 介绍一种KV存储的GC优化实践
介绍一种KV存储的GC优化实践

从内部需求出发,我们基于TiKV设计了一款兼容Redis的KV存储。基于TiKV的数据存储机制,对于窗口数据的处理以及过期数据的GC问题却成为一个难题。本文希望基于从KV存储的设计开始讲解,到GC设计的逐层优化的过程,从问题的存在到不同层面的分析,可以给读者在类似的优化实践中提供一种参考思路。
一、背景介绍
当前公司内部没有统一的KV存储服务,很多业务都将 Redis 集群当作KV存储服务在使用,但是部分业务可能不需要 Redis 如此高的性能,却承担着巨大的机器资源成本(内存价格相对磁盘来说更加昂贵)。为了降低存储成本的需求,同时尽可能减少业务迁移的成本,我们基于 TiKV 研发了一套磁盘KV存储服务。
1.1 架构简介
以下对这种KV存储(下称磁盘KV)的架构进行简单描述,为后续问题描述做铺垫。
1.1.1 系统架构
磁盘KV使用目前较流行的计算存储分离架构,在TiKV集群上层封装计算层(后称Tula)模拟Redis集群(对外表现是不同的Tula负责某些slot范围),直接接入业务Redis客户端。
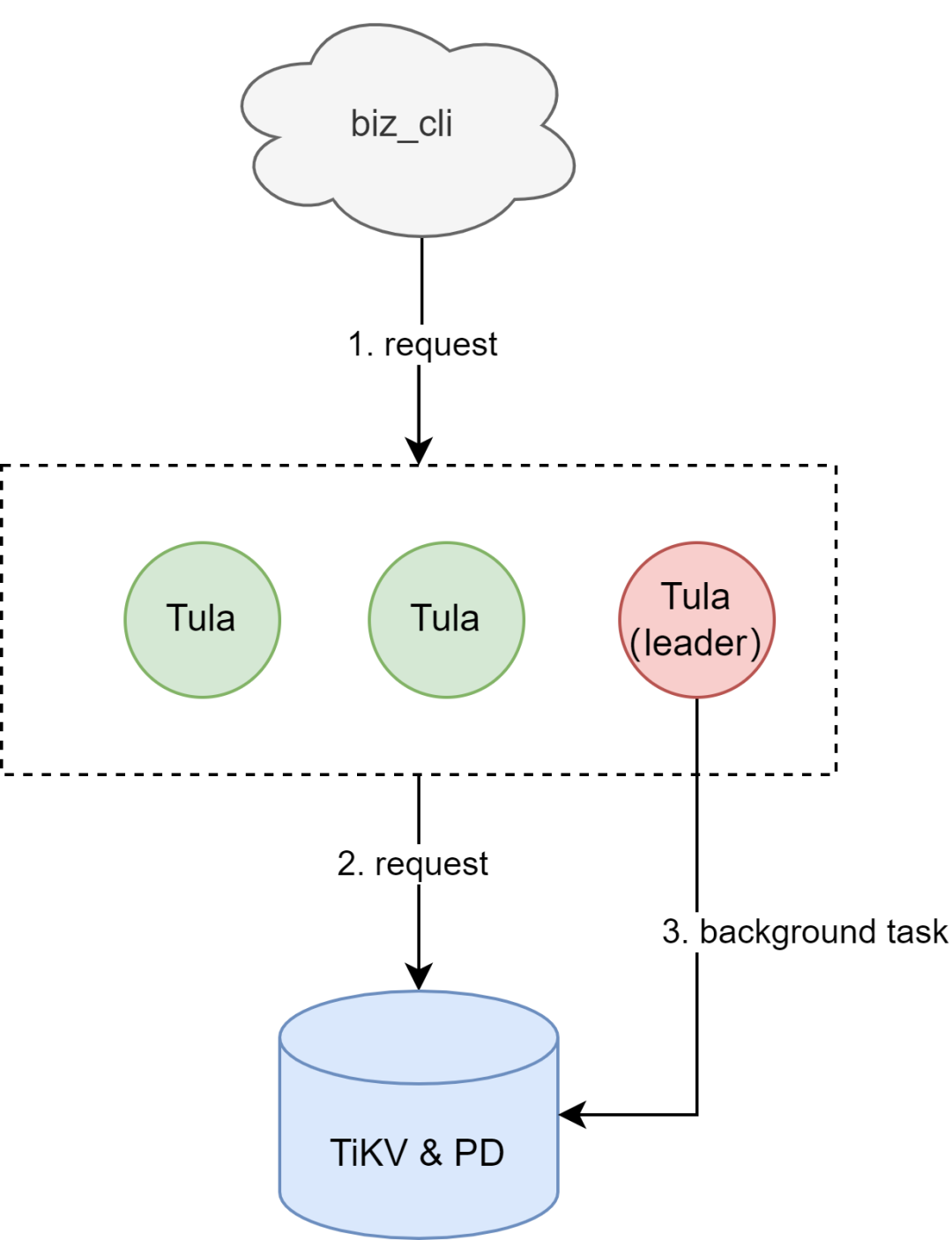
图1:磁盘KV架构图示
业务写入数据基于Tula转换成TiKV中存储的KV对,基于类似的方式完成业务数据的读取。
注意:Tula中会选举出一个leader,用于进行一些后台任务,后续详细说。
1.1.2 数据编码
TiKV对外提供的是一种KV的读写功能,但是Redis对外提供的是基于数据结构提供读写能力(例如SET,LIST等),因此需要基于TiKV现有提供的能力,将Redis的数据结构进行编码,并且可以方便地在TiKV中进行读写。
TiKV提供的API比较简单:基于key的读写接口,以及基于字典序的迭代器访问。
因此,Tula层面基于字典序的机制,对Redis的数据结构基于字典序进行编码,便于访问。
注意:TiKV的key是可以基于字典序进行遍历(例如基于某个前缀进行遍历等),后续的编码,机制基本是基于字典序的特性进行设计。
为了可以更好地基于字典序排列的搜索特性下对数据进行读写,对于复杂的数据结构,我们会使用另外的空间去存放其中的数据(例如SET中的member,HASH中的field)。而对于简单的数据结构(类似STRING),则可以直接存放到key对应的value中。
为此,我们在编码设计上,会分为metaKey和dataKey。metaKey是基于用户直接访问的key进行编码,是编码设计中直接对外的一层;dataKey则是metaKey的存储指向,用来存放复杂数据结构中的具体内部数据。
