提高强化学习的性能。
HomeGrid 中的语言提示
研究者引入了 HomeGrid 来评估一个环境中的智能体。在这个环境中,智能体除了任务指令外还会收到语言提示。
HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。HomeGrid 中的提示模拟了智能体可能从人类那里学到或从文本中获取的知识,提供了对解决任务有帮助但不是必需的信息:
未来观察:描述了智能体未来可能观察到的情况,比如「盘子在厨房里」。
与之前逐句或逐段消耗文本的多模态模型不同,研究者设计的 Dynalang 将视频和文本作为一个统一的序列来建模,一次处理一帧图像和一个文本 token。直观来说,这类似于人类在现实世界中接收输入的方式 —— 作为一个单一的多模态流,人需要时间来聆听语言。将所有内容建模为一个序列使得模型可以像语言模型一样在文本数据上进行预训练,并提高强化学习的性能。
HomeGrid 中的语言提示
研究者引入了 HomeGrid 来评估一个环境中的智能体。在这个环境中,智能体除了任务指令外还会收到语言提示。
HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。HomeGrid 中的提示模拟了智能体可能从人类那里学到或从文本中获取的知识,提供了对解决任务有帮助但不是必需的信息:
未来观察:描述了智能体未来可能观察到的情况,比如「盘子在厨房里」。
 Dynamics:描述了环境的动态变化,比如「踩踏板打开垃圾桶」。
Dynamics:描述了环境的动态变化,比如「踩踏板打开垃圾桶」。
 Messenger 中的游戏手册
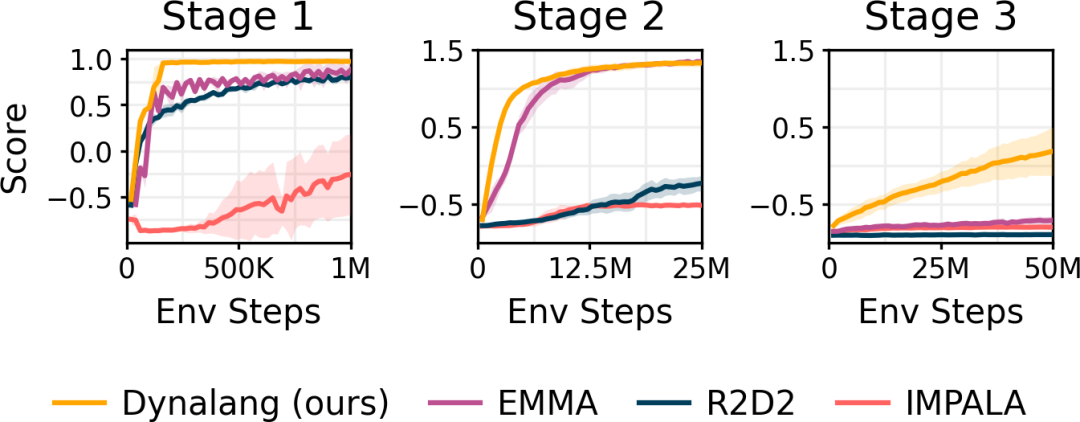
研究者在 Messenger 游戏环境中进行评估,以测试智能体如何从更长、更复杂的文本中学习,这需要对文本和视觉观察进行多次推理。智能体必须对描述每个任务动态的文本手册进行推理,并将其与环境中实体的观察结果结合起来,以确定哪些实体应该接收消息,哪些应该避免。Dynalang 的表现优于 IMPALA、R2D2 以及使用专门架构对文本和观察进行推理的任务特定 EMMA 基线,特别是在最困难的第三阶段。
Messenger 中的游戏手册
