 OpenHarmony集成OCR三方库实现文字提取
OpenHarmony集成OCR三方库实现文字提取

点击蓝字 ╳ 关注我们
开源项目 OpenHarmony是每个人的 OpenHarmony
郭岳峰
深圳开鸿数字产业发展有限公司
OS框架开发工程师
以下内容来自嘉宾分享,不代表开放原子开源基金会观点1.简介
Tesseract(Apache 2.0 License)是一个可以进行图像OCR识别的C++库,可以跨平台运行 。本样例基于Tesseract库进行适配,使其可以运行在OpenAtom OpenHarmony(以下简称“OpenHarmony”)上,并新增N-API接口供上层应用调用,这样上层应用就可以使用Tesseract提供的相关功能。2.效果展示
识别文字 身份信息识别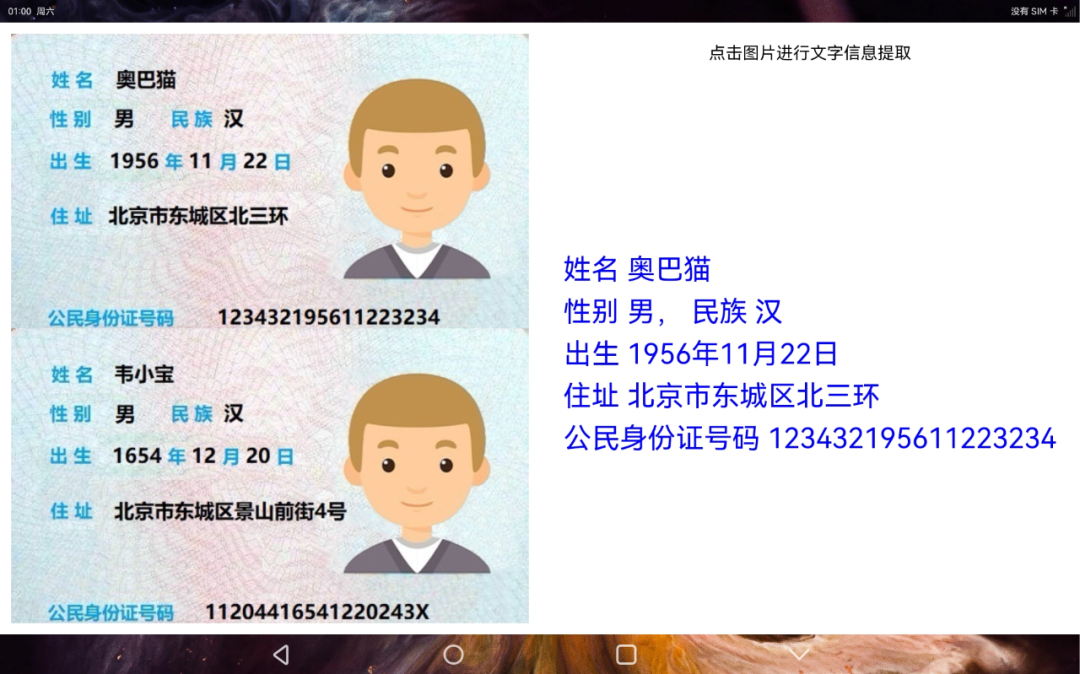 提取文字信息到本地文件
提取文字信息到本地文件 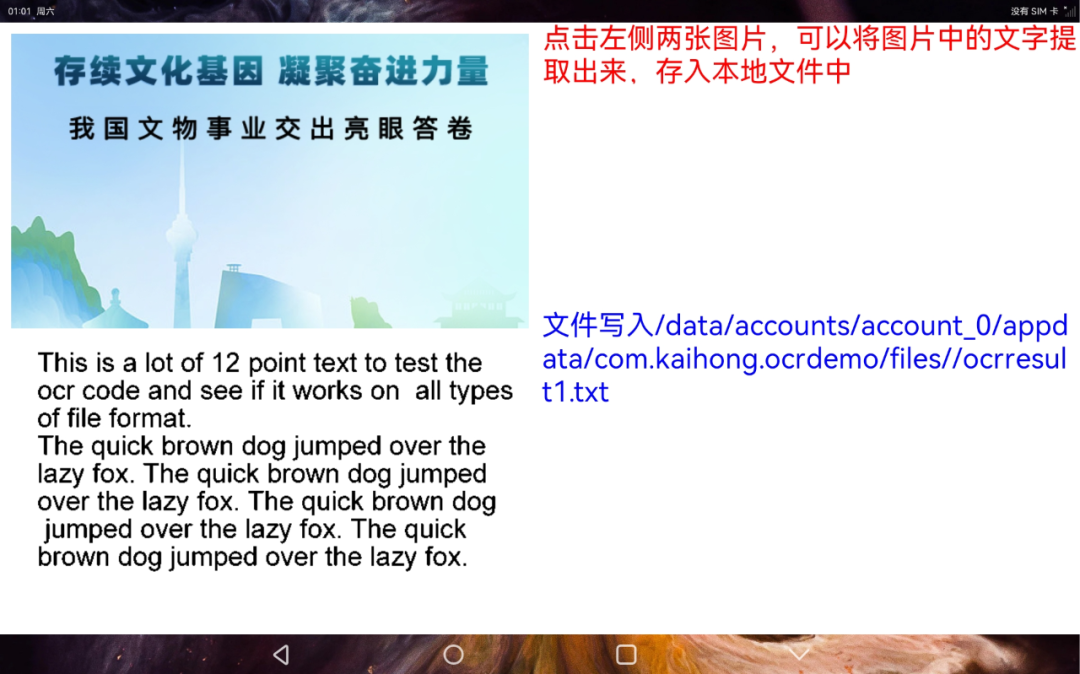
相关代码已经上传至SIG仓库,链接如下:
https://gitee.com/openharmony-sig/knowledge_demo_temp/tree/master/FA/OCRDemo
3.目录结构
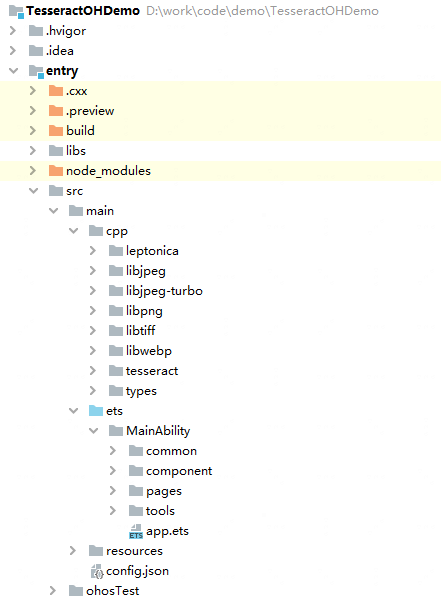
4.调用流程
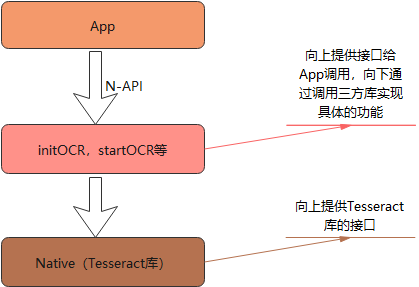 调用过程主要涉及到三方面,首先应用层实现样例的效果,包括页面的布局和业务逻辑代码;中间层主要起桥梁的作用,提供N-API接口给应用调用,再通过三方库的接口去调用具体的实现;Native层使用了三方库Tesseract提供具体的实现功能。
调用过程主要涉及到三方面,首先应用层实现样例的效果,包括页面的布局和业务逻辑代码;中间层主要起桥梁的作用,提供N-API接口给应用调用,再通过三方库的接口去调用具体的实现;Native层使用了三方库Tesseract提供具体的实现功能。
5.源码分析
本样例源码的分析主要涉及到两个方面,一方面是N-API接口的实现,另一方面是应用层的页面布局和业务逻辑。N-API实现 1. 首先在index.d.ts文件中定义好接口
/**
* 初始化文字识别引擎
* @param lang 识别的语言, eg:eng、chi_sim、 eng+chi_sim,为Null或不传则为中英文(eng+chi_sim)
* @param trainDir 训练模型目录,为Null或不传则为默认目录
*
* @return 初始化是否成功 0=>成功,-1=>失败
*/
export const initOCR: (lang: string, trainDir: string) => Promise<number>;
export const initOCR: (lang: string, trainDir: string, callback: AsyncCallback<number>) => void;
/**
* 开始识别
* @param imagePath 图片路径(当前支持的图片格式为png, jpg, tiff)
*
* @return 识别结果
*/
export const startOCR: (imagePath: string) => Promise<string>;
export const startOCR: (imagePath: string, callback: AsyncCallback<string>) => void;
/**
* 销毁资源
*/
exportconstdestroyOCR:()=>void;
代码中可以看出N-API接口initOCR和startOCR都采用了两种方式,一种是Promise,一种是Callback的方式。在样例的应用层,使用的是它们的Callback方式。 2 注册N-API模块和接口
EXTERN_C_START
static napi_value Init(napi_env env, napi_value exports) {
napi_property_descriptor desc[] = {
{
"initOCR", nullptr, InitOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
"startOCR", nullptr, StartOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
"destroyOCR", nullptr, DestroyOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
