 LLM风口背后,ChatGPT的成本问题
LLM风口背后,ChatGPT的成本问题

趁着ChatGPT这一热门话题还未消退,我们来聊一聊这类大规模语言模型(LLM)或通用人工智能(AGI)背后的细节。毕竟目前相关的概念股跟风大涨,但还是有不少人在持观望态度。无论是国外还是国内,有没有可能做出下一个ChatGPT?以及打造这样一个模型所需的研发成本和运营成本究竟是多少。
ChatGPT背后的成本,以及GPU厂商等候多时的增长点
首先,ChatGPT是OpenAI预训练的对话模型,除去训练本身所需的硬件与时间成本外,运营时的推理成本也要算在其中。根据UBS分析师Timothy Arcuri的观点,ChatGPT使用到了至少1万块英伟达的GPU来运营这一模型。不过这还是相对较为保守的数据,根据Semianalysis分析师Dylan Patel对模型参数、日活跃用户数以及硬件利用率等种种因素的分析,他粗略估计OpenAI需要用到3617个HGX A100服务器来维持ChatGPT的运转。

HGX A100 / 英伟达
需要注意的是,该分析中的HGX A100服务器是8块A100 SXM的定制化模块,并非DGX A100这样集成了AMD CPU的标准服务器模块,也就是说共需28936块英伟达A100 GPU。且不说A100本身就高昂的售价,更何况现在还有一定的溢价。一张40GB的A100 PCIe卡,目前在亚马逊上的单价为8000多美元,而80GB的A100 PCIe卡价格在15000美元左右浮动。
由此估算,运行ChatGPT的前期设备投入成本少说也有2.3亿美元,这其中还没算进CPU、内存、硬盘和网关等设备的硬件成本。所有GPU同时运转时的TDP功耗达到7234kW。按照美国商用电价来计算的话,哪怕是每日运转单由GPU带来的电费也至少要两万美元以上。这样的设备成本除非是微软、谷歌、亚马逊这样本就手握大把服务器硬件资源的厂商,否则很难支撑这一模型的日常运转。
接着我们再从每次查询的推理成本这个角度来看,如果只负责在服务器上部署ChatGPT的OpenAI无需考虑设备购入成本,而是只考虑GPU云服务器的定价。根据Dylan Patel的估算,ChatGPT每次查询的成本为0.36美分,约合2.4分人民币,每天在硬件推理上的成本也高达70万美元。由此来看,无论是OpenAI现在免费提供的ChatGPT,还是微软在Bing上启用的ChatGPT,其实都是在大把烧钱。
要知道,现在还只是用到了ChatGPT这一文本语言模型,根据OpenAI的CEO Sam Altman的说法,他们的AI视频模型也在准备当中。而要想打造更复杂的视频模型,势必会对GPU算力提出更高的要求。
未来的硬件成本会更低吗?
对于任何一个想要运行ChatGPT这类服务的厂商,打造这样一款应用都要付出不小的成本,所以现阶段还是微软、谷歌之类的巨头相互博弈。但Sam Altman也表示,随着越来越多的竞争出现,毋庸置疑会把硬件成本压低,也会把每个Token的定价压低。
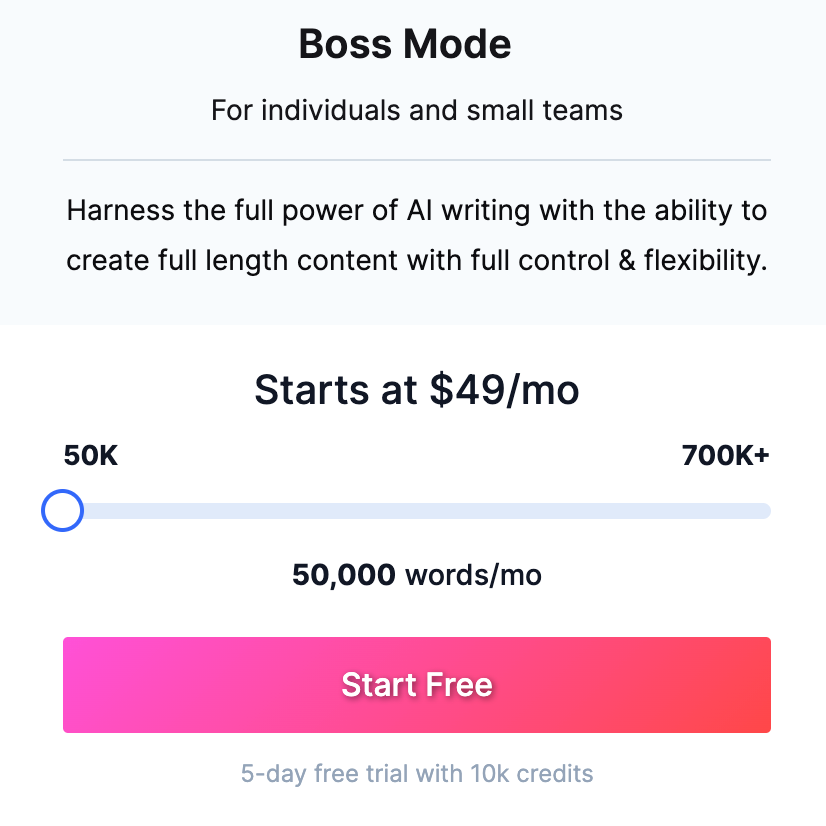
Jasper AI写作工具的定价 / Jasper.ai
大家可以参照一下其他利用OpenAI的GPT-3的AI工具,比如Jasper。Jasper作为一个人工智能写作软件,每月需要缴纳50美元,才能享受5万字的写作字数上限。而反观ChatGPT,哪怕是目前的免费版也能帮你写就长篇故事了。而这些工具鼓吹的多种模板,在ChatGPT中也只是换一种问法而已。
Sam Altman认为会有更多的玩家入局AGI,如此一来ChatGPT这种类型的服务会出现在更多的产品和应用中,而不再只是作为大厂的附庸,比如只在微软的Bing、Office中大规模使用等,这也是OpenAI还考虑授权给其他公司的原因。
不过如果依照谷歌的访问和搜索量来部署ChatGPT或Bard这样类似模型的话,所需的成本必定要远远高于Bing,毕竟谷歌依然是目前国际领先的搜索引擎。
如果谷歌用其TPU之类的专用硬件来完成LLM的训练与推理,其成本必然显著低于GPU这类通用硬件的,毕竟TPU这类ASIC芯片在量产成本和运行功耗上都有着得天独厚的优势。