研究者在 Messenger 游戏环境中进行评估,以测试智能体如何从更长、更复杂的文本中学习,这需要对文本和视觉观察进行多次推理。智能体必须对描述每个任务动态的文本手册进行推理,并将其与环境中实体的观察结果结合起来,以确定哪些实体应该接收消息,哪些应该避免。Dynalang 的表现优于 IMPALA、R2D2 以及使用专门架构对文本和观察进行推理的任务特定 EMMA 基线,特别是在最困难的第三阶段。

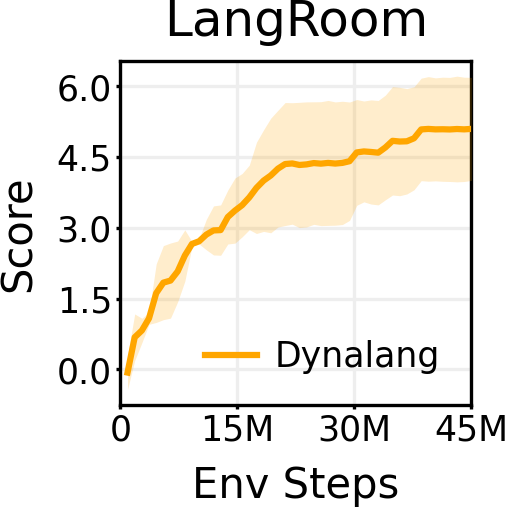
 基于 LangRoom 的语言生成
就像语言可以影响智能体对将要看到的事物的预测一样,智能体观察到的内容也会影响它对将要听到的语言的期望(例如,关于它所看到的内容的真实陈述)。通过在 LangRoom 中将语言输出到动作空间,研究者展示了 Dynalang 可以生成与环境相关联的语言,从而进行具身问答。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要在其中产生运动动作和语言。
基于 LangRoom 的语言生成
就像语言可以影响智能体对将要看到的事物的预测一样,智能体观察到的内容也会影响它对将要听到的语言的期望(例如,关于它所看到的内容的真实陈述)。通过在 LangRoom 中将语言输出到动作空间,研究者展示了 Dynalang 可以生成与环境相关联的语言,从而进行具身问答。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要在其中产生运动动作和语言。
 研究者表示,尽管他们的工作专注于用于在世界中行动的语言理解,但它也可以像一个仅文本语言模型一样从世界模型中生成文本。研究者在潜在空间中对预训练的 TinyStories 模型进行模拟的抽样,然后在每个时间步骤从表示中解码 token 观察。尽管生成的文本质量仍然低于当前语言模型的水平,但模型生成的文本令人惊讶地连贯。他们认为将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。
