 RAS(二)Intel MCA初探
RAS(二)Intel MCA初探

谈到当前业界使用最广泛、最好的RAS商用解决方案,那么必定是Intel公司。从广泛上来说,大部分公司使用的x86服务器,首选Intel;从RAS能力来说,Intel CPU的MCA架构,从故障检测、故障上报、故障恢复等层面功能都非常完善。所以笔者认为,想要学习Linux RAS,那么Intel CPU手册中MACHINE-CHECK ARCHITECTURE章节和对应的Linux arch/x86/kernel/cpu/mce目录相关代码将是非常好的入门学习资料。
MCA介绍
MCA(Machine Check Architecture)是Intel Xeon,Intel Atom和P6 family系列Processors支持的硬件错误检测、上报机制,硬件错误包括system bus errors,ECC errors,parity errors,cache errors and TLB errors。
从硬件层面看,MCA通过一些MSR(Model Specific Register)来实现检测、记录错误信息等功能。它包含了一组Global Control MSRs和多组Error-Reporting Bank Registers(Each Hardware Unit)记录和上报硬件错误。如下图:
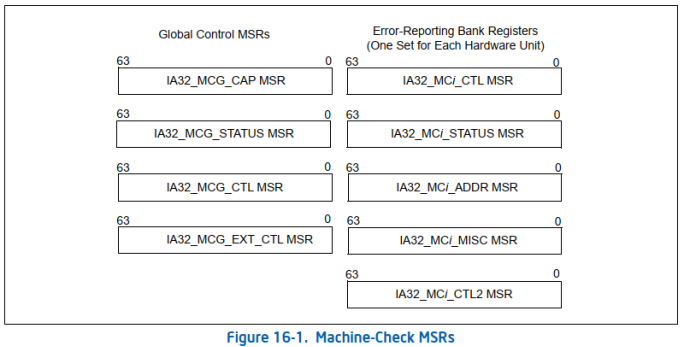
关于这一点,很多人开始都不太理解,也被问过多次。通过下面图可以很清楚的理解:
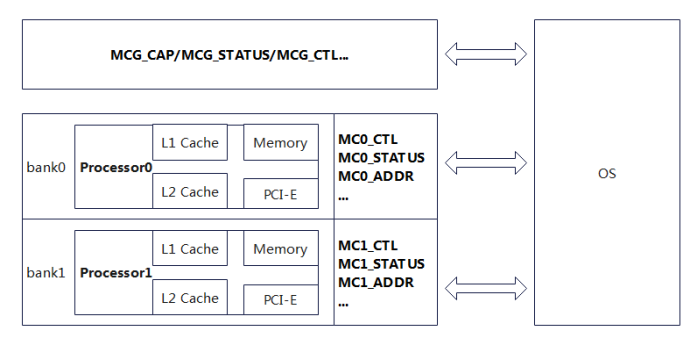
Intel把各个Processor内硬件以bank为单位分组,每个bank涉及多个硬件,共用一组error-reporting register。这个划分并不是随便的、杂乱的,反而是非常规整的。
MCA故障分类
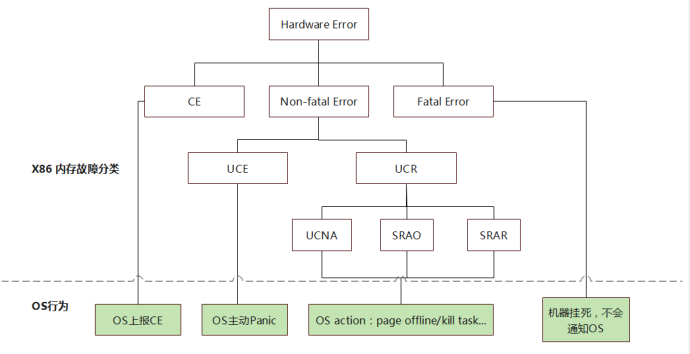
Intel将Hardware Error分类以及行为如下:
•CE(Corrected Error):指硬件自行恢复的故障,通常也会通知软件,软件读取Status寄存器记录故障信息;
•Fata Error:指严重的硬件错误,比如Processor 电源故障,Memory Control严重故障等。此类故障发生后,Intel芯片会直接挂起所有CPU,服务器挂死,不会通知到OS;
•UCE(Uncorrected Error):硬件无法自行恢复的故障。在Intel MCA架构下,此类错误是MCi_STATUS寄存器PCC bit为1,表示Processor可能已经被故障损坏,同时重启Processor也不可靠。软件会根据此信息主动Panic;
•UCR(Uncorrected Recoverable) Error:硬件无法自行恢复,但软件可以采取某些行为修复的错误;
至于UCNA、SRAO、SRAR在讲MCA Recovery机制时再细讲。
当然上述分类并不是绝对的,只能算是最全面的分类。比如Intel将PCIe Device的RAS故障只分为UCE和CE,这是因为Pcie连接外设一般是非核心硬件,比如USB、磁盘、网卡等。这些组件发生UCE后,都会通知到OS尝试修复。
Machine-Check Global Control寄存器组
Machine-Check Global Control MSRs是一组全局寄存器,用于Machine-Check的配置、状态显示等,包括IA32_MCG_CAP/IA32_MCG_STATUS/IA32_MCG_CTL/IA32