};
napi_define_properties(env, exports, sizeof(desc) / sizeof(desc[0]), desc);
return exports;
}
EXTERN_C_END
static napi_module demoModule = {
.nm_version = 1,
.nm_flags = 0,
.nm_filename = nullptr,
.nm_register_func = Init,
.nm_modname = "tesseract",
.nm_priv = ((void *)0),
.reserved = {
0
},
};
extern "C" __attribute__((constructor)) void RegisterHelloModule(void) {
napi_module_register(& demoModule);
}
通过nm_modname定义模块名,nm_register_func注册接口函数,在Init函数中指定了JS中initOCR,startOCR,destroyOCR对应的本地实现函数,这样就可以在对应的本地实现函数中调用三方库Tesseract的具体实现了。 3 以startOCR的Callback方式为例介绍N-API中的具体实现
static napi_value StartOCR(napi_env env, napi_callback_info info) {
OH_LOG_ERROR(LogType::LOG_APP, "OCR StartOCR 111");
size_t argc = 2;
napi_value args[2] = { nullptr };
//1. 获取参数
napi_get_cb_info(env, info, &argc, args, nullptr, nullptr);
//2. 共享数据
auto addonData = new StartOCRAddOnData{
.asyncWork = nullptr,
};
//3. N-API类型转成C/C++类型
char imagePath[1024] = { 0 };
size_t length = 0;
napi_get_value_string_utf8(env, args[0], imagePath, 1024, &length);
addonData->args0 = string(imagePath);
napi_create_reference(env, args[1], 1, &addonData->callback);
//4. 创建async work
napi_value resourceName = nullptr;
napi_create_string_utf8(env, "startOCR", NAPI_AUTO_LENGTH, &resourceName);
napi_create_async_work(env, nullptr, resourceName, executeStartOCR, completeStartOCRForCallback, (void *)addonData, &addonData->asyncWork);
//将创建的async work加到队列中,由底层调度执行
napi_queue_async_work(env, addonData->asyncWork);
napi_value result = 0;
napi_get_null(env, &result);
return result;
}
首先通过napi_get_cb_info方法获取JS侧传入的参数信息,将参数转成C++对应的类型,然后创建异步工作,异步工作的方法参数中包含,执行的函数以及函数执行完成的回调函数。 我们看一下执行函数
static void executeStartOCR(napi_env env, void* data) {
//通过data来获取数据
StartOCRAddOnData * addonData = (StartOCRAddOnData *)data;
napi_value resultValue;
try {
if (api != nullptr) {
//调用具体的实现,读取图片像素
PIX * pix = pixRead((const char*)addonData->args0.c_str());
//设置api的图片像素
api->SetImage(pix);
//调用文字提取接口,获取图片中的文字
char * result = api->GetUTF8Text();
addonData->result = result;
