 小编科普一下超标量处理器中的Cache
小编科普一下超标量处理器中的Cache

超标量处理器中,Cache和分支预测会直接影响着性能,分支预测的内容将在其它博文中介绍,本文重点关注超标量处理器中的Cache。
Cache之所以存在,是因为存储器的速度远远滞后于处理器的速度,人们观察到在计算机的世界中,存在如下的两个现象:
时间相关性(temporal locality):如果一个数据现在被访问了,那么以后很有可能也会被访问;
空间相关性(spatial locally):如果一个数据现在被访问了,那么它周围的数据在以后可能也会被访问;
处理器中的各种cache示意如图1所示,现代超标量处理器都是哈佛结构,为了增加流水线的执行效率,L1 Cache一般都包括两个物理的存在,指令Cache(I-Cache)和数据Cache(D-Cache),本质上两者是一样的,I-Cache只会发生读情况,D-Cahce既可以读也可以写,所以更复杂点,L1 Cach紧密耦合在处理器的流水线中,主打功能就是求快。
L2通常是指令和数据共享,它和处理器的速度不必保持同样,可以容忍慢点,它存在的主要意义是尽量保存更多的内容,即求全。
在L1 Cache miss的情况下,会去访问L2 Cache,加入L2 Cache在缺失时去访问物理内存(一般是DRAM),这个访问时间很长,因此要尽可能地提高L2 Cache的命中率。
L1 Cache和L2 Cache是和处理器联系最紧密的,通常采用SRAM实现。物理主存Main memory通常是采用DRAM实现的。
再往下就是硬盘(Disk)和闪存(Flash)。层层嵌套,CPU拥有存储器相当于硬盘的大小和SRAM的速度。
L1 Cache和L2 Cache通常和处理器是在一块实现的。
在SoC中,主存和处理器之间通过总线SYSBUS连接起来。
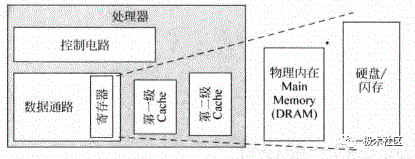
图1 处理器中的各种Cache
Cache主要由两部分组成,Tag部分和Data部分。因为Cache是利用了程序中的相关性,一个被访问的数据,它本身和它周围的数据在最近都有可能被访问,因此Data部分就是用来保存一片连续地址的数据,而Tag部分则是存储着这片连续地址的公共地址,一个Tag和它对应的所有数据Data组成一行称为Cache line,而Cache line中的数据部分成为数据块(Cache data block,也称做Cache block或Data block)。
如果一个数据可以存储在Cache的多个地方,这些被同一个地址找到的多个Cache line称为Cache set。
以上关系如图2所示。
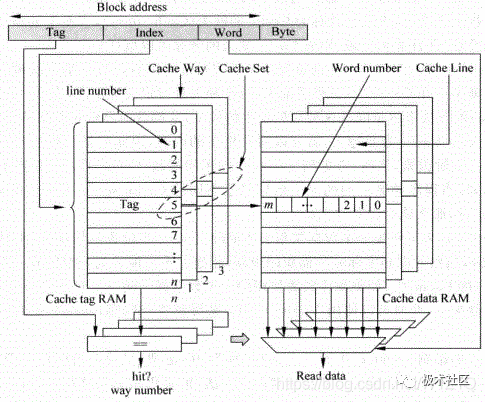
图2 Cache的结构
图2中只表示了一种可能的实现方式,在实际当中,Cache有三种主要的实现方式,直接映射(direct-mapped)Cache,组相连(set-associative)Cache和全相连(full-associative)Cache,实现原理如图3所示。
对于物理内存(physical memory)中的一个数据来说,如果在Cache中只有一个地方可以容纳它,它就是直接映射的Cache;如果Cache中有多个地方可以放置这个数据,它就是组相连的Cache;如果Cache中任何的地方都可以放置这个数据,那么它就是全相连的Cache。可以看出,直接映射和全相连映射这两种结构的Cache实际上是组相连Cache的两种特殊情况,现代处理器中的Cache一般属于上述三种方式的一种,例如TLB和Victim Cache多采用全相连结构,而普通的I-Cache和D-Cache则采用组相连结构等。
