 一种基于深度注意力感知特征的视觉定位框架
一种基于深度注意力感知特征的视觉定位框架

0.笔者个人体会:
这个工作来自于Baidu ADT部门,是该团队继L3-Net之后的在自动驾驶领域内关于定位的又一力作,其利用图像数据取得了与基于Lidar的方法相当的定位精度。 其突出的优势在于:
1.该方法达到了极高的精度。即使是在训练以及建图是用到了激光雷达(点云数据),但在实际线上使用时,只用了图像数据。在这种设置下,本方法大大节省了实际使用时的成本,并达到了厘米级别的精度。
2.该方法继承了L3-Net在求解位姿时的做法,即基于Cost volume求解位姿修正量。这种设置可以满足端到端训练的需求,并在某种程度上等价于对候选的位姿进行遍历对比,求解了一定范围内的最优解。
3.该方法的时间效率可控。随着选择较少的关键点数量,该方法可以达到极高的时间效率。
但此方法也有一定的不足,即该方法严重依赖于给定初始预测位姿的精度。基于Cost volume的定位本质上是在候选位姿集合上做一个遍历,选择其中的最优解。
但如果给定的初始预测位姿精度不够时,所有候选位姿的精度都有限,即无法得到一个精度较高的定位结果。这个问题可能为实际使用带来一定的局限性。
1、论文相关内容介绍:
摘要:针对自动驾驶应用领域,本文提出了一种基于深度注意力感知特征的视觉定位框架,该框架可达到厘米级的定位精度。传统的视觉定位方法依赖于手工制作的特征或道路上的人造物体。然而,它们要么容易由于严重的外观或光照变化而导致不稳定的匹配,要么太过稀少,无法在具有挑战性的场景中提供稳定和鲁棒的定位结果。
在这项工作中,本文利用深度注意力机制,通过一种新的端到端深度神经网络来寻找场景中有利于长距离匹配的显著的、独特的和稳定的特征。此外,此学习的特征描述符被证明有能力建立鲁棒的匹配,因此成功地估计出最优的、具有高精度的相机姿态。
本文使用新收集的具有高质量的地面真实轨迹和传感器之间硬件同步的数据集全面验证了本方法的有效性。
结果表明,与基于lidar的定位解决方案相比,在各种具有挑战性的环境下,本文的方法获得了具有竞争力的定位精度,这是一种潜在的低成本自动驾驶定位解决方案。
主要贡献:
1.提出一种新颖的自动驾驶视觉定位框架,在各种具有挑战性的照明条件下达到了厘米级定位精度。
2.通过一种新的端到端深度神经网络使用了注意力机制和深层特征,这有效的提高了算法性能。
3.使用具有高质量的地面真实轨迹和硬件(相机、激光雷达、IMU)同步的新数据集对所提出的方法进行严格测试,并验证了其性能。
方法介绍:
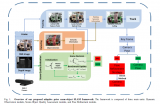
该系统分为三个阶段:(1)网络训练;(2)地图生成;(3)在线定位。地图生成和在线定位都可以看作是经过训练的网络的应用。提出的网络架构如图1所示。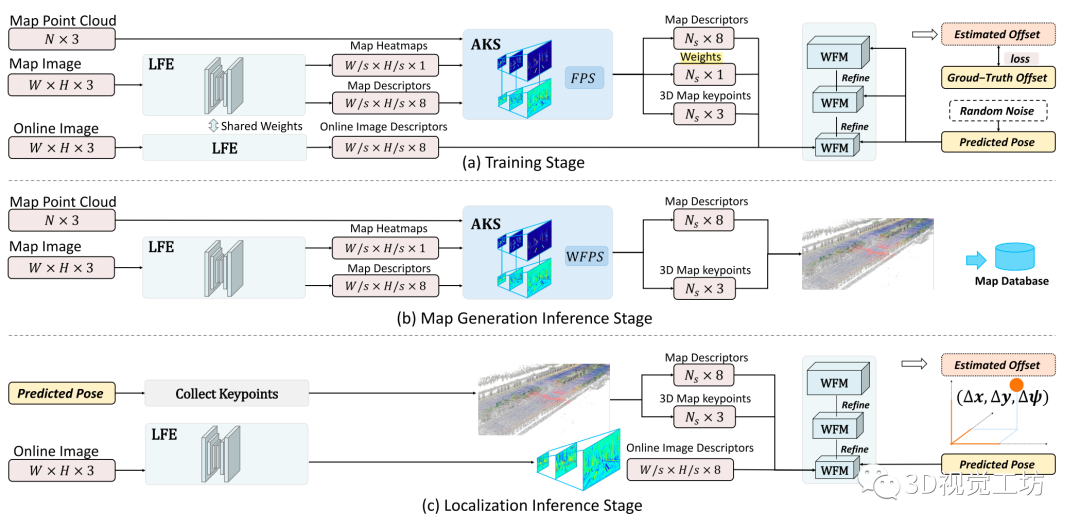
Fig1:基于端到端深度注意力感知特征的视觉定位框架在三个不同阶段的网络架构和系统工作流:a)训练;bb)地图生成;c)在线定位。
一、系统工作流
1. 训练:
训练阶段包括三个模块,LFE, AKS和WFM。首先,给定一个预测位姿,并选取其在欧氏距离内最接近的地图图像;接下来,LFE模块分别从在线图像和地图图像中提取稠密特征,并从地图图像中提取相应的注意力热图。AKS模块根据热图的注意力得分,从地图图像中选择具备好的特征的点作为关键点。
