 总结过去三年,MIT发布AI加速器综述论文
总结过去三年,MIT发布AI加速器综述论文

过去几年,关于人工智能和机器学习加速器的发展进行到哪一阶段了?来自 MIT 的研究者通过一篇综述性文章总结了过去三年关于 AI 加速器和处理器的调查。
过去这一年,无论是初创公司还是成熟大厂,预告、发布和部署人工智能(AI)和机器学习(ML)加速器的步伐很缓慢。但这并非不合理,对于许多发布加速器报告的公司来说,他们花三到四年的时间研究、分析、设计、验证和对加速器设计的权衡,并构建对加速器进行编程的技术堆栈。对于那些已发布升级版本加速器的公司来说,虽然他们报告的开发周期更短,但至少还是要两三年。这些加速器的重点仍然是加速深层神经网络(DNN)模型,应用场景从极低功耗嵌入式语音识别和图像分类到数据中心大模型训练,典型的市场和应用领域的竞争仍在继续,这是工业公司和技术公司从现代传统计算向机器学习解决方案转变的重要部分。
人工智能生态系统将边缘计算、传统高性能计算(HPC)和高性能数据分析(HPDA)的组件结合在一起,这些组件必须协同工作,才能有效地给决策者、一线人员和分析师赋能。图 1 展示了这种端到端 AI 解决方案及其组件的架构概览。
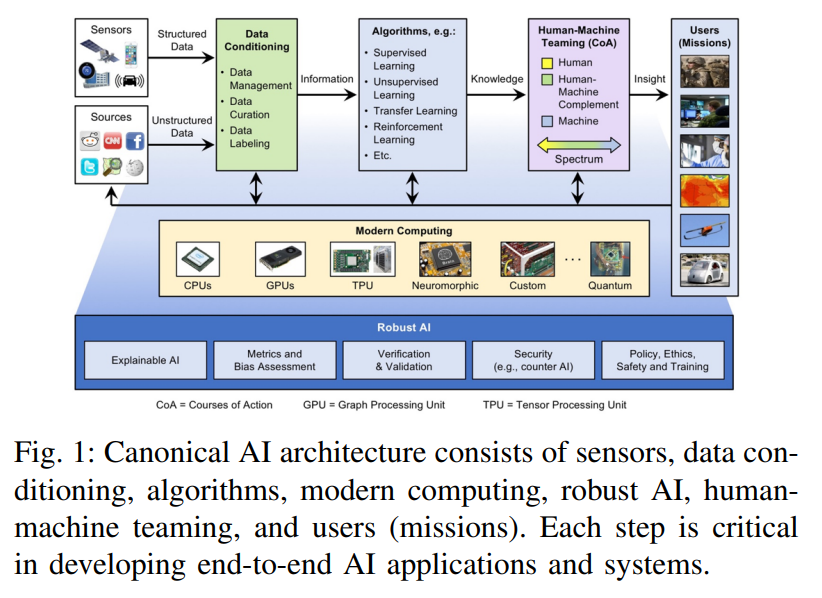
原始数据首先需要进行数据规整,在该步骤中数据被融合、聚合、结构化、累积并转换为信息。数据规整步骤生成的信息作为神经网络等有监督或无监督算法的输入,这些算法可提取模式、填充缺失数据或查找数据集之间的相似性、进行预测,从而将输入信息转换为可操作的知识。这些可操作的知识将会传递给人类,用于人机协作阶段的决策过程。人机协作阶段为用户提供有用且重要的洞察,将知识转化为可操作的智能或洞察力。
支撑这个系统的是现代计算系统。摩尔定律的趋势已经结束,但同时还有许多相关的定律和趋势被提出来,如 Denard 定律(功率密度)、时钟频率、核心数、每时钟周期的指令和每焦耳的指令(Koomey 定律)。从最早出现在汽车应用、机器人和智能手机中的片上系统(SoC)趋势来看,通过开发和集成常用内核、方法或功能的加速器,其创新仍在不断进步。这些加速器在性能和功能灵活性之间存在不同的平衡,包括深度学习处理器和加速器的创新爆发。通过阅读大量相关论文,本文探讨了这些技术的相对优势,因为它们对于将人工智能应用于对大小、重量和功率等有极大要求的嵌入式系统和数据中心时特别重要。