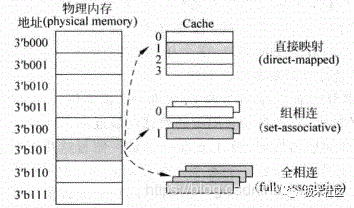
图3 Cache的三种实现方式
1. Cache的组成方式
1.1 直接映射
直接映射结构的Cache是最容易实现的一种方式,处理器访问存储器的地址会被分为三部分:Tag、Index和Block Offset。
如图4所示,使用Index来从Cache中找到一个对应的Cacheline,但是所有Index相同的地址都会寻址到这个Cacheline,因此在Cacheline中还有Tag部分,用来和地址中的Tag进行比较,只有它们相等才表明这个Cacheline就是想要的那个。
在一个Cacheline中有很多数据,通过存储器地址中的Block Offset部分可以找到真正想要的数据,它可以定位到每个字节。
在Cacheline中还有一个有效位(Valid),用来标记这个Cacheline是否保存着有效的数据,只有在之前被访问过的存储器地址,它的数据才会存在于对应的Cacheline中,相应的有效位也会被置为1。
直接映射有个缺点,就是对于所有Index相同的存储器地址,都会寻址到同一个Cacheline,如果两个Index部分相同的存储器地址交互地访问Cache,就会一直导致Cache缺失,严重地降低了处理器的执行效率。
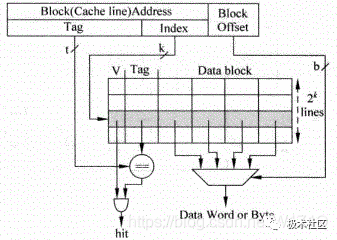
图4 直接映射Cache
1.2 组相连
组相连的方式是为了解决直接映射结构Cache的不足而提出的,存储器中的一个数据不单单只能放在一个Cacheline中,而是可以放在多个Cacheline中,对于一个组相连结构的Cache来说,如果一个数据可以放在n个位置,则称这个Cache是n路组相连的Cache(n way set-associative Cache),图5为一个两路组相连Cache的原理图。
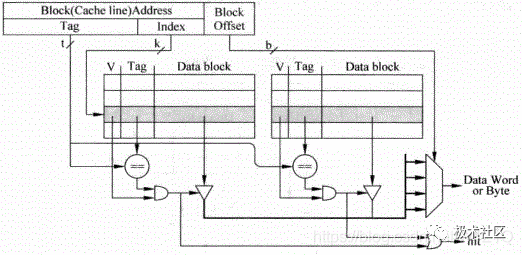
图5 2路组相连映射Cache
这种结构仍旧使用存储器地址的Index部分对Cache进行寻址,此时可以得到两个Cacheline,这两个Cacheline称为一个Cache set,究竟哪个Cacheline才是最终需要的,是根据Tag比较的结果来确定的,如果两个Cacheline的Tag比较结果都不相等,那么就说明这个存储器地址对应的数据不在Cache中,也就是发生了Cache缺失。
这种方式在实际处理器中应用最为广泛,上面提到的Tag部分和Data部分都是分开放置的,称为Tag SRAM和Data SRAM,可以同时访问这两部分。
图5所示为并行访问,如果先访问Tag SRAM部分,根据Tag比较的结果再去访问Data SRAM部分,就称为串行访问。
图6为并行访问方法的示意图,对于并行访问的结构,当某个地址的Tag部分被读取的同时,这个地址在Data部分对应的所有数据也会被读取出来,并送到一个多路选择器,这个多路选择器受到Tag部分比较结果的控制,选出对应的Data block,然后根据存储器地址中Block Offset的值,选择出合适的字节,一般将选择字节的这个过程称为数据对齐(Data Alignment)。 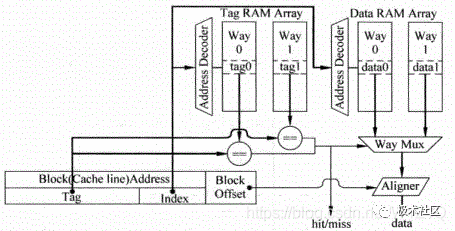
图6 并行访问Cache中的Tag和Data部分
如图7为串行访问实现方式,对于串行访问方法来说,首先对Tag SRAM进行访问,根据Tag比较的结果,就可以知道数据部分中,哪一路的数据时需要被访问的,此时可以直接访问这一路的数据,这样就不在需要图6中的多路选择器,而且,只需要访问数据部分指定的那个SRAM,其它的SRAM由于都不需要被访问,可以将它们的使能信号置为无效,这样可以节省很多功耗,当然串行访问在延迟上会更大。
