 DPU 技术发展概况系列(三) DPU的发展背景
DPU 技术发展概况系列(三) DPU的发展背景

DPU的出现是异构计算的又一个阶段性标志。摩尔定律放缓使得通用CPU性能增长的边际成本迅速上升,数据表明现在CPU的性能年化增长(面积归一化之后)仅有3%左右,但计算需求却是爆发性增长,这几乎是所有专用计算芯片得以发展的重要背景因素。以AI芯片为例,最新的GPT-3等千亿级参数的超大型模型的出现,将算力需求推向了一个新的高度。DPU也不例外。随着2019年我国以信息网络等新型基础设施为代表的“新基建”战略帷幕的拉开,5G、千兆光纤网络建设发展迅速,移动互联网、工业互联网、车联网等领域发展日新月异。云计算、数据中心、智算中心等基础设施快速扩容。网络带宽从主流10G朝着25G、40G、100G、200G甚至400G发展。网络带宽和连接数的剧增使得数据的通路更宽、更密,直接将处于端、边、云各处的计算节点暴露在了剧增的数据量下,而CPU的性能增长率与数据量增长率出现了显著的“剪刀差”现象。所以,寻求效率更高的计算芯片就成为了业界的共识。DPU芯片就是在这样的趋势下提出的。
一、带宽性能增速比(RBP)失调
摩尔定律的放缓与全球数据量的爆发这个正在迅速激化的矛盾通常被作为处理器专用化的大背景,正所谓硅的摩尔定律虽然已经明显放缓,但“数据摩尔定律”已然到来。IDC的数据显示,全球数据量在过去10年年均复合增长率接近50%,并进一步预测每四个月对于算力的需求就会翻一倍。因此必须要找到新的可以比通用处理器带来更快算力增长的计算芯片,DPU于是应运而生。这个大背景虽然有一定的合理性,但是还是过于模糊,并没有回答DPU之所以新的原因是什么,是什么“量变”导致了“质变”?
从现在已经公布的各个厂商的DPU架构来看,虽然结构有所差异,但都不约而同强调网络处理能力。从这个角度看,DPU是一个强IO型的芯片,这也是DPU与CPU最大的区别。CPU的IO性能主要体现在高速前端总线(在Intel的体系里称之为FSB,Front Side Bus),CPU通过FSB连接北桥芯片组,然后连接到主存系统和其他高速外设(主要是PCIe设备)。目前更新的CPU虽然通过集成存储控制器等手段弱化了北桥芯片的作用,但本质是不变的。CPU对于处理网络处理的能力体现在网卡接入链路层数据帧,然后通过操作系统(OS)内核态,发起DMA中断响应,调用相应的协议解析程序,获得网络传输的数据(虽然也有不通过内核态中断,直接在用户态通过轮询获得网络数据的技术,如Intel的DPDK,Xilinx的Onload等,但目的是降低中断的开销,降低内核态到用户态的切换开销,并没有从根本上增强IO性能)。可见,CPU是通过非常间接的手段来支持网络IO,CPU的前端总线带宽也主要是要匹配主存(特别是DDR)的带宽,而不是网络IO的带宽。
