 使用AXI CDMA制作FPGA AI加速器通道
使用AXI CDMA制作FPGA AI加速器通道

介绍
使用 AMD-Xilinx FPGA设计一个全连接DNN核心现在比较容易(Vitis AI),但是利用这个核心在 DNN 计算中使用它是另一回事。本项目主要是设计AI加速器,利用Xilinx的CDMA加载权重,输入到PL区的Block Ram。
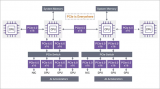
原理框图
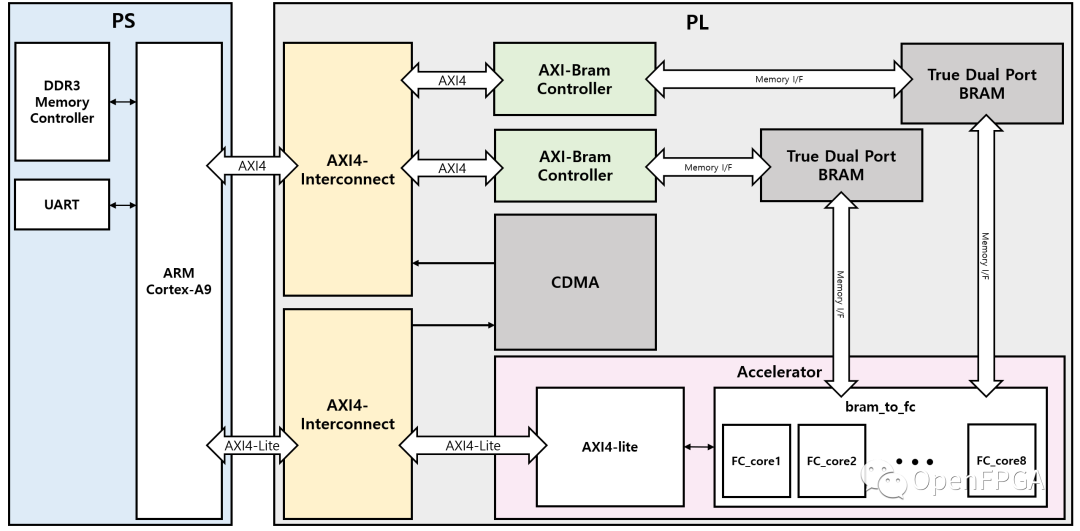
首先,我们创建了整个系统的示意图。有两个 Block RAW 分别用于存储输入特征和权重数据。每个Block RAM 都连接到一个 CDMA ,允许 DRAM 访问 Bram。每个 Block RAM 还连接到由 8 个 FCN 内核和 FSM 组成的主加速器,控制内核的操作。
完整的激活顺序如下:
在 DDR 内存中存储特征和权重。
使用CDMA 将这些数据分别发送到block ram1 和block ram2。
向 FC core 发送 activate 信号,进行 FCN 计算。
将结果存储在 blcok ram 中。
重复此过程,直到完成第一层前向传播。
重复整个过程,将输入链接到存储在Block RAM 中的结果。
码分多址
为了直接访问内存,我们使用了 cdma。可以在XIinx 网站上参考 xilinx turoial(https://www.xilinx.com/support/university/vivado/vivado-workshops/Vivado-adv-embedded-design-zynq.html)。
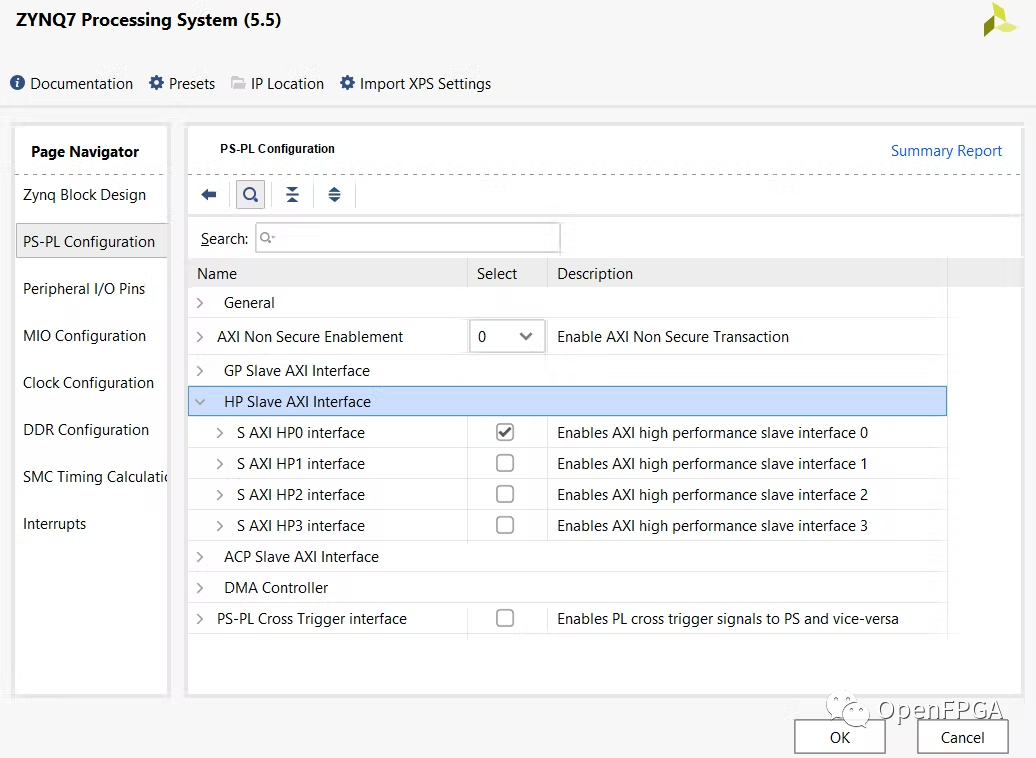
二、添加cdma和bram模块。Vivado 通过 Run Connection Automation 将 cdma 和 bram 连接到处理器。那么设计应该类似于下图。
加速器IP
加速器 IP 由 4 个源文件组成。
加速器:连接 AXI4-lite 模块和 bram_to_fc 模块。