另外,为了保证访问的数据一致性,我们基于TiKV的事务接口进行对key的访问。
(1)编码&字段
以下以编码中的一些概念以及设定,对编码进行简述。
key的编码规则如下:
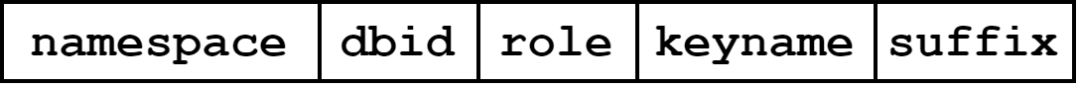
图2:key编码设计图示
以下对字段进行说明
namespace
为了方便在一个TiKV集群中可以存放不同的磁盘KV数据,我们在编码的时候添加了前缀namespace,方便集群基于这个namespace在同一个物理TiKV空间中基于逻辑空间进行分区。
dbid
因为原生Redis是支持select语句,因此在编码上需要预留字段表示db的id,方便后续进行db切换(select语句操作)的时候切换,表示不同的db空间。
role
用于区分是哪种类型的key。
对于简单的数据结构(例如STRING),只需要直接在key下面存储对应的value即可。
但是对于一些复杂的数据结构(例如HASH,LIST等),如果在一个value下把所有的元素都存储了,对与类似SADD等指令的并发,为了保证数据一致性,必然可以预见其性能不足。
因此,磁盘KV在设计的时候把元素数据按照独立的key做存储,需要基于一定的规则对元素key进行访问。这样会导致在key的编码上,会存在key的role字段,区分是用户看到的key(metaKey),还是这种元素的key(dataKey)。
其中,如果是metaKey,role固定是M;如果是dataKey,则是D。
keyname
在metaKey和dataKey的基础上,可以基于keyname字段可以较方便地访问到对应的key。
suffix
针对dataKey,基于不同的Redis数据结构,都需要不同的dataKey规则进行支持。因此此处需要预留suffix区间给dataKey在编码的时候预留空间,实现不同的数据类型。
以下基于SET类型的SADD指令,对编码进行简单演示:
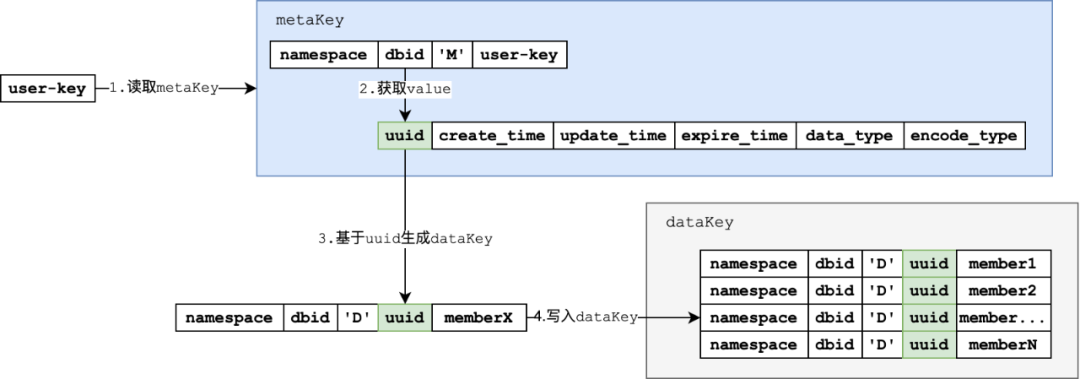
图3: SADD指令的编码设计指令图示
基于userKey,通过metaKey的拼接方式,拼接metaKey并且访问
访问metaKey获取value中的
基于value中的uuid,生成需要的dataKey
写入生成的dataKey
(2)编码实战
编码实战中,会以SET类型的实现细节作为例子,描述磁盘KV在实战中的编码细节。
在这之前,需要对metaKey的部分实现细节进行了解
(3)metaKey存储细节
所有的metaKey中都会存储下列数据。

图4:metaKey编码设计图示
uuid:每一个metaKey都会有一个对应的uuid,表示这个key的唯一身份。
