 Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX
Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX

英特尔的年度创新活动最近在圣何塞举行,该公司希望重新获得在过去几年中慢慢失去的大量技术动力。虽然英特尔一直在努力发布新产品,但进度的延迟和无法向亲临现场的观众展示他们的产品,使该公司及其产品失去了一些光泽。因此,对于在这次自疫情爆发以来举办的最大的现场技术活动,该公司正在尽可能多地展示其产品,以说服媒体、合作伙伴和客户相信其CEO Pat Gelsinger的努力已经使该公司回到了正轨。
在英特尔过去几年的奋斗中,没有比他们的Sapphire Rapids服务器/工作站CPU更好的产品了。作为Intel真正的下一代产品,它带来了从PCIe 5、DDR5到CXL的一切,以及一系列硬件加速卡,对于Sapphire Rapids的延迟,真的没有什么可写的。
但Sapphire Rapids即将到来。英特尔终于能够看到这些开发工作隧道尽头的光亮了。距离2023年第一季度的全面上市只有一个多季度,英特尔终于可以向更多人展示Sapphire Rapids了。或者从更务实的角度来看,英特尔现在需要在Sapphire Rapids的发布之前开始认真推广它。
在今年的展会上,英特尔邀请媒体成员观看预生产的Sapphire Rapids芯片的现场演示。演示的目的,除了让媒体能够说 "我们看到了它;它真的存在!"之外,也是为了开始展示Sapphire Rapids的一个更独特的功能:其专用加速器块的集合。
除了为CPU的处理器核心提供急需的更新外,Sapphire Rapids还为几个常见的CPU关键服务器/工作站工作负载添加了专用加速器块。简单地说,这个想法是,固定功能芯片可以用一小部分功率完成任务,甚至比CPU核心更好,而且只需增加一小部分芯片尺寸。随着超大规模企业和其他服务器运营商在计算密度和能源效率方面寻求重大改进,像这样的特定领域加速器是英特尔向其客户提供这种优势的一个好方法。而且,竞争对手AMD预计不会有类似的加速器模块,这对他们也没有什么影响。
01Sapphire Rapids芯片
在我们进一步讨论之前,我们先来看看Sapphire Rapids芯片的情况。

为了进行演示(以及提供给最终的评测者使用),英特尔使用预生产的芯片组装了一些双插口Sapphire Rapids系统。为了便于拍照,他们打开了一个系统并取出了CPU。

在这一点上,除了它的工作原理外,我们对芯片没有什么可说的。由于它仍然是预生产产品,英特尔没有披露时钟速度或型号,也没有透露非最终芯片的勘误表。但我们所知道的是,这些芯片有60个CPU内核在运行,还有演示的加速器块。
Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX
不算Sapphire Rapids CPU核心上的AVX-512单元,服务器CPU将在每个CPU块中配备4个专用加速器。
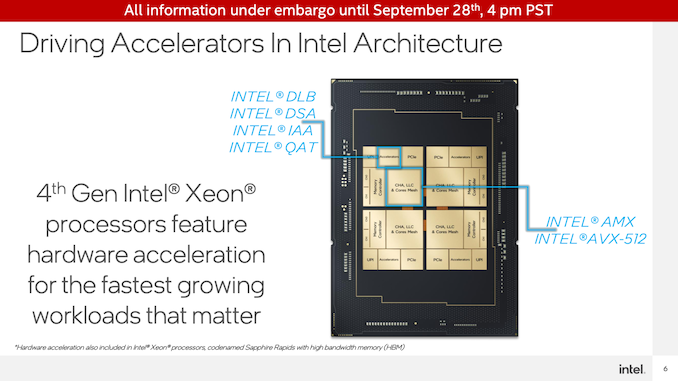
这些加速器是英特尔动态负载平衡器(DLB)、英特尔数据流加速器(DSA)、英特尔内存分析加速器(IAA)和英特尔快速辅助技术(QAT)。所有这些都作为专用设备挂在芯片网格上,本质上是作为PCIe加速器,已经集成到CPU芯片本身。这意味着加速器不消耗CPU核心资源(内存和I/O是另一回事),但这也意味着可用的加速器核心数量不会随着CPU核心数量的增加而直接增加。
在这些加速器中,除了QAT,其他都是英特尔的新产品。QAT是个例外,因为该技术的上一代是在用于第三代至强(Ice Lake-SP)处理器的PCH(芯片组)中实现的,而从Sapphire Rapids开始,它被集成到CPU芯片本身。因此,虽然英特尔实施特定领域的加速器并不是一个新现象,但该公司在Sapphire Rapids的想法上是全力以赴的。