//释放资源
pixDestroy (& pix);
delete[] result;
}
} catch (std::exception e) {
std::string error = "Error: ";
if (initResult != 0) {
error += "please first init tesseractocr.";
} else {
error += e.what();
}
addonData->result = error;
}
}
这个方法中通过data获取JS传入的参数,然后调用Tesseract库中提供的接口,调用具体的文字提取功能,获取图片中的文字。 执行完成后,会回调到completeStartOCRForCallback,在这个方法中会将执行函数中返回的结果转换为JS的对应类型,然后通过Callback的方式返回。
static void completeStartOCRForCallback(napi_env env, napi_status status, void * data) {
StartOCRAddOnData * addonData = (StartOCRAddOnData *)data;
napi_value callback = nullptr;
napi_get_reference_value(env, addonData->callback, &callback);
napi_value undefined = nullptr;
napi_get_undefined(env, &undefined);
napi_value result = nullptr;
napi_create_string_utf8(env, addonData->result.c_str(), addonData->result.length(), &result);
//执行回调函数
napi_value returnVal = nullptr;
napi_call_function(env, undefined, callback, 1, &result, &returnVal);
//删除napi_ref对象
if (addonData->callback != nullptr) {
napi_delete_reference(env, addonData->callback);
}
//删除异步工作项
napi_delete_async_work(env, addonData->asyncWork);
delete addonData;
}
应用层实现 应用层主要分为三个模块:动物图片文字识别,身份信息识别,提取文字到本地文件 1. 动物图片文字识别
build() {
Column() {
Row() {
Text('点击图片进行文字提取 提取结果 :').fontSize('30fp').fontColor(Color.Blue)
Text(this.ocrResult).fontSize('50fp').fontColor(Color.Red)
}.margin('10vp').height('10%').alignItems(VerticalAlign.Center)
Grid() {
ForEach(this.images, (item, index) => {
GridItem() {
AnimalItem({
path1: item[0],
path2: item[1]
});
}
})
}
.padding({left: this.columnSpace, right: this.columnSpace})
.columnsTemplate("1fr 1fr 1fr") // Grid宽度均分成3份
.rowsTemplate("1fr 1fr") // Grid高度均分成2份
.rowsGap(this.rowSpace) // 设置行间距
.columnsGap(this.columnSpace) // 设置列间距
.width('100%')
.height('90%')
}
.backgroundColor(Color.Pink)
}
布局主要使用了Grid的网格布局,每个Item都是对应的图片,通过点击图片可以对点击图片进行文字提取,将提取出的文字显示在标题栏。 2. 身份信息识别
build() {
Row() {
Column() {
Image('/common/idImages/aobamao.jpg')
.onClick(() => {
//点击图片进行信息识别
console.log('OCR begin dialog open 111');
this.ocrDialog.open();
