 分析 丨 AI数据中心堪比超算,NVIDIA与AMD同场竞技
分析 丨 AI数据中心堪比超算,NVIDIA与AMD同场竞技

超级计算机对于科学研究、能源、工程设计领域具有重要意义,在商业用途中也发挥重要作用。2022年高性能计算专业大会发布的全球超级计算机Top500排行榜显示,美国橡树岭国家实验室(ORNL)的Frontier系统位列榜首,自2022年6月以来,Frontier一直是全球超级计算机Top500名单上的强大设备。
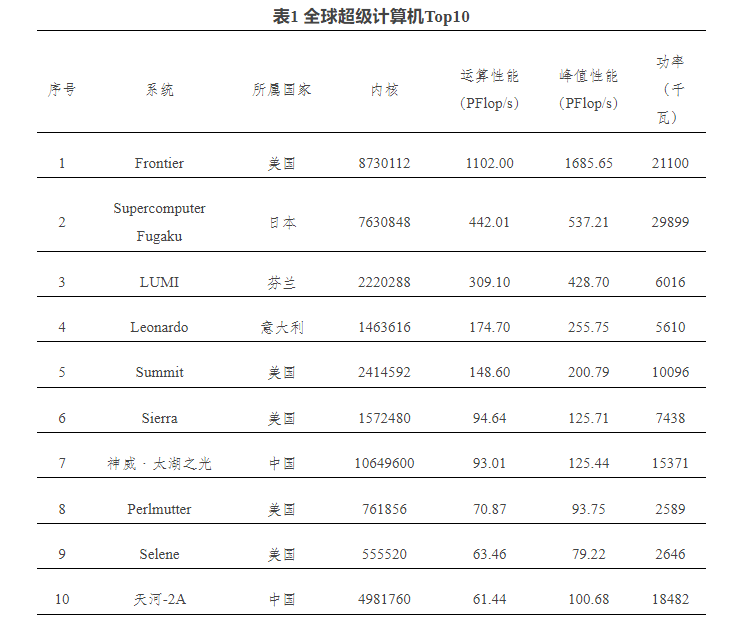
图注:全球超级计算机Top10,发布时间为2022年11月(来源:中科院网信工作网)
进入2023年,超级计算机的排行将发生改变。
芯查查APP显示,在美国劳伦斯利弗莫尔国家实验室(LLNL)安装的“El Capitan”超级计算机最快于2023年底启动,从而可能刷新全球超级计算机榜单。El Capitan估计FP64峰值性能约为2.3 exaflops,比Frontier超级计算机的1.68 exaflops性能高出约37%。
同时,人工智能(AI)应用掀起,超大规模云服务企和AI初创企业都开始构建大型数据中心,比如,NVIDIA和CoreWeave正在为Inflection AI开发数据中心;Microsoft Azure正在为OpenAI构建的数据中心。从下图可以看出,目前在建的这两个AI数据中心在TFLOPS算力性能上虽然不如现有的超级计算机,但是在成本上已经超出很多。
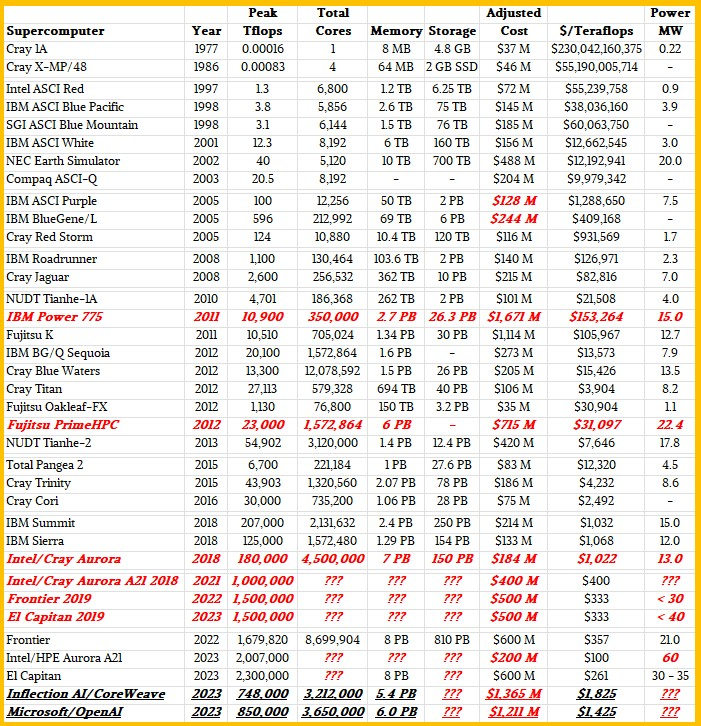
图注:超级计算机与AI数据中心对比(来源:nextplatform网站)
AI数据中心面向AI训练和推理进行配置,在建的AI数据中心进程如何?使用了哪些处理器?
Inflection AI使用处理器:NVIDIA H100Inflection AI是一家由Deep Mind前负责人创建,并由Microsoft和Nvidia支持的新创业公司。目前估值约为40亿美元,产品为AI聊天机器人,支持计划、调度和信息收集。
在筹集了13亿美元的资金之后,Inflection AI将建立一个由多达22000个NVIDIA H100 GPU驱动的超级计算机集群,其峰值理论计算能力将与Frontier相当。理论上能够提供1.474 exaflops的FP64性能。在CUDA内核上运行通用FP64代码时,峰值吞吐量仅为其一半:0.737 FP64 exaflops(与前文图表数值略有出入,但相差不大)。虽然FP64性能对于许多科学工作负载很重要,但对于面向AI的任务,该系统可能会更快。FP16/BF16的峰值吞吐量为43.5 exaflops,FP8吞吐量的峰值吞吐量是87.1 exaflops。
图片来源:NVIDIA
Inflection AI的服务器集群成本尚不清楚,但NVIDIA H100 GPU零售价超过30000美元,预计该集群的GPU成本将达到数亿美元。加上所有机架服务器和其他硬件,将占13亿美元资金的大部分。
在市场需求远远超过供应的情况下,NVIDIA或AMD不会为其GPU计算引擎给予大幅折扣就,其服务器OEM和ODM合作伙伴同样如此。因此,与美国的百亿亿次高性能计算系统相比,这些设备非常昂贵。Inflection AI的FP16半精度性能为21.8 exaflops,足以驱动一些非常大的LLM和DLRM(大型语言模型和深度学习推荐模型)。
El Capitan使用处理器:AMD Instinct MI300A为超级计算机“El Capitan”提供算力的处理器是“Antares”AMD Instinct MI300A CPU-GPU混合体,其FP16矩阵数学性能仍然未知。

