 ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2

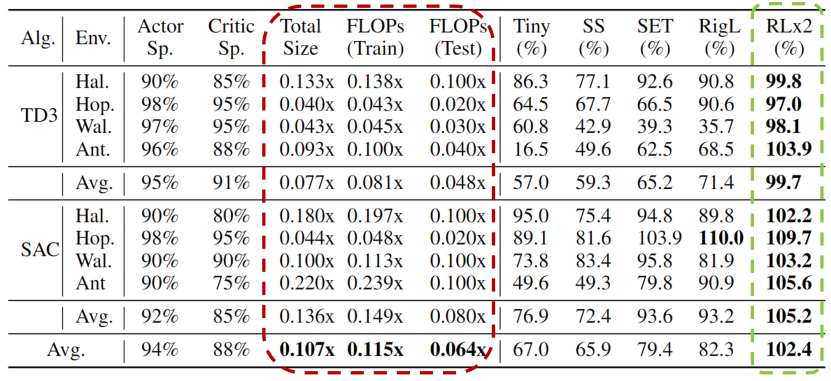
深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭代训练稠密网络,训练过程仍需要大量的计算资源。另外,由于强化学习自举训练的复杂性,训练过程中全程进行稀疏训练在深度强化学习领域尚未得到充分的研究。 清华大学黄隆波团队提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),可适用于多种离策略强化学习算法。它采用基于梯度的拓扑演化原则,能够完全基于稀疏网络训练稀疏深度强化学习模型。RLx2 引入了一种延迟多步差分目标机制,配合动态容量的回放缓冲区,实现了在稀疏模型中的稳健值学习和高效拓扑探索。在多个 MuJoCo 基准任务中,RLx2 达到了最先进的稀疏训练性能,显示出 7.5 倍至 20 倍的模型压缩,而仅有不到 3% 的性能降低,并且在训练和推理中分别减少了高达 20 倍和 50 倍的浮点运算数。大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。

- 论文主页:https://arxiv.org/abs/2205.15043
- 论文代码:https://github.com/tyq1024/RLx2
图:基于强化学习的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家 高昂的资源消耗限制了深度强化学习在资源受限设备上的训练和部署。为了解决这一问题,作者引入了稀疏神经网络。稀疏神经网络最初在深度监督学习中提出,展示出了对深度强化学习模型压缩和训练加速的巨大潜力。在深度监督学习中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于网络结构演化的动态稀疏训练(Dynamic sparse training - DST)框架可以从头开始训练一个 90% 稀疏的神经网络,而不会出现性能下降。
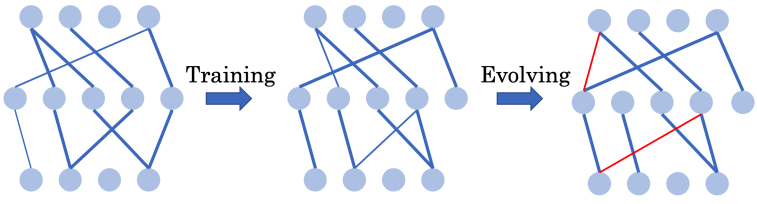
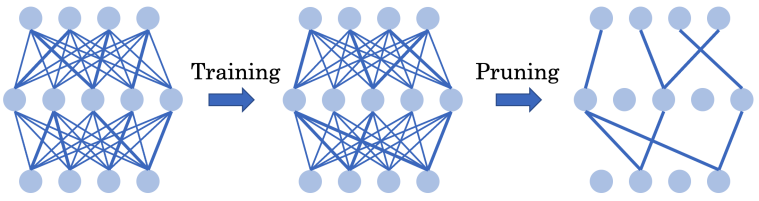
能否通过全程使用超稀疏网络从头训练出高效的深度强化学习智能体?
方法 清华大学黄隆波团队对这一问题给出了肯定的答案,并提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于离策略强化学习(Off-policy RL)。这是第一个在深度强化学习领域以 90% 以上稀疏度进行全程稀疏训练,并且仅有微小性能损失的算法框架。RLx2 受到了在监督学习中基于梯度的拓扑演化的动态稀疏训练方法 RigL [Evci et al. 2020] 的启发。然而,直接应用 RigL 无法实现高稀疏度,因为稀疏的深度强化学习模型由于假设空间有限而导致价值估计不可靠,进而干扰了网络结构的拓扑演化。 因此,RLx2 引入了延迟多步差分目标(Delayed multi-step TD target)机制和动态容量回放缓冲区(Dynamic capacity buffer),以实现稳健的价值学习(Value learning)。这两个新组件解决了稀疏拓扑下的价值估计问题,并与基于 RigL 的拓扑演化准则一起实现了出色的稀疏训练性能。为了阐明设计 RLx2 的动机,作者以一个简单的 MuJoCo 控制任务 InvertedPendulum-v2 为例,对四种使用不同价值学习和网络拓扑更新方案的稀疏训练方法进行了比较。
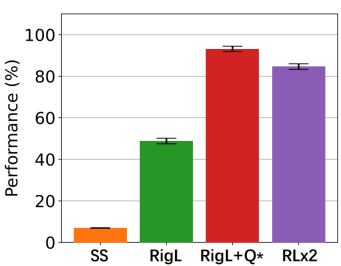
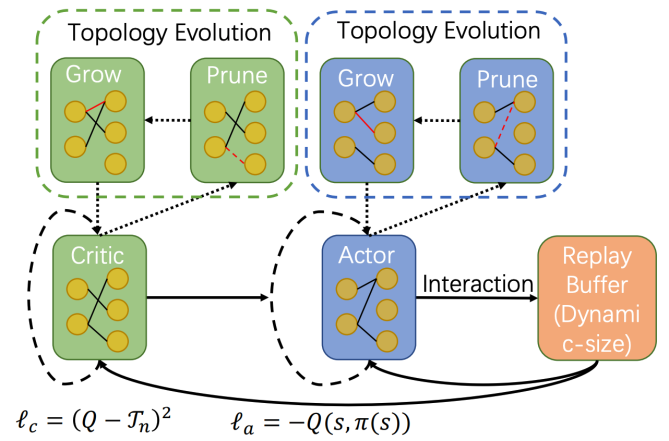
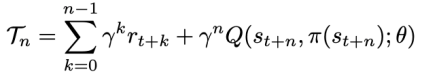