AXI4-lite :它执行 AXI4-lite 接口将结果值从 PL 传输到 PS。并将 fsm 信号传输到 bram_to_fc 模块。
bram_to_fc :它从 bram0、bram1 接收特征图和权重,并将它们发送到 sumproduct_core。
sumproduct_core :它使用 8 位输入执行 sumproduct 计算。并返回 32 位输出。
创建 AXI4 外设来制作 AXI4-lite 模板。接口类型是lite版,制作 10 个寄存器。然后修改模板来制作 AXI4-lite 模块。
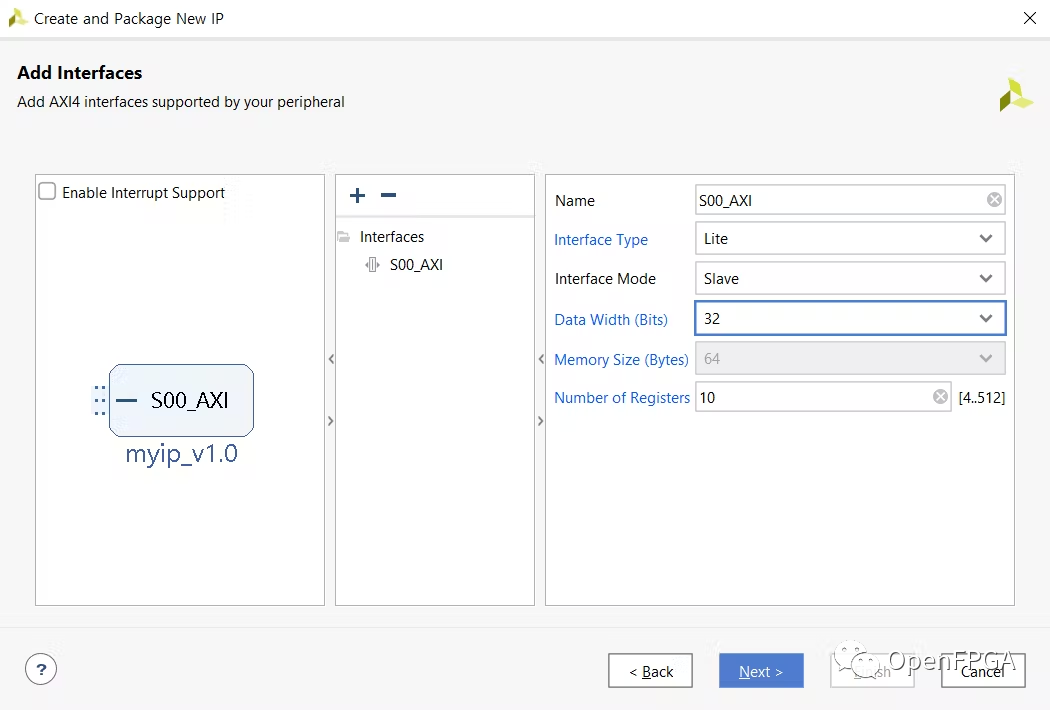
添加以上 4 个 Verilog 文件来生成加速器 IP。
Vivado Block设计
然后我们使用 VIVADO block digram 工具构建整个设计。我们使用具有 64 位数据宽度的双端口 bram 来最大化系统的效率。
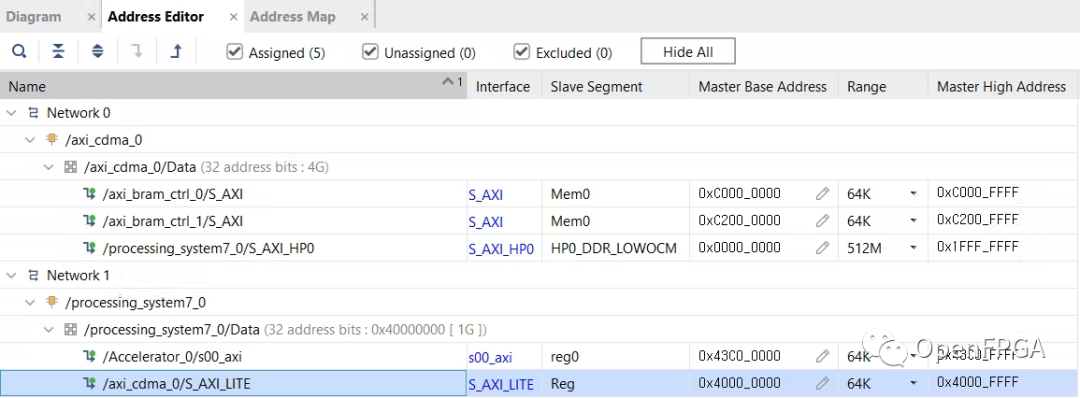
在地址编辑器中,将 axi_bram_ctrl 范围从 8k 更改为 64k。
测试
在 FPGA 板卡上测试了我们的加速器,将硬件导出到 VITIS,为了测试我们的加速器性能,我们比较了软件和硬件之间的相同任务运行时间。
HW运行时间:数据发送时间+HW计算时间+数据接收时间
SW runtime : SW计算时间
1. 使用 CDMA 将特征图和权重从 DDR3 传输到 BRAM。
//transferfeauturemapfromDDR3toBram0 XAxiCdma_IntrEnable(&xcdma,XAXICDMA_XR_IRQ_ALL_MASK); Status=XAxiCdma_SimpleTransfer(&xcdma,(u32)source_0,(u32)cdma_memory_destination_0,numofbytes,Example_CallBack,(void*)&xcdma); //transferweightfromDDR3toBram1 