 如何实现YOLOv8 + ONNRUNTIME推理界面化与多线程支持
如何实现YOLOv8 + ONNRUNTIME推理界面化与多线程支持

2023年一月份跟二月份创建了一个PyQT5人工智能软件开发系列的文章系列,过去的两个月都没怎么更新,心里一直想有时间继续更新下去,今天又更新了一篇,基于PyQT5实现多线程、界面化、YOLOv8对象检测、实例分割、姿态评估的推理。
基本设计思路
这个系列我好久没有更新了,今天更新一篇PyQT5中如何实现YOLOv8 + ONNRUNTIME推理界面化与多线程支持。首先需要实现三个类分别完成YOLOv8的对象检测、实例分割、姿态评估模型推理。然后在实现界面类,构建如图:
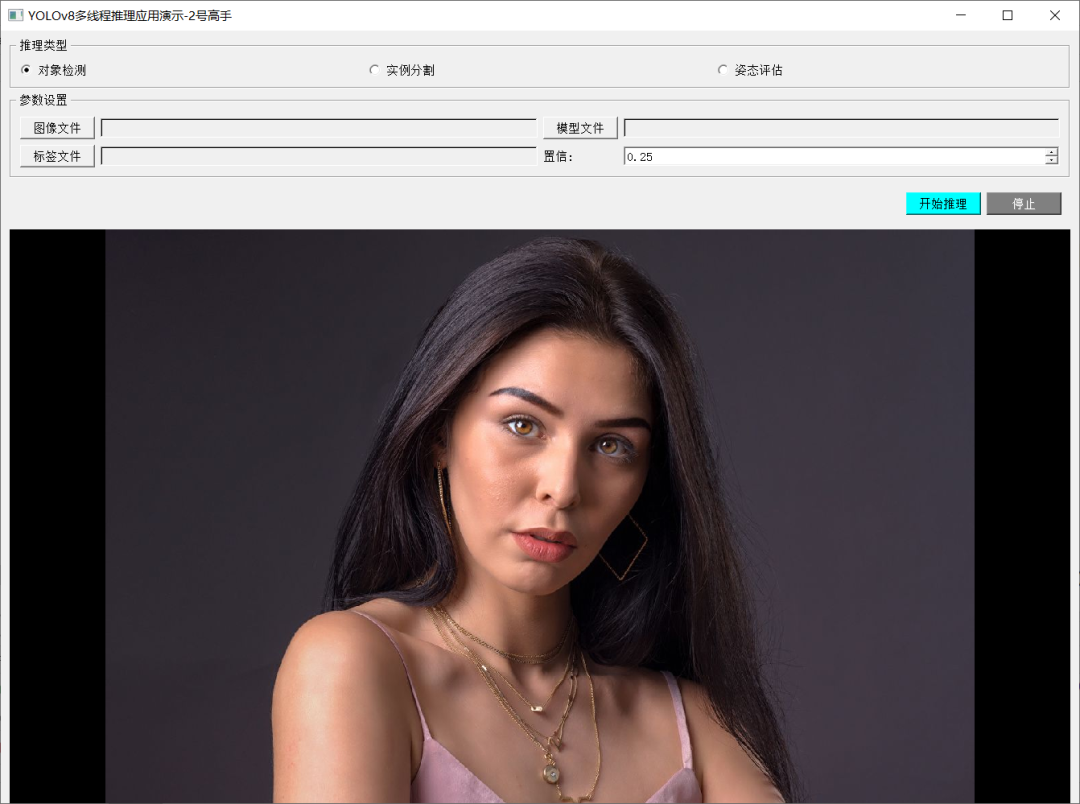
推理类型通过单选按钮实现选择,支持对象检测、实例分割、姿态评估。参数设置选择模型文件与标签文件地址作为输入,同时选择置信度,置信度之在0~1之间。 推理按钮开发推理演示,支持视频与图像文件,开始推理会单独开启一个推理线程实现推理,推理结果通过信号发送到指定的槽函数处理之后更新界面,通过信号与槽机制实现界面线程跟推理线程相互独立与数据共享。
界面代码实现
界面部分通过一个QWidget实现一个面板,通过垂直与水平布局实现界面组件的布局管理,相关的代码实现如下:
classYOLOv8InferPanel(QtWidgets.QWidget): def__init__(self,parent=None): super().__init__(parent) #文本标签 self.rbtn0=QtWidgets.QRadioButton("对象检测") self.rbtn1=QtWidgets.QRadioButton("实例分割") self.rbtn3=QtWidgets.QRadioButton("姿态评估") self.rbtn0.setChecked(True) hbox_layout1=QtWidgets.QHBoxLayout() hbox_layout1.addWidget(self.rbtn0) hbox_layout1.addWidget(self.rbtn1) hbox_layout1.addWidget(self.rbtn3) panel3=QtWidgets.QGroupBox("推理类型") panel3.setLayout(hbox_layout1) #输入文本框 self.image_file_edit=QtWidgets.QLineEdit() self.image_file_edit.setMinimumWidth(100) self.image_file_edit.setEnabled(False) fileBtn=QtWidgets.QPushButton("图像文件") self.weight_file_path=QtWidgets.QLineEdit() self.weight_file_path.setMinimumWidth(100) self.weight_file_path