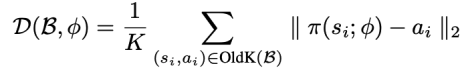
原文标题:ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2950文章
48164浏览量
418928
原文标题:ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
近日,上汽奥迪宣布旗下 E5 Sportback 车型升级搭载 全新Momenta 强化学习大模型。
蚂蚁集团全模态代码算法团队自研OpAgent技术框架
为应对真实 Web 环境的非结构化复杂性、时序不稳定性与交互隐式逻辑等挑战,蚂蚁集团全模态代码算法团队提出了一套结合了多任务微调、在线强化学习与模块化协作的综合解决方案:OpAgent。

自动驾驶中常提的离线强化学习是什么?
,图片源自:网络 但强化学习本身是需要不断试错的,如果采用这种学习方式在真实道路中不断尝试,一定会导致不可控的事故。于是就有人提出一种猜测,能不能利用已经存在的大量行驶日志、仿真记录和人类驾驶数据,在

强化学习会让自动驾驶模型学习更快吗?
[首发于智驾最前沿微信公众号]在谈及自动驾驶大模型训练时,有的技术方案会采用模仿学习,而有些会采用强化学习。同样作为大模型的训练方式,强化学习

多智能体强化学习(MARL)核心概念与算法概览
训练单个RL智能体的过程非常简单,那么我们现在换一个场景,同时训练五个智能体,而且每个都有自己的目标、只能看到部分信息,还能互相帮忙。这就是多智能体强化学习

如何训练好自动驾驶端到端模型?
[首发于智驾最前沿微信公众号]最近有位小伙伴在后台留言提问:端到端算法是怎样训练的?是模仿学习、强化学习和离线强化学习这三类吗?其实端到端(end-to-end)算法在自动驾驶、智能体

今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
智元推出真机强化学习,机器人训练周期从“数周”减至“数十分钟” 近日,智元机器人宣布其研发的真机强化学习技术,已在与龙旗科技合作的验证产线中成功落地。据介绍,此次落地的真机强化学习
发表于 11-05 09:44
•1175次阅读
自动驾驶中常提的“强化学习”是个啥?
[首发于智驾最前沿微信公众号]在谈及自动驾驶时,有些方案中会提到“强化学习(Reinforcement Learning,简称RL)”,强化学习是一类让机器通过试错来学会做决策的技术。简单理解

在Ubuntu20.04系统中训练神经网络模型的一些经验
本帖欲分享在Ubuntu20.04系统中训练神经网络模型的一些经验。我们采用jupyter notebook作为开发IDE,以TensorFlow2为训练框架,目标是
发表于 10-22 07:03
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率
随着模型规模迈入百亿、千亿甚至万亿参数级别,如何在有限显存中“塞下”训练任务,对研发和运维团队都是巨大挑战。NVIDIA Megatron-Core 作为流行的大模型训练框架,提供了灵

NVIDIA Isaac Lab多GPU多节点训练指南
NVIDIA Isaac Lab 是一个适用于机器人学习的开源统一框架,基于 NVIDIA Isaac Sim 开发,其模块化高保真仿真适用于各种训练环境,可提供各种物理 AI 功能和由 GPU 驱动的物理仿真,缩小仿真与现实世
如何在Ray分布式计算框架下集成NVIDIA Nsight Systems进行GPU性能分析
在大语言模型的强化学习训练过程中,GPU 性能优化至关重要。随着模型规模不断扩大,如何高效地分析和优化 GPU 性能成为开发者面临的主要挑战之一。
NVIDIA Isaac Lab可用环境与强化学习脚本使用指南
Lab 是一个适用于机器人学习的开源模块化框架,其模块化高保真仿真适用于各种训练环境,Isaac Lab 同时支持模仿学习(模仿人类)和强化学习

【书籍评测活动NO.62】一本书读懂 DeepSeek 全家桶核心技术:DeepSeek 核心技术揭秘
与 PPO 对比示意图
03.奖励模型的创新
在强化学习的训练过程中,DeepSeek 研究团队选择面向结果的奖励模型 ,而不是通常的面向过程的奖励模型。这种方式可以较好地避免奖励欺骗,同时,由于
发表于 06-09 14:38
OCR识别训练完成后给的是空压缩包,为什么?
OCR识别 一共弄了26张图片,都标注好了,点击开始训练,显示训练成功了,也将压缩包发到邮箱了,下载下来后,压缩包里面是空的
OCR图片20几张图太少了。麻烦您多添加点,参考我们的ocr识别训练数据集
请问
发表于 05-28 06:46



评论