所有这些专用加速块都是为了卸载一组特定的高吞吐量工作负载而设计的。例如,DSA可以加速数据复制和简单计算,例如计算CRC32。同时,QAT是一个加密加速块,也是一个数据压缩/解压缩块。IAA也是类似的,即时数据压缩和解压缩,允许大型数据库(即大数据)以压缩形式保存在内存中。最后,DLB是加速服务器之间负载平衡的一个块。
最后,还有Advanced Matrix Extension(AMX),它是Intel之前宣布的矩阵数学执行块。与张量核和其他类型的矩阵加速器类似,这些是高效执行矩阵数学的超高密度块。与其他加速器类型不同,AMX不是专用加速器,而是CPU内核的一部分,每个内核都有一个块。
AMX是Intel在深度学习市场上的重头戏,通过使用更密集的数据结构,它超越了目前使用AVX-512所能达到的吞吐量。虽然Intel将拥有超越这一点的GPU,但对于Sapphire Rapids,Intel希望解决需要人工智能推理的客户群体,这些推理发生在非常靠近CPU内核的位置,而不是在一个灵活性较低、更专用的加速器中。
02实例演示
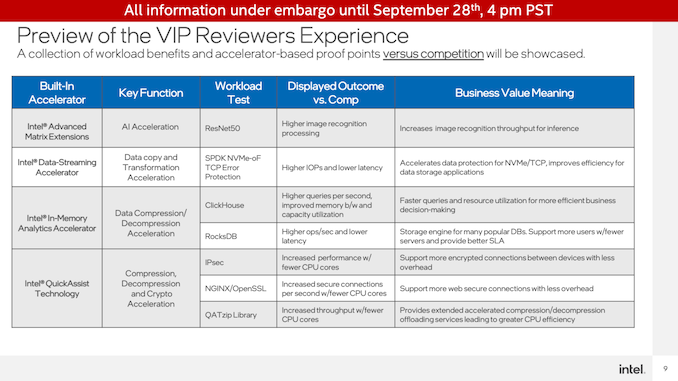
在活动上的演示中,Intel派出了测试团队,设置并展示了一系列利用新加速器的真实情况演示,并可以对其性能进行基准测试。为此,英特尔希望展示其在自己的Sapphire Rapids硬件上与非加速(CPU)操作相比的优势,即为什么应该在这些类型的工作负载中使用其加速器,并展示与在主要竞争对手AMD的EPYC(米兰)CPU上执行相同工作负载相比的性能优势。
当然,英特尔已经在内部运行这些数据。因此,这些演示的目的除了揭示这些性能数据外,还在于展示这些数据是真实的,以及它们是如何获得这些数据的。毫无疑问,这是英特尔想要迈出的最好的一步。但它是用真正的芯片和真正的服务器来实现的,工作负载(对我来说)似乎是测试的合理任务。
QuickAssist技术演示
首先是QuickAssist Technology(QAT)加速器的演示。Intel从NGINX工作负载开始,测量OpenSSL加密性能。
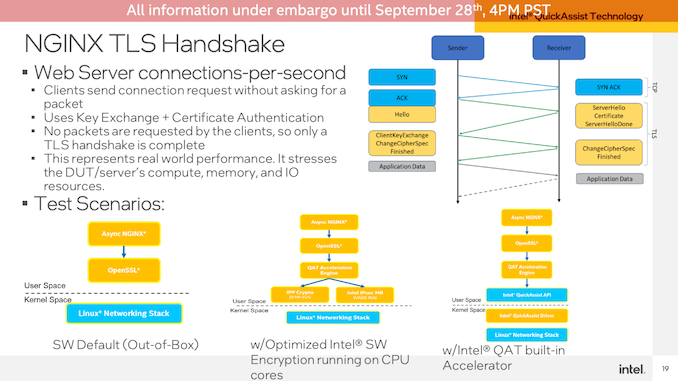
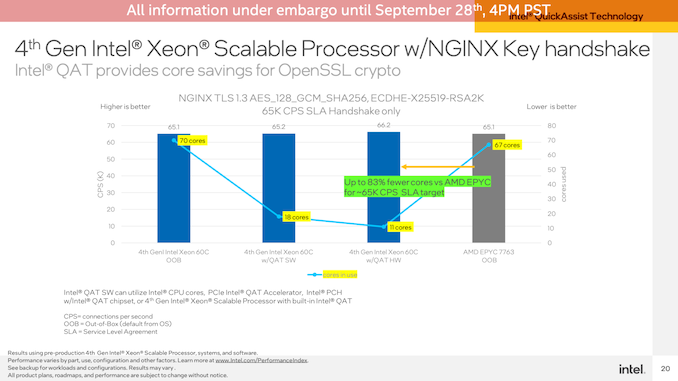
为了达到大致相同的性能,Intel能够在其Sapphire Rapids服务器上实现大约每秒66K的连接,仅使用QAT加速器和120(2x60)个CPU内核中的11个来处理演示的非加速位。相比之下,在Sapphire Rapids上无需任何QAT加速即可实现相同的吞吐量需要67个内核,而在双插槽EPYC 7763服务器上则需要67个核心。