.setEnabled(False) modelBtn=QtWidgets.QPushButton("模型文件") self.label_file_path=QtWidgets.QLineEdit() self.label_file_path.setMinimumWidth(100) self.label_file_path.setEnabled(False) labelBtn=QtWidgets.QPushButton("标签文件") self.conf_spinbox=QtWidgets.QDoubleSpinBox() self.conf_spinbox.setRange(0,1) self.conf_spinbox.setSingleStep(0.01) self.conf_spinbox.setValue(0.25) grid_layout2=QtWidgets.QGridLayout() grid_layout2.addWidget(fileBtn,0,0) grid_layout2.addWidget(self.image_file_edit,0,1) grid_layout2.addWidget(modelBtn,0,2) grid_layout2.addWidget(self.weight_file_path,0,3) grid_layout2.addWidget(labelBtn,1,0) grid_layout2.addWidget(self.label_file_path,1,1) grid_layout2.addWidget(QtWidgets.QLabel("置信:"),1,2) grid_layout2.addWidget(self.conf_spinbox,1,3) panel2=QtWidgets.QGroupBox("参数设置") panel2.setLayout(grid_layout2) #输入文本框 self.label=QtWidgets.QLabel() self.label.setMinimumSize(1280,720) pixmap=QtGui.QPixmap("images/wp.jpg") pix=pixmap.scaled(QtCore.QSize(1280,720),QtCore.Qt.KeepAspectRatio) self.label.setPixmap(pix) self.label.setAlignment(QtCore.Qt.AlignCenter) self.label.setStyleSheet("background-color:black;color:green") self.startBtn=QtWidgets.QPushButton("开始推理") self.stopBtn=QtWidgets.QPushButton("停止") self.startBtn.setStyleSheet("background-color:cyan;color:black") self.stopBtn.setStyleSheet("background