但谷歌如果使用专用硬件的话,可能会存在强制绑定的问题,哪怕谷歌选择公开TPU商业运营,如果想用集成Bard的合作客户也基本与谷歌云绑定了,就像现在的ChatGPT与微软Azure强制绑定一样。而且如果Bard出现算法路线上的大变动,TPU这种ASIC方案很难再对其进行针对性优化。
由此可以看出,虽然大小入局者众多,但真正落地、可大规模使用且还算好用的产品还是只有ChatGPT一个,要想等到行业内卷压低成本,可能还得等上很长一段时间。
ChatGPT如何实现盈利?
微软高调宣布与OpenAI合作,并将ChatGPT融入Bing等一系列微软产品中,这已经不是什么新闻了。但其实这样的合作关系昭示了ChatGPT的一种盈利方式,那就是授权。除了微软这种深度合作的厂商以外,其他应用开发商也可以采用授权的方式,将ChatGPT集成到自己的产品中去。
不过Sam Altman在接受外媒采访时表示,他们目前在授权上的合作还并不多。由此猜测,要么是此类授权费用昂贵,要么就是缺少成熟的产品形态来应用这一技术,毕竟当下还算强相关的应用也只有搜索引擎、写作工具以及AI助手等。再说,对于感兴趣想尝鲜的厂商来说,直接接入OpenAI的API或许价格反倒更低。
另一种盈利方式,也是现在最流行且已被普遍接受的收费模式,订阅制。2月1日,OpenAI正式推出了20美元一个月的ChatGPT Plus,提供高峰时期的访问、更快的响应速度以及新功能和改进的抢先体验。
结语
总的来说,ChatGPT这类AGI作为元宇宙之后的又一大风口,激发了一股初创公司入局LLM的热潮。但从客观来看,对于这些初创公司来说,他们打从一开始根本不需要考虑市场风险,比如这会不会是个伪需求。他们更应该担心的应该是技术风险,也就是究竟有没有这个实力和资本去打造一个可用的LLM。
ChatGPT背后的成本,以及GPU厂商等候多时的增长点
首先,ChatGPT是OpenAI预训练的对话模型,除去训练本身所需的硬件与时间成本外,运营时的推理成本也要算在其中。根据UBS分析师Timothy Arcuri的观点,ChatGPT使用到了至少1万块英伟达的GPU来运营这一模型。不过这还是相对较为保守的数据,根据Semianalysis分析师Dylan Patel对模型参数、日活跃用户数以及硬件利用率等种种因素的分析,他粗略估计OpenAI需要用到3617个HGX A100服务器来维持ChatGPT的运转。
HGX A100 / 英伟达
需要注意的是,该分析中的HGX A100服务器是8块A100 SXM的定制化模块,并非DGX A100这样集成了AMD CPU的标准服务器模块,也就是说共需28936块英伟达A100 GPU。且不说A100本身就高昂的售价,更何况现在还有一定的溢价。一张40GB的A100 PCIe卡,目前在亚马逊上的单价为8000多美元,而80GB的A100 PCIe卡价格在15000美元左右浮动。
由此估算,运行ChatGPT的前期设备投入成本少说也有2.3亿美元,这其中还没算进CPU、内存、硬盘和网关等设备的硬件成本。所有GPU同时运转时的TDP功耗达到7234kW。按照美国商用电价来计算的话,哪怕是每日运转单由GPU带来的电费也至少要两万美元以上。这样的设备成本除非是微软、谷歌、亚马逊这样本就手握大把服务器硬件资源的厂商,否则很难支撑这一模型的日常运转。
接着我们再从每次查询的推理成本这个角度来看,如果只负责在服务器上部署ChatGPT的OpenAI无需考虑设备购入成本,而是只考虑GPU云服务器的定价。根据Dylan Patel的估算,ChatGPT每次查询的成本为0.36美分,约合2.4分人民币,每天在硬件推理上的成本也高达70万美元。由此来看,无论是OpenAI现在免费提供的ChatGPT,还是微软在Bing上启用的ChatGPT,其实都是在大把烧钱。
要知道,现在还只是用到了ChatGPT这一文本语言模型,根据OpenAI的CEO Sam Altman的说法,他们的AI视频模型也在准备当中。而要想打造更复杂的视频模型,势必会对GPU算力提出更高的要求。