XAxiCdma_IntrEnable(&xcdma,XAXICDMA_XR_IRQ_ALL_MASK); Status=XAxiCdma_SimpleTransfer(&xcdma,(u32)source_1,(u32)cdma_memory_destination_1,numofbytes,Example_CallBack,(void*)&xcdma);
2. 发送 FSM 运行信号和要传输的输入数量。
Xil_Out32((XPAR_ACCELERATOR_0_BASEADDR)+(CTRL_REG*4),(u32)(numofbytes|0x80000000));
3. 检查硬件计算结果。
OT_RSLT_HW[0]=Xil_In64((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_0_REG*AXI_DATA_BYTE)); OT_RSLT_HW[1]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_1_REG*AXI_DATA_BYTE)); OT_RSLT_HW[2]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_2_REG*AXI_DATA_BYTE)); OT_RSLT_HW[3]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_3_REG*AXI_DATA_BYTE)); OT_RSLT_HW[4]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_4_REG*AXI_DATA_BYTE)); OT_RSLT_HW[5]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_5_REG*AXI_DATA_BYTE)); OT_RSLT_HW[6]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_6_REG*AXI_DATA_BYTE)); OT_RSLT_HW[7]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_7_REG*AXI_DATA_BYTE)); for(ii=0;ii<8; ii++){ printf("%d ", OT_RSLT_HW[ii]); }
