 基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线 第二篇
基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线 第二篇

作者:杨亦诚
前文回顾
基于OpenVINO 2022.2与oneAPI构建GPU视频分析服务流水线-第一篇
任务背景
在 Part 1 部分我们已经讨论了如何在英特尔 GPU 设备上利用 oneVPL 和 OpenVINO构建一个简单的视频分析流水线服务,但是在真实的工程环境中,为了能进一步“压榨”边缘设备有限硬件资源,降低项目成本,单台 AI Box 往往需要接入不止一路的视频分析任务,并同时进行解码与推理,这种情况如何优化多任务进程下的 AI 分析性能也成为了另外一大挑战。
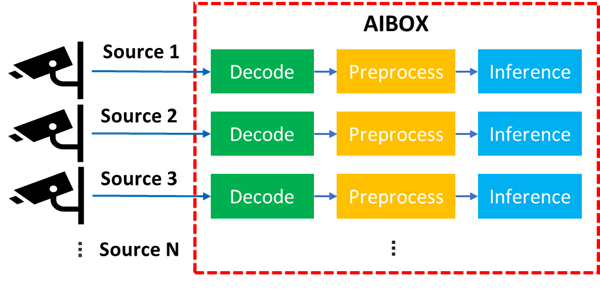
图:AI Box 多通道处理示意图
首先,我们来看一下多通道视频分析任务的优化方向,这里有两个非常重要概念:延迟 or 吞吐量?
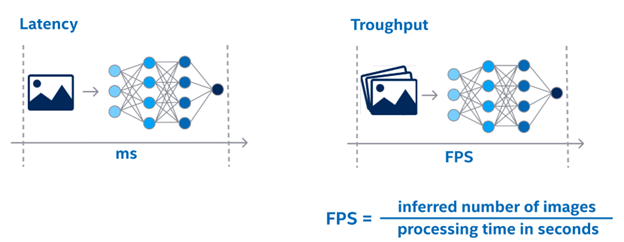
图:延迟和吞吐量对比说明
·延迟(Lantency),是指在处理单帧任务时所消耗的总时间;
·吞吐量(Throughput),是指在单位时间内所能处理的任务总量。
鉴于单通道视频分析任务中,视频源中的每一帧是以流水线这样的形式(一个接一个one by one)被送入到视频分析服务中,前后两帧存在时间上的依赖关系,理论上我们在同一时刻内只需要处理一帧画面的推理任务,因此这个时候我们更多是以延迟作为它的优化方向。但在多通道情况下,通道之间的数据往往没有相关性,我们需要在单位时间内尽可能的去处理更多通道的数据,在这种情况下,我们把吞吐量作为性能的主要优化方向,而提升吞吐量最好的方法就是提升多任务的并行性,减少单一任务多线程间由于数据同步带来的额外开销。
OpenVINO 推理并行优化方案
在谈到 OpenVINO 的并行优化方案的时候,这里有几个关键的配置参数不得不提一下:
· Thread:硬件系统可分配的最小并行执行单位,在 CPU 和 GPU 上,这个数字分别和 CPU 的核心数和 GPU 的 EU(Execution Unit)数相挂钩。
· Stream:OpenVINO对于多 Thread 的管理单元,OpenVINO可以将一个或多个 Thread 封装为一个 Stream,多个 Stream 中的推理任务可以并行执行,且平均分配 Thread 总数。
· Infer Request:推理任务的承载实例,每个 Infer Request 在执行过程中会被单独分配到一个 stream 中。
· Batch size:将 Batch size 个输入数据打包成在一起,送入 infer request 中进行推理,下图展示的是 Batch size 为一的情况(每个 infer request 中只有一个 input image )。
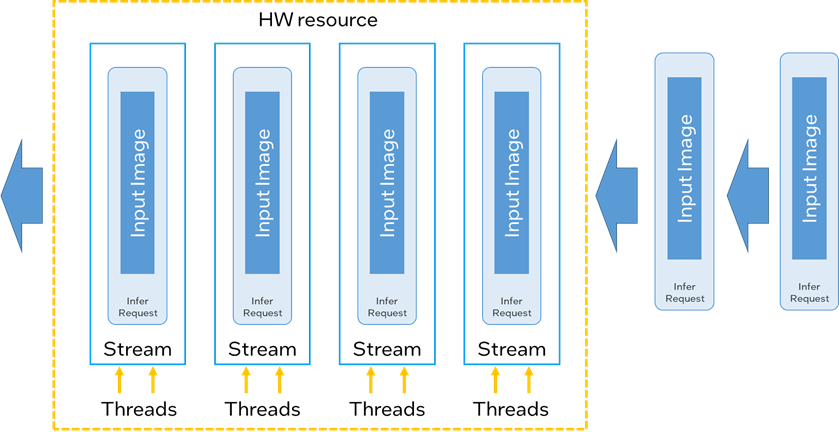
图:Thread, Stream, Infer request 关系说明
可以看到OpenVINO中的 Stream 更像是一个并行执行的推理任务队列,当其中的一个 infer request 完成推理后,这个闲置出的 stream 才能去加载下一个 infer request 推理任务。因此在实际开发过程中,我们需设置 infer request 的数量大于 stream 数量,确保在空闲 infer reques 在完成数据载入后,会被不间断地被送入空闲的 stream 中。
这里做个不一定恰当的比喻,stream 好比是工位,infer request 好比是工人,工人只有坐在工位上才能工作,没有工位的工人只能等到前面的工人完成作业后,才能坐进工位进行工作。但与此同时我们要确保那些没有工位的工人在等待的过程中要做好充足的准备,比如准备好工具(加载输入数),这样一旦坐进工位后,就立马可以开动干活。
