 大模型AI兴起:新一轮芯片、服务器、智算等浪潮来袭
大模型AI兴起:新一轮芯片、服务器、智算等浪潮来袭

AI需要多元异构算力提供支持,拉动AI芯片需求。人工智能算法需要从海量的图像、语音、视频等非结构化数据中挖掘信息。从大模型的训练、场景化的微调以及推理应用场景,都需要算力支撑。而以CPU为主的通用计算能力已经无法满足多场景的AI需求。以CPU+AI芯片(GPU、FPGA、ASIC)提供的异构算力,并行计算能力优越、具有高互联带宽,可以支持AI计算效力实现最大化,成为智能计算的主流解决方案。
服务器中的CPU和AI卡的数量并不固定,会根据客户应用需求调整,对于AI服务器来讲,较为常见的是配备2个CPU,以及八个AI卡。而相比于AI服务器,传统的通用服务器则以CPU为主。因此,AI的发展将极大拉动GPGPU、TPU、NPU等AI芯片的需求。
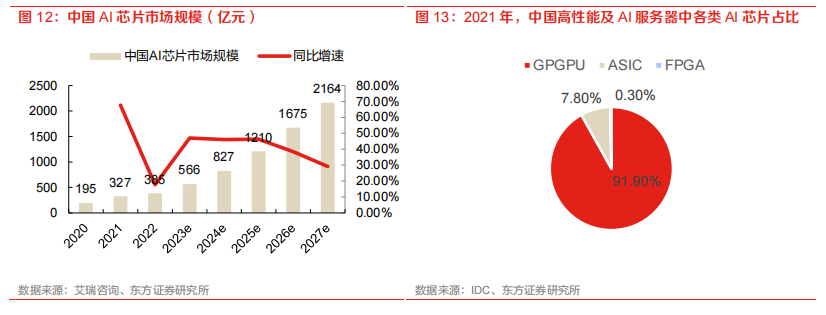
AI 计算需要多元异构算力提供支持,将极大拉动GPGPU、AISC 等 AI 芯片的需求。中国 AI 芯片市场规模有望快速增长,据艾瑞咨询发布的《2022 年中国人工智能产业研究报告(Ⅴ)》,预计 2027 年达到 2164 亿元。
中国AI芯片市场将保持高速增长,AI推理芯片份额有望持续提升,国产化AI芯片占比有望提升。2022年,中国的AI芯片市场规模约385亿元。随着AI发展以及智算中心建设浪潮,该市场预计将保持高增长趋势。据艾瑞咨询测算,到2027年,中国的AI芯片市场规模预计将达到2164亿元。另外,在我国高性能及AI服务器中,GPGPU凭借其优秀的性能和通用能力占比92%,剩下份额由AISC和FPGA分享。随着AI模型的优化落地,AI推理芯片的占比将日益提升。据艾瑞咨询,2022年,中国AI训练芯片以及AI推理芯片的占比分别为47.2%和52.8%。
AI芯片领域的三类玩家。大模型的训练需要大规模的训练数据以及强大的计算资源,需要多卡多机协同完成。这对AI芯片本身的性能,以及多卡多机的互联提出了很高的要求。目前,在AI芯片领域,有三类玩家。一种是以Nvidia、AMD为代表的实力强劲的老牌芯片巨头,这些企业积累了丰富的经验,产品性能突出。
另一种是以Google、百度、华为为代表的云计算巨头,这些企业纷纷布局通用大模型,并自己开发了AI芯片、深度学习平台等支持大模型发展。如google的TensorFlow以及TPU,华为的鲲鹏昇腾、CANN及Mindspore。
最后是一些小而美的AI芯片独角兽,如寒武纪、壁仞等。
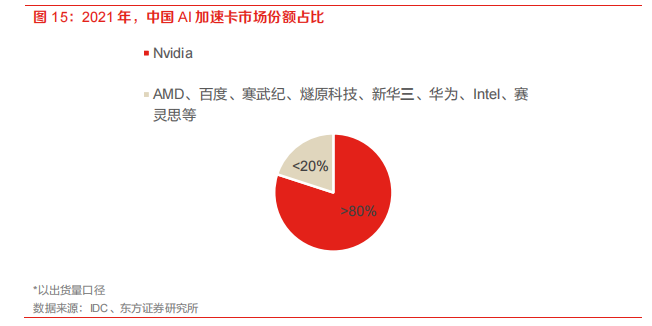
英伟达占据80%以上中国加速卡市场份额,国产AI芯片亟待发展。根据IDC的数据显示,2021年中国加速卡的出货数量已经超过80万片,其中Nvidia占据了超过80%的市场份额。剩下的份额有AMD、百度、寒武纪、燧原科技、新华三、华为、Intel和赛灵思等品牌。
1、英伟达:全球GPU龙头
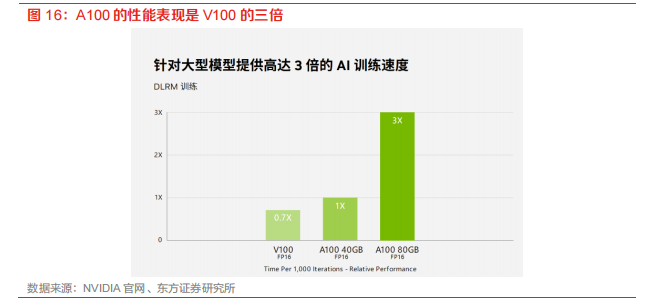
