 模态计算问题如何解?这题RSoft能回答!
模态计算问题如何解?这题RSoft能回答!







声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
新思科技
+关注
关注
5文章
979浏览量
52989
原文标题:模态计算问题如何解?这题RSoft能回答!
文章出处:【微信号:Synopsys_CN,微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
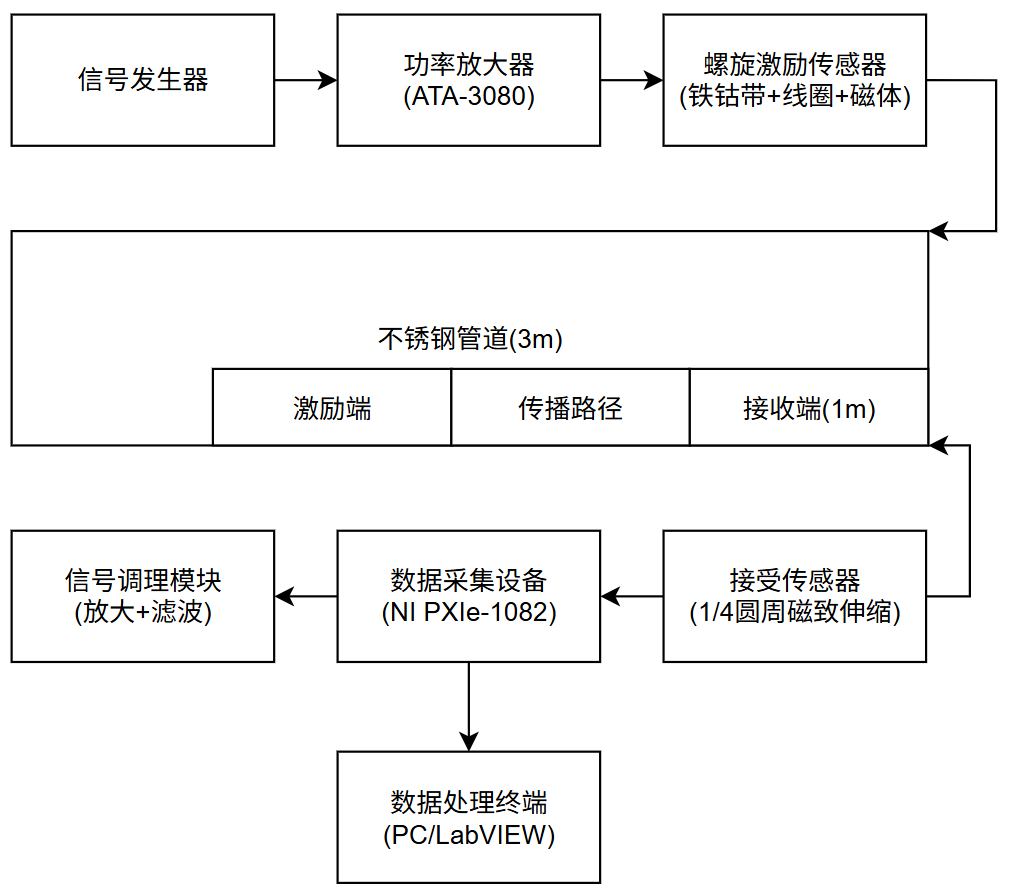
功率放大器在螺旋载荷下管中弯曲模态导波中的应用
管道在工业中应用广泛,是油、气、水等流体的主要运输方式,保障管道安全具有重要意义。超声导波检测具有高效便捷的特点,非常适合管道检测。当前管道导波检测主要采用轴对称模态导波,使用弯曲模态的几乎没有
RSoft GPU加速技术重塑光子元件设计效率革命
设计效率。为了解决这个问题,RSoft 光子器件工具的 FullWAVE FDTD 模组中引入 GPU 加速,通过 NVIDIA GPU 的平行运算能力,使得模拟速度相比 CPU 计算大幅提升。

赋能智慧隧道施工:工程车辆多模态数据采集系统
ADAS/AD数据采集与高性能车载计算解决方案随着智慧工地与无人化施工技术的推进,隧道施工装备的数字化转型已成为行业焦点。近期,在和众多该类客户的沟通过程中,我们观察到了一些被频繁提到的客户需求和场景痛点,针对于此,以隧道运输设备——MSV胶轮车为例,本文为该类客户量身定制了一套高性能多

【精选直播】openDACS 2025 开源EDA与芯片大赛 赛题五 赛题七 直播宣讲会
openDACS2025开源EDA与芯片大赛线上宣讲赛题五:芯片大模型Finetune11月11日(周二)19:30精彩开播|宣讲信息报告题目赛题宣讲:芯片大模型Finetune宣讲嘉宾王颖

【精选直播】openDACS 2025 开源EDA与芯片大赛 赛题六 赛题三 直播宣讲会
openDACS2025开源EDA与芯片大赛线上宣讲赛题六:从Verilog到网表:电路的PPA优化11月04日(周二)19:30精彩开播|宣讲信息报告题目赛题宣讲:从Verilog到网表:电路
亚马逊云科技上线Amazon Nova多模态嵌入模型
专为Agentic RAG与语义搜索量身打造,以行业顶尖的准确率实现跨模态检索 北京2025年10月29日 /美通社/ -- 亚马逊云科技宣布,Amazon Nova Multimodal