create_time:保存该元数据的创建时间
update_time:保存该元数据的最近更新时间
expire_time:保存过期时间
data_type:保存该元数据对应的数据类型,例如SET,HASH,LIST,ZSET等等。
encode_type:保存该数据类型的编码方式
(4)SET实现细节
基于metaKey的存储内容,以下基于SET类型的数据结构进行讲解。
SET类型的dataKey的编码规则如下:
keyname:metaKey的uuid
suffix:SET对应的member字段
因此,SET的dataKey编码如下:

图5:SET数据结构dataKey编码设计图示
以下把用户可以访问到的key称为user-key。集合中的元素使用member1,member2等标注。
这里,可以梳理出访问逻辑如下:
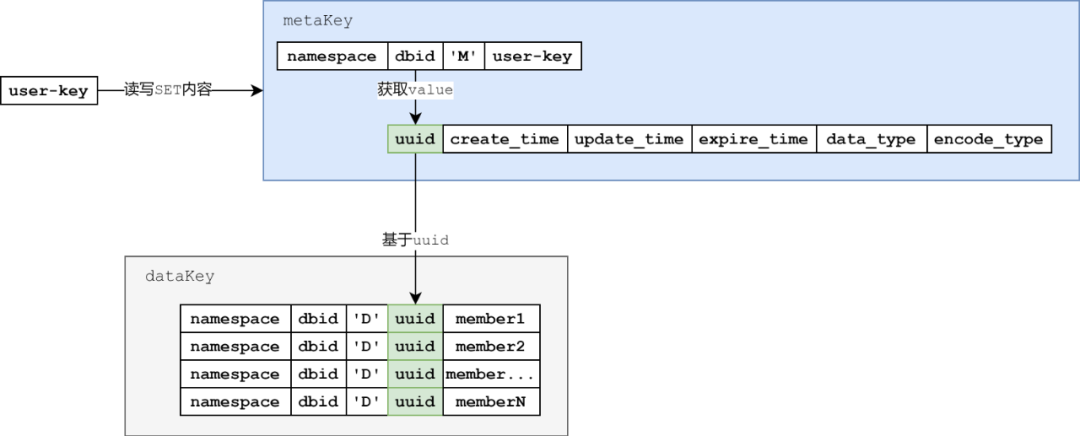
图6:SET数据结构访问流程图示
简述上图的访问逻辑:
基于user-key拼接出metaKey,读取metaKey的value中的uuid。
基于uuid拼接出dataKey,基于TiKV的字典序遍历机制获取uuid下的所有member。
1.1.3 过期&GC设计
对标Redis,目前在user-key层面满足过期的需求。
因为存在过期的数据,Redis基于过期的hash进行保存。但是如果磁盘KV在一个namespace下使用一个value存放过期的数据,显然在EXPIRE等指令下存在性能问题。因此,这里会有独立的编码支持过期机制。
鉴于过期的数据可能无法及时删除(例如SET中的元素),对于这类型的数据需要一种GC的机制,把数据完全清空。
(1)编码设计
针对过期以及GC(后续会在机制中详细说),需要额外的编码机制,方便过期和GC机制的查找,处理。
过期编码设计
为了可以方便地找到过期的key(下称expireKey),基于字典序机制,优先把过期时间的位置排到前面,方便可以更快地得到expireKey。
编码格式如下:
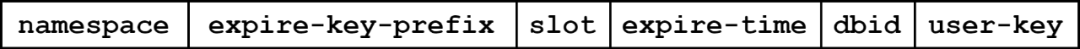
图7:expireKey编码设计图示
其中:
expire-key-prefix:标识该key为expireKey,使用固定的字符串标识
slot:4个字节,标识slot值,对user-key进行hash之后对256取模得到,方便并发扫描的时候线程可以分区扫描,减少同key的事务冲突
expire-time:标识数据的过期时间
user-key:方便在遍历过程中找到user-key,对expireKey做下一步操作
GC编码设计
