 基于PoseDiffusion相机姿态估计方法
基于PoseDiffusion相机姿态估计方法

介绍
一般意义上,相机姿态估计通常依赖于如手工的特征检测匹配、RANSAC和束调整(BA)。在本文中,作者提出了PoseDiffusion,这是一种新颖的相机姿态估计方法,它将深度学习与基于对应关系的约束结合在一起,因此能够在稀疏视图和密集视图状态下以高精度重建相机位置,他们在概率扩散框架内公式化了SfM问题,对给定输入图像的相机姿态的条件分布进行建模,用Diffusion模型来辅助进行姿态估计。在两个真实世界的数据集上证明了其方法比经典的SfM中的姿态估计和基于学习的方法有显著的改进,同时可以在不需要进一步训练的情况下在数据集之间进行泛化。
明确一下,该方法同时估计相机内外参,不同于视觉定位(估计相机外参,即旋转矩阵R和平移向量t)。
什么是扩散模型?
扩散模型是一类生成模型,受非平衡热力学的启发,通过扩散步骤的马尔可夫链近似数据分布,在图像、视频,3D点云生成方面都取得了令人印象深刻的成果。它们能够准确生成各种高质量的样本。
扩散模型的目标是通过捕捉从数据到简单分布的扩散过程的逆过程来学习复杂的数据分布,通常是通过加噪声和去噪来实现。加噪声处理通过一系列步骤将数据样本x逐渐转换为噪声,然后对模型进行训练以学习去噪过程。
去噪扩散概率模型(DDPM)专门将噪声处理定义为高斯。给定T个步骤的方差表,噪声变换定义如下:
方差表被设置为使得xT遵循各向同性高斯分布,即。定义αt=1−βt和,则存在一个闭式解,在给定数据x0的情况下直接对xt进行采样:
如果βt足够小,则反向仍然是高斯的。因此,它可以通过模型Dθ来近似:
为什么可以使用扩散模型来进行姿态估计任务?
一方面扩散模型在建模复杂分布(例如,在图像、视频和点云上)方面都取得了成功,另一方面扩散模型的随机采样过程已被证明可以有效地驾驭复杂分布的对数似然,因此非常适合复杂的BA优化。扩散过程的另一个好处是,它可以一步一步地训练,而不需要在整个优化过程中展开梯度。
方法
基于扩散模型的Bundle Adjustment(BA)
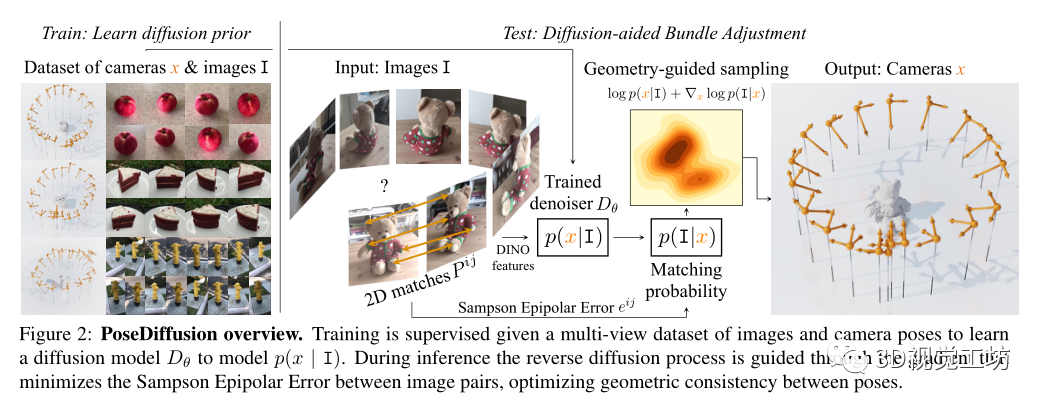