本文是对 IEEE-HPEC 过去三年论文的一次更新。与过去几年一样,本文继续关注深度神经网络(DNN)和卷积神经网络(CNN)的加速器和处理器,它们的计算量极大。本文主要针对加速器和处理器在推理方面的发展,因为很多 AI/ML 边缘应用极度依赖推理。本文针对加速器支持的所有数字精度类型,但对于大多数加速器来说,它们的最佳推理性能是 int8 或 fp16/bf16(IEEE 16 位浮点或 Google 的 16 位 brain float)。

论文链接:https://arxiv.org/pdf/2210.04055.pdf
目前,已经有很多探讨 AI 加速器的论文。如本系列调查的第一篇论文就有探讨某些 AI 模型的 FPGA 的峰值性能,之前的调查都深入覆盖了 FPGA,因此不再包含在本次调查中。这项持续调查工作和文章旨在收集一份全面的 AI 加速器列表,包括它们的计算能力、能效以及在嵌入式和数据中心应用中使用加速器的计算效率。与此同时文章主要比较了用于政府和工业传感器和数据处理应用的神经网络加速器。前几年论文中包含的一些加速器和处理器已被排除在今年的调查之外,之所以放弃它们,是因为它们可能已经被同一家公司的新加速器替代、不再维护或者与主题不再相关。
处理器调查
人工智能的许多最新进展部分原因要归功于硬件性能的提升,这使得需要巨大算力的机器学习算法,尤其是 DNN 等网络能够实现。本文的这次调查从公开可用的材料中收集各类信息,包括各种研究论文、技术期刊、公司发布的基准等。虽然还有其他方法获取公司和初创公司(包括那些处于沉默期的公司)的信息,但本文在本次调查时忽略了这些信息,这些数据将在公开后纳入该调查。该公共数据的关键指标如下图所示,其反映了最新的处理器峰值性能与功耗的关系能力(截至 2022 年 7 月)。
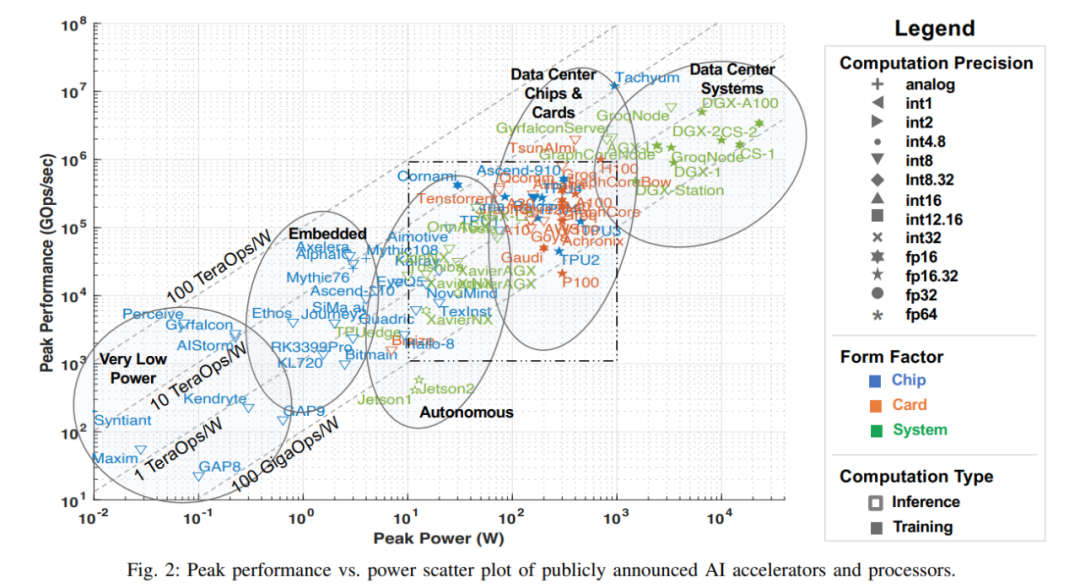
注意:图 2 中虚线方框与下图 3 是对应的,图 3 是把虚线框放大后的图。
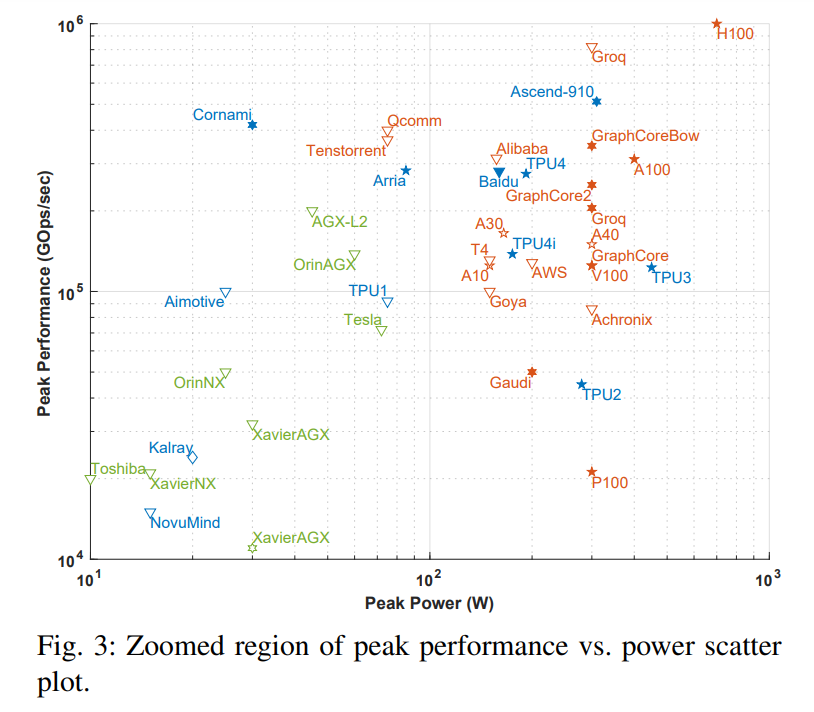