然后通过激光雷达点云投影得到它们的相应的三维坐标。最后,以这些三维关键点和特征描述符作为输入,WFM模块在一个三维代价卷中搜索,寻找最优位姿偏移量,并将最优位姿偏移量与地面真实位姿进行比较,构造损失函数。
2.地图生成:
训练结束后,使用如图2所示的网络的部分子网络,可以完成地图生成。给定激光雷达扫描和车辆真实位姿,可以很容易地获得激光雷达点的全局三维坐标。注意,激光雷达传感器和车辆位姿真值仅用于建图。首先,在给定车辆真实位姿的情况下,通过将三维激光雷达点投影到图像上,将地图图像像素与全局三维坐标关联起来。
然后利用LFE网络求解地图图像的注意力热图和不同分辨率的特征图。接下来,在AKS模块的金字塔中为不同的分辨率选择一组关键点。总体而言,本方法将关键点及其特征描述符,以及其3D坐标保存到地图数据库中。
3.在线定位:
在定位阶段,利用LFE网络再次估计在线图像中不同分辨率的特征图。本方法从给定的相机的预测位姿的最近的地图图像中收集关键点及其特征描述符和全局3D坐标。
然后,在WFM模块中,构建的成本卷中给出了候选位姿,而这些关键点则被利用这些候选位姿投影到在线图像上。通过三个不同分辨率的特征匹配网络级联实现由粗到细的位姿估计。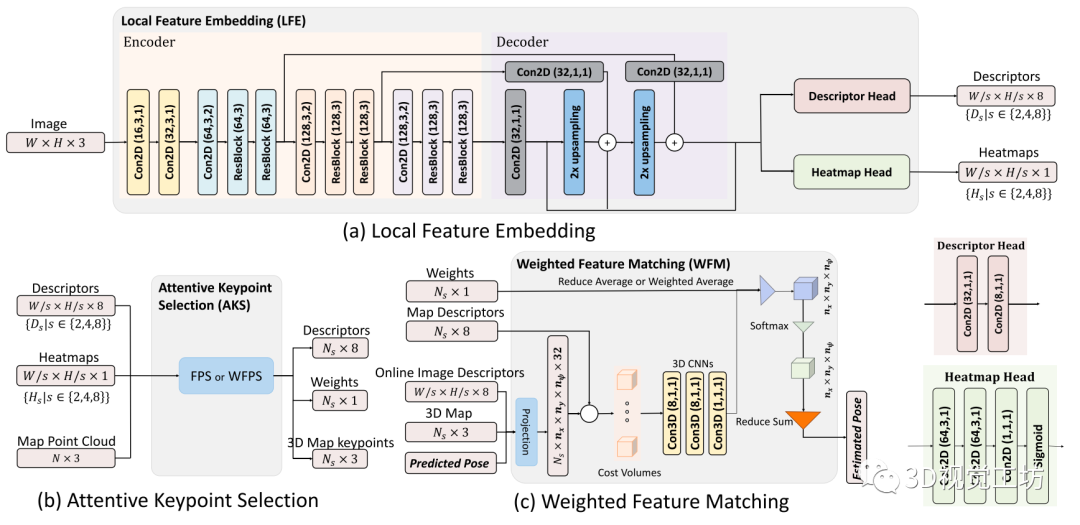
Fig.2 三个主要模块的网络结构说明:(a)局部特征学习(LFE);(b)关键点选取(AKS);(c)加权特征匹配(WFM)。
二、局部特征学习
在所有三个不同的阶段都使用相同的LFE模块。本文采用了一种类似于特征金字塔网络(FPN)的网络架构,如图2(a)所示。通过将编码器和解码器中相同大小的特征图级联起来,FPN可以在所有尺度上增强高级语义特征,从而获得更强大的特征提取器。
在本方法的编码器中有一个FPN,其由17层网络组成,可以分解为4个阶段。第一阶段由两个二维卷积层组成,其中括号中的数字分别是通道、核和步幅大小。从第二阶段开始,每个阶段包括一个二维卷积层和两个残差块。每个残差块由两个3 × 3卷积层组成。
在解码器中,经过二维卷积层后,上采样层被应用于从更粗糙但语义更强的特征中产生更高分辨率的特征。来自编码器的相同分辨率的特征被通过按元素平均来合并以增强解码器中的这些特征。解码器的输出是原始图像的不同分辨率的特征图。再通过如图2右下角所示的两个不同的网络头,分别用于提取特征描述符和估计注意力热图
。特征描述符表示为d维向量,能够在不同光照或视点条件引起的严重外观变化下进行鲁棒匹配。该热图由[0-1]标量组成,这些标量在后文的基于注意力的关键点选择和特征匹配模块中用作相关性权重。更具体地说,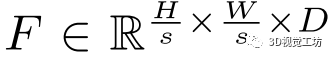
是描述符学习模块输出, 其中s∈2,4,8是尺度因子,D = 8为特征维度。注意力热图输出是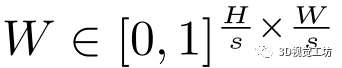 .
.
三、关键点选取
在研究过程中,了解到不同的关键点选择策略对系统的整体性能有相当大的影响。AKS模块分为两个阶段:训练和地图生成。当在解决一个几何问题时,众所周知,相较于聚集在一起的关键点,在几何空间中几乎均匀分布的一组关键点是至关重要的。
本方法发现,提出的方法优于其他更自然的选择,例如top-K。本方法考虑了两种选择策略,即最远点采样(FPS)算法及其变体,加权FPS (WFPS)算法(如图2(b)所示)。给定一组已选点S和未选点Q,如果试图迭代地从Q中选择一个新点, FPS算法会计算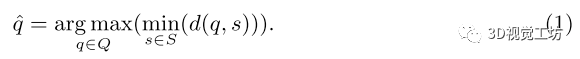