目前除了STRING类型,其他的类型因为如果在一次过期操作中把所有的元素都删除,可能会存在问题:如果一个user-key下面的元素较多,过期进度较慢,这样metaKey可能会长期存在,占用空间更大。
因此使用一个GC的key(下称gcKey)空间,安排其他线程进行扫描和清空。
编码格式如下:
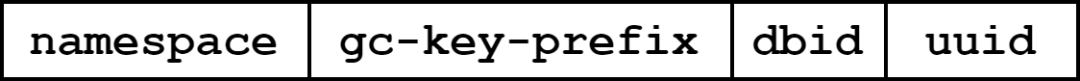
图8:gcKey编码设计图示
(2)机制描述
基于前面的编码,可以对Tula内部的过期和GC机制进行简述。
因为过期和GC都是基于事务接口,为了减少冲突,Tula的leader会进行一些后台的任务进行过期和GC。
过期机制
因为前期已经对过期的user-key进行了slot分开,expireKey天然可以基于并发的线程进行处理,提高效率。

图9:过期机制处理流程图示
简述上图的过期机制:
拉起各个过期作业协程,不同的协程基于分配的slot,拼接协程下的expire-key-prefix,扫描expireKey
扫描expireKey,解析得到user-key
基于user-key拼接得到metaKey,访问metaKey的value,得到uuid
根据uuid,添加gcKey
添加gcKey成功后,删除metaKey
就目前来说,过期速度较快,而且key的量级也不至于让磁盘KV存在容量等过大负担,基于hash的过期机制目前表现良好。
GC机制
目前的GC机制比较落后:基于当前Tula的namespace的GC前缀(gc-key-prefix),基于uuid进行遍历,并且删除对应的dataKey。
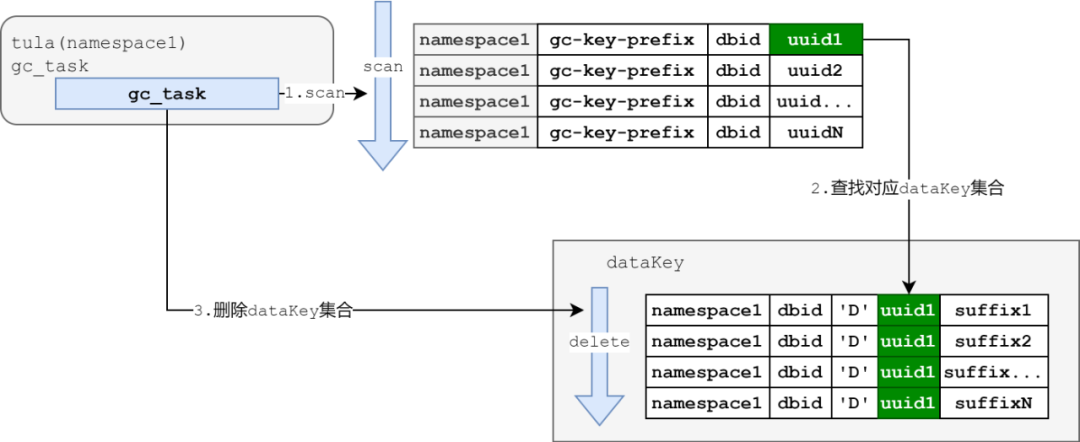
图10:GC机制处理流程图示
简述上图的GC机制:
拉起一个GC的协程,扫描gcKey空间
解析扫描到的gcKey,可以获得需要GC的uuid
基于uuid,在dataKey的空间中基于字典序,删除对应uuid下的所有dataKey
因此,GC本来就是在expire之后,会存在一定的滞后性。
并且,当前的GC任务只能单线程操作,目前来说很容易造成GC的迟滞。
1.2 问题描述
1.2.1 问题现象
业务侧多次反馈,表示窗口数据(定期刷入重复过期数据)存在的时候,磁盘KV占用的空间特别大。
我们使用工具单独扫描对应的Tula配置namespace下的GC数据结合,发现确实存在较多的GC数据,包括gcKey,以及对应的dataKey也需要及时进行删除。
1.2.2成因分析
现网的GC过程速度比不上过期的速度。往往expireKey都已经没了,但是gcKey很多,并且堆积。
这里的问题点在于:前期的设计中,gcKey的编码并没有像expireKey那样提前进行了hash的操作,全部都是uuid。