第二个QAT演示是在相同硬件上测量压缩/解压缩性能。正如我们对专用加速器块的期望一样,这个基准测试非常失败。QAT硬件加速器超过了CPU,甚至在使用Intel高度优化的ISA-L库时超过了CPU。与此同时,这几乎是一项完全卸载的任务,因此它消耗了4个CPU内核的时间,而软件工作负载中的所有120/128个CPU内核都是如此。

内存分析加速器演示
第二个演示是内存分析加速器。尽管名称如此,它实际上并没有加速任务的实际分析部分。相反,它是一个压缩/解压缩加速器,准备用于数据库,以便可以在内存中操作它们,而无需大量的CPU性能成本。
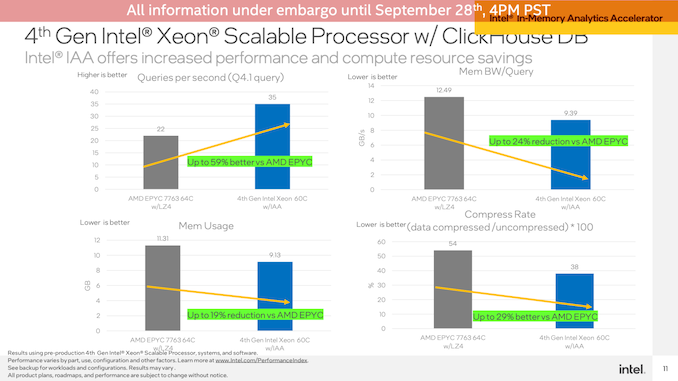
在ClickHouse DB上运行演示,该场景演示了Sapphire Rapids系统与AMD EPYC系统相比,每秒查询数达到59%的性能优势(Intel没有运行仅限软件的Intel设置),并且总体上减少了内存带宽使用量和内存使用量。
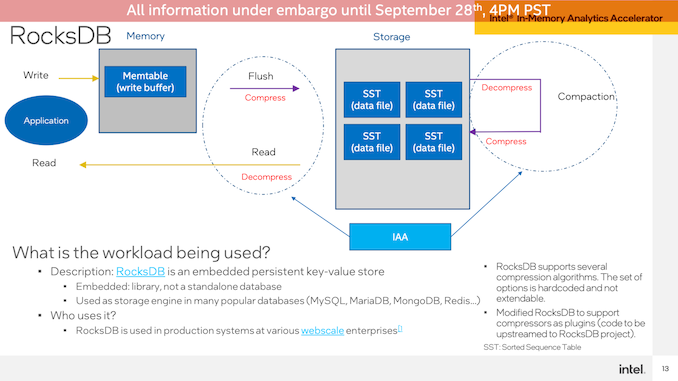
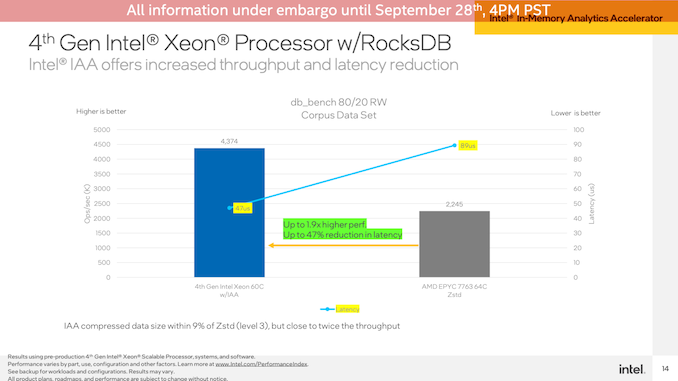
第二次IAA演示是在RocksDB上进行的,使用相同的Intel和AMD系统。Intel再次展示了IAA加速SPR系统,其性能提高了1.9倍,延迟几乎降低了一半。