未来的硬件成本会更低吗?
对于任何一个想要运行ChatGPT这类服务的厂商,打造这样一款应用都要付出不小的成本,所以现阶段还是微软、谷歌之类的巨头相互博弈。但Sam Altman也表示,随着越来越多的竞争出现,毋庸置疑会把硬件成本压低,也会把每个Token的定价压低。
Jasper AI写作工具的定价 / Jasper.ai
大家可以参照一下其他利用OpenAI的GPT-3的AI工具,比如Jasper。Jasper作为一个人工智能写作软件,每月需要缴纳50美元,才能享受5万字的写作字数上限。而反观ChatGPT,哪怕是目前的免费版也能帮你写就长篇故事了。而这些工具鼓吹的多种模板,在ChatGPT中也只是换一种问法而已。
Sam Altman认为会有更多的玩家入局AGI,如此一来ChatGPT这种类型的服务会出现在更多的产品和应用中,而不再只是作为大厂的附庸,比如只在微软的Bing、Office中大规模使用等,这也是OpenAI还考虑授权给其他公司的原因。
不过如果依照谷歌的访问和搜索量来部署ChatGPT或Bard这样类似模型的话,所需的成本必定要远远高于Bing,毕竟谷歌依然是目前国际领先的搜索引擎。
如果谷歌用其TPU之类的专用硬件来完成LLM的训练与推理,其成本必然显著低于GPU这类通用硬件的,毕竟TPU这类ASIC芯片在量产成本和运行功耗上都有着得天独厚的优势。
但谷歌如果使用专用硬件的话,可能会存在强制绑定的问题,哪怕谷歌选择公开TPU商业运营,如果想用集成Bard的合作客户也基本与谷歌云绑定了,就像现在的ChatGPT与微软Azure强制绑定一样。而且如果Bard出现算法路线上的大变动,TPU这种ASIC方案很难再对其进行针对性优化。
由此可以看出,虽然大小入局者众多,但真正落地、可大规模使用且还算好用的产品还是只有ChatGPT一个,要想等到行业内卷压低成本,可能还得等上很长一段时间。
ChatGPT如何实现盈利?
微软高调宣布与OpenAI合作,并将ChatGPT融入Bing等一系列微软产品中,这已经不是什么新闻了。但其实这样的合作关系昭示了ChatGPT的一种盈利方式,那就是授权。除了微软这种深度合作的厂商以外,其他应用开发商也可以采用授权的方式,将ChatGPT集成到自己的产品中去。
不过Sam Altman在接受外媒采访时表示,他们目前在授权上的合作还并不多。由此猜测,要么是此类授权费用昂贵,要么就是缺少成熟的产品形态来应用这一技术,毕竟当下还算强相关的应用也只有搜索引擎、写作工具以及AI助手等。再说,对于感兴趣想尝鲜的厂商来说,直接接入OpenAI的API或许价格反倒更低。
另一种盈利方式,也是现在最流行且已被普遍接受的收费模式,订阅制。2月1日,OpenAI正式推出了20美元一个月的ChatGPT Plus,提供高峰时期的访问、更快的响应速度以及新功能和改进的抢先体验。
结语
总的来说,ChatGPT这类AGI作为元宇宙之后的又一大风口,激发了一股初创公司入局LLM的热潮。但从客观来看,对于这些初创公司来说,他们打从一开始根本不需要考虑市场风险,比如这会不会是个伪需求。他们更应该担心的应该是技术风险,也就是究竟有没有这个实力和资本去打造一个可用的LLM。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
ChatGPT
+关注
关注
31文章
1600浏览量
10393 -
LLM
+关注
关注
1文章
350浏览量
1394
发布评论请先 登录
相关推荐
热点推荐
OpenAI正式发布ChatGPT Images 2.0版本
在人工智能技术迅猛发展的浪潮中,OpenAI始终是引领行业变革的先锋力量。近日,OpenAI正式发布ChatGPT Images 2.0版本,这一消息如同一颗重磅炸弹,在科技圈引发了强烈反响,在
Google正式发布LLM评测基准Android Bench
LLM 在 Android 开发任务中的表现。现在,我们发布了 Android Bench 的首个版本,这是 Google 官方专门针对 Android 开发打造的 LLM 排行榜。