如果有一个类似的slot字段可以让GC可以使用多个协程进行并发访问,可以更加高效地推进GC的进度,从而达到满足优化GC速度的目的,窗口数据的场景可以得到较好的处理。
下面结合两个机制的优劣,分析存在GC堆积的原因。
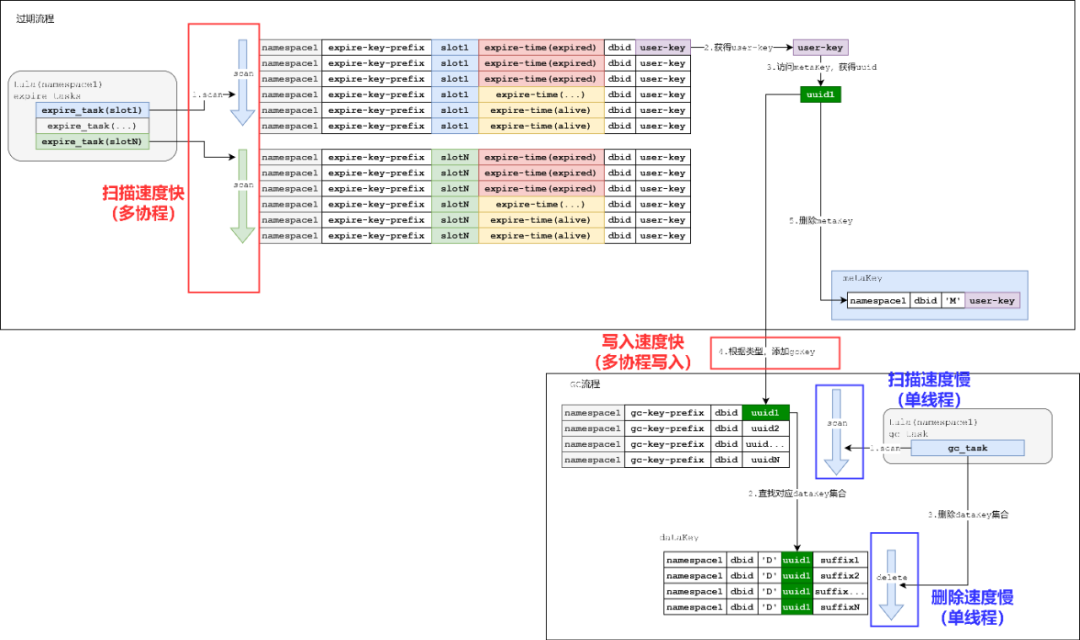
图11:GC堆积成因图示
简单来说,上图的流程中:
过期的扫描速度以及处理速度很快,expireKey很快及时的被清理并且添加到gcKey中
GC速度很慢,添加的gcKey无法及时处理和清空
从上图分析可以知道:如果窗口数据的写入完全超过的GC的速度的话,必然导致GC的数据不断堆积,最后导致所有磁盘KV的存储容量不断上涨。
二、优化
2.1 目标
分析了原始的GC机制之后,对于GC存在滞后的情况,必然需要进行优化。
如何加速GC成为磁盘KV针对窗口数据场景下的强需求。
但是,毕竟TiKV集群的性能是有上限的,在进行GC的过程也应该照顾好业务请求的表现。
这里就有了优化的基本目标:在不影响业务的正常使用前提下,对尽量减少GC数据堆积,加速GC流程。
2.2.实践
2.2.1 阶段1
在第一阶段,其实并没有想到需要对GC这个流程进行较大的变动,看可不可以从当前的GC流程中进行一些简单调整,提升GC的性能。
分析
GC的流程相对简单:
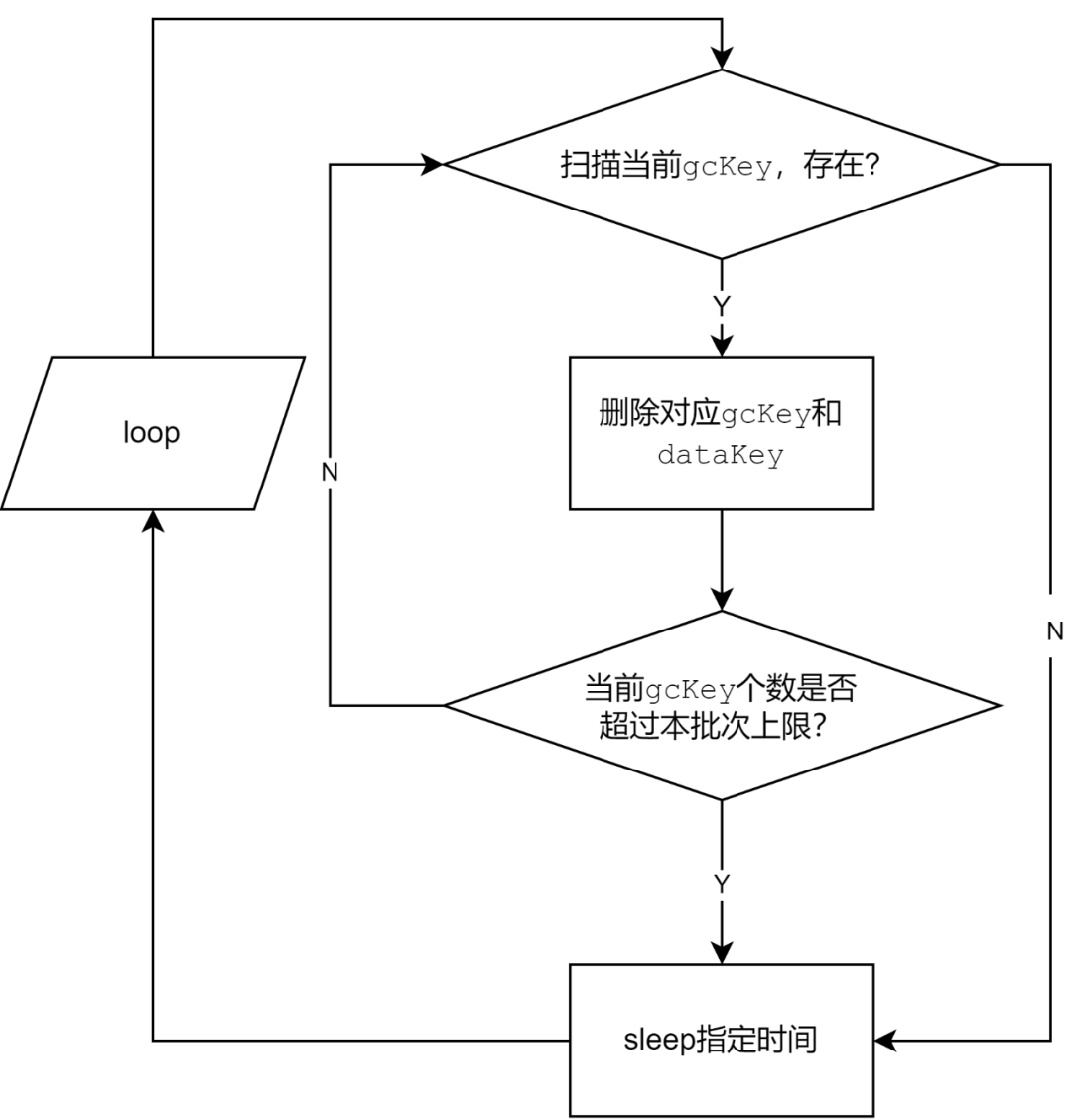
图12:GC流程图示
可以看到,如果存在gcKey,会触发一个批次的删除gcKey和dataKey的流程。
最初设计存在sleep以及批次的原因在于减少GC对TiKV的影响,降低对现网的影响。
因此这里可以调整的范围比较有限:按照批次进行控制,或者缩短批次删除之间的时间间隔。
尝试
缩短sleep时间(甚至缩短到0,去掉sleep过程),或者提高单个批次上限。
结果
但是这里原生sleep时间并不长,而且就算提高批次个数,毕竟单线程,提高并没有太大。
小结
原生GC流程可变动的范围比较有限,必须打破这种局限才可以对GC的速度得以更好的优化。
2.2.2 阶段2
第一阶段过后,发现原有机制确实局限比较大,如果需要真的把GC进行加速,最好的办法是在原有的机制上看有没有办法类似expireKey一样给出并发的思路,可以和过期一样在质上提速。
但是当前现网已经不少集群在使用磁盘KV集群,并发提速必须和现网存量key设计一致前提下进行调整,解决现网存量的GC问题。
分析
如果有一种可能,更改GC的key编码规则,类似模拟过期key的机制,添加slot位置,应该可以原生满足这种多协程并发进行GC的情况。
但是基于当前编码方式,有没有其他办法可以较好地把GC key分散开来?