高级矩阵扩展演示
Intel设置的最后一个演示站配置为显示Advanced Matrix Extensions(AMX)和Data Streaming Accelerator(DSA)。
从AMX开始,Intel使用TensorFlow和ResNet50神经网络运行图像分类基准测试。该测试在CPU上使用了非加速的FP32操作,AVX-512在Sapphire Rapids上加速了INT8,最后AMX也在Sappphire Rapid上加速了INT8。
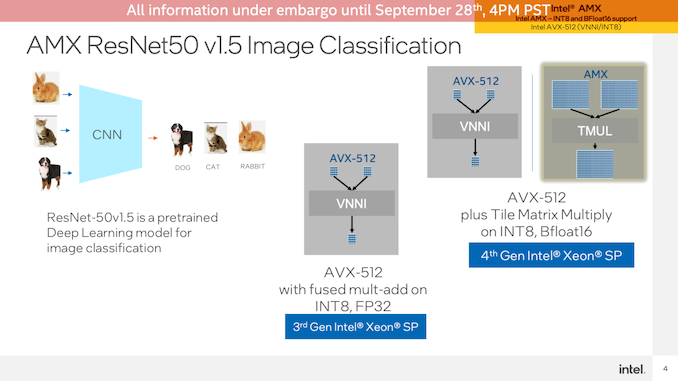

