 利用视觉+语言数据增强视觉特征
利用视觉+语言数据增强视觉特征

研究动机
传统的多模态预训练方法通常需要"大数据"+"大模型"的组合来同时学习视觉+语言的联合特征。但是关注如何利用视觉+语言数据提升视觉任务(多模态->单模态)上性能的工作并不多。本文旨在针对上述问题提出一种简单高效的方法。
在这篇文章中,以医疗影像上的特征学习为例,我们提出对图像+文本同时进行掩码建模(即Masked Record Modeling,Record={Image,Text})可以更好地学习视觉特征。该方法具有以下优点:
简单。仅通过特征相加就可以实现多模态信息的融合。此处亦可进一步挖掘,比如引入更高效的融合策略或者扩展到其它领域。
高效。在近30w的数据集上,在4张NVIDIA 3080Ti上完成预训练仅需要1天半左右的时间。
性能强。在微调阶段,在特定数据集上,使用1%的标记数据可以接近100%标记数据的性能。
方法(一句话总结)
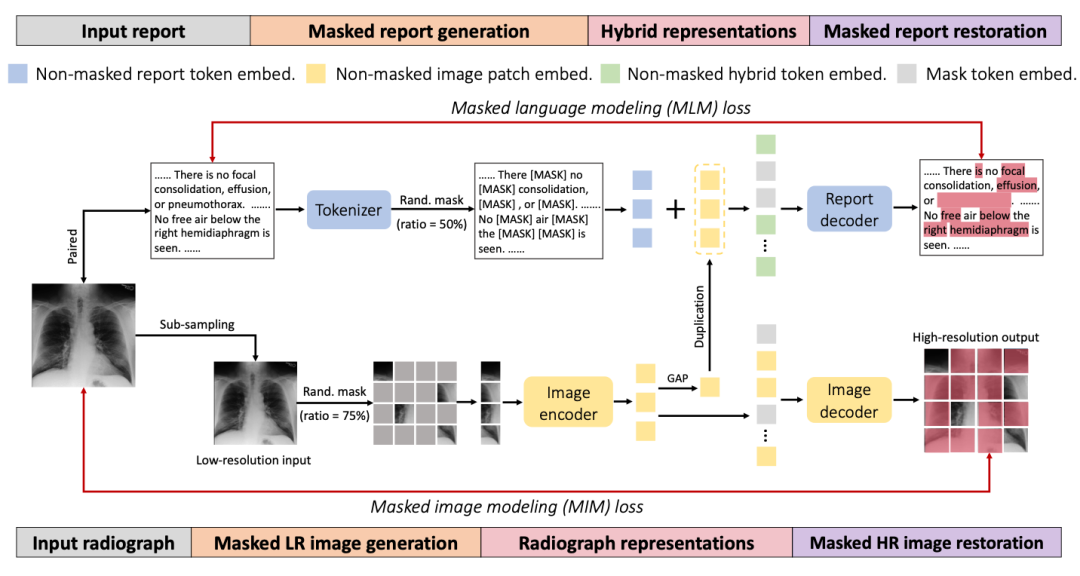
如上图所示,我们提出的训练策略是比较直观的,主要包含三步:
随机Mask一部分输入的图像和文本
使用加法融合过后的图像+文本的特征重建文本
使用图像的特征重建图像。
性能
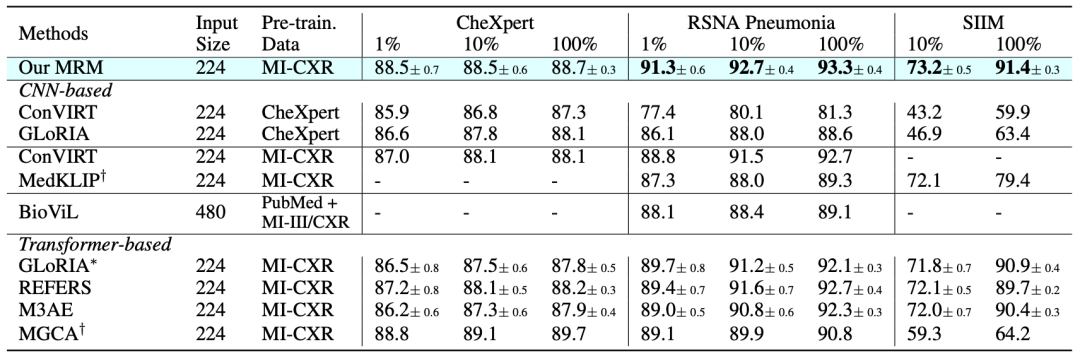
如上图所示,我们全面对比了现有的相关方法和模型在各类微调任务上的性能。
在CheXpert上,我们以1%的有标记数据接近使用100%有标记数据的性能。
在RSNA Pneumonia和SIIM (分割)上,我们以较大幅度超过了之前最先进的方法。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
建模
+关注
关注
1文章
320浏览量
62725 -
数据集
+关注
关注
4文章
1230浏览量
26036 -
大数据
+关注
关注
64文章
9029浏览量
143041
原文标题:ICLR 2023 | 厦大&港大提出MRM:利用视觉+语言数据增强视觉特征
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
AI眼镜视觉处理芯片:从图像感知到智能增强的技术跃迁
,而到2028年,随着AR功能普及与视觉交互成为标配,出货量有望逼近4亿台。在这一爆发性增长背后,视觉处理能力已成为AI眼镜的核心竞争力,而支撑这一能力的关键,正是日益复杂的视觉处理芯片架构。 AI眼镜的