芯盾时代如何破局LLM供应链漏洞危机
随着人工智能技术进入 2026 年的爆发期,大语言模型(LLM)已不再是实验室里的原型,而是支撑企业核心业务的“数字引擎”。然而,LLM的强大高度依赖于全球化的AI生态。从海量的互联网训练数据,到
新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
LLM-8850KitLLM-8850Kit是一款面向边缘AI与嵌入式计算场景的高性能AI加速卡套件,由LLM-8850CardAI加速卡与LLM-8850PiHat转接板组成。核心加速卡

【CIE全国RISC-V创新应用大赛】+ 一种基于LLM的可通过图像语音控制的元件库管理工具
成本下长时间的维持运营一个良好的库存环境。本项目实现了多模态同步,在项目中联合调用了CV(OCR),ASR,LLM。
主要功能构想
1.实现用户将采购单或元器件标签或元器件(下文称输入资料)放置或
发表于 11-12 19:32
NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT LLM 作为 NVIDIA 为大规模 LLM 推理打造的推理框架,核心目标是突破 NVIDIA 平台上的推理性能瓶颈。为实现这一目标,其构建了多维度的核心实现路径:一方面,针对需
TensorRT-LLM的大规模专家并行架构设计
之前文章已介绍引入大规模 EP 的初衷,本篇将继续深入介绍 TensorRT-LLM 的大规模专家并行架构设计与创新实现。