-color:gray;color:white") self.stopBtn.setEnabled(False) hbox_layout=QtWidgets.QHBoxLayout() hbox_layout.addStretch(1) hbox_layout.addWidget(self.startBtn) hbox_layout.addWidget(self.stopBtn) panel1=QtWidgets.QWidget() panel1.setLayout(hbox_layout) #添加到布局管理器中 vbox_layout=QtWidgets.QVBoxLayout() vbox_layout.addWidget(panel3) vbox_layout.addWidget(panel2) vbox_layout.addWidget(panel1) vbox_layout.addWidget(self.label) vbox_layout.addStretch(1) #面板容器 self.setLayout(vbox_layout) #setuplistener modelBtn.clicked.connect(self.on_weight_select) fileBtn.clicked.connect(self.on_update_image) labelBtn.clicked.connect(self.on_label_select) self.startBtn.clicked.connect(self.on_yolov8_infer) self.work_thread=None
推理线程
基于QThread继承实现run方法,完成推理线程构建,根据传入的参数不同,初始化不同的推理类型(对象检测、实例分割、姿态评估),推理线程实现代码如下:
classInferenceThread(QtCore.QThread):
fire_stats_signal=QtCore.pyqtSignal(dict)
def__init__(self,settings):
super(InferenceThread,self).__init__()
self.settings=settings
self.detector=None
ifself.settings.model_type==0:
self.detector=YOLOv8ORTDetector(settings)
ifself.settings.model_type==1:
self.detector=YOLOv8ORTSegment(settings)
ifself.settings.model_type==2:
self.detector=YOLOv8ORTPose(settings)
self.input_image=settings.input_image
defrun(self):
ifself.detectorisNone:
return
ifself.input_image.endswith(".mp4"):