FPGA和GPU加速的视觉SLAM系统中特征检测器研究
特征检测是SLAM系统中常见但耗时的模块,随着SLAM技术日益广泛应用于无人机等功耗受限平台,其效率优化尤为重要。本文首次针对视觉SLAM流程开展硬件加速特征检测器的对比研究,通过对比现代SoC平台

机器视觉检测PIN针
: 结合形态学处理、特征提取(如长宽比、面积)及深度学习(针对复杂缺陷),自动检出弯曲、断裂、变形、污染等。输出与控制:实时显示检测结果(OK/NG)及具体参数数值。生成检测报告,支持数据追溯。NG品自动剔除信号输出,无缝对接产线。了解更多机器
发表于 09-26 15:09
iTOF技术,多样化的3D视觉应用
(CMOS)产品项目利用其在传统TOF(CCD)技术方面的专业知识,目标是在2023年12月之前量产。基于客户样本验证的初步反馈和沟通表明,与同类产品相比,这两项指标的表现均具有优异性,增强了我们对其
发表于 09-05 07:24

一文带你了解什么是机器视觉网卡
机器视觉网卡通常指的是在机器视觉系统中用于连接工业相机到计算机的以太网卡。它的核心作用是实现高速、稳定、低延迟的图像数据传输。以下是关于机器视觉网卡的关键信息:1.核心功能:高速图像传

EtherCAT科普系列(8):EtherCAT技术在机器视觉领域的应用
机器视觉是基于软件与硬件的组合,通过光学装置和非接触式的传感器自动地接受一个真实物体的图像,并利用软件算法处理图像以获得所需信息或用于控制机器人运动的装置。机器视觉可以赋予机器人及自动化设备获取外界

黑芝麻智能视觉与4D毫米波雷达前融合算法介绍
本文介绍了黑芝麻智能视觉与4D毫米波雷达前融合算法,通过多模态特征对齐和时序建模,显著提升逆光、遮挡等复杂场景下的目标检测精度,增强辅助驾驶安全性。
VLM(视觉语言模型)详细解析
的详细解析: 1. 核心组成与工作原理 视觉编码器 :提取图像特征,常用CNN(如ResNet)或视觉Transformer(ViT)。 语言模型 :处理文本输入/输出,如GPT、BE

全志视觉芯片V821接入DeepSeek和豆包视觉大模型
带来一款全志新的视觉芯片V821,通过网络接入的方式打通DeepSeek-R1满血版模型和豆包视觉大模型,并展示其语言和视觉交互的能力和多样性。
Fibocom AI Stack满足各种机器视觉应用需求
机器视觉作为AI应用的“智慧之眼”,正成为各行各业数字化转型的核心技术,广泛应用于工业自动化、智能安防、医疗诊断等各个领域。训练和优化目标检测、关键点检测、图像分割、超分辨率、图像增强、360环视

开源项目 ! 利用边缘计算打造便携式视觉识别系统
利用边缘计算打造便携式人工智能解决方案,面向开发者的视觉识别项目!
自制视觉识别系统
我们将深入探究一套堪称绝妙的软硬件组合,以助力开发者轻松构建便携式、高效的视觉识别装置。需要哪些
发表于 12-16 16:31
NaVILA:加州大学与英伟达联合发布新型视觉语言模型
日前,加州大学的研究人员携手英伟达,共同推出了一款创新的视觉语言模型——NaVILA。该模型在机器人导航领域展现出了独特的应用潜力,为智能机器人的自主导航提供了一种全新的解决方案。 视觉语言





 工商网监
工商网监
评论