_MCG_EXT_CTL寄存器。
IA32_MCG_CAP MSR
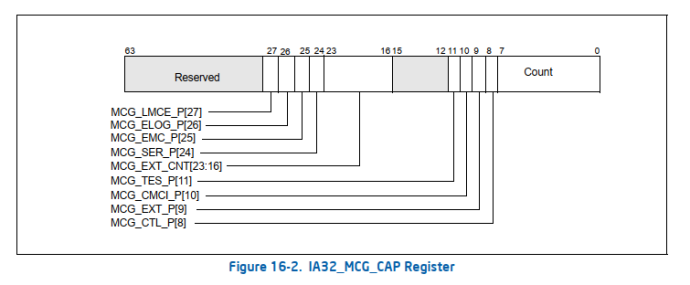
IA32_MCG_CAP MSR是只读寄存器,表示当前Processor拥有的MCA的能力。
Count field, bits 7:0:表示某Processor支持Hardware unit error-reporting banks的数量;
MCG_CTL_P (control MSR present) flag, bit 8:MCG_CTL MSR有效位;
MCG_EXT_P (extended MSRs present) flag, bit 9:MCG_EXT_CTL有效位;
MCG_CMCI_P (Corrected MC error counting/signaling extension present) flag, bit 10:表示当发生一个CE或CE个数超过阈值后,是否通过CMCI中断通知错误;
MCG_TES_P (threshold-based error status present) flag, bit 11:当Set时,表示IA32_MCi_STATUS MSR的54:53用来上报threshold-based error状态;
MCG_EXT_CNT, bits 23:16:表示extended machine-check state registers个数,仅当MCG_EXT_P set时有效;
MCG_SER_P (software error recovery support present) flag, bit 24:当Set时,表示Processor支持software error recovery,同时IA32_MCi_STATUS MSR的56:55位提供uncorrected recoverable errors信息,以及判断软件是否需要task recovery actions来进行恢复。IA32_MCi_STATUS MSR的56:55位是AR和S位,可以对UER进行分类;
MCG_EMC_P (Enhanced Machine Check Capability) flag, bit 25:当Set时,表示Processor支持MCA增强特性;
MCG_ELOG_P (extended error logging) flag, bit 26:当Set时,Processor允许firmware接收硬件错误并将bank寄存器信息记录在ACPI的“Generic Error Data Entry”。这样MCA就可以改为Firmware First并兼容APEI上报方式。
MCG_LMCE_P (local machine check exception) flag, bit 27:是否支持Local Machine Check Exception (LMCE)。当Set后,IA32_MCG_STATUS 的LMCE_S位有效;
Linux内核中使用举例(v6.3,arch/x86/kernel/cpu/mce/core.c)
|
C++
|
这段cap init代码即开始读取MCG_CAP寄存器的Count field, bits 7:0,获取Banks数量,MCG_BANKCNT_MASK定义在mce.h
#define MCG_BANKCNT_MASK 0xff /* Number of Banks */
IA32_MCG_STATUS MSR