4. 检查SW计算结果。
可以在下面看到测试结果。
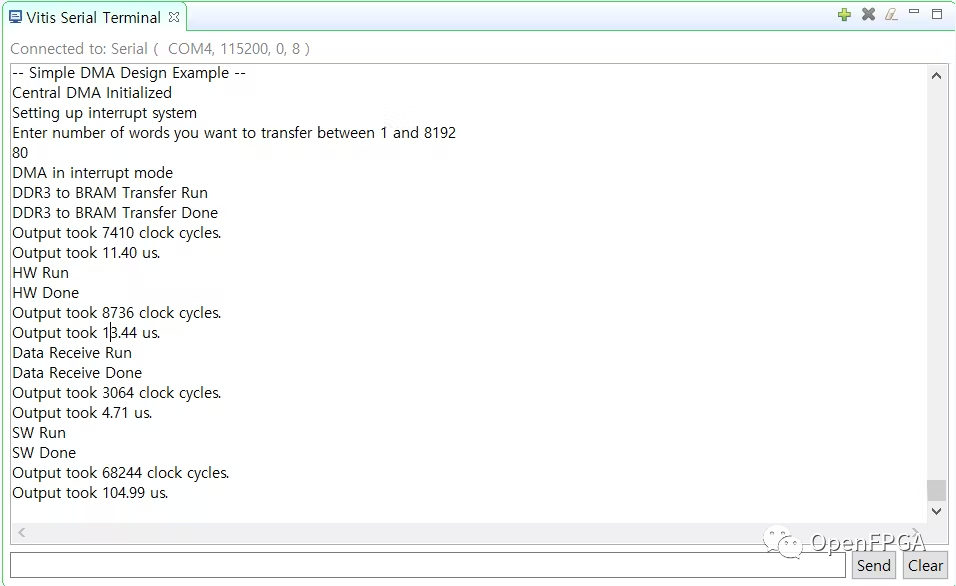
正如在这个结果中看到的那样,我们加速器的使用时间(11.40+13.44+4.71 us)比在 PS 区域(104.99 us)上要少得多。
代码
https://github.com/Hyunho-Won/cdma_accelerator
审核编辑:汤梓红
-
FPGA
+关注
关注
1655文章
22281浏览量
630049 -
amd
+关注
关注
25文章
5646浏览量
138997 -
加速器
+关注
关注
2文章
836浏览量
39708 -
AI
+关注
关注
89文章
38076浏览量
296300 -
AXI
+关注
关注
1文章
143浏览量
17781
原文标题:使用 AXI CDMA 制作 FPGA AI 加速器通道
文章出处:【微信号:Open_FPGA,微信公众号:OpenFPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
数据中心加速器就看GRVI Phalanx FPGA加速器

机器学习实战:GNN加速器的FPGA解决方案
使用AMD-Xilinx FPGA设计一个AI加速器通道
【书籍评测活动NO.18】 AI加速器架构设计与实现
《 AI加速器架构设计与实现》+第2章的阅读概括
优化基于FPGA的深度卷积神经网络的加速器设计
基于Xilinx FPGA的Memcached硬件加速器的介绍
基于FPGA的SIMD卷积神经网络加速器
什么是AI加速器 如何确需要AI加速器
如何采用带专用CNN加速器的AI微控制器实现CNN的硬件转换

PCIe在AI加速器中的作用
粒子加速器的加速原理是啥呢?
边缘计算中的AI加速器类型与应用






 工商网监
工商网监
评论