 未来的高性能FPGA是否会优于GPU?
未来的高性能FPGA是否会优于GPU?

英特尔加速器架构实验室的Eriko Nurvitadhi 博士以最新的GPU为参照,对两代IntelFPGA上新兴的DNN算法进行了评估,认为新兴的低精度和稀疏DNN算法效率较之传统的密集FP32 DNN有巨大改进,但是它们引入了GPU难以处理的不规则并行度和定制数据类型。相比之下,FPGA正是设计用于在运行不规则并行度和自定义数据类型时实现极端的可定制性的。这样的趋势使未来FPGA成为运行DNN、AI和ML应用的可行平台。
来自社交媒体和互联网的图像、视频和语音数字数据的持续指数增长推动了分析的需要,以使得数据可以理解和处理。
数据分析通常依赖于机器学习(ML)算法。在ML算法中,深度卷积神经网络(DNN)为重要的图像分类任务提供了最先进的精度,并被广泛采用。
在最近的 International Symposium onField Programmable Gate Arrays (ISFPGA) 上,Intel Accelerator Architecture Lab (AAL) 的 Eriko Nurvitadhi 博士提出了一篇名为CanFPGAs beat GPUs in AcceleratingNext-Generation Deep Neural Networks 的论文。他们的研究以最新的高性能的 NVIDIA Titan X Pascal * Graphics Processing Unit (GPU) 为参照,对两代 Intel FPGA(Intel Arria10 和Intel Stratix 10)的新兴DNN算法进行了评估。
Intel Programmable SolutionsGroup 的 FPGA 架构师 Randy Huang 博士,论文的合著者之一,说:“深度学习是AI中最令人兴奋的领域,因为我们已经看到了深入学习带来的巨大进步和大量应用。虽然AI 和DNN 研究倾向于使用 GPU,但我们发现应用领域和英特尔下一代FPGA 架构之间是完美契合的。我们考察了接下来FPGA 的技术进展,以及DNN 创新算法的快速增长,并思考了对于下一代 DNN 来说,未来的高性能 FPGA 是否会优于GPU。我们的研究发现,FPGA 在DNN 研究中表现非常出色,可用于需要分析大量数据的AI、大数据或机器学习等研究领域。使用经修剪或压缩的数据(相对于全32位浮点数据(FP32)),被测试的 Intel Stratix10 FPGA 的性能优于GPU。除了性能外,FPGA 的强大还源于它们具有适应性,通过重用现有的芯片可以轻松实现更改,从而让团队在六个月内从想法进展到原型(和用18个月构建一个ASIC相比)。”
测试中使用的神经网络机器学习
神经网络可以被表现为通过加权边互连的神经元的图形。每个神经元和边分别与激活值和权重相关联。该图形被构造为神经元层。如图1所示。