在本方法的WFPS算法中,取而代之的是计算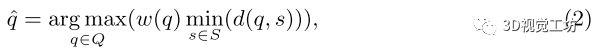
在训练阶段,本方法的目标是统一学习所有的候选者的注意力分数,因此必须要有一个有效的随机选择策略。为此,首先随机抽取K个候选点,然后,本方法应用FPS算法来选择其中的关键点。 在地图生成阶段,本方法通过有效地结合学习的注意力权重实现了一个能够选择好的关键点的算法。
本方法再次随机选择K个候选点,然后在地图生成过程中使用WFPS,并以热图为采样概率来使用稠密采样。 为了将二维特征描述符与三维坐标相关联,本方法将3D激光雷达点投射到图像上。考虑到并非所有的图像像素都与LiDAR点相关联,本方法只考虑与已知三维坐标有关联的稀疏2D像素作为候选点,从中选择适合匹配的关键点。
四、加权特征匹配
传统方法通常利用RANSAC框架中的PnP求解器来求解给定2D-3D对应的摄像机位姿估计问题。不幸的是,这些包括异常值拒绝步骤的匹配方法是不可微的,从而阻碍了他们在训练阶段的反向传播。
L3-Net引入了一种特征匹配和位姿估计方法,该方法利用可微分的三维代价卷来评估给定的位姿偏移量下,来自在线图像和地图图像的对应特征描述符对的匹配代价。 下面,本方法对原来的L3-Net设计进行改进,提出将注意力权重纳入解决方案,并使其有效训练。网络架构如图2(c)所示。
代价卷:与L3-Net的实现类似,本方法建立了一个
的代价卷,其中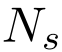 为所选关键点的个数,
为所选关键点的个数,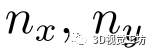 和
和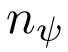 为每个维度的网格大小。具体来说,给定预测位姿作为代价卷中心,将其相邻空间均匀划分为一个三维网格,记为
为每个维度的网格大小。具体来说,给定预测位姿作为代价卷中心,将其相邻空间均匀划分为一个三维网格,记为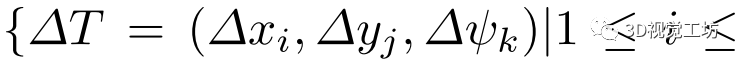
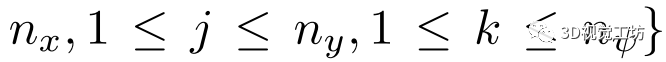 。
。
该代价卷中的节点是候选位姿,本方法希望从中评估其对应的特征对并找到最优解。具体而言,利用每个候选位姿将地图图像中选定的三维关键点投影到在线图像上,通过对在线图像特征图进行双线性插值,计算出对应的局部特征描述符。通过计算在线和地图图像的两个描述符之间的元素的总的L2距离,本方法实现了一个单维代价标量。然后,由一个以Conv3D(8,1,1)-Conv3D(8,1,1)-Conv3D(1,1,1)为内核的三层三维CNN对代价卷进行处理,结果记为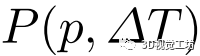
边缘化:通过应用平均操作,在关键点维度上将匹配代价卷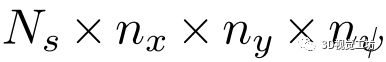 边缘化为
边缘化为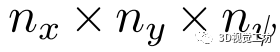 。
。
在LFE模块的热图学习训练中,成功的关键在于如何有效地结合所有关键点特征的注意力权重。与没有注意力权重的平均相比,最直接的解决方案是使用加权平均操作取代直接平均。
