 邱锡鹏团队提出SpeechGPT:具有内生跨模态能力的大语言模型
邱锡鹏团队提出SpeechGPT:具有内生跨模态能力的大语言模型

「 SpeechGPT 为打造真正的多模态大语言模型指明了方向:将不同模态的数据(视觉,语音等)统一表示为离散单元集成在 LLM 之中,在跨模态数据集上经过预训练和指令微调,来使得模型具有多模态理解和生成的能力,从而离 AGI 更进一步。」—— 复旦大学计算机学院教授邱锡鹏

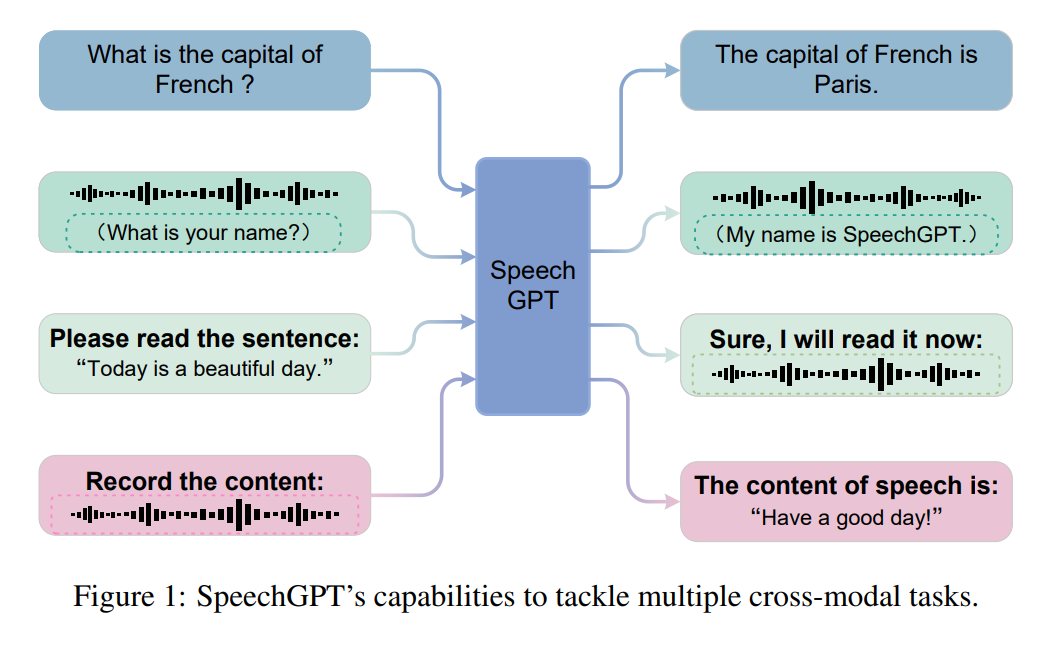
大型语言模型(LLM)在各种自然语言处理任务上表现出惊人的能力。与此同时,多模态大型语言模型,如 GPT-4、PALM-E 和 LLaVA,已经探索了 LLM 理解多模态信息的能力。然而,当前 LLM 与通用人工智能(AGI)之间仍存在显著差距。首先,大多数当前 LLM 只能感知和理解多模态内容,而不能自然而然地生成多模态内容。其次,像图像和语音这样的连续信号不能直接适应接收离散 token 的 LLM。
当前的语音 - 语言(speech-language)模型主要采用级联模式,即 LLM 与自动语音识别(ASR)模型或文本到语音(TTS)模型串联连接,或者 LLM 作为控制中心,与多个语音处理模型集成以涵盖多个音频或语音任务。一些关于生成式口语语言模型的先前工作涉及将语音信号编码为离散表示,并使用语言模型对其进行建模。
虽然现有的级联方法或口语语言模型能够感知和生成语音,但仍存在一些限制。首先,在级联模型中,LLM 仅充当内容生成器。由于语音和文本的表示没有对齐,LLM 的知识无法迁移到语音模态中。其次,级联方法存在失去语音的附加语言信号(如情感和韵律)的问题。第三,现有的口语语言模型只能合成语音,而无法理解其语义信息,因此无法实现真正的跨模态感知和生成。
在本文中,来自复旦大学的张栋、邱锡鹏等研究者提出了 SpeechGPT,这是一个具有内生跨模态对话能力的大型语言模型,能够感知和生成多模态内容。他们通过自监督训练的语音模型对语音进行离散化处理,以统一语音和文本之间的模态。然后,他们将离散的语音 token 扩展到 LLM 的词汇表中,从而赋予模型感知和生成语音的内生能力。