研究者表示,尽管他们的工作专注于用于在世界中行动的语言理解,但它也可以像一个仅文本语言模型一样从世界模型中生成文本。研究者在潜在空间中对预训练的 TinyStories 模型进行模拟的抽样,然后在每个时间步骤从表示中解码 token 观察。尽管生成的文本质量仍然低于当前语言模型的水平,但模型生成的文本令人惊讶地连贯。他们认为将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。

图源:谷歌机器人团队论文「Interactive Language: Talking to Robots in Real Time」。
UC 伯克利 Dynalang 研究的关键思想是,我们可以将语言看作是帮助我们更好地对世界进行预测的工具,比如「我们的牛奶喝完了」→打开冰箱时没有牛奶;「扳手可以用来拧紧螺母」→使用工具时螺母会旋转。Dynalang 在一个模型中结合了语言模型(LM)和世界模型(WM),使得这种范式变成多模态。研究者认为,将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。

论文概览 人工智能长期以来的目标是开发能够在物理世界中与人类自然交互的智能体。当前的具身智能体可以遵循简单的低层指令,比如「拿一块蓝色的积木」或者「经过电梯,然后向右转」。 然而,要实现自由交流的互动智能体,就需要理解人们在「此时此地」之外使用语言的完整方式,包括:传递知识,比如「左上角的按钮是关掉电视的」;提供情境信息,如「我们的牛奶喝完了」;以及协同,比如跟别人说「我已经吸过客厅了」。我们在文本中阅读的很多内容或者从他人口中听到的信息都在传递有关世界的知识,无论是关于世界如何运行还是关于当前世界状态的知识。 我们如何使智能体能够使用多样化的语言呢?一种训练基于语言的智能体解决任务的方法是强化学习(RL)。然而,目前的基于语言的 RL 方法主要是学习从特定任务指令生成行动,例如将目标描述「拿起蓝色的积木」作为输入,输出一系列运动控制。 然而,当考虑到自然语言在现实世界中所服务的多样功能时,直接将语言映射到最优行动是一个具有挑战性的学习问题。以「我把碗放好了」为例:如果任务是清洗,智能体应该继续进行下一个清洗步骤;而如果是晚餐服务,智能体应该去取碗。当语言不涉及任务时,它只与智能体应该采取的最优行动弱相关。将语言映射到行动,尤其是仅使用任务奖励,对于学会使用多样化语言输入完成任务来说是一个弱学习信号。 