图7 串行访问Cache中的Tag部分和Data部分
1.3 全相连
在全相连中,一个存储器地址的数据可以放在任何一个cacheline中,如图8所示,存储器地址中将不再有Index部分,而是直接在整个的Cache中进行Tag值比较,找到比较结果相等的那个Cache line,这种方式相当于直接使用存储器的内容来寻址,从存储器中找到匹配的项,这其实就是内容寻址的存储器( Content Address Memory, CAM),实际当中的处理器在使用全相连结构的Cache时,都是使用CAM来存储Tag值,使用普通的SRAM来存储数据的。
当CAM中的某一行被寻址到时,SRAM中对应的行(一般称为word line)也将会被找到,从而SRAM可以直接输出对应的数据。
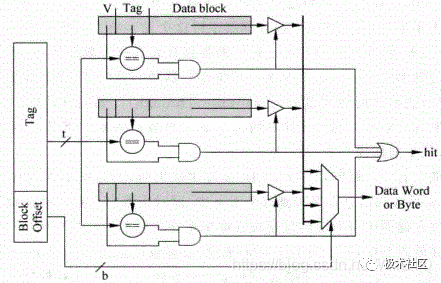
图8 全相连
2. Cache的写入
2.1 写通和写回
对于D-Cache来说,它的写操作和读操作有所不同,当执行一条store指令时,如果只是向D-Cache中写入数据,而并不改变它的下级存储器中的数据,这样就会导致D-Cache和下级存储器中,对于这一个地址有着不同的数据,这称作不一致(non-consistent)。
要想保持它们的一致性,最简单的方式就是当数据在写到D-Cache的同时,也写到它的下级存储器中,这种写入方式称为写通(Write Through)。
由于D-cache的下级存储器需要的访问时间相对是比较长的,而store指令在程序中出现的频率又比较高,如果每次执行store指令时,都向这样的慢速存储器中写入数据,处理器的执行效率肯定不会很高了。
如果在执行store指令时,数据被写到D-Cache后,只是将被写入的Cacheline做一个记号,并不将这个数据写到更下级的存储器中,只有当Cache中这个被标记的line要被替换时,才将它写到下级存储器中,这种方式就称为 写回(Write Back),被标记的记号在计算机术语中称为脏(dirty)状态,很显然,这种方式可以减少写慢速存储器的频率,从而获得比较好的性能。
当然,这种方式会造成D-Cache和下级存储器中有很多地址中的数据是不一致的,这会给存储器的一致性管理带来一定的负担。
2.2 Non-Write Allocate和Write Allocate
上面所讲述的情况都是假设在写D-Cache时,要写入的地址总是D-Cache中存在的,而实际当中,有可能发现这个地址并不在D-Cache中,这就发生了写缺失(write miss),此时最简单的处理方法就是将数据直接写到下级存储器中,而并不写到D-Cache中,这种方式称为Non-Write Allocate。
与之相对应的方法就是Write Allocate,在这种方法中,如果写Cache时发生了缺失,会首先从下级存储器中将这个发生缺失的地址对应的整个数据块(data block)取出来,将要写入到D-Cache中的数据合并到这个数据块中,然后将这个被修改过的数据块写到D-Cache中。
如果为了保持存储器的一致性,将这个数据块也写到下级存储器中,这种方法就是上小节说过的写通(Write Through)。
如果只是将D-Cache中对应的line标记为脏(Dirty)的状态,只有等到这个line要被替换时,才将其写回到下级存储器中,则这种方法就是前面提到的写回(Write Back)。
Write Allocate为什么在写缺失时,要先将缺失地址对应的数据块从下级存储器中读取出来,然后在合并后写到Cache中?