图1 深度神经网络概述
神经网络计算会通过网络中的每个层。对于给定层,每个神经元的值通过相乘和累加上一层的神经元值和边权重来计算。计算非常依赖于多重累积运算。DNN计算包括正向和反向传递。正向传递在输入层采样,遍历所有隐藏层,并在输出层产生预测。对于推理,只需要正向传递以获得给定样本的预测。对于训练,来自正向传递的预测错误在反向传递中被反馈以更新网络权重。这被称为反向传播算法。训练迭代地进行向前和向后传递以调整网络权重,直到达到期望的精度。
FPGA成为可行的替代方案
硬件:与高端GPU 相比,FPGA 具有卓越的能效(性能/瓦特),但它们不具有高峰值浮点性能。FPGA技术正在迅速发展,即将推出的Intel Stratix10 FPGA提供超过5,000个硬件浮点单元(DSP),超过28MB的芯片上RAM(M20Ks),与高带宽内存(up to 4x250GB/s/stack or 1TB/s)的集成,并来自新HyperFlex技术的改进频率。英特尔FPGA 提供了一个全面的软件生态系统,从低级HardwareDescription 语言到具有OpenCL、C和C ++的更高级别的软件开发环境。英特尔将进一步利用MKL-DNN库,针对Intel的机器学习生态系统和传统框架(如今天提供的Caffe)以及其他不久后会出现的框架对 FPGA进行调整。基于14nm工艺的英特尔Stratix 10在FP32吞吐量方面达到峰值9.2TFLOP/s。相比之下,最新的Titan X Pascal GPU的FP32吞吐量为11TFLOP/s。
新兴的DNN算法:更深入的网络提高了精度,但是大大增加了参数和模型大小。这增加了对计算、带宽和存储的要求。因此,使用更为有效的DNN已成趋势。新兴趋势是采用远低于32位的紧凑型低精度数据类型, 16位和8位数据类型正在成为新的标准,因为它们得到了DNN软件框架(例如TensorFlow)支持。此外,研究人员已经对极低精度的2位三进制和1位二进制 DNN 进行了持续的精度改进,其中值分别约束为(0,+ 1,-1)或(+ 1,-1)。Nurvitadhi 博士最近合著的另一篇论文首次证明了,ternary DNN可以在最著名的ImageNet数据集上实现目前最高的准确性。另一个新兴趋势是通过诸如修剪、ReLU 和ternarization 等技术在DNN神经元和权重中引入稀疏性(零存在),这可以导致DNN带有〜50%至〜90%的零存在。由于不需要在这样的零值上进行计算,因此如果执行这种稀疏DNN 的硬件可以有效地跳过零计算,性能提升就可以实现。新兴的低精度和稀疏DNN算法效率较之传统的密集FP32 DNN有巨大改进,但是它们引入了GPU难以处理的不规则并行度和定制数据类型。相比之下,FPGA正是设计用于在运行不规则并行度和自定义数据类型时实现极端的可定制性的。这样的趋势使未来FPGA成为运行DNN、AI和ML应用的可行平台。黄先生说:“FPGA专用机器学习算法有更多的余量。图2说明了FPGA的极端可定制性(2A),可以有效实施新兴的DNN(2B)。
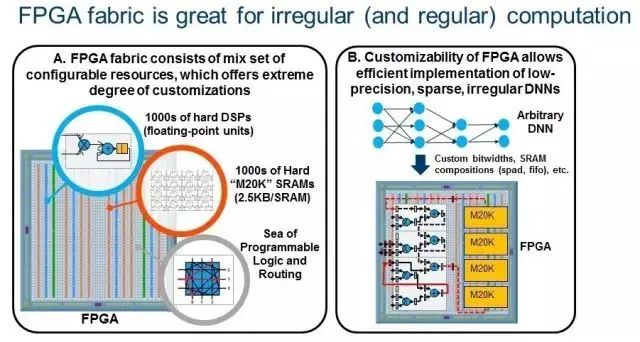
图2
研究所用的硬件和方法
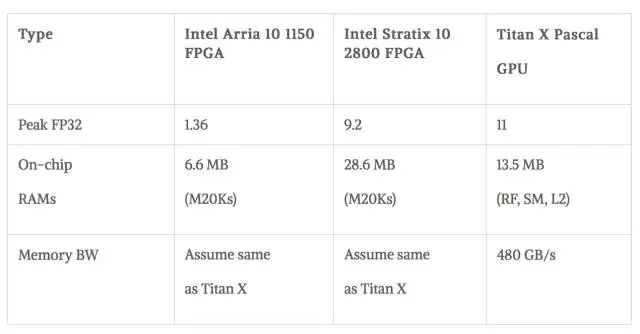
GPU:使用已知的库(cuBLAS)或框架(Torch with cuDNN)FPGA:使用QuartusEarly Beta版本和PowerPlay
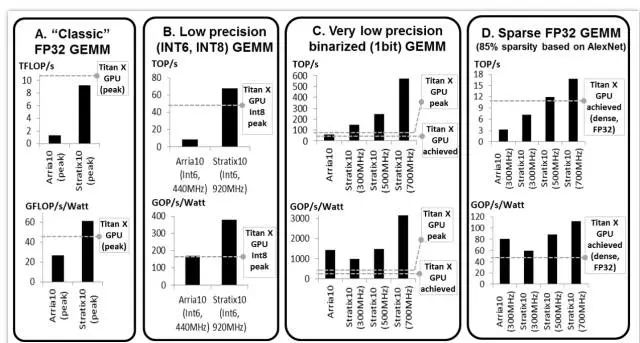
图3 GEMM测试结果、GEMM是DNN中的关键操作
在低精度和稀疏DNN中,Stratix 10 FPGA 比 Titan X GPU的性能更好,甚至性能功耗比要更好。未来这类DNN可能会成为趋势。
研究1:GEMM测试
DNN 严重依赖GEMM。常规DNN依靠FP32密集GEMM。然而,较低的精度和稀疏的新兴DNN 依赖于低精度和/或稀疏的GEMM 。Intel 团队对这些GEMM进行了评估。
FP32 密集GEMM:由于FP32密集GEMM得到了很好的研究,该团队比较了FPGA和GPU数据表上的峰值。Titan X Pascal 的最高理论性能是Stratix 10 的11 TFLOP和9.2 TFLOP。图3A显示,带有多得多的DSP 数量的Intle Stratix 10 将提供比Intel Arria 10 更强大的FP32性能,和Titan X 的性能表现接近。
低精度INT6 GEMM:为了显示FPGA的可定制性优势,该团队通过将四个int6打包到一个DSP模块中,研究了FPGA的Int6 GEMM。对于本来不支持Int6 的GPU,他们使用了Int8 GPU 的峰值性能进行了比较。图3B显示,Intel Stratix 10 的性能优于GPU。FPGA比GPU提供了更引人注目的性能/功耗比。
非常低精度的1位二进制GEMM :最近的二进制DNN 提出了非常紧凑的1bit数据类型,允许用xnor 和位计数操作替换乘法,非常适合FPGA。图3C显示了团队的二进制GEMM 测试结果,其中FPGA 基本上执行得比GPU 好(即,根据频率目标的不同,为~2x 到 ~10x)。
稀疏GEMM:新出现的稀疏DNN包含许多零值。该团队在带有85%零值的矩阵上测试了一个稀疏的GEMM(基于已修剪的AlexNet)。该团队测试了使用FPGA的灵活性以细粒度的方式来跳过零计算的 GEMM 设计。该团队还在 GPU 上测试了稀疏的 GEMM,但发现性能比在GPU 上执行密集的 GEMM 更差(相同的矩阵大小)。该团队的稀疏 GEMM 测试(图3D)显示,FPGA 可以比 GPU 表现更好,具体取决于目标 FPGA 的频率。