不同的是,UC 伯克利的研究者提出,智能体使用语言的一种统一方法是帮助它们预测未来。前面提到的语句「我把碗放好了」有助于智能体更好地预测未来的观察结果(即,如果它采取行动打开橱柜,它将在那里看到碗)。 我们遇到的很多语言可以通过这种方式与视觉体验联系起来。先前的知识,比如「扳手可以用来拧紧螺母」,帮助智能体预测环境变化。诸如「包裹在外面」的陈述有助于智能体预测未来的观察结果。这个框架还将标准指令遵循归入预测范畴:指令帮助智能体预测自己将如何受到奖励。类似于下一个 token 预测允许语言模型形成关于世界知识的内部表示,研究者假设预测未来的表示为智能体理解语言以及它与世界的关系提供了丰富的学习信号。
基于此,他们提出了 Dynalang,一种从在线经验中学习语言和图像世界模型,并利用该模型学习如何行动的智能体。
Dynalang 将学习用语言对世界建模(带有预测目标的监督学习)与学习根据该模型采取行动(带有任务奖励的强化学习)分离开来。该世界模型接收视觉和文本输入作为观察模态,并将它们压缩到潜在空间。研究者通过在线收集的经验训练世界模型,使其能够预测未来的潜在表示,同时智能体在环境中执行任务。他们通过将世界模型的潜在表示作为输入,训练策略来采取最大化任务奖励的行动。由于世界建模与行动分离,Dynalang 可以在没有行动或任务奖励的单模态数据(仅文本或仅视频数据)上进行预训练。
此外,他们的框架还可以统一语言生成:智能体的感知可以影响智能体的语言模型(即其对未来 token 的预测),使其能够通过在动作空间输出语言来描述环境。
论文链接:https://arxiv.org/pdf/2308.01399.pdf项目主页:https://dynalang.github.io/代码链接:https://github.com/jlin816/dynalang
研究者在具有不同类型语言上下文的多样化环境中对 Dynalang 进行了评估。在一个多任务家庭清洁环境中,Dynalang 学会利用关于未来观察、环境动态和修正的语言提示,更高效地完成任务。在 Messenger 基准测试中,Dynalang 可以阅读游戏手册来应对最具挑战性的游戏阶段,优于特定任务的架构。在视觉 - 语言导航中,研究者证明 Dynalang 可以学会在视觉和语言复杂的环境中遵循指令。