ToolUtils.ocrResult(ToolUtils.aobamao, (result) => {
console.log('111 OCR result = ' + result);
this.result = result;
this.ocrDialog.close();
});
})
.margin('10vp')
.objectFit(ImageFit.Auto)
.height('50%')
Image('/common/idImages/weixiaobao.jpg')
.onClick(() => {
//点击图片进行信息识别
this.ocrDialog.open();
ToolUtils.ocrResult(ToolUtils.weixiaobao, (result) => {
console.log('111 OCR result = ' + result);
this.result = result;
this.ocrDialog.close();
});
})
.margin('10vp')
.objectFit(ImageFit.Auto)
.height('50%')
}
.width(this.screenWidth/2)
.padding('20vp')
Column() {
Text(this.title).height('10%').fontSize('30fp').fontColor(this.titleColor)
Column() {
Text(this.result)
.fontColor('#0000FF')
.fontSize('50fp')
}.justifyContent(FlexAlign.Center).alignItems(HorizontalAlign.Center).height('90%')
}
.justifyContent(FlexAlign.Start)
.width('50%')
}
.width('100%')
.height('100%')
}
身份信息识别的布局最外层是一个水平布局,分为左右两部分,左边的子布局是垂直布局,里面是两张不同的身份证图片,右边子布局也是垂直布局,主要是标题区和识别结果的内容显示区。 3. 提取文字到本地文件
Row() {
Column() {
Image('/common/save2FileImages/testImage1.png')
.onClick(() => {
//点击图片进行信息识别
ToolUtils.ocrResult(ToolUtils.testImage1, (result) => {
let path = this.dir + 'ocrresult1.txt';
try {
let fd = fileio.openSync(path, 0o100 | 0o2, 0o666);
fileio.writeSync(fd, result);
fileio.closeSync(fd);
this.displayText = '文件写入' + path;
} catch (e) {
console.log('OCR fileio error = ' + e);
}
});
})
Image('/common/save2FileImages/testImage2.png')
.onClick(() => {
//点击图片进行信息识别
ToolUtils.ocrResult(ToolUtils.testImage2, (result) => {
let path = this.dir + 'ocrresult2.txt';
let fd = fileio.openSync(path, 0o100 | 0o2, 0o666);
fileio.writeSync(fd, result);
fileio.closeSync(fd);
this.displayText = '文件写入' + path;
});
})
}
Column() {
Text(this.title)
Column() {
Text(this.displayText)
}
}
}
这个功能首先通过接口识别出图片中的文字,然后再通过fileio的能力将文字写入文件中。
6.总结
样例通过Native的方式将C++的三方库集成到应用中,通过N-API方式提供接口给上层应用调用。对于依赖三方库能力的应用,都可以使用这种方式来进行,移植三方库到Native,通过N-API提供接口给应用调用。 关于样例开发,我之前还分享过《如何利用OpenHarmony ArkUI的Canvas组件实现涂鸦功能?》、《如何通过OpenHarmony的音频模块实现录音变速功能?》欢迎感兴趣的开发者进行了解并与我交流样例开发经验。
原文标题:OpenHarmony集成OCR三方库实现文字提取