图中 x 轴表示峰值功率,y 轴表示每秒峰值千兆操作数(GOps/s),均为对数尺度。处理能力的计算精度用不同几何形状表示,计算精度范围从 int1 到 int32、从 fp16 到 fp64。显示的精度有两种类型,左边代表乘法运算的精度,右边代表累加 / 加运算的精度(如 fp16.32 表示 fp16 乘法和 fp32 累加 / 加)。使用颜色和形状区分不同类型系统和峰值功率。蓝色表示单芯片;橙色表示卡;绿色表示整体系统(单节点桌面和服务器系统)。此次调查仅限于单主板、单内存系统。图中空心几何图形是仅进行推理加速器的最高性能,而实心几何图形代表执行训练和推理的加速器的性能。
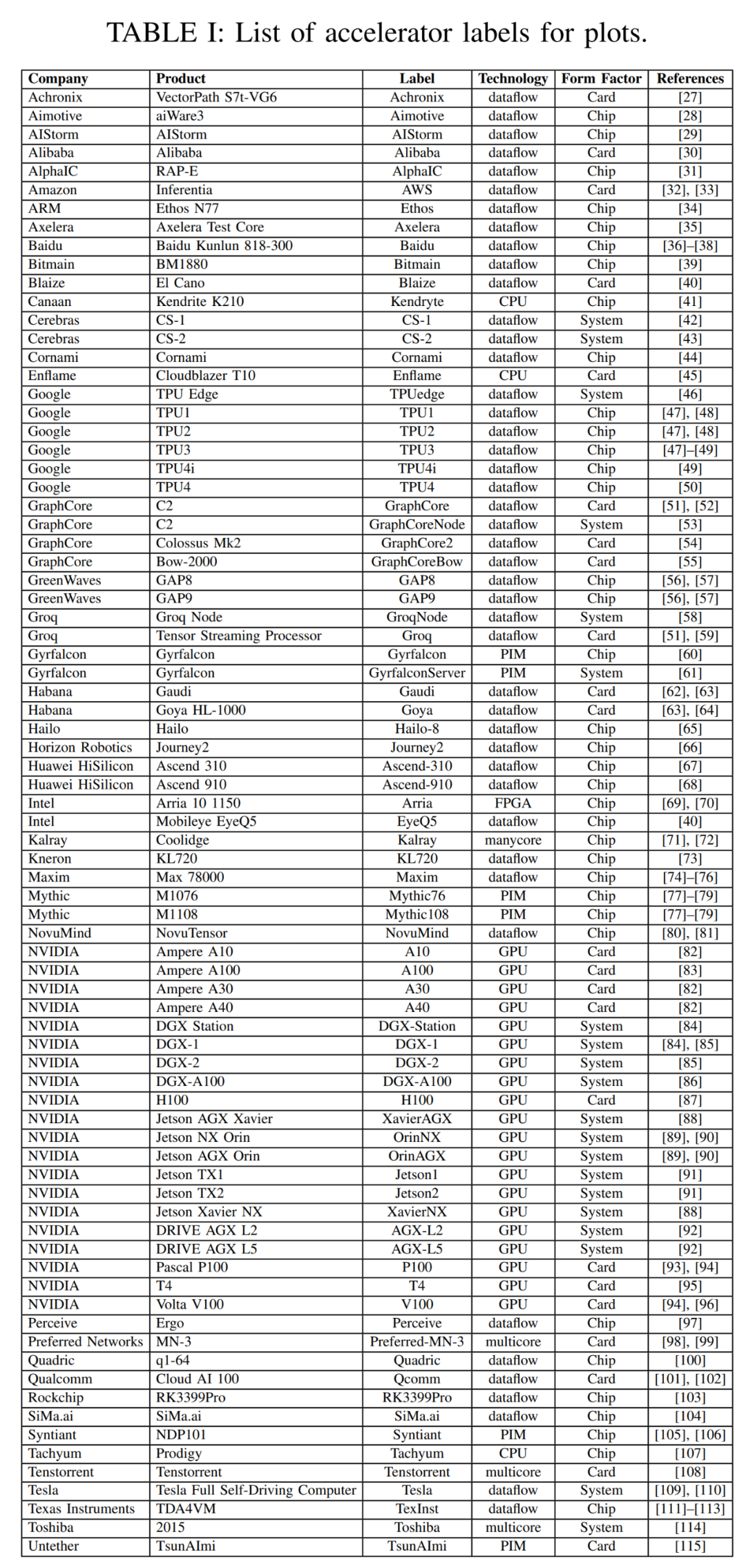
本次调查中本文以过去三年调查数据的散点图开篇。下表 1 中本文总结了加速器、卡和整体系统的一些重要元数据,包括图 2 中每个点的标签,许多要点都是从去年的调查中提出来的。表 1 中大多数列和条目都是准确清楚的。但有两个技术条目可能不是:Dataflow 和 PIM。Dataflow 型处理器是为神经网络推理和训练定制的处理器。由于神经网络训练和推理计算完全确定地构建,因此它们适合 dataflow 处理,其中计算、内存访问和 ALU 间通信被显式 / 静态编程或者布局布线到计算硬件。内存处理器(PIM)加速器将处理元素与内存技术集成在一起。在这些 PIM 加速器中,有一些基于模拟计算技术的加速器,该技术使用就地模拟乘法加法功能增强闪存电路。可以参考 Mythic 和 Gyrfalcon 加速器的相关资料,了解关于此创新技术的更多详细信息。
本文根据加速器的预期应用对其进行合理分类,图 1 用椭圆标识了五类加速器,根据性能和功耗做对应:功耗非常低,传感器非常小的语音处理;嵌入式摄像机、小型无人机和机器人;驾驶辅助系统、自动驾驶和自动机器人;数据中心的芯片和卡;数据中心系统。
大多数加速器的性能、功能等指标都没有改变,可以参阅过去两年的论文以了解相关信息。下面的是没有被过去的文章所收录的加速器。
荷兰嵌入式系统初创公司 Acelera 声称他们生产的嵌入式测试芯片具有数字和模拟设计能力,而这种测试芯片是为了测试数字设计能力的范围。他们希望在未来的工作中增加模拟(也可能是闪存)设计要素。