相较而言,DPU的IO带宽几乎可以与网络带宽等同,例如,网络支持25G,那么DPU就要支持25G。从这个意义上看,DPU继承了网卡芯片的一些特征,但是不同于网卡芯片,DPU不仅仅是为了解析链路层的数据帧,而是要做直接的数据内容的处理,进行复杂的计算。所以,DPU是在支持强IO基础上的具备强算力的芯片。简言之,DPU是一个IO密集型的芯片;相较而言,GPU还是一个计算密集型芯片。
进一步地,通过比较网络带宽的增长趋势和通用CPU性能增长趋势,能发现一个有趣的现象:带宽性能增速比(RBP,Ratioof Bandwidth and Performance growth rate)失调。RBP定义为网络带宽的增速比上CPU性能增速,即RBP=BW GR/Perf. GR如下图所示,以Mellanox的ConnectX系列网卡带宽作为网络IO的案例,以Intel的系列产品性能作为CPU的案例,定义一个新指标“带宽性能增速比”来反应趋势的变化。
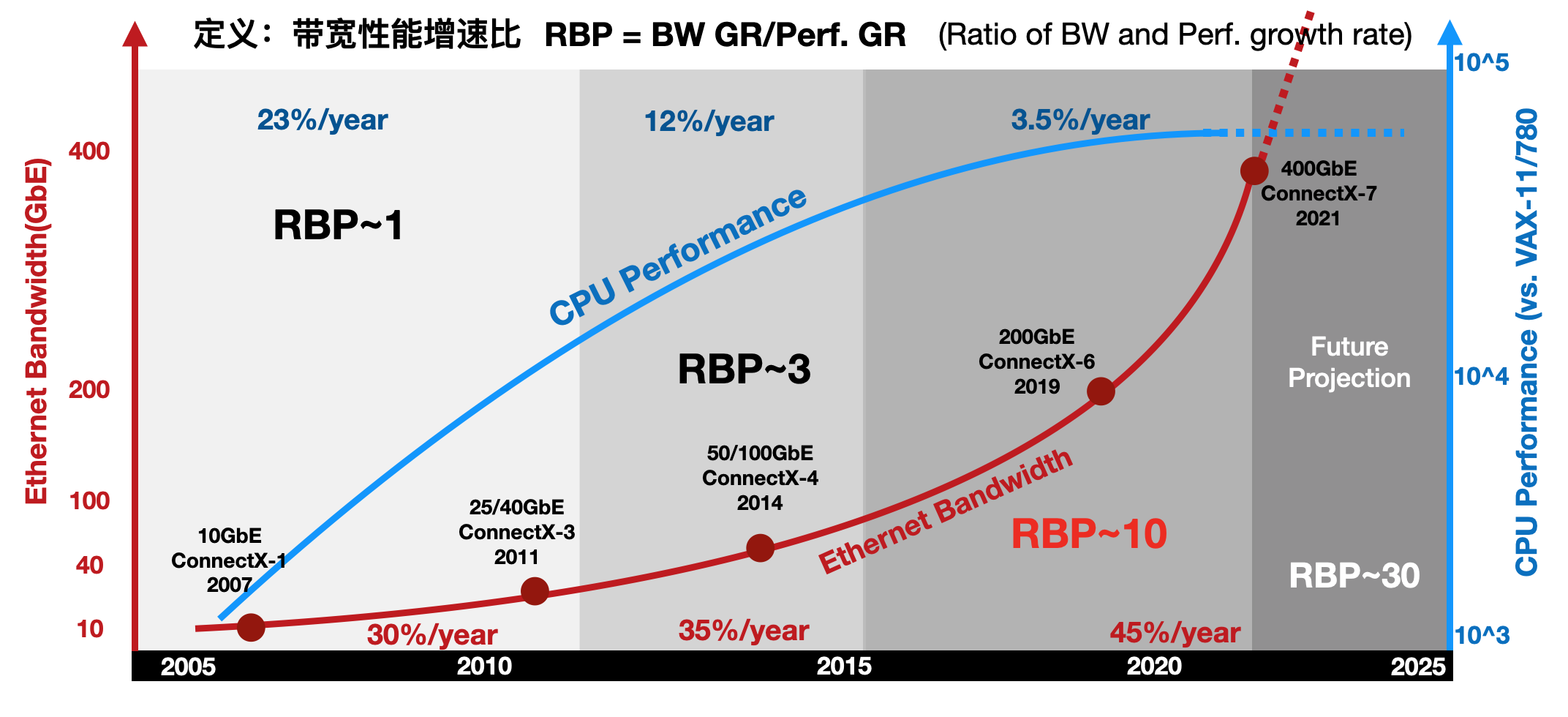
图 带宽性能增速比(RBP)失调
2010年前,网络的带宽年化增长大约是30%,到2015年微增到35%,然后在近年达到45%。相对应的,CPU的性能增长从10年前的23%,下降到12%,并在近年直接降低到3%。在这三个时间段内,RBP指标从1附近,上升到3,并在近年超过了10!如果在网络带宽增速与CPU性能增速近乎持平,RGR~1,IO压力尚未显现出来,那么当目前RBP达到10倍的情形下,CPU几乎已经无法直接应对网络带宽的增速。RBP指标在近几年剧增也许是DPU终于等到机会“横空出世”的重要原因之一。
二、异构计算发展趋势的助力
DPU首先作为计算卸载的引擎,直接效果是给CPU“减负”。DPU的部分功能可以在早期的TOE(TCP/IP Offloading Engine)中看到。正如其名,TOE就是将CPU的处理TCP协议的任务“卸载”到网卡上。传统的TCP软件处理方式虽然层次清晰,但也逐渐成为网络带宽和延迟的瓶颈。软件处理方式对CPU的占用,也影响了CPU处理其他应用的性能。TCP卸载引擎(TOE)技术,通过将TCP协议和IP协议的处理进程交由网络接口控制器进行处理,在利用硬件加速为网络时延和带宽带来提升的同时,显著降低了CPU处理协议的压力。