文章出处:【微信公众号:OpenAtom OpenHarmony】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
鸿蒙
+关注
关注
60文章
3018浏览量
46173 -
OpenHarmony
+关注
关注
33文章
3974浏览量
21356
原文标题:OpenHarmony集成OCR三方库实现文字提取
文章出处:【微信号:gh_e4f28cfa3159,微信公众号:OpenAtom OpenHarmony】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
三方库移植OpenHarmony过程
战码先锋,PR征集令(以下简称“战码先锋”)第二期正如火如荼地进行中,涉及OpenAtom OpenHarmony(以下简称“OpenHarmony”)主干仓、SIG仓、三方库,共计1
使用OpenHarmonyNDK移植三方库Speexdsp
大家好,我是一名即将本科毕业的OpenHarmony开发者,去年暑假利用了两个月时间移植了一个语音处理的三方库Speexdsp到OpenHarmony标准系统。主要为其编写了`buil
快速移植OpenHarmony到三方芯片平台的方法
移植概述本文面向希望将OpenHarmony移植到三方芯片平台硬件的开发者,介绍一种借助三方芯片平台自带Linux内核的现有能力,快速移植OpenHarmony到
发表于 04-12 11:08
【PIMF】OpenHarmony啃论文俱乐部—盘点开源鸿蒙三方库【1】
OpenHarmony third_party三方库:三方开源库是封装的软件功能,可以避免重复造轮子、提升软件开发效率。
发表于 06-17 19:48
【PIMF】OpenHarmony啃论文俱乐部—盘点开源鸿蒙三方库【2】
OpenHarmony third_party三方库:三方库(开源库)是封装的软件功能,可以避免
发表于 06-29 16:44
4步成功将三方库——speexdsp移植到OpenHarmony
归)进行分享,他在完成了一个三方库在OpenHarmony标准系统上的移植工作后,总结了以下经验。四步实现三方
发表于 09-27 12:02
OpenHarmony集成OCR三方库实现文字提取
;#125;这个功能首先通过接口识别出图片中的文字,然后再通过fileio的能力将文字写入文件中。6. 总结样例通过Native的方式将C++的三方库
发表于 11-15 12:09
OpenHarmony三方库适配指南
本文以OpenHarmony-3.2-Beta4上适配modbus编译动态库为例。获取三方库使用之前要做好代码溯源,确认可用的版本,开源许可和发布方式等。通过正确的路径获取源码,可以是
发表于 04-07 09:12
OpenAtom OpenHarmony 三方库创建发布及安全隐私检测
的三方库进行功能性测试,如果三方库没有真正的功能实现或其功能无法在OpenHarmony上验证,
发表于 11-13 17:27
openharmony第三方组件适配移植的文字组合拆分库
项目介绍 项目名称: MatchView 所属系列: openharmony的第三方组件适配移植 功能: 是一款由进度条来控制文字的组合和拆分的库 项目移植状态: 主功能完成 调用差异
发表于 03-30 10:59
•0次下载
基于openharmony实现绑定ability和fraction页面切换的三方库
项目介绍 项目名称:Alligator 所属系列:openharmony的第三方组件适配移植 功能:通过注解处理器实现一套绑定ability和fraction页面切换的三方
发表于 04-08 10:21
•1次下载
总结移植三方库到OpenHarmony的经验
三方库主要是基于标准 Linux 系统的 c/c++ 开源库,所以三方库的移植工作,首先是在标准 Linux 系统搭建环境、编译与验证,然后
鸿蒙三方库适配指南
本文以 OpenHarmony-3.2-Beta4 上适配 modbus 编译动态库为例。 获取三方库 使用之前要做好代码溯源,确认可用的版本,开源许可和发布方式等。 通过正确的路径获
【开源三方库】bignumber.js:一个大数数学库
点击蓝字 ╳ 关注我们 开源项目 OpenHarmony 是每个人的 OpenHarmony OpenAtom OpenHarmony (以下简称“OpenHarmony”)
【开源三方库】crypto-js加密算法库的使用方法
点击蓝字 ╳ 关注我们 开源项目 OpenHarmony 是每个人的 OpenHarmony OpenAtom OpenHarmony(简称“OpenHarmony”)



评论