Dynalang 学会使用语言来预测未来的(文本 + 图像)观察结果和奖励,从而帮助解决任务。在这里,研究者展示了在 HomeGrid 环境中真实的模型预测结果。智能体在接收环境中的视频和语言观察的同时,探索了各种房间。根据过去的文本「瓶子在客厅」,在时间步 61-65,智能体预测将在客厅的最后一个角落看到瓶子。根据描述任务的文本「拿起瓶子」,智能体预测将因为拿起瓶子而获得奖励。智能体还可以预测未来的文本观察:在时间步 30,给定前半句「盘子在」,并观察到橱柜上的盘子,模型预测下一个最可能的 token 是「厨房」。
研究者考虑了一系列具有视觉输入和多样化语言的环境。HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。Messenger 是一个具有符号输入的基准测试,包含数百个人工编写的游戏手册,需要进行多次推理。Habitat 是一个模拟逼真的 3D 家居环境,用于视觉 - 语言导航,在其中智能体必须在数百个场景中定位物体。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要同时生成动作和语言。
详解 Dynalang 工作原理
使用语言来理解世界很自然地符合世界建模范式。这项工作构建在 DreamerV3 的基础之上,DreamerV3 是一种基于模型的强化学习智能体。Dynalang 不断地从经验数据中学习,这些数据是智能体在环境中执行任务时收集到的。
如下图(左)所示,在每个时间步,世界模型将文本和图像压缩成潜在表示。通过这个表示,模型被训练用于重建原始观察结果、预测奖励,并预测下一个时间步的表示。直观地说,世界模型根据它在文本中读到的内容,学习它应该期望在世界中看到什么。
如下图(右)所示,Dynalang 通过在压缩的世界模型表示之上训练策略网络来选择行动。它通过来自世界模型的想象的模拟结果进行训练,并学会采取能够最大化预测奖励的行动。
与之前逐句或逐段消耗文本的多模态模型不同,研究者设计的 Dynalang 将视频和文本作为一个统一的序列来建模,一次处理一帧图像和一个文本 token。直观来说,这类似于人类在现实世界中接收输入的方式 —— 作为一个单一的多模态流,人需要时间来聆听语言。将所有内容建模为一个序列使得模型可以像语言模型一样在文本数据上进行预训练,并提高强化学习的性能。