Maxim Integrated 发布了一款名为 MAX78000 用于超低功耗应用的系统芯片(SoC)。其包括 ARM CPU 内核、RISC-V CPU 内核和 AI 加速器。ARM 核心用于快速原型设计和代码重用,而 RISC-V 核心用于实现优化,以实现最低的功耗。AI 加速器有 64 个并行处理器,支持 1 位、2 位、4 位和 8 位整数运算。SoC 的最大工作功率为 30mW,适用于低延迟、电池供电的应用。
Tachyum 最近发布名为 Prodigy 一体式处理器,Prodigy 每个核心都集成 CPU 和 GPU 的功能,它是为 HPC 和机器学习应用程序设计的,该芯片有 128 个高性能统一内核,运行频率为 5.7GHz。
NVIDIA 于 2022 年 3 月发布了名为 Hopper(H100)的下一代 GPU。Hopper 集成更多的 Symmetric Multiprocessor(SIMD 和 Tensor 核),50% 的内存带宽,SXM 夹层卡实例的功率为 700W。(PCIe 卡功率为 450W)
过去几年 NVIDIA 发布了一系列系统平台,用于部署在汽车、机器人和其他嵌入式应用程序 Ampere 架构的 GPU。对于汽车应用,DRIVE AGX 平台增加了两个新系统:DRIVE AGX L2 可在 45W 功率范围内实现 2 级自动驾驶,DRIVE AGX L5 可在 800W 功率范围内能实现 5 级自动驾驶。Jetson AGX Orin 和 Jetson NX Orin 也使用 Ampere 架构 GPU,用于机器人、工厂自动化等,它们最大峰值功率为 60W 和 25W。
Graphcore 发布其第二代加速器芯片 CG200,它部署在 PCIe 卡上,峰值功率约为 300W。去年,Graphcore 还推出 Bow 加速器,这是与台积电合作设计的首款晶圆对晶圆处理器。加速器本身与上面提到的 CG200 相同,但它与第二块晶片配合使用,从而大大改善了整个 CG200 芯片的功率和时钟分布。这意味着性能提高了 40% 以及 16% 每瓦特的性能提升。
2021 年 6 月,谷歌宣布了其第四代纯推理 TPU4i 加速器的详细信息。将近一年后,谷歌分享了其第 4 代训练加速器 TPUv4 的详细信息。虽然官宣的细节很少,但他们分享了峰值功率和相关性能数值。与以前的 TPU 各种版本一样,TPU4 可通过 Google Compute Cloud 获得并用于内部操作。
