 一种基于new concepts的text-to-image生成模型的fine-tuning方法
一种基于new concepts的text-to-image生成模型的fine-tuning方法

2. 引言
最近通过文本生成图像的深度学习相关技术取得了非常大的进展,2021已经成为了图像生成的一个新的milestone,诸如DALL-E和Stable diffusion这种模型都取得了长足的进步,甚至达到了“出圈”的效果。通过简单文本prompts,用户能够生成前所未有的质量的图像。这样的模型可以生成各种各样的对象、风格和场景,并把它们进行组合排序,这让现有的图像生成模型看上去是无所不能的。

但是,尽管这些模型具有多样性和一些泛化能力,用户经常希望从他们自己的生活中合成特定的概念。例如,亲人、朋友、宠物或个人物品和地点,这些都是非常有意义的concept,也和个人对于生成图像的信息有对齐。由于这些概念天生就是个人的,因此在大规模的模型训练过程中很难出现。
事后通过详细的文字,来描述这种概念是非常不方便的,也无法保留足够多的视觉细节来生成新的personal的concepts。这就需要模型具有一定的“定制”能力。也就是说如果给定少量用户提供的图像,我们能否用新概念(例如宠物狗或者“月亮门”,如图所示)增强现有的文本到图像扩散模型?经过微调的模型应该能够将它们与现有概念进行概括并生成新的变化。这带来了几个比较严峻的挑战:
首先,模型倾向于遗忘现有概念的含义:例如,在添加“moon gate”这一concept的时候,“moon”的含义就会丢失。
其次,由于stable diffusion这样的网络往往参数会超级多,所以在小数据上训练模型,容易造成对训练样本进行过拟合,而且采样中变化也有限。
此外,论文还关注了一个更具挑战性的问题,即组group fine-tuning,即能够超越单个个体concept的微调,并将多个概念组合在一起。学习多个新的concepts同时也是存在一定的挑战的,比如 concept mixing以及concept omission。
在这项工作中,论文提出了一种fine-tuning技术,即文本到图像扩散模型的“定制扩散”。我们的方法在计算和内存方面都很有效。为了克服上述挑战,新方法固定一小部分模型权重,即文本到潜在特征的key值映射在cross-attention layer中。fine-tuning这些足以更新模型的新concepts。