cap=cv.VideoCapture(self.input_image)
whileTrue:
ret,frame=cap.read()
ifretisTrue:
self.detector.infer_image(frame)
self.fire_stats_signal.emit({"result":frame})
else:
break
else:
frame=cv.imread(self.input_image)
self.detector.infer_image(frame)
self.fire_stats_signal.emit({"result":frame})
self.fire_stats_signal.emit({"done":"done"})
return
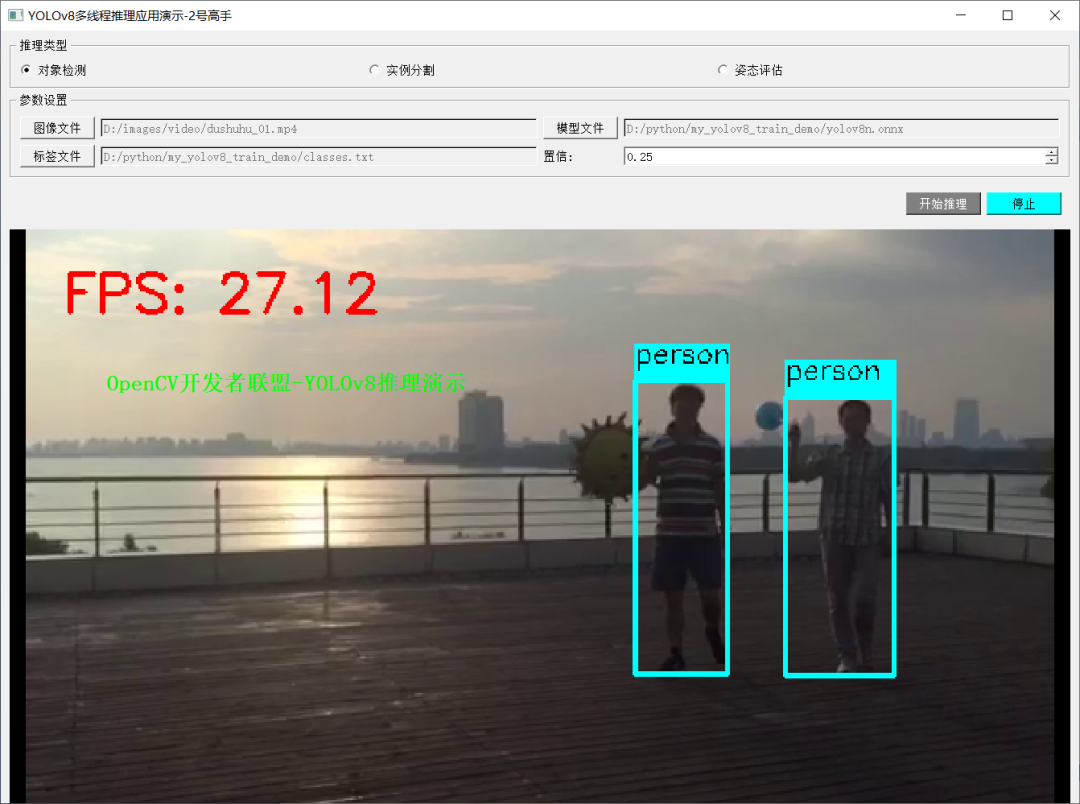
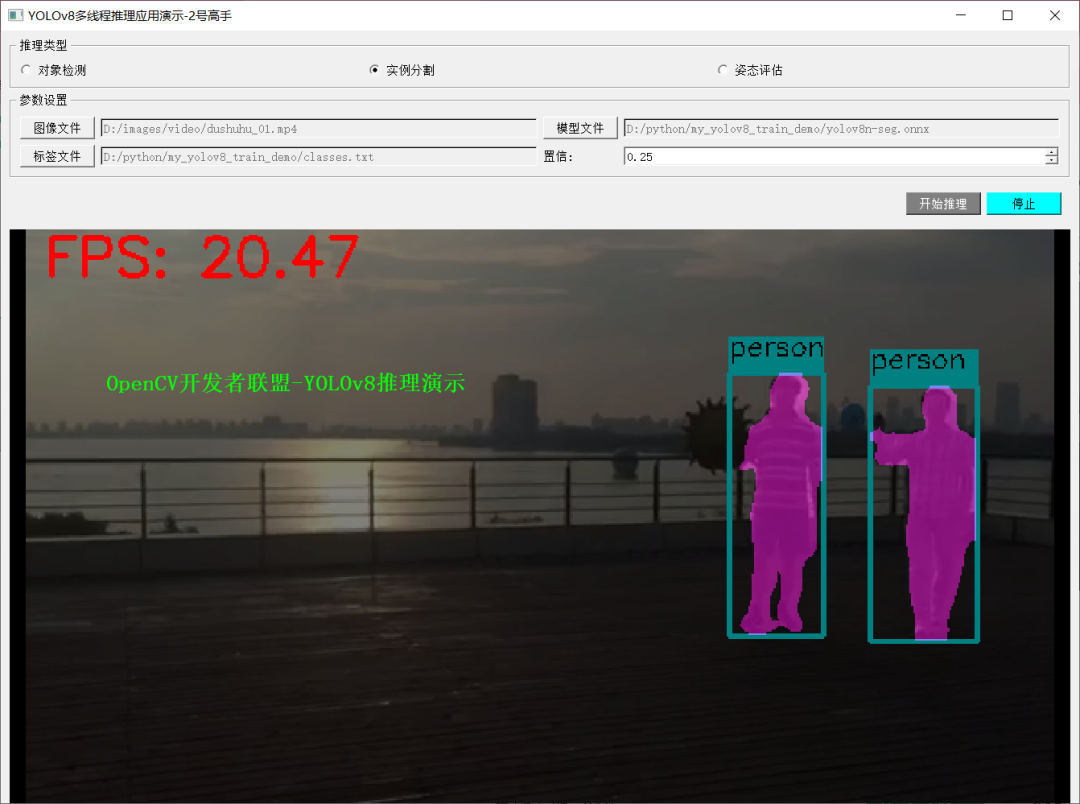
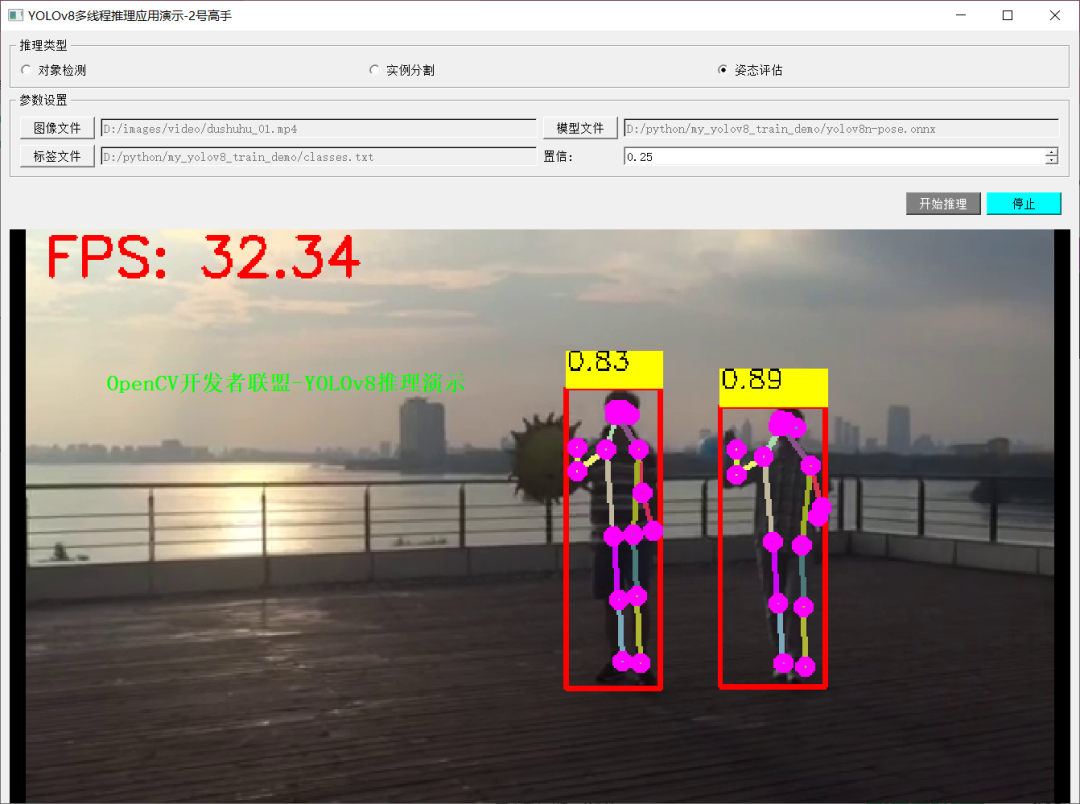
应用程序演示
最终调用应用程序代码,实现启动与运行的界面如下:
#初始化APP实例
importplatform
app=QtWidgets.QApplication(sys.argv)
if'Windows'==platform.system():
app.setStyle('Windows')
#初始化桌面容器
main_win=QtWidgets.QMainWindow()
#设置APP窗口名称
main_win.setWindowTitle("YOLOv8多线程推理应用演示-2号高手")
#初始化内容面板
content_panel=YOLOv8InferPanel()
#设置窗口大小
main_win.setMinimumSize(1340,960)
main_win.setCentralWidget(content_panel)
#请求显示
main_win.show()
#加载窗口并启动App
app.exec()
审核编辑:彭静
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
软件
+关注
关注
69文章
5395浏览量
92112 -
人工智能
+关注
关注
1821文章
50547浏览量
267933 -
pyqt5
+关注
关注
0文章
25浏览量
3655
原文标题:多线程界面化、ONNXRUNTIME + YOLOv8推理演示
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
基于YOLOv8实现自定义姿态评估模型训练
Hello大家好,今天给大家分享一下如何基于YOLOv8姿态评估模型,实现在自定义数据集上,完成自定义姿态评估模型的训练与推理。

TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示
对YOLOv8实例分割TensorRT 推理代码已经完成C++类封装,三行代码即可实现YOLOv8对象检测与实例分割模型推理,不需要改任何代