图4 DNN精度的趋势,以及FPGA和GPU在Ternary ResNet DNN上的测试结果
研究2:使用三进制 ResNet DNN 测试
三进制DNN最近提出神经网络权重约束值为+1,0或-1。这允许稀疏的2位权重,并用符号位操作代替乘法。在本次测试中,该团队使用了为零跳跃、2位权重定制的FPGA设计,同时没有乘法器来优化运行Ternary-ResNet DNN 。
与许多其他低精度和稀疏的DNN 不同,三进制DNN可以为最先进的DNN(即ResNet)提供可供比较的精度,如图4A所示。“许多现有的GPU和FPGA研究仅针对基于AlexNet(2012年提出)的ImageNet的”足够好“的准确性。最先进的Resnet(在2015年提出)提供比AlexNet高出10%以上的准确性。在2016年底,在另一篇论文中,我们首先指出,Resnet上的低精度和稀疏三进制DNN 算法可以在全精度ResNet 的±1%的精度范围内实现。这个三进制ResNet 是我们在FPGA研究中的目标。因此,我们首先论证,FPGA可以提供一流的(ResNet)ImageNet精度,并且可以比GPU更好地实现。““Nurvitadhi说。
图4B显示了 Intel Stratix 10 FPGA 和 Titan X GPU 在 ResNet-50上的性能和性能/功耗比。即使保守估计,Intel Stratix 10 FPGA 也比 Titan X GPU 性能提高了约60%。中度和激进的估计会更好(2.1x和3.5x的加速)。有趣的是,Intel Stratix 10 750MHz的激进预估可以比 Titan X 的理论峰值性能还高35%。在性能/功耗比方面,从保守估计到激进估计,Intel Stratix 10 比 Titan X 要好2.3倍到4.3倍, FPGA如何在研究测试中堆叠
结果表明,Intel Stratix 10 FPGA的性能(TOP /秒)比稀疏的、Int6 和二进制DNN的GEMM上的 Titan X Pascal GPU分别提高了10%、50%和5.4倍。在三进制 ResNet 上,Stratix 10 FPGA 的性能比Titan X Pascal GPU 提高了60%,而性能/功耗比好2.3倍。结果表明,FPGA 可能成为下一代DNN 加速的首选平台。深层神经网络中FPGA的未来
FPGA 能否在下一代 DNN 的性能上击败 GPU ?Intel 对两代 FPGA(Intel Arria 10和 Intel Stratix 10)以及最新的 Titan X GPU 的各种新兴DNN的评估显示,目前DNN算法的趋势可能有利于FPGA,而且FPGA甚至可以提供卓越的性能。虽然这些结论源于2016年完成的工作,Intel 团队在继续测试 Intel FPGA 的现代 DNN 算法和优化(例如,FFT / winograd 数学变换,量化,压缩)。
该团队还指出,除了DNN之外,FPGA在其他不规则应用以及延迟敏感(如ADAS和工业用途)等领域也有机会。
“目前使用32位密集矩阵乘法的机器学习是GPU体现优势的领域”,黄表示:“我们鼓励其他开发人员和研究人员与我们一起重新表述机器学习问题,以充分发挥 FPGA 更小位数处理能力的优势,因为 FPGA 可以很好地适应向低精度的转变。”



欢迎加入至芯科技FPGA微信学习交流群,这里有一群优秀的FPGA工程师、学生、老师、这里FPGA技术交流学习氛围浓厚、相互分享、相互帮助、叫上小伙伴一起加入吧!
点个在看你最好看
原文标题:未来的高性能FPGA是否会优于GPU?
文章出处:【微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
-
FPGA
+关注
关注
1665文章
22587浏览量
641237
原文标题:未来的高性能FPGA是否会优于GPU?
文章出处:【微信号:gh_9d70b445f494,微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索Lattice MachXO2 FPGA:低功耗与高性能的完美融合
沐曦股份联合上海人工智能实验室发布高性能GPU算子生成系统Kernel-Smith

基于openEuler平台的CPU、GPU与FPGA异构加速实战

基于FPGA的DAQ系统|实现高性能数据采集的挑战

探索Arria V系列FPGA:高性能与低功耗的完美结合
青翼基于KU115FPGA 高性能数据预处理载板-PCIe信号处理板-FPGA载板

MAX17409:高性能GPU的电源控制利器
FPGA+GPU异构混合部署方案设计
AMD UltraScale架构:高性能FPGA与SoC的技术剖析
基于DSP与FPGA异构架构的高性能伺服控制系统设计

汽车中的GPU是如何使用的?




评论