为了防止模型丧失原来强大的表征能力,新方法仅仅使用一小组的图像与目标图像类似的真实图像进行训练。我们还在微调期间引入data的augamation,这可以让模型更快的收敛,并获得更好的结果。论文提出的方法实验是构建在Stable Diffusion之上,并对各种数据集进行了实验,其中最少有四幅训练图像。
对于添加单个concept,新提出的方法显示出比相似任务的作品和基线更好的文本对齐和视觉相似性。更重要的是,我们的方法可以有效地组成多个新concepts,而直接对不同的concepts进行组合的方法则遇到困难,经常会省略一个。最后,我们的方法只需要存储一小部分参数(模型权重的3%),消耗的GPU memory非常有限,同时也减少了fine-tuning的时间。
3. 方法
总结来讲,论文提出的方法,就是仅更新权重的一小部分,即模型的交叉注意力层。此外,由于目标概念的训练样本很少,所以使用一个真实图像的正则化集,以防止过拟合。
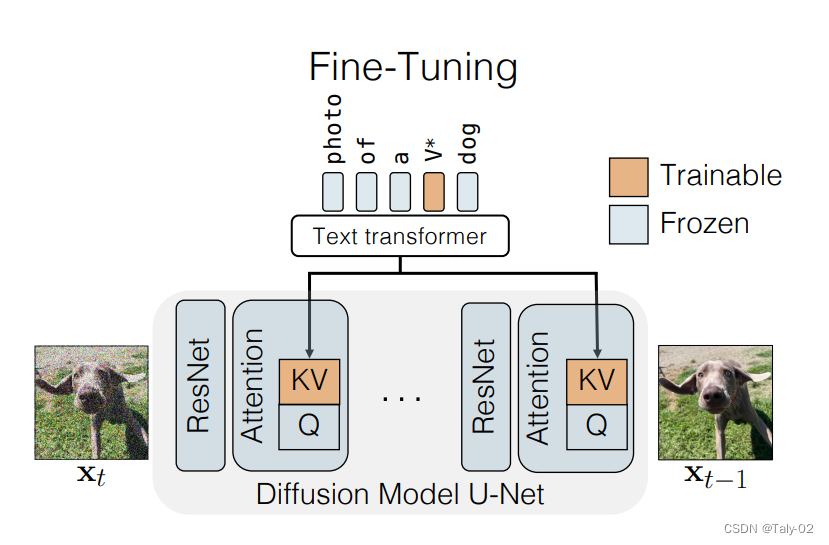
对于Single-Concept Fine-tuning,给定一个预训练的text-to-image diffusion model,我们的目标是在模型中加入一个新的concept,只要给定四张图像和相应的文本描述进行训练。fine-tuning后的模型应保留其先验知识,允许根据文本提示使用新概念生成新的图像类型。
这可能具有挑战性,因为更新的文本到图像的映射可能很容易过拟合少数可用图像。所以保证泛化性就非常有必要,也比较有挑战。所以就仅仅fine-tuning新的K和V,而对于query,则保持不变,这样就可以增加新概念的同时,保证模型的表征能力不受到太多的影响。优化目标还是diffusion的形式:
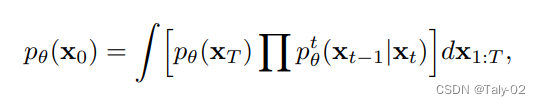
概括起来实际上非常简单,就是训练一个k和v的矩阵,来扩充维度,增加模型的表征能力,使其能生成更为丰富的图像内容。
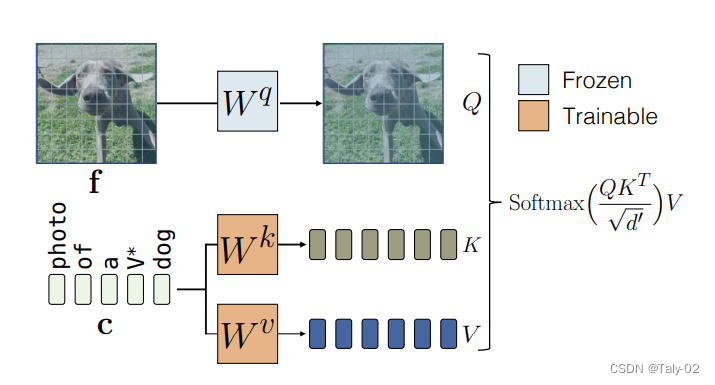
而对于Multiple-Concept Compositional Fine-tuning,为了对多个概念进行微调,我们将每个概念的训练数据集合并,并使用我们的方法将它们联合训练。为了表示目标概念,我们使用不同的修饰符的,并将它们与每个层的交叉注意关键和值矩阵一起初始化,并优化它们。通过将权重更新限制为交叉注意key和value参数,与DreamBooth等方法相比,可以显着更好地将两个概念合并在一起。