IA32_MCG_STATUS MSR描述的是machine-check exception发生后的当前Processor状态。
RIPV (restart IP valid) flag, bit 0:当set时,表示machine-check exception发生后程序是否还可以从异常打断后的指令处重新可靠的执行;当clear时,表示程序无法可靠地从instruction pointer处重新执行;
EIPV (error IP valid) flag, bit 1:当set时,表示machine-check exception和当前instruction pointed有直接关联。当clear时,表示instruction pointed与错误无关;
MCIP (machine check in progress) flag, bit 2:当set时,表示当前machine-check exception正在处理中。软件可以设置或清除此标志位。
LMCE_S (local machine check exception signaled), bit 3:当set时,表示当前的machine-check event被当前Processor捕获和处理。这个bit很有意思,intel以前的cpu,machine-check event可以上报到其他Processor,当前处理的Processor需要遍历所有Banks来找到真正的machine-check even。这个机制对于同步MCE来说非常不友好,后面icelake或arm64,都是自动报到local cpu,省去了很多不必要的麻烦,代码也更简洁。
Linux内核中使用举例(v6.3,arch/x86/kernel/cpu/mce/core.c)
|
C++
|
这里代码在发生UCE后MCE的处理函数do_machine_check()中,通过MCG_STATUS_LMCES确定故障是否是local machine check。
IA32_MCG_CTL MSR
控制machine-check exceptions的上报,写1使能machine-check特性。
IA32_MCG_EXT_CTL MSR
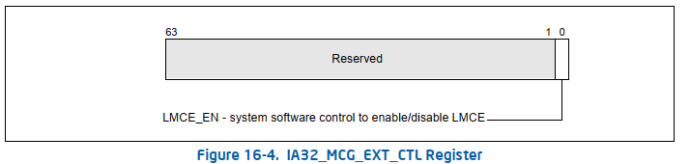
LMCE_EN (local machine check exception enable) flag, bit 0:LMCE功能的使能位。
Error-Reporting Register Banks寄存器组
每个error-reporting register bank包括IA32_MCi_CTL, IA32_MCi_STATUS, IA32_MCi_ADDR, and IA32_MCi_MISC MSRs。
IA32_MCi_CTL MSRs

IA32_MCi_CTL控制每个bank发生硬件错误时产生的#MC信号。
IA32_MCi_STATUS MSRS

每个IA32_MCi_STATUS MSR包含了machine-check error的信息。这个寄存器是比较重要的,包含了硬件错误的故障类型信息等,Linux主要通过这个寄存器对故障进行分类并采取相应的Action。
MCA (machine-check architecture) error code field, bits 15:0:MCA架构定义的Error Code,内部包含了详细的错误信息,比如错误发生硬件、触发原因等。下面会单独将MCA Error Codes;
Model-specific error code field, bits 31:16:MCA架构定义的model-specific error code;
Reserved, Error Status, and Other Information fields, bits 56:32:Error Status和Other Information区域。这些bit包含了更多错误信息,比如UCE的错误类型等等。
PCC (processor context corrupt) flag, bit 57:当Set时,表示Processor可能已经被故障损坏,同时重启Processor也不可靠。当Clear时,表示错误并未影响到Processor状态,并且软件可以采取recovery actions隔离、恢复故障;
ADDRV (IA32_MCi_ADDR register valid) flag, bit 58:ADDR有效位,当Set时,IA32_MCi_ADDR包含了错误发生的物理地址。这个寄存器仅当Memory、Cache data、TLB data发生错误时才会写入物理地址;
MISCV (IA32_MCi_MISC register valid) flag, bit 59:当Set时,表示IA32_MCi_MISC寄存器内包含了附加的错误信息。当Clear时,不要读取IA32_MCi_MISC寄存器信息;
EN (error enabled) flag, bit 60:对应IA32_MCi_CTL register使能位;
UC (error uncorrected) flag, bit 61:当Set时,表示Processor硬件无法恢复这个硬件故障。即UCE;当Clear时,表示Processor可以纠正这次错误,即CE;
OVER (machine check overflow) flag, bit 62:当Set时,表示前一次错误还在上报、处理过程中时又发生了硬件错误,即多次machine error同时发生;
VAL (IA32_MCi_STATUS register valid) flag, bit 63:IA32_MCi_STATUS寄存器信息是否有效;
Linux内核中使用举例(v6.3,arch/x86/kernel/cpu/mce/severity.c)
|
C++
|
Intel服务器在mce_severity_intel()函数中
•通过MCI_STATUS_UC=0确定发生CE类型故障;
•通过MCI_STATUS_UC=1,MCI_UC_AR=1确定发生AO类型故障;
IA32_MCi_ADDR MSRs