HomeGrid 中的语言提示
研究者引入了 HomeGrid 来评估一个环境中的智能体。在这个环境中,智能体除了任务指令外还会收到语言提示。
HomeGrid 是一个具有指令和多样化提示的具有挑战性的视觉网格世界。HomeGrid 中的提示模拟了智能体可能从人类那里学到或从文本中获取的知识,提供了对解决任务有帮助但不是必需的信息:
未来观察:描述了智能体未来可能观察到的情况,比如「盘子在厨房里」。
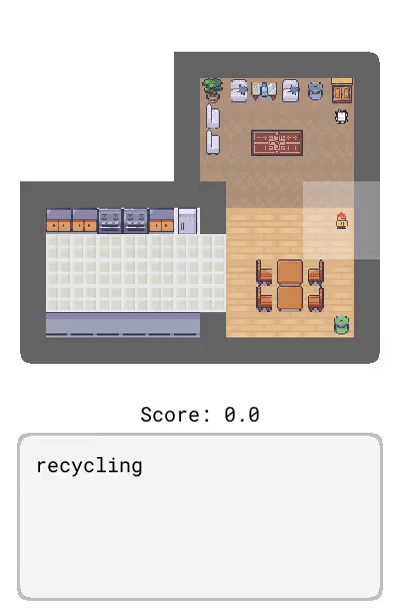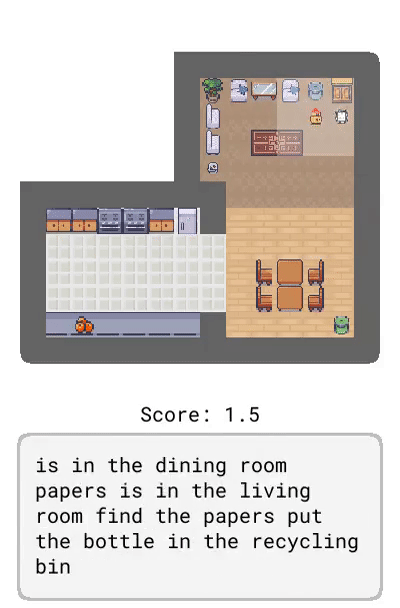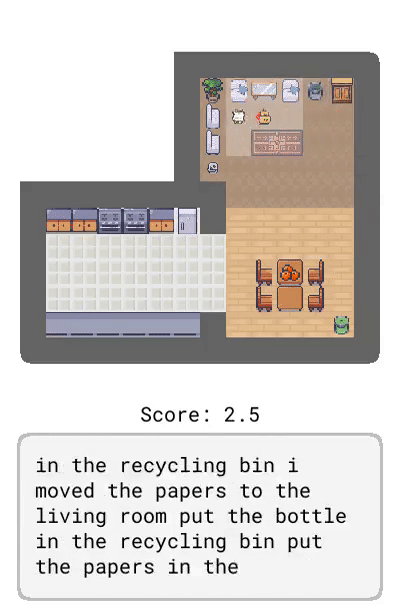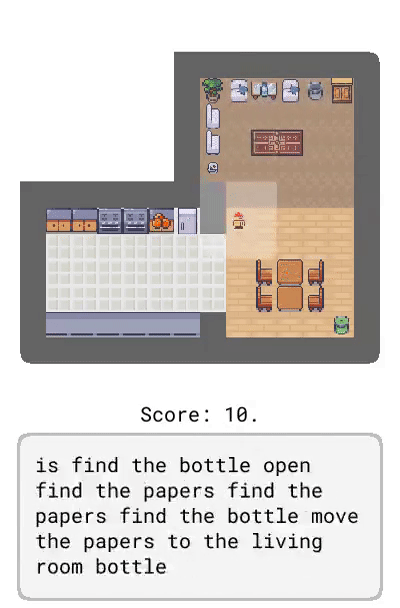
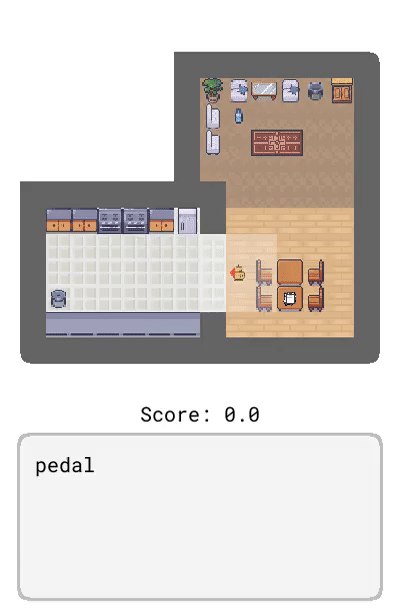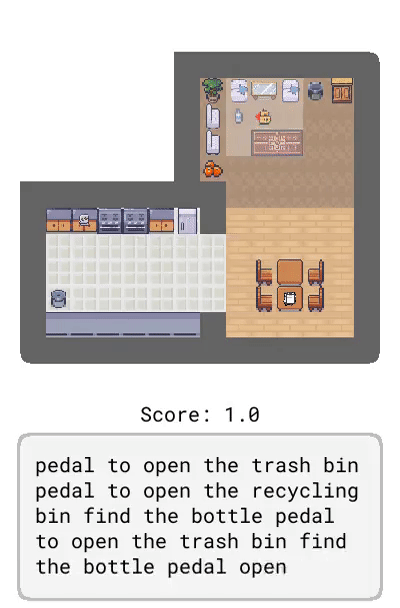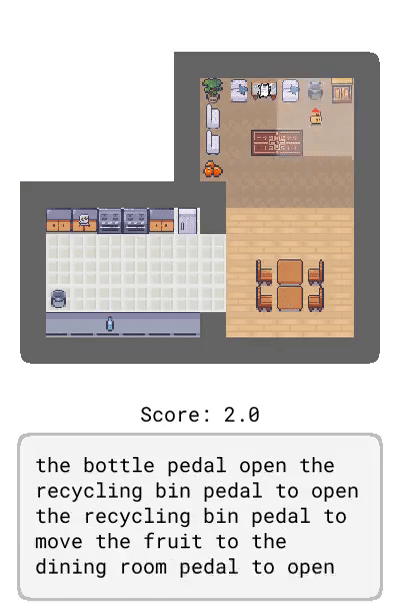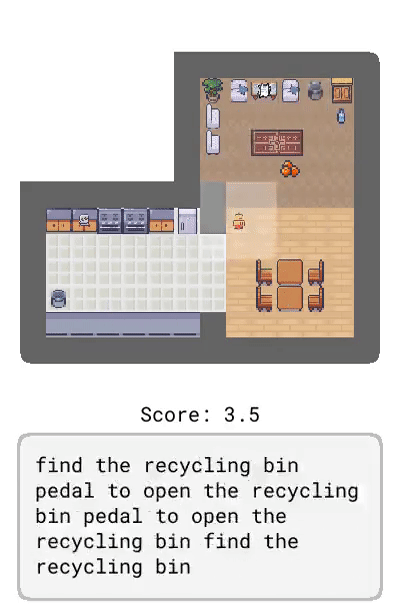
Correction:提供了基于智能体当前行为的交互式反馈,比如「转身」。
Dynamics:描述了环境的动态变化,比如「踩踏板打开垃圾桶」。
Messenger 中的游戏手册
研究者在 Messenger 游戏环境中进行评估,以测试智能体如何从更长、更复杂的文本中学习,这需要对文本和视觉观察进行多次推理。智能体必须对描述每个任务动态的文本手册进行推理,并将其与环境中实体的观察结果结合起来,以确定哪些实体应该接收消息,哪些应该避免。Dynalang 的表现优于 IMPALA、R2D2 以及使用专门架构对文本和观察进行推理的任务特定 EMMA 基线,特别是在最困难的第三阶段。
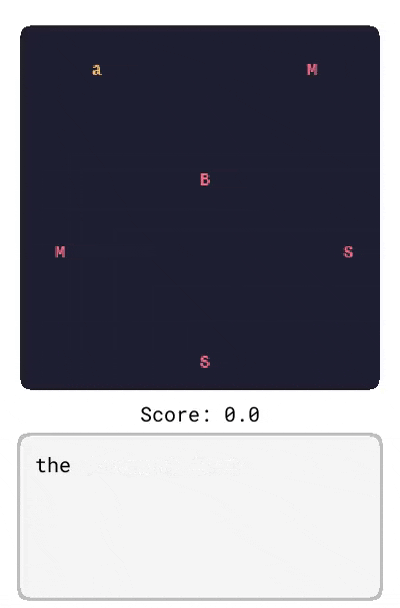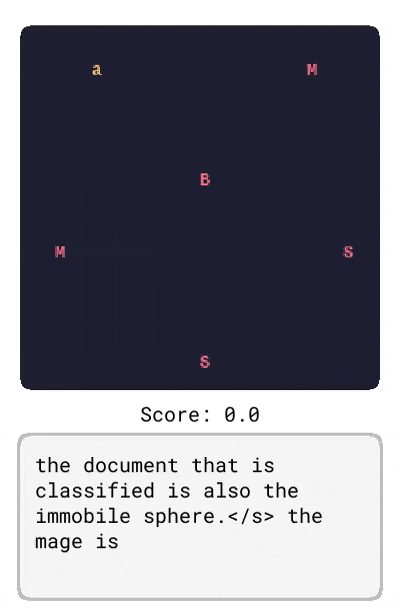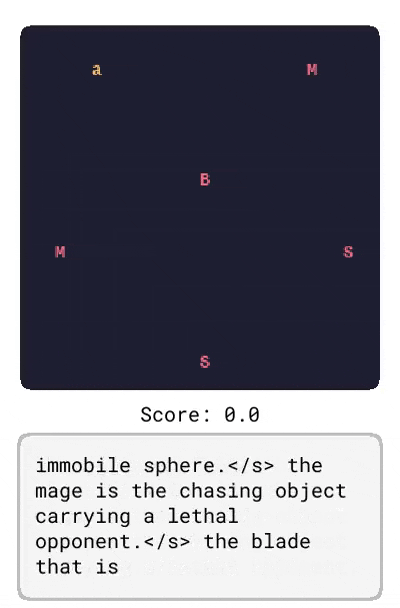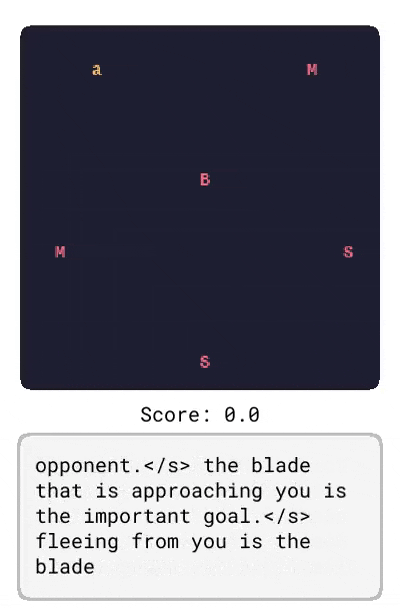