接下来是对没有出现在图 2 中的加速器的介绍,其中每个版本都发布一些基准测试结果,但有的缺少峰值性能,有的没有公布峰值功率,具体如下。
SambaNova 去年发布了一些可重构 AI 加速器技术的基准测试结果,今年也发布了多项相关技术并与阿贡国家实验室合作发表了应用论文,不过 SambaNova 没有提供任何细节,只能从公开的资料估算其解决方案的峰值性能或功耗。
今年 5 月,英特尔 Habana 实验室宣布推出第二代 Goya 推理加速器和 Gaudi 训练加速器,分别命名为 Greco 和 Gaudi2。两者性能都比之前版本表现好几倍。Greco 是 75w 的单宽 PCIe 卡,而 Gaudi2 还是 650w 的双宽 PCIe 卡(可能在 PCIe 5.0 插槽上)。Habana 发布了 Gaudi2 与 Nvidia A100 GPU 的一些基准比较,但没有披露这两款加速器的峰值性能数据。
Esperanto 已经生产了一些 Demo 芯片,供三星和其他合作伙伴评估。该芯片是一个 1000 核 RISC-V 处理器,每个核都有一个 AI 张量加速器。Esperanto 已经发布了部分性能指标,但它们没有披露峰值功率或峰值性能。
在特斯拉 AI Day 中,特斯拉介绍了他们定制的 Dojo 加速器以及系统的一些细节。他们的芯片具有 22.6 TF FP32 性能的峰值,但没有公布每个芯片的峰值功耗,也许这些细节会在以后公布。
去年 Centaur Technology 推出一款带有集成 AI 加速器的 x86 CPU,其拥有 4096 字节宽的 SIMD 单元,性能很有竞争力。但 Centaur 的母公司 VIA Technologies 将位于美国的处理器工程团队卖给了 Intel,似乎已经结束了 CNS 处理器的开发。
一些观察以及趋势
图 2 中有几个观察值得一提,具体内容如下。
Int8 仍然是嵌入式、自主和数据中心推理应用程序的默认数字精度。这种精度对于使用有理数的大多数 AI/ML 应用程序来说是足够的。同时一些加速器使用 fp16 或 bf16。模型训练使用整数表示。
在极低功耗的芯片中,除了用于机器学习的加速器之外,还没发现其他额外功能。在极低功耗芯片和嵌入式类别中,发布片上系统(SoC)解决方案是很常见的,通常包括低功耗 CPU 内核、音频和视频模数转换器(ADC)、加密引擎、网络接口等。SoC 的这些附加功能不会改变峰值性能指标,但它们确实会对芯片报告的峰值功率产生直接影响,所以在比较它们时这一点很重要。