论文链接:https://arxiv.org/pdf/2305.11000.pdf
demo 地址:https://0nutation.github.io/SpeechGPT.github.io/
GitHub 地址:https://github.com/0nutation/SpeechGPT
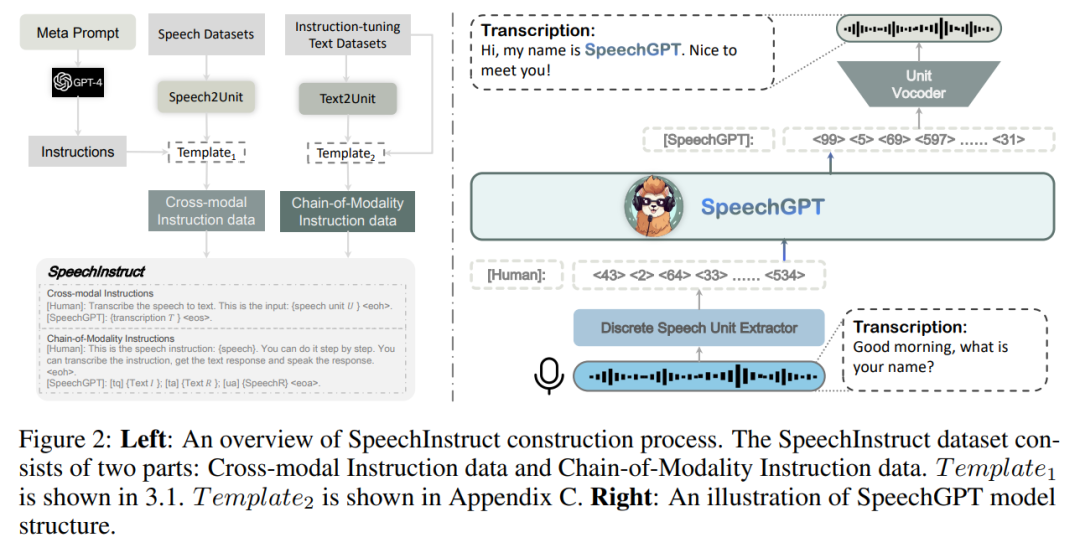
为了为模型提供处理多模态指令的能力,研究者构建了第一个语音 - 文本跨模态指令遵循数据集 SpeechInstruct。具体而言,他们将语音离散化为离散单元(discrete unit),并基于现有的 ASR 数据集构建跨模态的单元 - 文本(unit-text)对。同时,他们使用 GPT-4 构建了针对多个任务的数百个指令,以模拟实际用户的指令,具体见附录 B。此外,为了进一步增强模型的跨模态能力,他们设计了「Chain-of-Modality」指令数据,即模型接收语音命令,用文本思考过程,然后以语音形式输出响应。
为了实现更好的跨模态迁移和高效的训练,SpeechGPT 经历了三个阶段的训练过程:模态适应预训练、跨模态指令微调和 chain-of-modality 指令微调。第一阶段通过离散语音单元连续任务实现了 SpeechGPT 的语音理解能力。第二阶段利用 SpeechInstruct 改进了模型的跨模态能力。第三阶段利用参数高效的 LoRA 微调进行进一步的模态对齐。
为了评估 SpeechGPT 的有效性,研究者进行了广泛的人工评估和案例分析,以评估 SpeechGPT 在文本任务、语音 - 文本跨模态任务和口语对话任务上的性能。结果表明,SpeechGPT 在单模态和跨模态指令遵循任务以及口语对话任务方面展现出强大的能力。
SpeechInstruct
由于公开可用的语音数据的限制和语音 - 文本任务的多样性不足,研究者构建了 SpeechInstruct,这是一个语音 - 文本跨模态指令遵循数据集。该数据集分为两个部分,第一部分叫做跨模态指令,第二部分叫做 Chain-of-Modality 指令。SpeechInstruct 的构建过程如图 2 所示。
SpeechGPT
研究者设计了一个统一的框架,以实现不同模态之间的架构兼容性。如图 2 所示,他们的模型有三个主要组件:离散单元提取器、大型语言模型和单元声码器。在这个架构下,LLM 可以感知多模态输入并生成多模态输出。
离散单元提取器
离散单元提取器利用 Hidden-unit BERT(HuBERT)模型将连续的语音信号转换为一系列离散单元的序列。
HuBERT 是一个自监督模型,它通过对模型的中间表示应用 k-means 聚类来为掩蔽的音频片段预测离散标签进行学习。它结合了 1-D 卷积层和一个 Transformer 编码器,将语音编码为连续的中间表示,然后使用 k-means 模型将这些表示转换为一系列聚类索引的序列。随后,相邻的重复索引被移除,得到表示为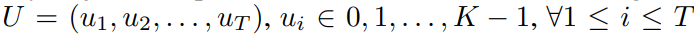 的离散单元序列,K 表示聚类总数。
的离散单元序列,K 表示聚类总数。
大型语言模型
研究者采用 Meta AI 的 LLaMA 模型作为他们的大型语言模型。LLaMA 包括一个嵌入层、多个 Transformer 块和一个语言模型头层。LLaMA 的参数总数范围从 7B 到 65B 不等。通过使用包含 1.0 万亿 token 的大规模训练数据集,LLaMA 在各种自然语言处理基准测试中展现出与规模更大的 175B GPT-3 相当的性能。
单元声码器
由于 (Polyak et al., 2021) 中单个说话人单元声码器的限制,研究者训练了一个多说话人单元的 HiFi-GAN,用于从离散表示中解码语音信号。HiFi-GAN 的架构包括一个生成器 G 和多个判别器 D。生成器使用查找表(Look-Up Tables,LUT)来嵌入离散表示,并通过一系列由转置卷积和具有扩张层的残差块组成的模块对嵌入序列进行上采样。说话人嵌入被连接到上采样序列中的每个帧上。判别器包括一个多周期判别器(Multi-Period Discriminator,MPD)和一个多尺度判别器(Multi-Scale Discriminator,MSD),其架构与 (Polyak et al., 2021) 相同。
实验
跨模态指令遵循
如表 1 所示,当提供不同的指令时,模型能够执行相应的任务并根据这些输入生成准确的输出。