把上述问题作为阶段2的分析切入点,再对当前的GC key进行分析:
图13:gcKey编码设计图示
考虑其中的各个字段:
namespace:同一个磁盘KV下GC空间的必然一致
gc-key-prefix:不管哪个磁盘KV的字段必然一致
dbid:现网的磁盘KV都是基于集群模式,dbid都是0
uuid:映射到对应的dataKey
分析下来,也只有uuid在整个gcKey的编码中是变化的。
正因为uuid的分布应该是足够的离散,此处提出一种比较大胆的想法:基于uuid的前若干位当作hash slot,多个协程可以基于不同的前缀进行并发访问。
因为uuid是一个128bit长度(8个byte)的内容,如果拿出前面的8个bit(1个byte),可以映射到对应的256个slot。
尝试
基于上述分析,uuid的前一个byte作为hash slot的标记,这样,GC流程变成:
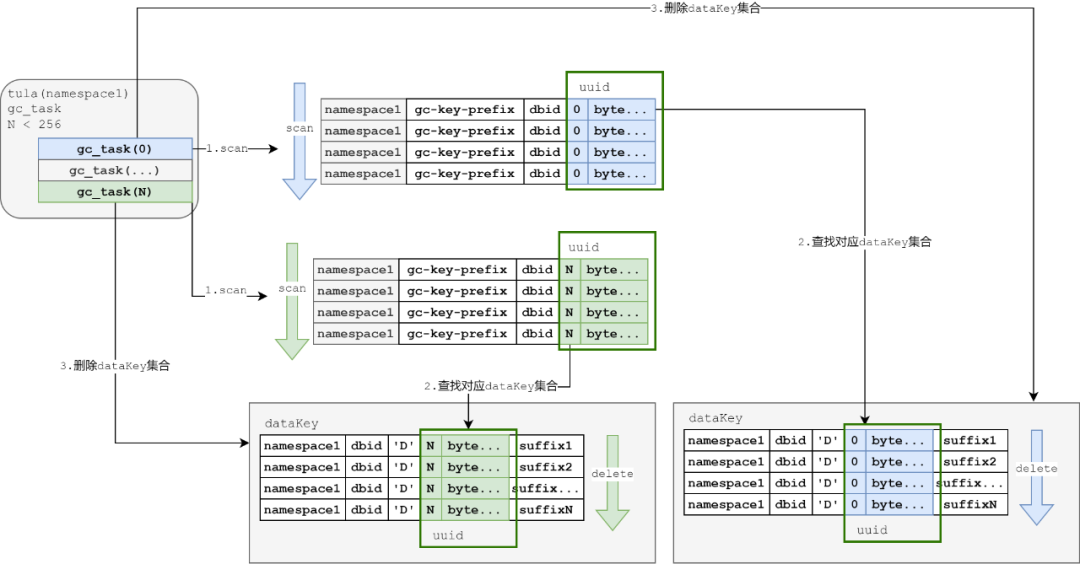
图14:基于uuid划分GC机制图示
简单描述下阶段2的GC流程:
GC任务使用协程,分成256个任务
每一个任务基于前缀扫描的时候,从之前扫描到dbid改成后续补充一个byte,每个协程被分配不同的前缀,进行各自的任务执行
GC任务执行逻辑和之前单线程逻辑保持不变,处理gcKey以及dataKey。
这样,基于uuid的离散,GC的任务可以拆散成并发协程进行处理。
这样的优点不容置疑,可以较好地进行并发处理,提高GC的速度。
结果
基于并发的操作,GC的耗时可以缩短超过一半。后续会有同样条件下的数据对比。
小结
阶段2确实带来一些突破:再保留原有gcKey设计的前提下,基于拆解uuid的方法使得GC的速度有质的提高。
但是这样会带来问题:对于dataKey较多(可以理解为一个HASH,或者一个SET的元素较多)的时候,删除操作可能对TiKV的性能带来影响。这样带来的副作用是:如果并发强度很高地进行GC,因为TiKV集群写入(无论写入还是删除)性能是一定的,这样是不是可能导致业务的正常写入可能带来了影响?
如何可以做到兼顾磁盘KV日常的写入和GC?这成了下一个要考虑的问题。
2.2.3 阶段3
阶段2之后,GC的速度是得到了较大的提升,但是在测试过程中发现,如果在过程中进行写入,写入的性能会大幅度下降。如果因为GC的性能问题忽视了现网的业务正常写入,显然不符合线上业务的诉求。
磁盘KV的GC还需要一种能力,可以调节GC。
分析
如果基于阶段2,有办法可以在业务低峰期的时候进行更多的GC,高峰期的时候进行让路,也许会是个比较好的方法。
基于上面的想法,我们需要在Tula层面可以比较直接地知道当前磁盘KV的性能表现到底到怎样的层面,当前是负荷较低还是较高,应该用怎样的指标去衡量当前磁盘KV的性能?