嵌入式部分的变化不大,就是说计算性能和峰值功率足以满足该领域的应用需求。
过去几年,包括德州仪器在内的几家公司已经发布了 AI 加速器。而 NVIDIA 也发布了一些性能更好的汽车和机器人应用系统,如前所述。在数据中心中,为了突破 PCIe v4 300W 的功率限制,PCIe v5 规格备受期待。
最后,高端训练系统不仅发布了令人印象深刻的性能数据,而且这些公司还发布了高度可扩展的互联技术,将数千张卡连接在一起。这对于像 Cerebras、GraphCore、Groq、Tesla Dojo 和 SambaNova 这样的数据流加速器尤其重要,这些加速器通过显式 / 静态编程或布局布线到计算硬件上的。这样一来它使这些加速器能够适应像 transformer 这种超大模型。
审核编辑 :李倩
-
加速器
+关注
关注
2文章
841浏览量
40236 -
MIT
+关注
关注
3文章
254浏览量
25030 -
机器学习
+关注
关注
67文章
8562浏览量
137209
原文标题:总结过去三年,MIT发布AI加速器综述论文
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何使用 powerquad 加速器中的一些功能以及 CMSIS 原始实现中的一些功能?
奕行智能论文入选国际计算机体系结构顶级会议 ISCA 2026

安路科技2025年度总结
使用NORDIC AI的好处
奇异摩尔参编人工智能加速器互联芯粒技术要求团体标准发布
边缘计算中的AI加速器类型与应用

亚马逊云科技第三期创业加速器圆满收官 助力初创释放Agentic AI潜力 加速全球化进程
创客总部加入MathWorks加速器计划
Andes晶心科技推出新一代深度学习加速器
【免费送书】AI芯片,从过去走向未来:《AI芯片:前沿技术与创新未来》

【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》
粒子加速器 —— 科技前沿的核心装置

直击Computex2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍




评论