图注:基于AMD MI300的刀片设施(来源:http://tomshardware.com)
Instinct MI300是一款数据中心APU,它混合了总共13个chiplet,其中许多是3D堆叠的,形成一个单芯片封装,其中包含24个Zen 4 CPU内核,融合CDNA 3图形引擎和八个总容量为128GB的HBM3内存堆栈。这个芯片拥有1460亿个晶体管,使其成为AMD投入生产的最大芯片。其中,由9个计算die构成的5nm CPU和GPU混合体,在4个6nm die上进行3D堆叠,这4个die主要处理内存和I/O流量。
预计每个MI300A在2.32 GHz时钟频率下可提供784 teraflops性能,常规MI300的时钟频率约为1.7GHz。惠普公司(HPE)或许在El Capitan系统中为每个滑轨配置8个MI300A,El Capitan的计算部分应该有大约2931个节点、46个机柜和8行设备。基于上述猜测,El Capitan应该有大约23500个MI300 GPU,具备大约18.4 exaflops的FP16矩阵数学峰值性能。相比Inflection AI,用更少的钱,发挥出更大性能。
Microsoft/OpenAI使用处理器:NVIDIA H100传闻Microsoft正在为OpenAI构建25000 GPU集群,用于训练GPT-5。
从历史上看,Microsoft Azure使用PCI-Express版本的NVIDIA加速器构建其HPC和AI集群,并使用InfiniBand网络将它们连接在一起。
为OpenAI构建的集群使用NVIDIA H100 PCI-Express板卡,假设为每个20000美元,即5亿美元。另外,使用英特尔“Sapphire Rapids”至强SP主机处理器、2TB的主内存和合理数量的本地存储,每个节点再增加150000美元,这将为容纳这25000个GPU的3125个节点再增加4.69亿美元。InfiniBand网络将增加2.42亿美元。合计12.1亿美元,这些费用要比国家实验室的超级计算机贵很多。
全球超级计算机追求新颖的架构,为最终商业化而进行研发。超大规模云服务商可以做同样的数学运算,构建自己的计算引擎,包括亚马逊网络服务、谷歌、百度和Facebook都是如此。即使有50%的折扣,诸如Inflection AI和OpenAI的设备单位价格仍然比国家实验室为超级计算机昂贵。
“神威·太湖之光”使用处理器:申威26010以2022年的全球超级计算机榜单来看,进入Top10的我国超级计算机是“神威·太湖之光”。资料显示,该计算机安装了40960个中国自主研发的申威26010众核处理器,采用64位自主神威指令系统,峰值性能为12.5亿亿次每秒,持续性能为9.3亿亿次每秒,核心工作频率1.5GHz。
申威和龙芯目前是我国自研处理器的代表,两者均采用自研处理器的指令集架构。CPU国产化目前有3种方式,一个是获得x86内核授权,一个是获得Arm指令集架构授权,另一种是自研指令集架构,这种方式的安全可控程度较高,也是自主化较为彻底的一种方式。