PoseDiffusion对给定图像I的样本x(即相机参数)的条件概率分布p(x|I)进行建模。根据扩散模型(如上所述),通过去噪过程对p(x| I)进行建模,更具体地说,p(x|I)首先通过在N个场景的大训练集 of 上训练扩散模型Dθ来估计,该场景具有真实值图像批Ij和它们的相机参数xj。在推断时,对于一组新的观测图像I,对p(x|I)进行采样,以估计相应的相机参数x。注意,与独立于I的噪声处理不同,去噪处理以输入图像集I为条件,即
将去噪Dθ实现为transfomer Trans,
这里,Trans接受输入图像Ii的有噪姿态元组、扩散时间t和特征嵌入。去噪器输出相应的去噪相机参数的元组,在训练时,Dθ受到监督,具有以下去噪损失:
训练后的去噪器Dθ被用来对pθ(x|I)进行采样,这解决了在给定输入图像I的情况下推断相机参数x的任务。更详细地说,在DDPM采样之后,从随机相机开始,在每次迭代中,下一步通过下式采样:
几何引导的采样
前馈网络需要将图像直接映射到相机参数的空间。考虑到深度网络在回归精确量(即旋转矩阵和平移向量)方面很糟糕,通过利用两视图几何约束,提取场景图像之间可靠的2D对应关系,并指导DDPM采样迭代以便估计的姿态满足对应关系诱导的双视图极线约束。
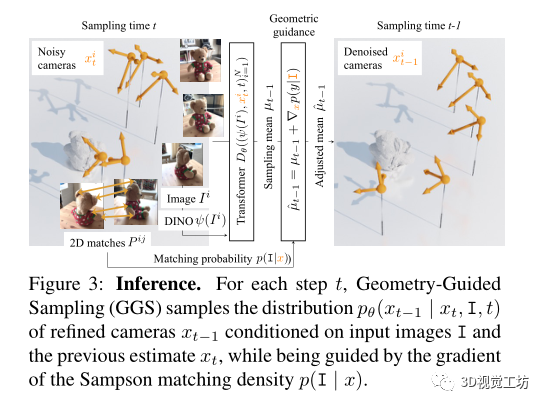
具体来说,让表示一对场景图像的图像点之间的一组二维对应,表示相应的相机姿势。通过Sampson Epipolar Error 来评估相机和2D对应关系之间的兼容性:
遵循分类器diffusion指导来引导采样朝着最小化Sampson极线误差的解决方案进行,因此这满足了图像-图像间的极线约束。
在每次采样迭代中,分类器引导以xt条件引导分布p(I|xt)的梯度扰动预测的平均值:
假设摄像机x上的一致先验允许将p(I|xt)建模为成对Sampson误差上的独立指数分布的乘积:
当所有图像对之间的Sampson误差为0(即满足所有核约束)时,可以获得最终模型。
实验
在两个真实世界的数据集上进行了实验,讨论了模型的设计选择,并与之前的工作进行了比较。
考虑了两个具有不同统计数据的数据集。第一个是CO3Dv2,其中包含50个MS-COCO类别中的物体的大约37k个视频。
其次,对RealEstate10k进行了评估,它包括捕捉房地产内部和外部的80k YouTube剪辑视频。
baseline:
选择COLMAP作为密集姿态估计基线。除了利用RANSAC匹配的SIFT的经典版本外,还对COLMAP+SPG进行了基准测试,它建立在与SuperGlue匹配的SuperPoints的基础上,还与RelPose进行了比较,RelPose是当前稀疏姿态估计的最先进技术。最后为了理解几何引导采样的影响,在没有GGS的情况下实现了学习去噪器。