【精选直播】openDACS 2025 开源EDA与芯片大赛 赛题二 赛题四 直播宣讲会
openDACS2025开源EDA与芯片大赛线上宣讲赛题二:TestBench生成与验证10月31日(周五)19:30精彩开播|宣讲信息报告题目赛题宣讲:TestBench生成与验证宣讲嘉宾叶靖
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
话:基于历史回答图中女孩头发和衣服分别是什么颜色
上一次我们详细讲解在RK3576上部署多模态模型的案例,这次将继续讲解多轮对话的部署流程。整体流程基于 rknn-llm 里的多轮对话案例[1
发表于 09-05 17:25
浅析多模态标注对大模型应用落地的重要性与标注实例
在人工智能迈向AGI通用智能的关键道路上,大模型正从单一的文本理解者,演进为能同时看、听、读、想的“多面手”。驱动这一进化的核心燃料,正是高质量的多模态数据,而将原始数据转化为“机器可读教材
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
128 512
纯文字:自我介绍纯文字:能回答哪些问题纯文字:谁是爱因斯坦纯文字执行结果
多模态问答能力上述为图片问答的测试准备与初始提问,下文展示‘RK3576 多模态图片问答:测
发表于 08-29 18:08
功率放大器赋能:基于正则模态展开的管道弯曲处导波散射研究
的散射特性对于优化无损检测技术和提高结构健康监测的准确性至关重要。基于正则模态展开(normalmodeexpansion)的方法是研究管道弯曲处导波散射的一种有效手段。该方法通过将导波在管道中的传播分解为一系列正则模态的叠加,进而分析这些

斜齿式超声电机定子振动模态的有限元分析
超声电机是一种利用压电陶瓷逆压电效应制成的全新概念的电机,主要由定子、转子以及施加预压力的机构等部件构成。其中,斜齿式模态转换型超声电机是一种针对大力矩、单一旋向等特殊需求的超声电机。一般情况下
发表于 07-16 19:04
商汤日日新SenseNova融合模态大模型 国内首家获得最高评级的大模型
近日,中国信息通信研究院(以下简称“中国信通院”)完成可信AI多模态大模型首轮评估。 商汤日日新SenseNova融合模态大模型在所有模型中,获得当前最高评级——4+级,并成为国内首家获得最高评级
Android Studio中的Gemini支持多模态输入功能
的 Gemini 现已支持多模态输入,您可在提示中直接添加图像!这为团队协作和界面开发工作流程解锁了更多新的可能性。
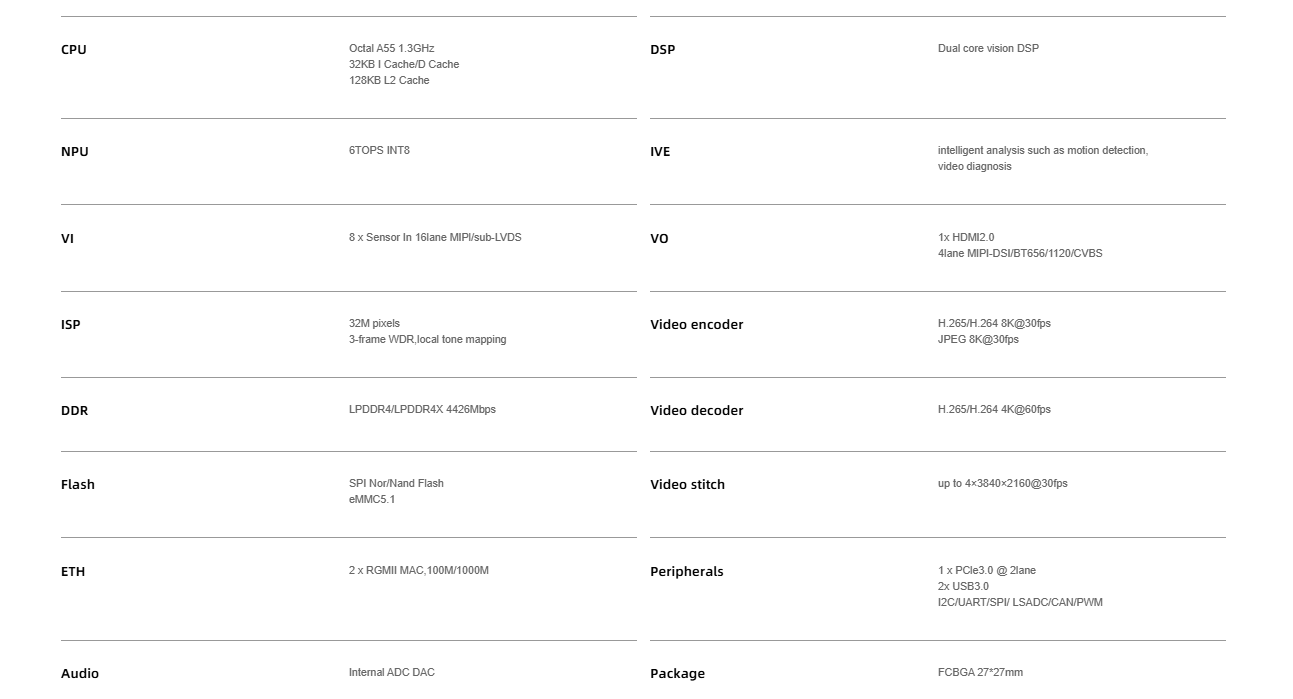
为旌科技VS859:国产具身智能“感算控”一体SoC,赋能边缘多模态智能场景
VS859是上海为旌科技有限公司推出的一款面向国产具身智能的多模态“感算控”一体化单芯片解决方案。是一款专为边缘智能场景设计的高集成度SoC芯片,集成多模态感知接入、高性能异构计算与低时延处理能力,可广泛适配智慧城市、智能机



评论