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化
TensorRT-LLM 在 NVIDIA Blackwell GPU 上创下了 DeepSeek-R1 推理性能的世界纪录,Multi-Token Prediction (MTP) 实现了大幅提速

如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
TensorRT-LLM 作为 NVIDIA 专为 LLM 推理部署加速优化的开源库,可帮助开发者快速利用最新 LLM 完成应用原型验证与产品部署。
新品|CamModule SC850SL,为 LLM630 打造的高清摄像头模组
CamModuleSC850SL是一款专为LLM630ComputeKit定制的高性能摄像模组,采用SmartSensSC850SL8MPCMOS图像传感器,支持4K视频采集、宽动态范围(HDR

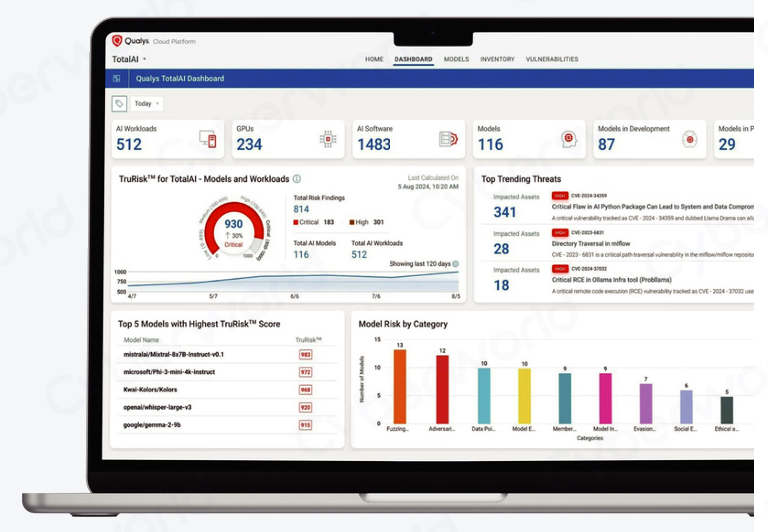
Qualys TotalAI 降低 Gen AI 和 LLM 工作负载的风险
“在AI时代,最大的风险不是不去创新,而是在没有稳固基础的情况下创新。” 生成式人工智能 (Gen AI) 和大语言模型 (LLM) 正在革新各行各业,但是,它们的快速应用带来了严峻的网络安全挑战
使用 llm-agent-rag-llamaindex 笔记本时收到的 NPU 错误怎么解决?
使用 conda create -n ov-nb-demos python=3.11 创建运行 llm-agent-rag-llamaindex notebook 的环境。
执行“创建
发表于 06-23 06:26
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践
针对基于 Diffusion 和 LLM 类别的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能显著提升推理速度。在单张 NVIDIA Ada Lovelace

LM Studio使用NVIDIA技术加速LLM性能
随着 AI 使用场景不断扩展(从文档摘要到定制化软件代理),开发者和技术爱好者正在寻求以更 快、更灵活的方式来运行大语言模型(LLM)。
小白学大模型:从零实现 LLM语言模型
在当今人工智能领域,大型语言模型(LLM)的开发已经成为一个热门话题。这些模型通过学习大量的文本数据,能够生成自然语言文本,完成各种复杂的任务,如写作、翻译、问答等。https




评论