英伟达占据芯片市场绝对优势。长期以来,英伟达在高端GPU市场占据绝对主导地位,现如今已量产的主流A100芯片相比前代产品V100,性能得到显著提高,代表当今高端芯片水平。最新一代H100芯片也已经亮相,即将量产。天数智芯数据显示,2021年英伟达在中国云端AI训练芯片市场的份额达到90%。据IDC,在2021年中国出货的80多万张加速卡中,英伟达占据超过80%份额。芯片的研发周期较长,英伟达具有绝对先行优势,虽然目前国内企业突破英伟达垄断仍然任重道远,但寒武纪、华为AI芯片快速发展,有望逐步进行国产替代。
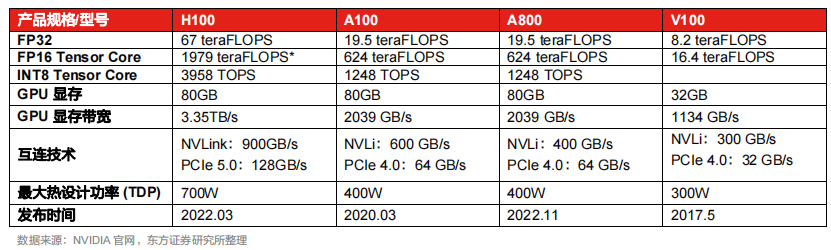
受制裁影响,英伟达对部分产品性能进行 “阉割”,推出“中国版芯片”A800、H800。2022年10月,美国发布了针对中国的先进计算与半导体产品的出口管制,限制美国企业向中国出口先进高端芯片设备。在新管制的限制下,英伟达的A100、H100被禁止售卖给中国,而采用12nm工艺、性能较低的V100 GPU芯片不在管控之列。针对此次制裁,英伟达对A100的部分性能进行“阉割”,推出A800。
相比于A100,A800在单卡计算性能上没有差别,但是互联带宽从600GB/s下降到了400GB/s,在一定程度上影响了如大模型训练等多卡互联场景的性能。目前,A800已实现量产,并在中国规模化落地应用。英伟达还推出了旗舰芯片H100的替代版H800,目前还未量产。
2、海光信息:国产高性能CPU和GPGPU领军企业
海光信息专注于研发、设计和销售高端处理器(CPU以及GPGPU),持续技术创新、产品迭代。海光信息的主要产品为应用于服务器和工作站等设备中的通用处理器(CPU)和协处理器(DCU,即GPGPU)。海光处理器性能出众,同时软硬件生态丰富、工具链完整、应用迁移成本低。另外,海光CPU与DCU虽脱胎于AMD,但经过多年独立自主研发迭代,已经实现自主可控、安全可靠,是***之光。目前,苏州昆山、成都等多地超算中心已经搭载海光CPU与DCU,为社会提供优质算力。
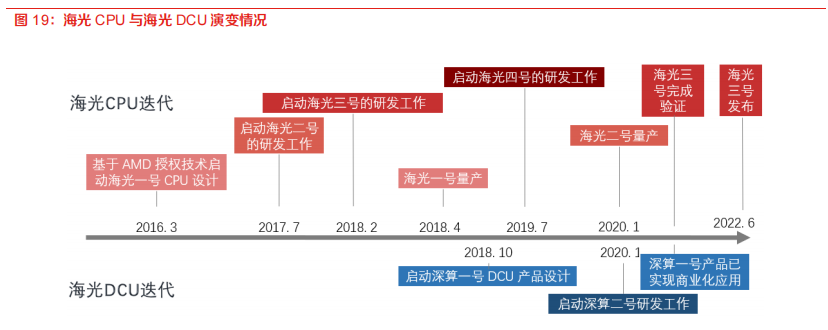
海光CPU一、二代均已商业化, 三代初亮相,四代有序研发中。海光DCU一代已商业化应用,二代研发中。公司持续技术创新和演进,坚持走“销售一代, 验证一代, 研发一代”的产品开发策略。公司建立了完善的高端处理器的研发环境和流程,持续开发多代产品,产品性能不断提高,同时功能不断完善丰富。海光CPU的四代产品中,海光一号和海光二号均实现了商业化应用,海光三号已亮相发布会,海光四号处于研发阶段。海光DCU于2018年启动DCU第一代产品深算一号的产品研发,于2020年1月启动了深算二号的研发,截至2022年6月,深算一号已实现商业化应用。
海光DCU某些硬件性能与英伟达的A100、AMD的MI100相近。海光DCU双精度计算能力突出。据北京大学高性能计算系统中标公告(HCZB-2021-ZB0364),海光信息的DCU Z100的通用计算核心达到8192个。其关键性能指标实现:FP64 10.8TFlops,显存32GB HBM2,对比全球芯片巨头的高端AI芯片不遑多让。英伟达A100的相关指标为:FP64 9.7 TFlops、显存40/80GB HBM2。AMD MI100的相关指标为:FP64 11.5 TFlops、显存32GB HBM2。

海光DCU生态丰富,工具链完整。海光的DCU脱胎于AMD,兼容主流生态——开源ROCmGPU计算生态,支持TensorFlow、Pytorch和PaddlePaddle等主流深度学习框架、适配主流应软件。ROCm又被称为类CUDA,现有CUDA上运行的应用可以低成本迁移到基于ROCm的海光平台上运行。