大家可以通过OpenVINO自带的 benmark_app 性能基准工具对这三个参数进行配置,分别测试在不同配置情况下,对于实际性能的影响。
benchmark_app -m MODEL_DIR -nstreams NUMBER_STREAMS -nthreads NUMBER_THREADS -nireq NUMBER_INFER_REQUESTS --b BATCH_SIZE
向右滑动查看完整代码
为实现 Infer request 并行化的目标,OpenVINO中特别提供了一组异步推理接口。在使用异步接口进行推理时。推理线程采用非阻塞模式,这也意味这个你可以同时开启多个推理请求并行执行,或是在处理单个推理任务的过程中,之前其他前后处理任务。相较同步 API,异步 API 可以尽可能的提升设备资源的利用率。
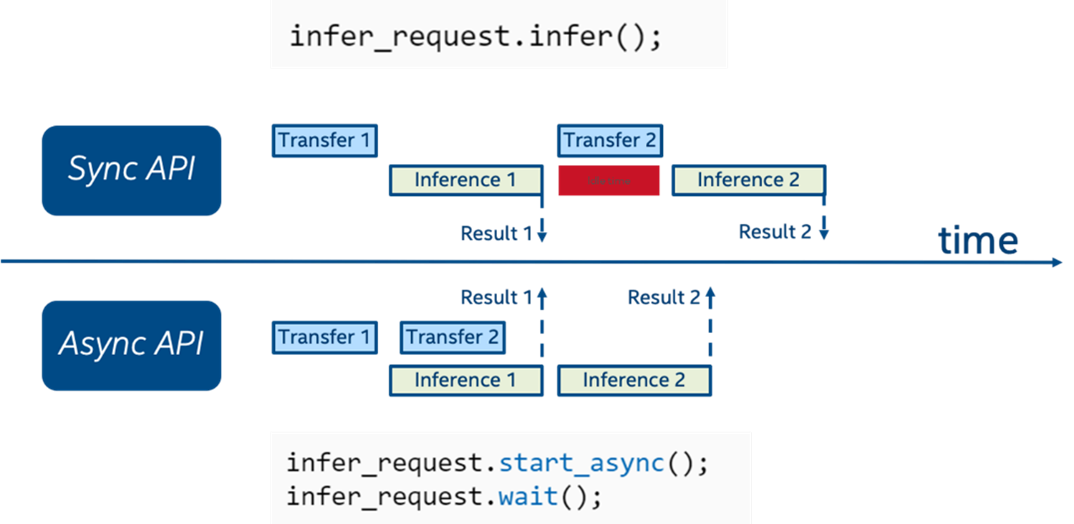
图:同步与异步 API 比较
回到多通道视频流分析优化这个主题上,为了提升多任务的并行化率,我们目前主要有以下两种优化策略,这里的 batching 是指我们提前将多个输入数据按次序叠加在一起,同时送进 infer request 中进行推理,并在获取结果后对他们进行拆分,同样可以达到数据并行的目的:
· 小 Batch size 配大 Stream number
· 大 Batch size 配小 Stream number
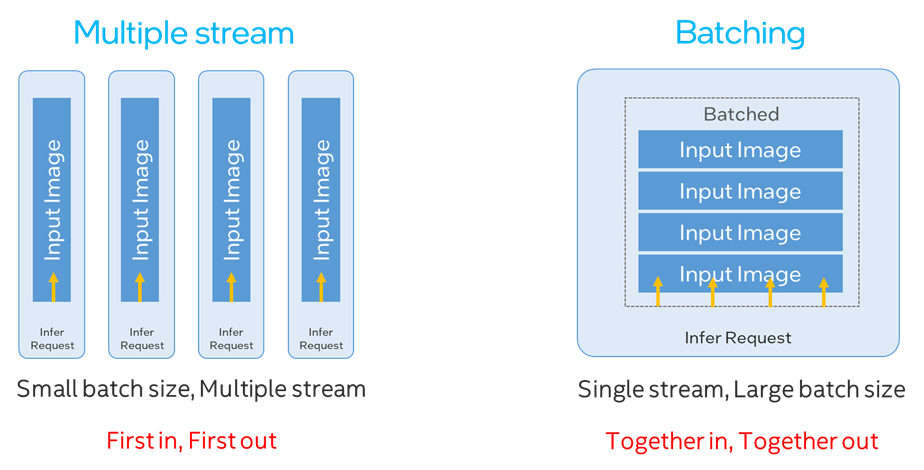
图:Multiple stream和Batching方案比较
这两种方案在 GPU 上各有不同的优缺点。首先就小 Batch size 配大 stream number 来说,由于不同的 stream 之间没有依赖性,所以先开始推理的 infer request 就可以先获得结果数据,适合对单帧数据推理延时比较敏感的场景,但同样问题也显而易见,由于每个 stream 的 OpenCL 队列是需要通过单独 CPU 线程来维护,并通过轮询机制来获取结果数据,因此这也造成了对 CPU 额外的资源开销,GPU stream 数越高,CPU 资源占用也越大。
而大 Batch size 配小 stream number 则没有这样的烦恼,可以最大化减少 CPU 上的开销。但因为我们需要将多个 input 打包,所以先完成解码的数据会和后完成解码的数据一起送入 infer request 中进行推理,并同时返回结果,所以对时延敏感的任务并不友好。
针对 GPU 吞吐量这一优化目标而言,利用 benchmark_app 实测发现,在 stream 数量达到一个瓶颈后,则对对吞吐量提升没有任何帮助,而通过增加 batch size 方式对于吞吐量性能的提升更为显著,因此在该方案中,我们将采用大 batch 配小 stream 的方式来优化性能。
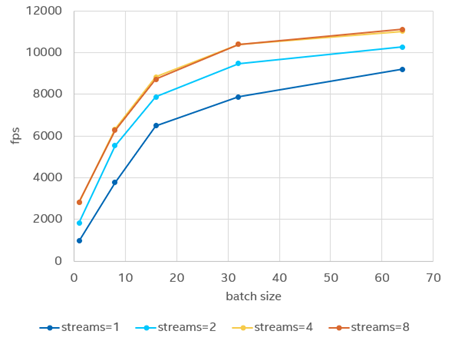
图:比较不同stream和batch size配置下对于GPU性能的影响
(非官方数据,仅供趋势参考)
方案设计
这里我们用来做演示的多通道视频分析服务主要会分为两个部分,分别对应了 oneVPL 和OpenVINO这两个工具组件。
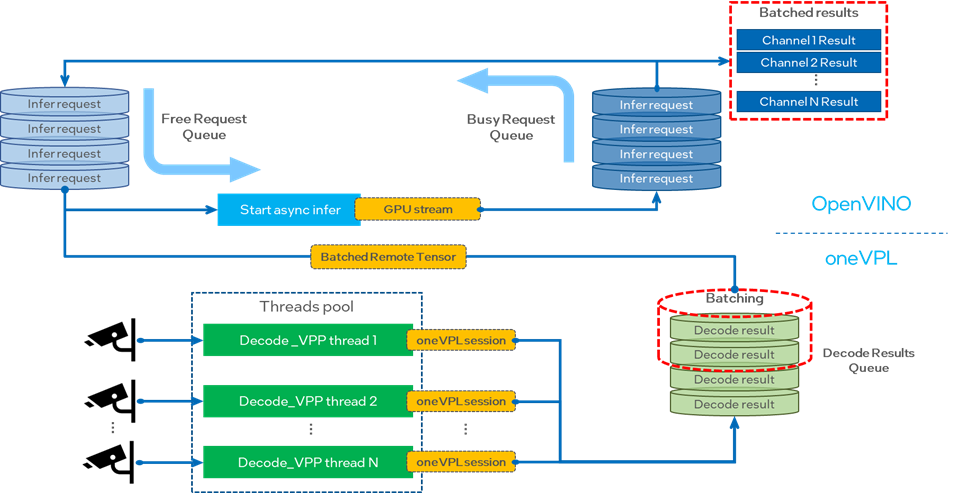
图:多通道视频处理服务示例流程图
1. 视频处理部分
视频处理部分我们需要使用 oneVPL 完成每一个通道数据的解码和前处理任务,并将结果按次序送入解码结果队列(Decode results queue)中,等待后面的 AI 处理部分进行调用。为了提高任务的并行度,我们需要为每个通道的视频处理任务单独配置一个 CPU 线程,此外由于 oneVPL 的每个 session 只能处理一个数据源示例,因此我们同样也要为每个视频源单独创建一个独立的 session 来进行 decode 和 VPP 处理。