尝试
此处我们进行过以下的一些摸索:
基于TiKV的磁盘负载进行调整
基于Tula的时延表现进行调整
基于TiKV的接口性能表现进行调整
暂时发现TiKV的接口性能表现调整效果较好,因为基于磁盘负载不能显式反馈到Tula的时延表现,基于Tula的时延表现应该需要搜集所有的Tula时延进行调整(对于同一个TiKV集群接入多个不同的Tula集群有潜在影响),基于TiKV的接口性能表现调整可以比较客观地得到Tula的性能表现反馈。
在阶段1中,有两个影响GC性能的参数:
sleep时延
单次处理批次个数
加上阶段2并发的话,会有三个可控维度,控制GC的速度。
调整后的GC流程如下:

图15:自适应GC机制图示
阶段3对GC添加自适应机制,简述如下:
①开启协程,搜集TiKV节点负载
发现TiKV负载较高,控制GC参数,使得GC缓慢进行
发现TiKV负载较低,控制GC参数,使得GC激进进行
②开启协程,进行GC
发现不需要GC,控制GC参数,使得GC缓慢进行
结果
基于监控表现,可以明显看到,GC不会一直强制占据TiKV的所有性能。当Tula存在正常写入的时候,GC的参数会响应调整,保证现网写入的时延。
小结
阶段3之后,可以保证写入和但是从TiKV的监控上看,有时候GC并没有完全把TiKV的性能打满。
是否有更加高效的GC机制,可以继续提高磁盘KV的GC性能?
2.2.4 阶段4
基于阶段3继续尝试找到GC性能更高的GC方式。
分析
基于阶段3的优化,目前基于单个节点的Tula应该可以达到一个可以较高强度的GC,并且可以给现网让路的一种情况。
但是,实际测试的时候发现,基于单个节点的删除,速度应该还有提升空间(从TiKV的磁盘IO可以发现,并没有占满)。
这里的影响因素很多,例如我们发现client-go侧存在获取tso慢的一些报错。可能是使用客户端不当等原因造成。
但是之前都是基于单个Tula节点进行处理。既然每个Tula都是模拟了Redis的集群模式,被分配了slot区间去处理请求。这里是不是可以借鉴分片管理数据的模式,在GC的过程直接让每个Tula管理对应分片的GC数据?
这里先review一次优化阶段2的解决方式:基于uuid的第一个byte,划分成256个区间。leader Tula进行处理的时候基于256个区间。
反观一个Tula模拟的分片范围是16384(0-16383),而一个byte可以表示256(0-255)的范围。
如果使用2个byte,可以得到65536(0-65535)的范围。
这样,如果一个Tula可以基于自己的分片范围,映射到GC的范围,基于Tula的Redis集群模拟分片分布去做基于Tula节点的GC分片是可行的。
假如某个Tula的分片是从startSlot到endSlot(范围:0-16383),只要经过简单的映射:
startHash = startSlot* 4
endHash = (endSlot + 1)* 4 - 1
基于这样的映射,可以直接把Tula的GC进行分配,而且基本在优化阶段2中无缝衔接。
尝试
基于分析得出的机制如下:
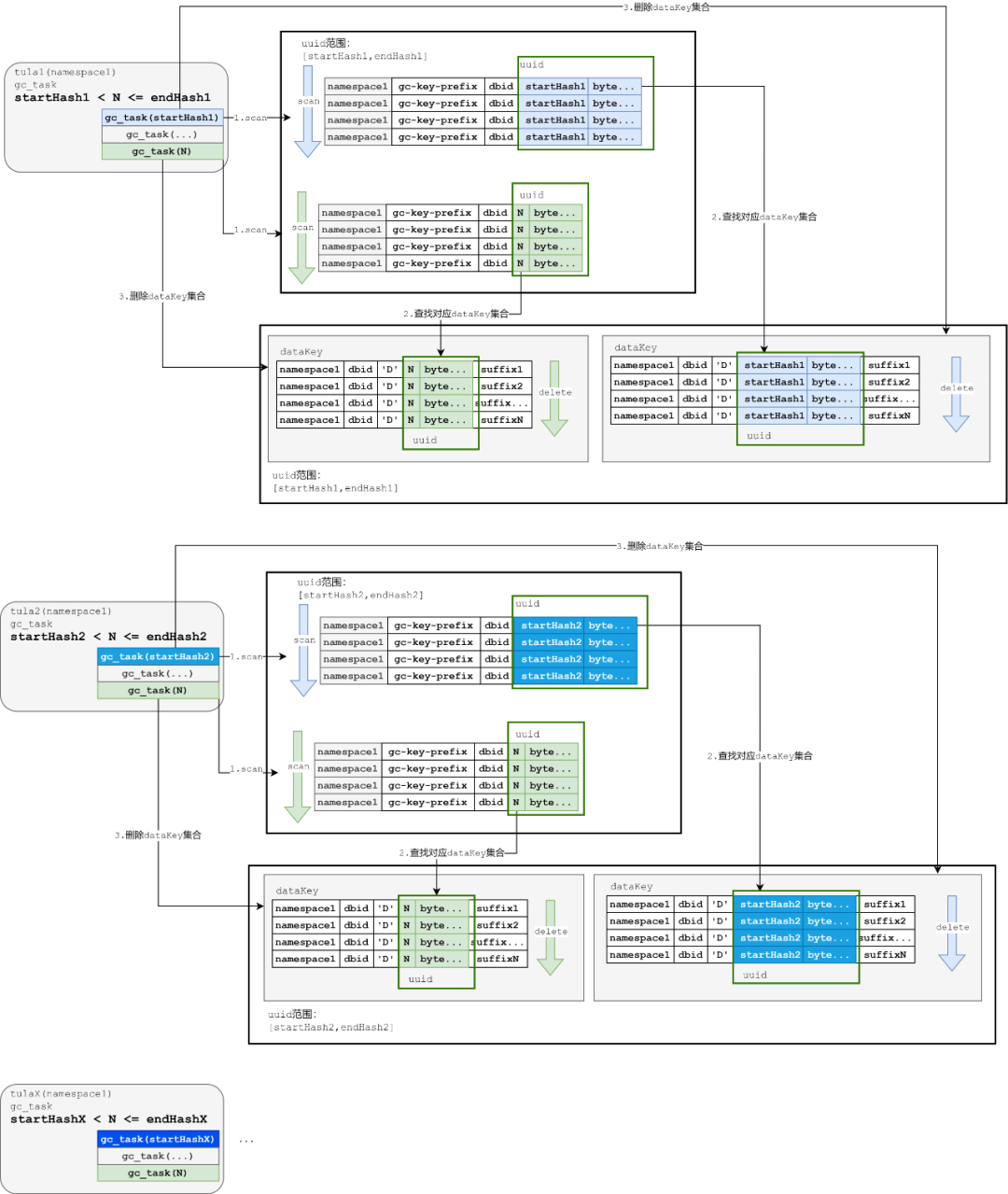
图16:多Tula节点GC机制图示
可以简单地描述优化之后的GC流程:
① 基于当前拓扑划分当前Tula节点的startHash与endHash
② 基于步骤1的startHash与endHash,Tula分配协程进行GC,和阶段2基本一致:
GC任务使用协程,分成多个任务。
每一个任务基于前缀扫描的时候,从之前扫描到dbid改成后续补充2个byte,每个协程被分配不同的前缀,进行各自的任务执行。