当IA32_MCi_STATUS的ADDRV位设置后,IA32_MCi_ADDR MSR表示硬件故障的code或data地址信息:The address returned is an offset into a segment, linear address, or physical address. This depends on the error encountered.
Linux内核中使用举例(v6.3,arch/x86/kernel/cpu/mce/core.c)
|
C++
|
MCE驱动代码中,通过mce_rdmsrl(mca_msr_reg(i, MCA_ADDR))函数读取MCA_ADDR计算内存故障的物理地址。
IA32_MCi_MISC MSRs

如果IA32_MCi_STATUS寄存器的MISCV标志位Set时,IA32_MCi_MISC MSR包含了附加的machine-check error信息。
Recoverable Address LSB (bits 5最低地址有效位。比如IA32_MCi_MISC是01001b,十进制是9,那么故障地址的bits [8:0]需要忽略。
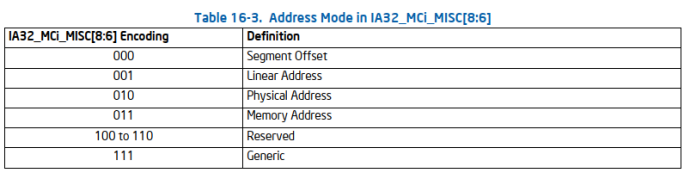
Address Mode (bits 8IA32_MCi_ADDR的地址模式,如下图
Model Specific Information (bits 63 Not architecturally defined.
IA32_MCi_CTL2 MSRs
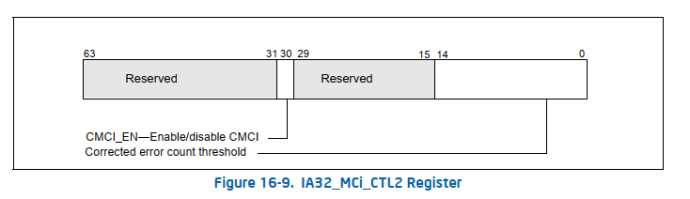
IA32_MCi_CTL2 MSR描述了进程使用CE的通知能力。
Corrected error count threshold, bits 14:0:软件必须初始化这个区域。描述CMCI(corrected machine-check error interrupt)触发的CE阈值,即corrected error数量达到阈值会触发CMCI信号;
CMCI_EN (Corrected error interrupt enable/disable/indicator), bits 30:CMCI使能位
本篇主要对Intel MCA机制、Global Control MSR/Error-reporting Register Bank进行介绍。了解上述2组寄存器,对MCA硬件有个大概的了解,后续会结合内核介绍MCA的增强功能。
参考文档:《Intel 64 and IA-32 Architectures Software Developer’s Manual 》
-
cpu
+关注
关注
68文章
11343浏览量
226053 -
intel
+关注
关注
19文章
3511浏览量
191699 -
MCA
+关注
关注
0文章
9浏览量
9427
原文标题:RAS(二)Intel MCA初探
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
MCA将为临床医护带来革命
TETRACAM全新的Micro-MCA 和Micro-MCA Snap系列产品
美国泰克(Tektronix)MCA3027微波计数器 MCA3027 泰克MCA3027计数器
美国泰克MCA3027回收MCA3040微波计数器
用于ARMv8-A RAS扩展和RAS系统架构2.0 BET0平台的ACPI设计文档
学习架构-RAS概述
利用MCA技术对电机进行故障诊断
MCA_TouchProbeECAT探针是什么
功能块MCA_CamInDirect的电子凸轮功能
Intel MCA-CMCI初探
RISC-V架构CPU的RAS解决方案




评论