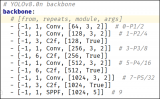
YOLOv8版本升级支持小目标检测与高分辨率图像输入
YOLOv8版本最近版本又更新了,除了支持姿态评估以外,通过模型结构的修改还支持了小目标检测与高分辨率图像检测。原始的YOLOv8模型结构如下。
教你如何用两行代码搞定YOLOv8各种模型推理
大家好,YOLOv8 框架本身提供的API函数是可以两行代码实现 YOLOv8 模型推理,这次我把这段代码封装成了一个类,只有40行代码左右,可以同时

目标检测算法再升级!YOLOv8保姆级教程一键体验
YOLO作为一种基于图像全局信息进行预测的目标检测系统,始终保持着极高的迭代更新率,从YOLOv5到YOLOv8,本次升级主要包括结构算法、命令行界面、PythonAPI等。具体到YOLOv8
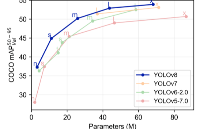
三种主流模型部署框架YOLOv8推理演示
深度学习模型部署有OpenVINO、ONNXRUNTIME、TensorRT三个主流框架,均支持Python与C++的SDK使用。对YOLOv5~YOLOv8的系列模型,均可以通过C++推理
OpenCV4.8+YOLOv8对象检测C++推理演示
自从YOLOv5更新成7.0版本,YOLOv8推出以后,OpenCV4.6以前的版本都无法再加载导出ONNX格式模型了,只有OpenCV4.7以上版本才可以支持最新版本YOLOv5与
基于YOLOv8的自定义医学图像分割
YOLOv8是一种令人惊叹的分割模型;它易于训练、测试和部署。在本教程中,我们将学习如何在自定义数据集上使用YOLOv8。但在此之前,我想告诉你为什么在存在其他优秀的分割模型时应该使用YOLOv8呢?

YOLOv8实现旋转对象检测
YOLOv8框架在在支持分类、对象检测、实例分割、姿态评估的基础上更近一步,现已经支持旋转对象检测(OBB),基于DOTA数据集,支持航拍图像的15个类别对象检测,包括车辆、船只、典型
基于OpenCV DNN实现YOLOv8的模型部署与推理演示
基于OpenCV DNN实现YOLOv8推理的好处就是一套代码就可以部署在Windows10系统、乌班图系统、Jetson的Jetpack系统
RV1126 yolov8训练部署教程
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的基于YOLOV5进行更新的 下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,鉴于Yolov
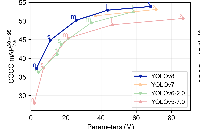
使用ROCm™优化并部署YOLOv8模型
作者:AVNET 李鑫杰 一,YOLOv8介绍? YOLOv8 由 Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面提供了前沿的性能。YOLOv8 在之前 YOLO



评论