在返回结果数据时,我们希望队列中的数据可以被存储在通道间共享的 GPU surface 内存中,方便OpenVINO的 remote tensor 进行调用,但实际上每次初始化 oneVPL session 以后,都会生成一个新的内存 handle 句柄对象,所以我们要通过 MFXVideoCORE_SetHandle 强制为每个 session 配置相同的handle句柄。
MFXVideoCORE_SetHandle 配置 handle
sts = MFXVideoCORE_SetHandle(session,
static_cast(MFX_HANDLE_VA_DISPLAY),
va_dpy);
向右滑动查看完整代码
2. AI 推理部分
AI 推理部分是本次分享的重头戏,首先我们需要分别创建两个队列用来存放开启推理任务的 busy infer request,以及空闲的 free infer request,在空闲的 infer request 中提前载入经过 oneVPL 处理以后的结果数据,等待 busy infer request 完成推理后,再送入 stream 中进行推理, 而 busy infer request 则会在输出结果数据,转变为 free infer request,被送入到 free request 队列中,并从 oneVPL 的结果队列中取出第一组等待被推理的解码结果。通过这种机制我可以确保 stream 中会源源不断有 infer request 被执行。
创建 free request 队列
BlockingQueue free_requests; for (int i = 0; i < FLAGS_nr; i++) free_requests.push(compiled_model.create_infer_request());
向右滑动查看完整代码
从 busy request 队列中的 infer request 取出推理结果数据, 并压入 free request 队里
for (;;) {
auto res = busy_requests.pop();
auto batched_frames = res.first;
auto infer_request = res.second;
if (!infer_request)
break;
infer_request.wait();
ov::Tensor output_tensor = infer_request.get_output_tensor(0);
PrintMultiResults(output_tensor, batched_frames, input_shape);
// When application completes the work with frame surface, it must call release to avoid memory leaks
for (auto frame : batched_frames)
{
frame.first->FrameInterface->Release(frame.first);
}
free_requests.push(infer_request);
}
向右滑动查看完整代码
此外在为每个 free infer request 加载解码结果数据之前,我们还需要进行 batching 的操作,将多个 decode result 队列当中的前n个数据打包成一个 batch,再进行推理。大家可以根据自己 GPU 的机能选择合适的 batch size,理论上 batch size 越大带来的吞吐量提升也越大,但受限于 GPU 上的内存资源有限,过大的 batch size 反而会造成性能瓶颈,因此 batch size 的大小尽量以实测为准。当然如果嫌测试麻烦,OpenVINO 2022.1的版本中也更新的 auto-batching 功能,该功能会根据 GPU 的硬件资源能力和实际任务负载,自动配置为 GPU 配置 batch size 大小,提供相对最优的配置参数。具体说明详见:
https://docs.openvino.ai/latest/openvino_docs_OV_UG_Automatic_Batching.html#doxid-openvino-docs-o-v-u-g-automatic-batching:
将多个解码结果打包为一个batch
for (auto va_surface : batched_frames)
{
mfxResourceType lresourceType;
mfxHDL lresource;
va_surface.first->FrameInterface->GetNativeHandle(va_surface.first,
&lresource,
&lresourceType);
VASurfaceID lvaSurfaceID = *(VASurfaceID *)(lresource);
auto nv12_tensor = shared_va_context.create_tensor_nv12(shape[2], shape[3], lvaSurfaceID);
y_tensors.push_back(nv12_tensor.first);
uv_tensors.push_back(nv12_tensor.second);
}
向右滑动查看完整代码
参考示例使用方法
本示例已开源,并在 Ubuntu 20.04 操作系统,第十一代英特尔 酷睿 iGPU 及 ARC A380 dGPU 环境下进行了验证。
1. 依赖安装及编译
可以参考 github 中的 README 文档完成以来安装和源码编译:
https://github.com/OpenVINO-dev-contest/decode-infer-on-GPU
2. 运行输出
当完成可执行文件编译后,可以按以下规则运行多通道版本的示例
$ ./multi_src/multi_source -i ../content/cars_320x240.h265,../content/cars_320x240.h265,../content/cars_320x240.h265 -m ~/vehicle-detection-0200/FP32/vehicle-detection-0200.xml -bz 2 -nr 4 -fr 30
向右滑动查看完整代码
其中可配置参数为:
-i = .h265格式的输入视频路径,多视频源之间用逗号隔开
-m = IR .xml 格式 IR 模型文件路径;
-bs = Batch size 大小;
-nr = Inference requests 数量;
-fr = 单个视频源的解码帧数,默认前30帧;
输出结果示意如下图,该示例会为按预先设置的 batch size 大小输出对应结果,此处 batch size 为2:
libva info: VA-API version 1.12.0 libva info: Trying to open /opt/intel/mediasdk/lib64/iHD_drv_video.so libva info: Found init function __vaDriverInit_1_12 libva info: va_openDriver() returns 0 Implementation details: ApiVersion: 2.7 Implementation type: HW AccelerationMode via: VAAPI Path: /usr/lib/x86_64-linux-gnu/libmfx-gen.so.1.2.7 Frames [stream_id=1] [stream_id=0] image0: bbox 204.99, 49.43, 296.43, 144.56, confidence = 0.99805 image0: bbox 91.26, 115.56, 198.41, 221.69, confidence = 0.99609 image0: bbox 36.50, 44.75, 111.34, 134.57, confidence = 0.98535 image0: bbox 77.92, 72.38, 