这是加速器的又一次爆炸。由于CPU内核上的AMX块,Sapphire Rapids系统在batch size为1的AVX-512 VNNI模式下的性能提高了2倍,而在bach size为16的情况下,性能提高了两倍以上。当然,与EPYC CPU相比,这种情况看起来更适合Intel,因为当前Milan处理器不提供AVX-512VNNI。这里的总体性能提升不如从纯CPU升级到AVX-512,但AVX-512s本身已经部分成为矩阵加速块(除其他外)。
数据流加速器演示
最后,Intel演示了数据流加速器(DSA)块,该块将在Sapphire Rapids上展示专用的加速器块。在这个测试中,Intel使用FIO设置了一个网络传输演示,让客户端从Sapphire Rapids服务器读取数据。这里使用DSA来卸载用于TCP数据包的CRC32计算,这一操作在Intel测试的非常高的数据速率(2x100GbE连接)下,CPU需求迅速增加。
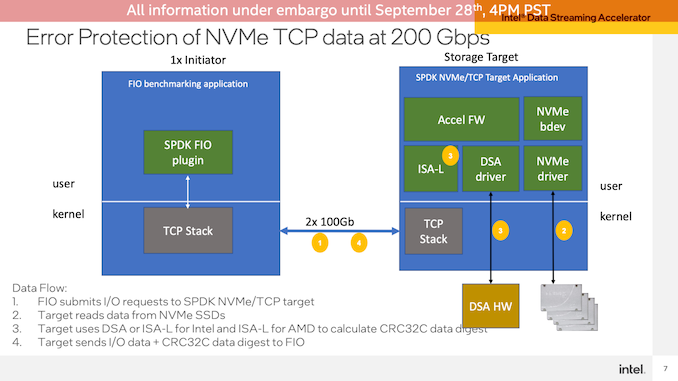
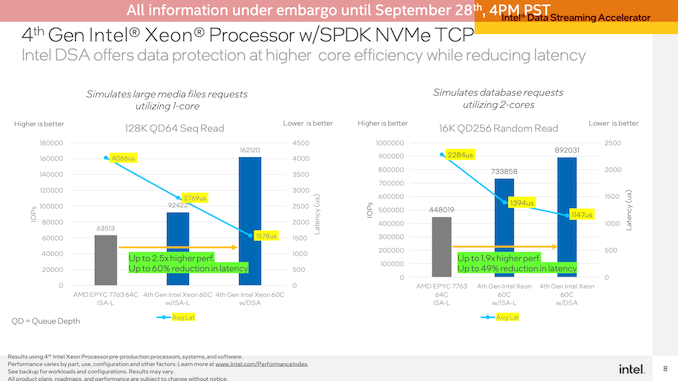
这里使用单个CPU内核来展示效率(因为几个CPU内核就足以使链路饱和),与在相同工作负载上仅使用Intel优化的ISA-L库相比,DSA块允许Sapphire Rapids在128K QD64顺序读取上提供76%的IOPS。EPYC系统的领先优势甚至更大,DSA的延迟远低于2000 us。
使用较小的16K QD256随机读取,在2个CPU内核上运行,也进行了类似的测试。DSA的性能优势在这里没有那么大——与Sapphire Rapids上的优化软件相比,只有22%——但与EPYC相比,它的优势更大,延迟更低。
这就是:在Intel的第4代Xeon(Sapphire Rapids)CPU上首次发布专用加速块(和AMX)的新闻演示。我们看到了它,它确实存在,它是Sapphire Rapids计划从明年开始为客户带来的一切的冰山一角。
鉴于特定于领域的加速器的性质和目的,我觉得这里没有什么应该让普通技术读者感到惊讶的。DSA的存在正是为了加速专用工作负载,特别是那些CPU和/或能源密集型工作负载,这就是Intel在这里所做的。随着服务器市场的竞争预计将成为CPU总体性能的一个热点,这些加速块是Intel为其Xeon处理器增加更多价值的一种方式,并且在AMD和其他推出更多CPU内核的竞争对手中脱颖而出。
预计在未来几个月内,随着英特尔最终将推出下一代服务器CPU,Sapphire Rapids将有更多的应用。
审核编辑 :李倩
-
英特尔
+关注
关注
61文章
10342浏览量
181362 -
cpu
+关注
关注
68文章
11378浏览量
226479 -
加速器
+关注
关注
2文章
841浏览量
40311
原文标题:英特尔Sapphire Rapids硬件加速器的作用大揭秘
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
onsemi通用NPN硅晶体管:NST846BMX2、NST847AMX2、NST847BMX2解析
安森美通用晶体管NST857AMX2和NST857BMX2:性能与应用解析
MAX20326双精度总线加速器:电子设计的理想之选
如何使用 powerquad 加速器中的一些功能以及 CMSIS 原始实现中的一些功能?
AMD Alveo MA35D加速器:开启大规模交互式流媒体新时代
工业级-专业液晶图形显示加速器RA8889ML3N简介+显示方案选型参考表
边缘计算中的AI加速器类型与应用

亚马逊云科技第三期创业加速器圆满收官 助力初创释放Agentic AI潜力 加速全球化进程
航裕电源以大电流技术为国内外超导加速器项目提供优质方案
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持

创客总部加入MathWorks加速器计划
Andes晶心科技推出新一代深度学习加速器
高压放大器在粒子加速器研究中的应用

粒子加速器 —— 科技前沿的核心装置




评论