可以发现,增加约束还是让模型具有更强的表征能力的。最下面一行才和真正的门比较相似,同时生成的月亮也非常合理。
4. 实验

给定一个新concepts的图像如左侧显示的目标图像,提出的方法可以在看不见的上下文和艺术风格中生成带有该概念的图像。
第一行:代表水彩画艺术风格中的概念。方法还可以在背景中生成山脉,而 DreamBooth 和 Textual Inversion 忽略了这一点。
第二行:改变背景场景。我们的方法和 DreamBooth 的表现与 Textual Inversion 相似且更好。
第三行:添加另一个对象,例如带有目标桌子的橙色沙发。新的方法成功地添加了另一个对象。第四行:改变对象属性,如花瓣的颜色。第五行:用太阳镜装饰私人宠物猫。我们的方法比基线更好地保留了视觉相似性,同时仅更改花瓣颜色或为猫添加太阳镜。

可以发现Multiple-Concept Compositional Fine-tuning的效果也非常惊艳。

风格迁移的效果也不错。
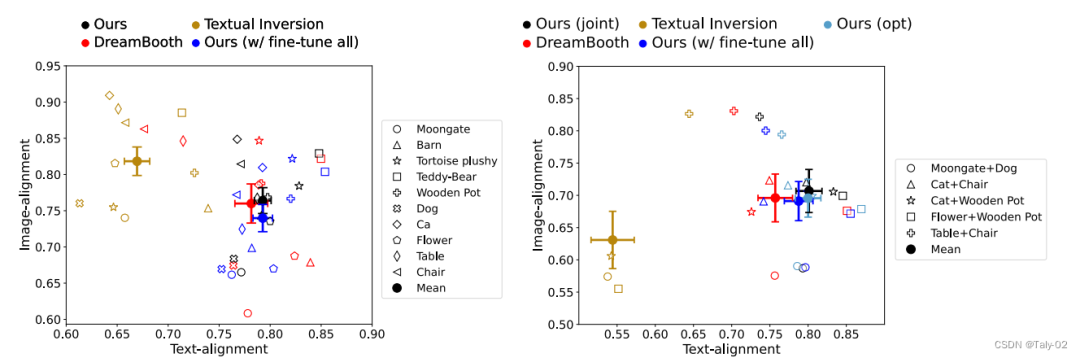
定量指标也有比较有竞争力的表现:
5. 结论
论文提出了一种基于new concepts的text-to-image生成模型的fine-tuning方法。只需使用一些有限的图像示例, 新方法就能一高效的方法生成微调概念的新样本同时保留原有的生成能力。而且,我们只需要保存一小部分模型权重。此外,方法可以连贯地在同一场景中组合多个新概念,这是之前的方法所缺少的能力。
审核编辑:刘清
-
gpu
+关注
关注
28文章
5335浏览量
136248
原文标题:如何简单高效地定制自己的文本作画模型?
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Text2SQL智能体基础到实战
将 MCUX SDK LIN 堆栈集成到 Zephyr OS 中,是否有一种方法可以自动生成它们从 .ldf 文件?
沐曦股份曦云C系列GPU产品Day 0适配百度文心ERNIE-Image文生图模型
昆仑万维天工AI大模型SkyReels V4登上Artificial Analysis榜单全球第一

使用Firebase AI Logic生成图像模型的两种新功能
【CIE全国RISC-V创新应用大赛】+ 一种基于LLM的可通过图像语音控制的元件库管理工具
拼多多商品推广链接生成API:社交裂变的转化追踪利器

上海控安:基于模型的测试用例生成
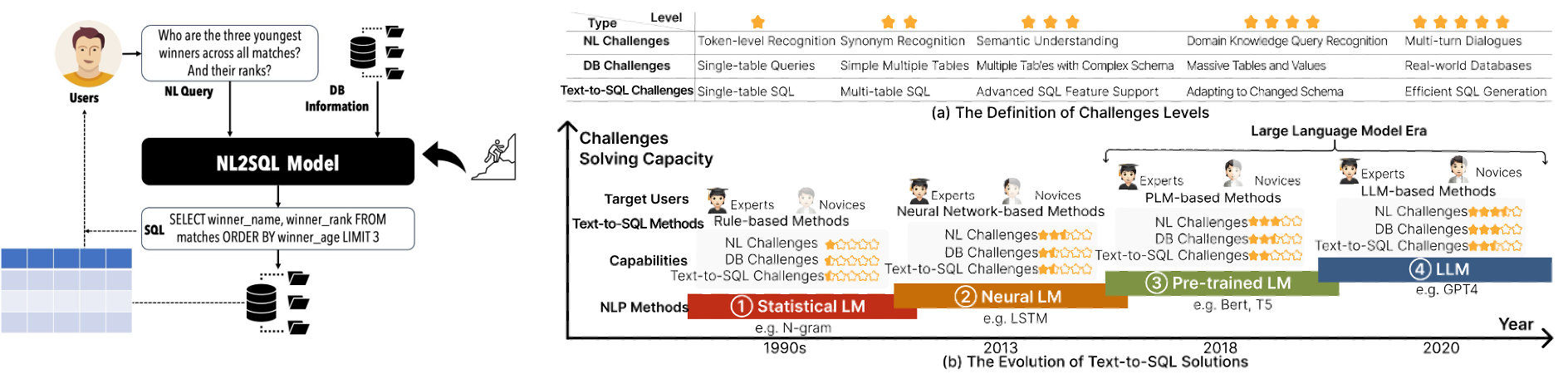
Text2SQL准确率暴涨22.6%!3大维度全拆
一种新的无刷直流电机反电动势检测方法
一种新的无刷直流电机反电动势检测方法
Hyperabrupt Junction Tuning 变容二极管 skyworksinc

Hyperabrupt Junction Tuning Varactor skyworksinc
一种基于扩散模型的视频生成框架RoboTransfer




评论