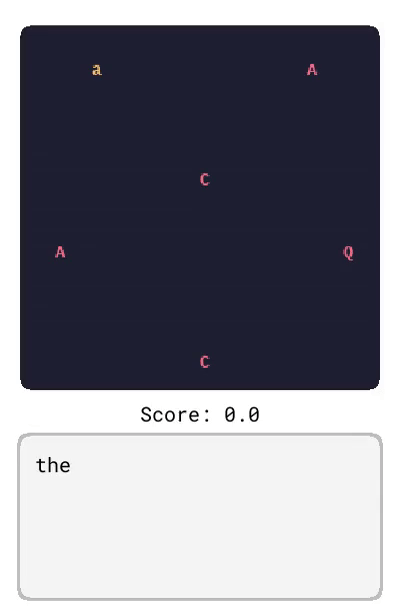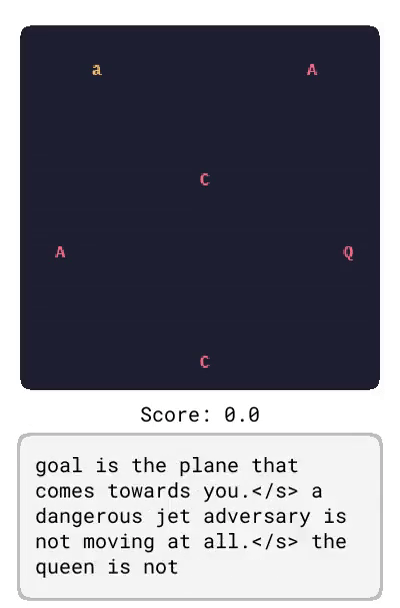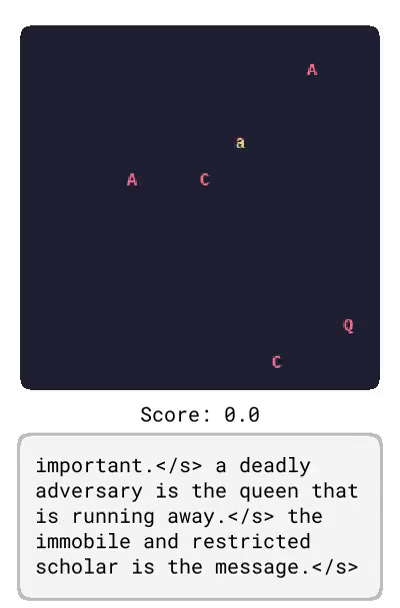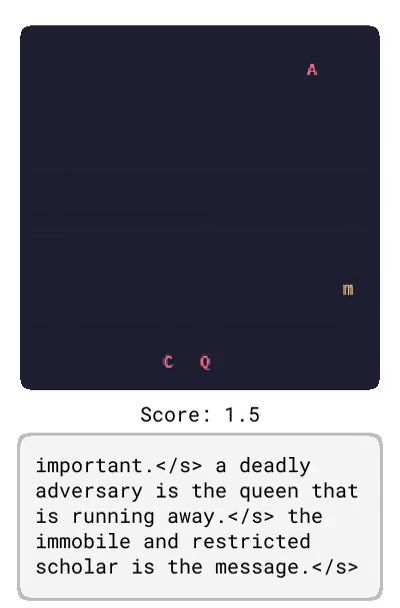

基于 LangRoom 的语言生成
就像语言可以影响智能体对将要看到的事物的预测一样,智能体观察到的内容也会影响它对将要听到的语言的期望(例如,关于它所看到的内容的真实陈述)。通过在 LangRoom 中将语言输出到动作空间,研究者展示了 Dynalang 可以生成与环境相关联的语言,从而进行具身问答。LangRoom 是一个简单的视觉网格世界,具有部分可观察性,智能体需要在其中产生运动动作和语言。

研究者表示,尽管他们的工作专注于用于在世界中行动的语言理解,但它也可以像一个仅文本语言模型一样从世界模型中生成文本。研究者在潜在空间中对预训练的 TinyStories 模型进行模拟的抽样,然后在每个时间步骤从表示中解码 token 观察。尽管生成的文本质量仍然低于当前语言模型的水平,但模型生成的文本令人惊讶地连贯。他们认为将语言生成和行动统一在一个智能体架构中是未来研究的一个令人兴奋的方向。
原文标题:用语言建模世界:UC伯克利多模态世界模型利用语言预测未来
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2939文章
47317浏览量
407840
原文标题:用语言建模世界:UC伯克利多模态世界模型利用语言预测未来
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
如何使用语音指令控制串口输出
在上两篇文章中, 我们实现了GPIO输出, 和PWM输出(组件介绍在前文中已经介绍过 ),在本章节我们将继续进行使用语音指令控制串口输出。
飞凌嵌入式RK3576多模态大模型图像理解助手,让嵌入式设备“看懂”世界
(LLM)+视觉语言模型(VLM)多模态架构,推出多模态大模型图像理解助手,为嵌入式设备打造 “智能视觉中枢”,让终端设备能够真正 “看懂”

自动驾驶中常提的世界模型是个啥?