具体有三个方面的优化:1)隔离网络中断,2)降低内存数据拷贝量,3)协议解析硬件化。这三个技术点逐渐发展成为现在数据平面计算的三个技术,也是DPU普遍需要支持的技术点。例如,NVMe协议,将中断策略替换为轮询策略,更充分的开发高速存储介质的带宽优势;DPDK采用用户态调用,开发“Kernel-bypassing”机制,实现零拷贝(Zeor-Copy);在DPU中的面向特定应用的专用核,例如各种复杂的校验和计算、数据包格式解析、查找表、IP安全(IPSec)的支持等,都可以视为协议处理的硬件化支持。所以,TOE基本可以被视为DPU的雏形。
延续TOE的思想,将更多的计算任务卸载至网卡侧来处理,促进了智能网卡(SmartNIC)技术的发展。常见的智能网卡的基本结构是以高速网卡为基本功能,外加一颗高性能的FPGA芯片作为计算的扩展,来实现用户自定义的计算逻辑,达到计算加速的目的。然而,这种“网卡+FPGA”的模式并没有将智能网卡变成一个绝对主流的计算设备,很多智能网卡产品被当作单纯的FPGA加速卡来使用,在利用FPGA优势的同时,也继承了所有FPGA的局限性。DPU是对现有的SmartNIC的一个整合,能看到很多以往SmartNIC的影子,但明显高于之前任何一个SmartNIC的定位。
Amazon的AWS在2013研发了Nitro产品,将数据中心开销(为虚机提供远程资源,加密解密,故障跟踪,安全策略等服务程序)全部放到专用加速器上执行。Nitro架构采用轻量化Hypervisor配合定制化的硬件,将虚拟机的计算(主要是CPU和内存)和I/O(主要是网络和存储)子系统分离开来,通过PCIe总线连接,节省了30%的CPU资源。阿里云提出的X-Dragon系统架构,核心是MOC卡,有比较丰富的对外接口,也包括了计算资源、存储资源和网络资源。MOC卡的核心X-Dragon SOC,统一支持网络,IO、存储和外设的虚拟化,为虚拟机、裸金属、容器云提供统一的资源池。
可见,DPU其实在行业内已经孕育已久,从早期的网络协议处理卸载,到后续的网络、存储、虚拟化卸载,其带来的作用还是非常显著的,只不过在此之前DPU“有实无名”,现在是时候迈上一个新的台阶了。
来源:专用数据处理器(DPU)技术白皮书,中国科学院计算技术研究所,鄢贵海等
-
DPU
+关注
关注
0文章
419浏览量
27198
发布评论请先 登录
中科驭数DPU芯片亮相第九届数字中国建设峰会 自研核心技术筑牢国产算力底座

中关村云计算产业联盟党建交流活动在中科驭数圆满举办
【「芯片设计基石——EDA产业全景与未来展望」阅读体验】跟着本书来看EDA的奥秘和EDA发展




评论