本方法在训练时使用加权平均,在在线定位化阶段使用直接平均。 其余部分估计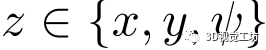 的最优偏移量
的最优偏移量 及其概率分布
及其概率分布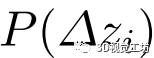 与图2 (c)所示的L3-Net的设计相同。
与图2 (c)所示的L3-Net的设计相同。
五、损失函数设计
1)绝对损失:以估计偏移量 与真值
与真值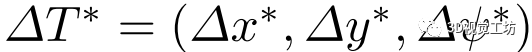 之间的绝对距离作为第一个损失:
之间的绝对距离作为第一个损失: 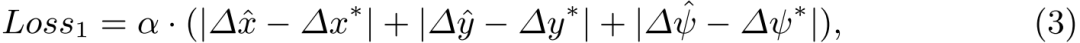
其中α是一个平衡因子。
2)聚集损失:除上述绝对损失外,概率分布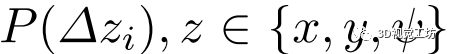 对估计的鲁棒性也有相当大的影响。因此,取
对估计的鲁棒性也有相当大的影响。因此,取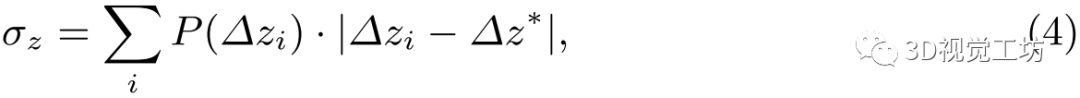
其中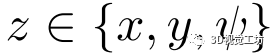 。
。
从而第二个损失函数定义为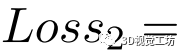
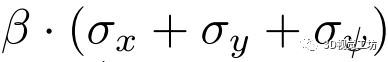 。
。
3)相似损失:除几何约束外,对应的2D-3D关键点该有相似的描述符。因此,本方法将第三个损失定义为: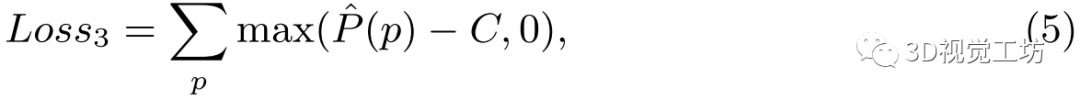
其中,为关键点P的三维CNN的输出,当使用真值位姿将地图中的关键点投影到在线图像上时,在在线图像中找到对应的点,并计算匹配点对之间的描述符的距离。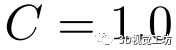 是一个常数。
是一个常数。
审核编辑:刘清
-
ADT
+关注
关注
0文章
12浏览量
9725 -
激光雷达
+关注
关注
983文章
4595浏览量
197404 -
自动驾驶
+关注
关注
795文章
15056浏览量
181991
原文标题:视觉定位在自动驾驶领域可否比肩基于Lidar的方法?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
2026年中国十大机器视觉公司的决胜逻辑:全栈能力与场景深耕
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
零基础手写大模型资料2026
HM博学谷狂野AI大模型第四期
深度相机:从技术突破到全场景落地,解锁三维感知新可能

安森美浅谈机器视觉应用发展趋势和深度感知的技术难题

RTK-SCAM-60 双目立体视觉相机|精准深度感知 全场景智能视觉

CCD视觉定位加持!博特精密光纤激光打标机助力电子制造业效率翻倍

双目视觉是如何实现深度估计的?
自然场景下注意力如何耳周脑电可靠监测

【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
欧菲光与广和通联合首发ToF+双目感知定位模块
视觉定位引导劈刀修磨系统赋能芯片封装

一种适用于动态环境的自适应先验场景-对象SLAM框架



评论