GC任务执行逻辑和之前单线程逻辑保持不变,处理gcKey以及dataKey。
基于节点分开之后,可以满足在每个节点并发地前提下,各个节点不相干地进行GC。
结果
基于并发的操作,GC的耗时可以在阶段2的基础上继续缩短。后续会有同样条件下的数据对比。
小结
基于节点进行并发,可以更加提高GC的效率。
但是我们在这个过程中也发现,client-go的使用上可能存在不当的情况,也许调整client-go的使用后可以获得更高的GC性能。
三、优化结果对比
我们基于一个写入500W的SET作为写入数据。其中每一个SET都有一个元素,元素大小是4K。
因为阶段2和阶段4的提升较大,性能基于这两个进行对比:
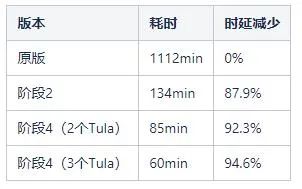
表1:各阶段GC耗时对照表
可以比较明显地看出:
阶段2之后的GC时延明显缩减
阶段4之后的GC时延可以随着节点数的增长存在部分缩减
四、后续计划
阶段4之后,我们发现Tula的单节点性能应该有提升空间。我们会从以下方面进行入手:
补充更多的监控项目,让Tula更加可视,观察client-go的使用情况。
基于上述调整跟进client-go在不同场景下的使用情况,尝试找出client-go在使用上的瓶颈。
尝试调整client-go的使用方式,在Tula层面提高从指令执行,到GC,过期的性能。
五、总结
回顾我们从原来的单线程GC,到基于编码机制做到了多线程GC,到为了减少现网写入性能影响,做到了自适应GC,再到为了提升GC性能,进行多节点GC。
GC的性能提升阶段依次经历了以下过程:
单进程单协程
单进程多协程
多进程多协程
突破点主要在于进入阶段2(单进程多协程)阶段,设计上的困难主要来源于:已经存在存量数据,我们需要兼顾存量数据的数据分布情况进行设计,这里我们必须在考虑存量的gcKey存在的前提下,原版gcKey的编码设计与基于字典序的遍历机制对改造造成的约束。
但是这里基于原有的设计,还是有空间进行一些二次设计,把原有的问题进行调优。
这个过程中,我们认为有几点比较关键:
在第一次设计的时候,应该从多方面进行衡量,思考好某种设计会带来的副作用。
在上线之前,对各种场景(例如不同的指令,数据大小)进行充分测试,提前发现出问题及时修正方案。
已经是存量数据的前提下,更应该对原有的设计进行重新梳理。也许原有的设计是有问题的,遵循当前设计的约束,找出问题关键点,基于现有的设计尝试找到空间去调整,也许存在调优的空间。
审核编辑:刘清
-
SET
+关注
关注
0文章
17浏览量
8439 -
Redis
+关注
关注
0文章
396浏览量
12281 -
迭代器
+关注
关注
0文章
45浏览量
4645
原文标题:一种KV存储的GC优化实践
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
[VirtualLab] 光纤耦合优化
忆联自研芯片以压缩技术重塑KV Cache存储效率

当大型机械学会“感知”高压:一种近电预警的技术实践

【「Altium Designer 25 电路设计精进实践」阅读体验】+本书概览与内容特点介绍
电能质量在线监测装置的暂态波形存储时长可以通过哪些方式进行优化?
CI/CD实践中的运维优化技巧
PPEC电源DIY套件:图形化算法编程,解锁电力电子底层算法实践
一种无序超均匀固体器件的网格优化方法

一种环保型红色发烟弹主装药配方设计与优化

全新升级!格科新一代2MP CIS GC20C3,低功耗、高感光赋能智慧城市

宽调速范围低转矩脉动的一种新型内置式永磁同步电机的设计与分析
多个i.MXRT共享一颗Flash启动的方法与实践(下)




评论