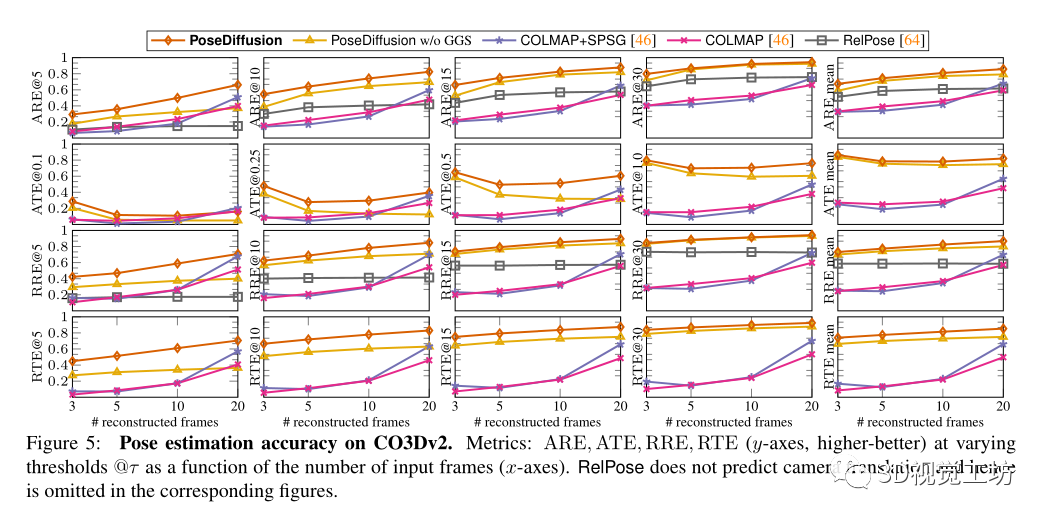
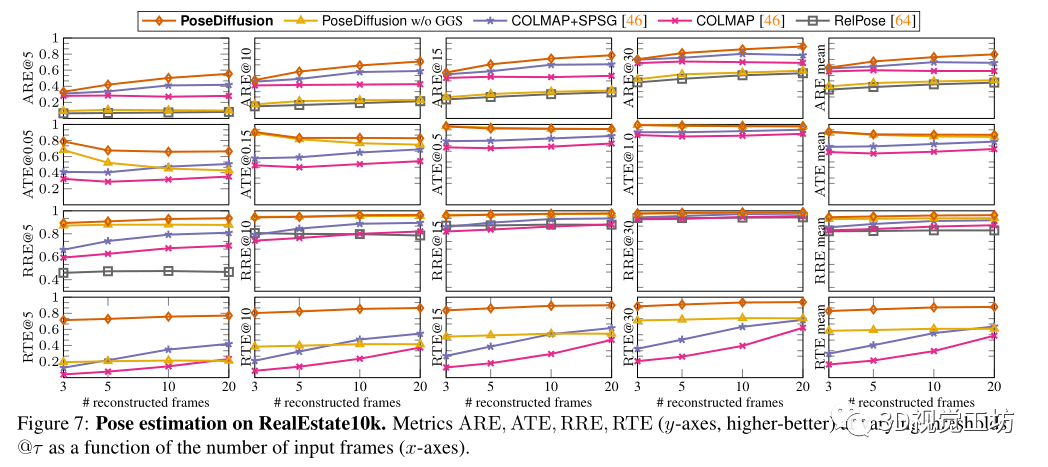
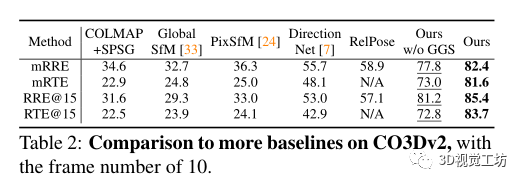
还评估了不同方法泛化到不同数据的能力。首先,在RelPose之后,对来自CO3Dv2的41个训练类别进行训练,并对剩余的10个保留类别进行评估。其方法优于所有基线,表明具有优越的泛化性。
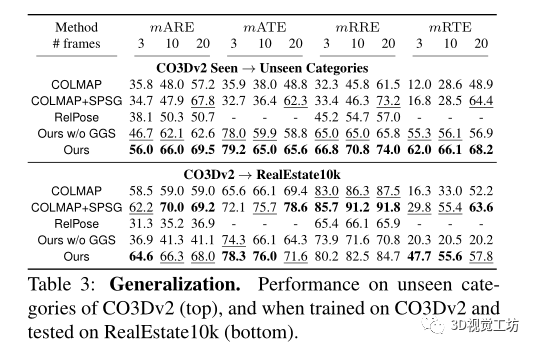
同时该方法还可以用来进行新视图合成,用来帮助nerf。
总结:
提出了Pose diffusion,这是一种学习的相机估计器,同时具有传统极线几何约束和扩散模型的能力。展示了扩散框架如何与相机参数估计任务兼容。这一经典任务的迭代性质反映在去噪扩散公式中。此外,图像对之间的点匹配约束可以用于指导模型并细化最终预测。这改进了传统的SfM方法,如COLMAP,以及学习的方法。展示了在姿态预测精度以及新的视图合成(COLMAP当前最流行的应用之一)任务方面的改进。
责任编辑:彭菁
-
相机
+关注
关注
5文章
1634浏览量
56079 -
模型
+关注
关注
1文章
3873浏览量
52337 -
数据集
+关注
关注
4文章
1242浏览量
26298
原文标题:ArXiv2023 | PoseDiffusion:基于Diffusion的姿态估计算法,来自Meta AI
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
针对姿态传感器的姿态估计方法的详细资料说明免费下载
一种采用深度残差网络的头部姿态估计方法

基于深度学习的二维人体姿态估计方法

基于散焦模糊量估计的相机加权标定方法

基于深度学习的二维人体姿态估计算法

基于Bagging-SVM集成分类器的头部姿态估计方法
基于面部特征点定位的图像人脸姿态估计方法
人脸姿态检测|Fine Grained Head Pose Estimation Without Keypoint

基于OnePose的无CAD模型的物体姿态估计
一种基于去遮挡和移除的3D交互手姿态估计框架
AI深度相机-人体姿态估计应用




评论