图注:国内服务器处理器厂商
小 结随着人工智能应用发酵,超级计算机与AI数据中心的界限可能变得模糊,两者的硬件和架构已经发展到可以更快地处理更多数据,因此其配置将会逐步超越,芯查查认为,整体呈现为几点趋势:面向AI应用,高性能处理器采用更多核心、异质架构将更加普遍,以支持更多的并行计算和更快的数据处理速度,处理器的内存管理和缓存设计也得到了优化,以减少对主存储器的访问延迟。专门的加速器,比如图形处理单元(GPU)和神经网络处理单元(NPU),将被引入处理器,高效地执行矩阵计算和神经网络。能效是AI数据中心和超级计算机共同难点,处理器能效成为要点,设计趋向于降低功耗和散热需求,采用更先进的制程技术、优化的电源管理以及动态频率调节等方法。AI数据中心和超级计算机建设的需求推动了处理器的发展,也推动了存储、结构和GPU的进步,这些组件都将服务于系统的数据吞吐量和效率。
审核编辑 黄宇
-
数据中心
+关注
关注
18文章
5780浏览量
75213 -
AI
+关注
关注
91文章
41305浏览量
302684
发布评论请先 登录
数据中心缺电,英伟达又有新动作!

意法半导体为超大规模AI数据中心破解供电难题

“上天入海”之算力革命:“海风直连”海底数据中心开启绿色算力新纪元

派恩杰SiC器件在数据中心中的应用
微软最新AI技术数据中心即将启用
华为星河AI高算效数据中心网络亮相ODCC 2025

Cadence 借助 NVIDIA DGX SuperPOD 模型扩展数字孪生平台库,加速 AI 数据中心部署与运营
华为数字能源亮相2025开放数据中心大会
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
加速AI未来,睿海光电800G OSFP光模块重构数据中心互联标准
华为面向拉美地区发布全新星河AI数据中心网络方案
PCIe协议分析仪在数据中心中有何作用?
国民技术发布面向AI数据中心的3 kW数字电源参考设计方案

国民技术发布面向AI数据中心的3 kW数字电源参考设计方案

简单认识安森美AI数据中心电源解决方案



评论