155.06, 164.30, confidence = 0.97510 image1: bbox 204.99, 49.43, 296.43, 144.56, confidence = 0.99805 image1: bbox 91.26, 115.56, 198.41, 221.69, confidence = 0.99609 image1: bbox 36.50, 44.75, 111.34, 134.57, confidence = 0.98535 image1: bbox 77.92, 72.38, 155.06, 164.30, confidence = 0.97510 Frames [stream_id=1] [stream_id=0] image0: bbox 206.96, 50.41, 299.54, 146.23, confidence = 0.99805 image0: bbox 93.81, 115.29, 200.86, 222.94, confidence = 0.99414 image0: bbox 84.15, 92.91, 178.14, 191.82, confidence = 0.99316 image0: bbox 37.78, 45.82, 113.29, 132.28, confidence = 0.98193 image0: bbox 75.96, 71.88, 154.31, 164.54, confidence = 0.96582 image1: bbox 206.96, 50.41, 299.54, 146.23, confidence = 0.99805 image1: bbox 93.81, 115.29, 200.86, 222.94, confidence = 0.99414 image1: bbox 84.15, 92.91, 178.14, 191.82, confidence = 0.99316 image1: bbox 37.78, 45.82, 113.29, 132.28, confidence = 0.98193 image1: bbox 75.96, 71.88, 154.31, 164.54, confidence = 0.96582 ... decoded and infered 60 frames Time = 0.328556s
向右滑动查看完整代码
小结
通过 batching 以及多线程的方式,我们可以进一步提升多数据源任务处理时,GPU 在吞吐量性能上的优势,并且降低 CPU 侧的任务负载。随着越来越多的英特尔独立显卡系列产品的推出,相信这样一套参考设计帮助开发者在 GPU 平台上实现更出色的性能表现。
-
英特尔
+关注
关注
61文章
10276浏览量
179370 -
gpu
+关注
关注
28文章
5105浏览量
134489 -
流水线
+关注
关注
0文章
127浏览量
27124
原文标题:基于OpenVINO™ 2022.2与oneAPI构建GPU视频分析服务流水线 第二篇
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
流水线基本结构
如何更好地选择工业流水线上用的条码扫码器?

二维码扫描读码器在工厂流水线的应用

流水线扫码升级选NVF230!工业二维码读码器方案实测

自动化开装封码流水线数据采集解决方案
面包成型流水线数据采集远程监控系统

远程io模块在汽车流水线的应用
工业4.0时代,为什么你的流水线必须配备固定式扫码器?

工业流水线上用的条码扫码器,如何选择与使用?

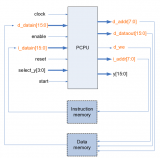
RISC-V五级流水线CPU设计
请问使用2022.2时是否可以读取模型OpenVINO™层?
为什么无法在RedHat中构建OpenVINO™ 2022.2?
利用OpenVINO和LlamaIndex工具构建多模态RAG应用

工业二维码条码扫描器流水线条码扫描






 工商网监
工商网监
评论