2022年,海光发布国内首个全精度(FP64)异构计算平台,该平台搭载CPU海光三号和DCU海光深算,涵盖数值模拟、AI训练、AI推理所需的多样算力,实现了智能计算与数值运算的深度融合。同时,此平台可全面支持TensorFlow、PyTorch、Caffe2等主流AI深度学习框架,目前已超过1000种应用软件部署在该平台上。
3、寒武纪:国产AI芯片先行者
寒武纪始终深耕芯片研发,不断推陈出新、实现技术进步。寒武纪成立于2016年,专注人工智能芯片产品的研发与创新。公司成立之初便开始了对AI芯片领域的探索创新。并在2016年年底成功研发出全球首款AI手机芯片——寒武纪1A。2017年,这款芯片被搭载于华为的高端系统级芯片麒麟970,应用于Mate10手机,并获得了广泛好评。芯片可以在功耗极低的前提下,涵盖人脸识别、语音识别、图像增强等多种功能。此后,寒武纪又陆续推出了多款AI芯片产品,包括云端训练芯片MLU100、边缘推理芯片MLU270、车载推理芯片MLU290等 。这些产品都具有高性能、低功耗、高集成度等特点,在图像识别、语音识别、自然语言处理等领域都有着优异的表现。
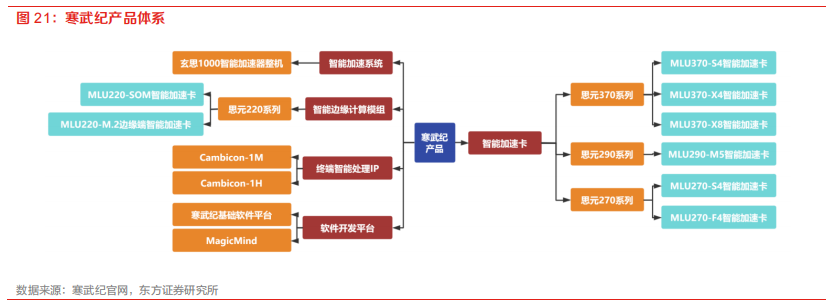
思元370是寒武纪的首款训练推理一体芯片,也是其云端产品的第三代。思元370采用了7nm制程工艺,并成为首款采用Chiplet技术的人工智能芯片。该芯片最大算力可达256TOPS(INT8),是上一代云端推理产品思元270算力的两倍,同时该芯片还支持LPDDR5内存,内存带宽是270的三倍,因此可以在板卡有限的功耗范围内为人工智能芯片分配更多的能源,从而输出更高的算力。思元370智能芯片还采用了先进的Chiplet技术,支持灵活的芯粒组合,仅用单次流片便可以实现多款智能加速卡产品的商用。目前,该公司已推出三款加速卡:MLU370-S4、MLU370-X4和MLU370-X8,包含应用于计算密度高的数据中心、针对专注人工智能推理相关业务的互联网厂商需求和应用于对算力带宽要求高的训练任务,满足用户的多样化需求。
新一代训练芯片寒武纪590还未量产,据悉训练能力突出。寒武纪最新一代云端智能训练芯片思元590还未正式发布,据寒武纪董事长在2022 WAIC上介绍,思元590采用全新的MLUarch05架构,实测训练性能较在售产品有了显著提升。思元590可提供更大的内存容量和更高的内存带宽,其PCIe接口也较上代实现了升级。
审核编辑 :李倩
-
芯片
+关注
关注
462文章
53530浏览量
458835 -
AI
+关注
关注
89文章
38085浏览量
296316 -
人工智能
+关注
关注
1813文章
49734浏览量
261392
原文标题:大模型AI兴起:新一轮芯片、服务器、智算等浪潮来袭
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI服务器电源测试解决方案:为算力巨擘注入稳定之魂
苏州传感器芯片IDM厂商“矩阵光电”获新一轮融资
亿铸科技完成新一轮融资
夏厦精密开启新一轮投资布局
穹彻智能完成新一轮融资
AI 芯片浪潮下,职场晋升新契机?
借势 RISC-V与 AI 浪潮,元石智算打造算力新范式







 工商网监
工商网监
评论