口语对话
表 2 展示了 SpeechGPT 的 10 个口语对话案例。对话表明,在与人类的交互中,SpeechGPT 能够理解语音指令并用语音作出相应回应,同时遵守「HHH」标准(无害、有帮助、诚实)。

局限性
尽管 SpeechGPT 展示出令人印象深刻的跨模态指令遵循和口语对话能力,但仍存在一些限制:
它不考虑语音中的语音外语言信息,例如无法以不同的情绪语调生成回应;
它在生成基于语音的回应之前需要生成基于文本的回应;
由于上下文长度的限制,它无法支持多轮对话。
审核编辑 :李倩
-
模态
+关注
关注
0文章
9浏览量
6436 -
语言模型
+关注
关注
0文章
575浏览量
11381 -
数据集
+关注
关注
4文章
1242浏览量
26310
原文标题:邱锡鹏团队提出SpeechGPT:具有内生跨模态能力的大语言模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
可提高跨模态行人重识别算法精度的特征学习框架
基于预训练视觉-语言模型的跨模态Prompt-Tuning

ACL2021的跨视觉语言模态论文之跨视觉语言模态任务与方法
百图生科AIGP平台发布:提供多种蛋白质生成能力,邀伙伴联手开发“新物种”
利用大语言模型做多模态任务
邱锡鹏团队提出具有内生跨模态能力的SpeechGPT,为多模态LLM指明方向

650亿参数,8块GPU就能全参数微调!邱锡鹏团队把大模型门槛打下来了!


更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

北大&华为提出:多模态基础大模型的高效微调

自动驾驶和多模态大语言模型的发展历程

机器人基于开源的多模态语言视觉大模型

VLM(视觉语言模型)详细解析




评论