对外部环境进行抽象和建模的技术,让自动驾驶系统在一个简洁的内部“缩影”里,对真实世界进行描述与预测,从而为感知、决策和规划等关键环节提供有力支持。 什么是世界
世界模型:多模态融合+因果推理,解锁AI认知边界
电子发烧友网综合报道 在人工智能的蓬勃发展进程中,世界模型正崭露头角,成为推动其迈向更高智能水平的关键力量。世界模型作为 AI 系统对外部世界
《虚拟世界的力学交响曲:Adams如何重塑工业仿真边界》
Adams的求解器吞吐着万亿次牛顿力学方程时,我们正在逼近某个临界点——物理世界与数字世界的力学法则开始相互校正。某风力发电机厂商发现,其数字模型预测的叶片颤振频率,竟比实测数据更接近
发表于 06-06 11:36
Matter 智能家居的通用语言
Matter由连接标准联盟(CSA)创建,旨在解决智能家居的互操作性问题。Matter 基于简单性、互操作性、可靠性和安全性四大核心原则 。
是采用基于 IP 应用层的开源协议,本质上是一种“通用语言
发表于 05-19 15:35
商汤“日日新”融合大模型登顶大语言与多模态双榜单
据弗若斯特沙利文(Frost & Sullivan, 简称“沙利文”)联合头豹研究院发布的《2025年中国大模型年度评测》结果显示:在语言和多模态核心能力测评中,商汤“日日新”融合大模型
VLM(视觉语言模型)详细解析
视觉语言模型(Visual Language Model, VLM)是一种结合视觉(图像/视频)和语言(文本)处理能力的多模态人工智能模型,

FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......
”“大模型圈的大黑马”“硅谷震惊了”“来自中国的学霸级AI”……
从智能手机到自动驾驶,从数据中心到物联网,FPGA 正悄然改变着我们的生活。未来,FPGA 又将如何塑造世界?DeepSeek 带你一起
发表于 03-03 11:21
大语言模型的解码策略与关键优化总结
本文系统性地阐述了大型语言模型(LargeLanguageModels,LLMs)中的解码策略技术原理及其实践应用。通过深入分析各类解码算法的工作机制、性能特征和优化方法,为研究者和工程师提供了全面


英伟达发布Cosmos世界基础模型
自动驾驶汽车、机器人等物理AI系统的开发进程。 Cosmos平台的核心在于其强大的生成世界基础模型,这一模型能够模拟和预测现实世界的各种复杂
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
能力。书中提到的Robotic Transformer-1就是一个典型的例子。它通过将自然语言指令与图像输入进行编码和融合,生成融合后的token序列,并利用Transformer预测动作。这种架构
发表于 12-29 23:04
AI大语言模型开发步骤
开发一个高效、准确的大语言模型是一个复杂且多阶段的过程,涉及数据收集与预处理、模型架构设计、训练与优化、评估与调试等多个环节。接下来,AI部落小编为大家详细阐述AI大语言





 工商网监
工商网监
评论