 强化学习与智能驾驶决策规划
强化学习与智能驾驶决策规划

本文介绍了强化学习与智能驾驶决策规划。智能驾驶中的决策规划模块负责将感知模块所得到的环境信息转化成具体的驾驶策略,从而指引车辆安全、稳定的行驶。真实的驾驶场景往往具有高度的复杂性及不确定性。如何制定一套泛化能力强的决策规划机制是智能驾驶目前面临的难点之一。强化学习是一种从经验中总结的学习方式,并从长远的角度出发,寻找解决问题的最优方案。近些年来,强化学习在人工智能领域取得了重大突破,因而成为了解决智能驾驶决策规划问题的一种新的思路。
01.强化学习的介绍
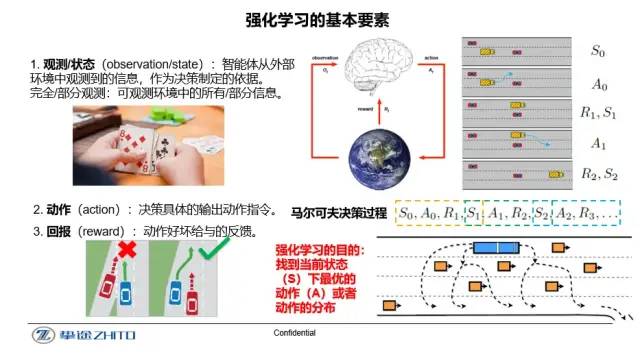
强化学习(Reinforcement Learning)近些年来是人工智能的一个前言领域,属于机器学习的一个重要分支。从定义上来讲,强化学习可以通过经验探索来学习到解决问题的最优策略,即累计回报值最大的动作选取策略。在没有任何初始经验的情况下,强化学习可以通过平衡探索未知动作的可能性,学习到解决问题的最优方法,从而达到自我学习的目的。因此,强化学习与其他机器学习算法的一个显著区别为不依赖初始人工标注数据集的大小,探索式的自我学习可大幅度的节省人力成本。近些年来,随着深度学习的迅速发展,将深度学习与强化学习相结合的深度强化学习成为人工智能研究的热门领域之一,并在游戏、控制等领域取得了令人瞩目的成就。
02.智能驾驶决策规划的任务

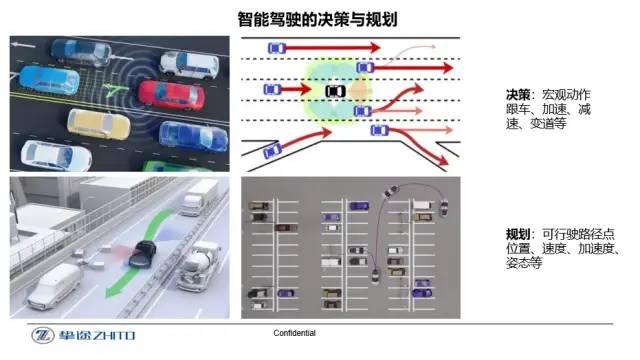
智能驾驶的主要目的是为人们提供安全、舒适及高效的出行体验。大多数的交通事故产生的原因来自于驾驶员人为因素,例如疲劳驾驶、情绪驾驶以及路况判断失误等。因此,合理的选择驾驶行为及路线规划是智能驾驶的一个重要环节。其中,行为决策负责在接收到全局路径后,根据从感知模块得到的环境信息(车辆速度、障碍物及道路信息等),做出具体的行为决策(如变道、跟车、减速等)。而规划的任务则是在接收到决策层的宏观动作指令之后,将其转化成一条更加具体的行驶轨迹,从而能够生成一系列控制信号(油门、方向盘转角、刹车等),实现车辆的自动行驶。如何应对不同的路况信息将做出合理的决策与规划是无人驾驶智能化的一个重要指标。
03.决策规划目前的难点
由于实际的交通场景千变万化,道路结构差异大(高速、十字路口、停车场等),如何去设计一套通用性强的决策规划机制是目前困扰着智能驾驶的一个主要难题。同时,其他交通参与者的行为存在不确定性,不仅需要对其行为做预测,还需要考虑本车与其他交通参与者的博弈。因此,需要对时刻变化的外部环境做出快速及准确的响应。如何应对感知模块提供的信息做不到100%的准确和100%的全覆盖也是智能车在决策规划时要考虑的重要因素。
04.强化学习对于智能驾驶决策规划的意义
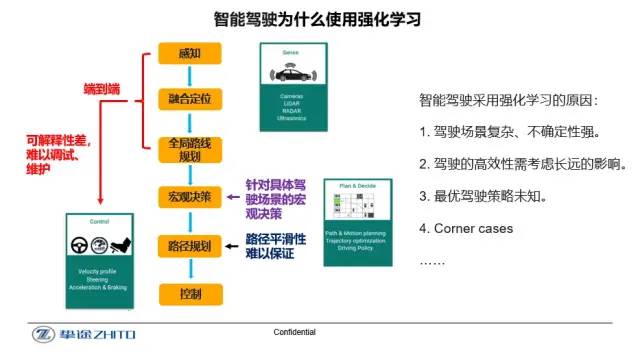
强化学习适用于求解具有时序性的决策问题,这正与智能驾驶的决策过程相契合。结合神经网络的深度强化学习框架可以增加驾驶场景的泛化能力。同时,考虑部分不可观测环境的强化学习流程可以评估交通参与者的不确定性,并通过预测与推演的方式从长远的角度出发来寻求最优的驾驶方案。更重要的是,强化学习由于其自身具有应对外部环境改变而产生进化的能力。当未知的corner case产生时,智能体可以通过改变自身的驾驶策略来适应并探索学习到解决该问题的方法。
-
人工智能
+关注
关注
1819文章
50298浏览量
266844 -
智能驾驶
+关注
关注
5文章
3037浏览量
51373 -
强化学习
+关注
关注
4文章
273浏览量
11996
原文标题:强化学习对于智能驾驶决策规划的意义
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
Momenta R6强化学习大模型上车东风日产NX8
Momenta强化学习大模型助力别克至境世家纯电版正式上市
Momenta R7强化学习世界模型即将推出
自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
如何训练好自动驾驶端到端模型?

今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
什么是自动驾驶决策系统?发展有何挑战?

自动驾驶中常提的“强化学习”是个啥?

无人驾驶:智能决策与精准执行的融合
18个常用的强化学习算法整理:从基础方法到高级模型的理论技术与代码实现




评论