因为通常对于写D-Cache来说,最多也就是写入一个字,直接写入Cache的话,会造成数据块中的其它部分和下级存储器中对应的数据不一致,且是无效的,如果这个cacheline由于被替换而写回到下级存储器中时,就会使下级存储器中的正确数据被篡改。
通过上面的描述可以看出,对于D-Cache来说,一般情况下,写通(Write Through)总是配合Non-Write Allocate一起使用的,它们都是直接将数据更新到下级存储器中,这两种方法配合的工作流程如图9所示。 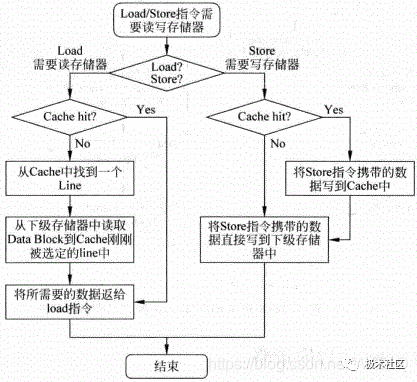
图9 Write Through和Non-Write Allocate两种方法配合工作的流程图
在D-Cache中,写回(Write back)的方法和Write Allocate也是配合在一起使用的,它的工作流程如图10所示。

图10 Write back和Write Allocate配合工作的流程图
由图10可以看出,在D-Cache中采用写回(Write back)的方法时,不管是读取还是写入时发生缺失,都需要从D-Cache中找到一个line来存放新的数据,这个被替换的line如果此时是脏(dirty)状态,那么首先需要将其中的数据写回到下级存储器中,然后才能够使用这个line存放新的数据。
也就是说,当D-Cache中被替换的line是脏的状态时,需要对下级存储器进行两次访问,首先需要将这个line中的数据写回到下级存储器,然后需要从下级存储器中读取缺失的地址对应的数据块,并将其写到刚才找到的Cache line中。
对于D-Cache来说,还需要将写入的数据也放到这个line中,并将其标记为脏的状态。
从图9和图10可以看出,采用写回和Write Allocate配合工作的方法,其设计复杂度要高于写通和Non-Write Allocate配合工作的方法,但是它可以减少写下级存储器的频率,从而使处理器获得比较好的性能。
3. Cache的替换策略
在一个Cache Set内的所有line都已经被占用的情况下,如果需要存放从下游存储器中读过来的其它地址的数据,那么就需要从其中替换一个,如何从这些有效的Cache line找到一个并替换之,这就是替换(Cache replacement)策略。本节主要介绍几种最常用的替换算法。
3.1 近期最少使用法
近期最少使用法(Least Recently Used, LRU)会选择最近被使用次数最少的Cache line,因此这个算法需要追踪每个Cache line的使用情况,这需要为每个Cache line都设置一个年龄(age)部分,每次当一个Cache line被访问时,它对应的年龄部分就会增加,或者减少其它Cache line的年龄值,这样当进行替换时,年龄值最小的那个Cacheline就是被使用次数最少的了,会选择它进行替换。
图11为LRU算法的工作流程。
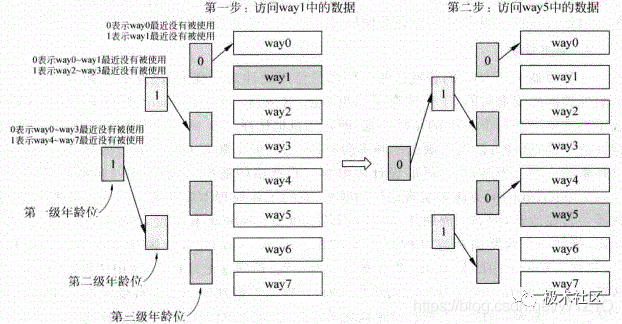
图11 LRU算法的工作流程
3.2 替换策略
在处理器中,Cache的替换算法一般都是使用硬件来实现的,因此如果做得很复杂,会影响处理器的周期时间,于是就有了随机替换(Random Replacement)的实现方法,这种方法不再需要记录每个way的年龄信息,而是随机地选择一个way进行替换,相比于LRU替换方法来说,这种方法确实的频率会更高一些,但是随着Cache容量的增大,这个差距是越来越小的。
当然,在实际的设计中很难实现严格的随机,一般采用一种称为时钟算法(Clock algorithm)的方法来实现近似的随机,它的工作原理本质上就是一个计数器,这个计数器一直在运转,例如每周期加1,计数器的宽度由Cache的相关度,也就是way的个数来决定,例如一个八路组相连的结构的Cache,则计数器的宽度需要三位,每次当Cache中的某个line需要被替换时,就会访问这个计数器,使用计数器当前的值,从被选定的Cache Set中找到要替换的line,这样就近似地实现了一种随机的替换,这种方法从理论上来说,可能并不能获得最优化的结果,但是它的硬件复杂度比较低,也不会损失过多的性能,因此综合来看是一种不错的折中方法。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20360浏览量
255481 -
存储器
+关注
关注
39文章
7764浏览量
172364 -
TLB电路
+关注
关注
0文章
9浏览量
5417 -
SRAM芯片
+关注
关注
0文章
67浏览量
12864
原文标题:学习分享|CPU Cache知识
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
什么是超标量处理器的流水线?超标量处理器的特点有哪些?
什么是超标量技术/FADD?
PowerPC芯片特点及超标量体系CPU优化技术
乱序超标量处理器核的功耗优化



评论