 文本噪声标签在预训练语言模型(PLMs)上的特性
文本噪声标签在预训练语言模型(PLMs)上的特性

数据的标签错误随处可见,如何在噪声数据集上学习到一个好的分类器,是很多研究者探索的话题。在 Learning With Noisy Labels 这个大背景下,很多方法在图像数据集上表现出了非常好的效果。
而文本的标签错误有时很难鉴别。比如对于一段文本,可能专家对于其主旨类别的看法都不尽相同。这些策略是否在语言模型,在文本数据集上表现好呢?本文探索了文本噪声标签在预训练语言模型(PLMs)上的特性,提出了一种新的学习策略 SelfMix,并机器视觉上常用的方法应用于预训练语言模型作为 baseline。
为什么选 PLMs
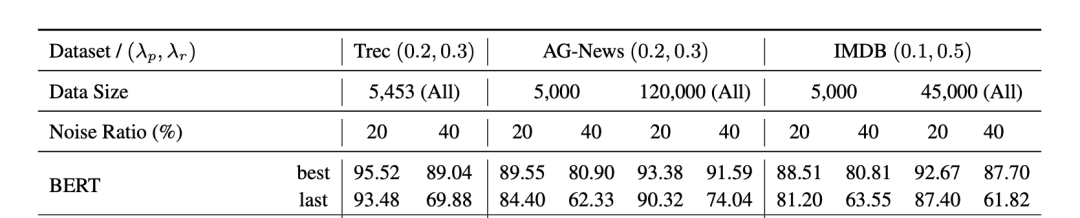
我们对于常见语言分类模型在带噪文本数据集上做了一些前期实验,结果如下:

首先,毫无疑问,预训练模型(BERT,RoBERTa)的表现更好。其次,文章提到,预训练模型已经在大规模的预训练语料上获得了一定的类别先验知识。故而在有限轮次训练之后,依然具有较高的准确率,如何高效利用预训练知识处理标签噪声,也是一个值得探索的话题。
预训练模型虽然有一定的抗噪学习能力,但在下游任务的带噪数据上训练时也会受到噪声标签的影响,这种现象在少样本,高噪声比例的设置下更加明显。
方法
由此,我们提出了 SelfMix,一种对抗文本噪声标签的学习策略。
基础模型上,我们采用了 BERT encoder + MLP 这一常用的分类范式。
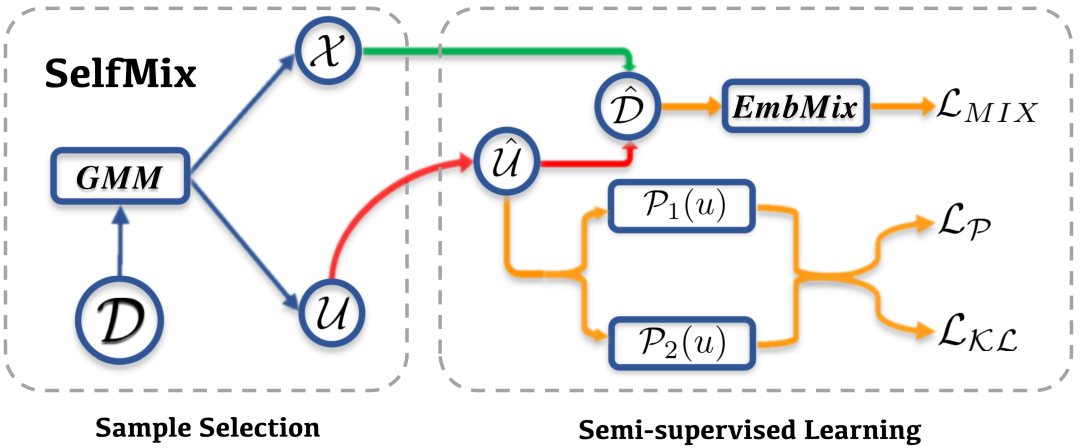
针对带噪学习策略,主要可以分为两个部分
Sample Selection
Semi-supervised Learning
Sample Selection
Sample Selection 部分对于原始数据集 ,经过模型的一次传播,根据每个样本对应的 loss,通过 2 核的 GMM 拟合将数据集分为干净和带噪声的两个部分,分别为 和 。因为其中 被认为是噪声数据集,所以其标签全部被去除,认为是无标签数据集。
这里的 GMM,简单的来讲其实可以看作是根据整体的 loss 动态拟合出一个阈值(而不是规定一个阈值,因为在训练过程中这个阈值会变化),将 loss 位于阈值两边的分别分为 clean samples 和 noise samples。
Semi-supervised Learning
关于 Semi-supervised Learning 部分,SelfMix 首先利用模型给给无标签的数据集打伪标签(这里采用了 soft label 的形式),得到 。因为打伪标签需要模型在这个下游任务上有一定的判别能力,所以模型需要预先 warmup 的少量的步数。
「Textual Mixup」:文中采用了句子 [CLS] embedding 做 mixup。Mixup 也是半监督和鲁棒学习中经常采用的一个策略。
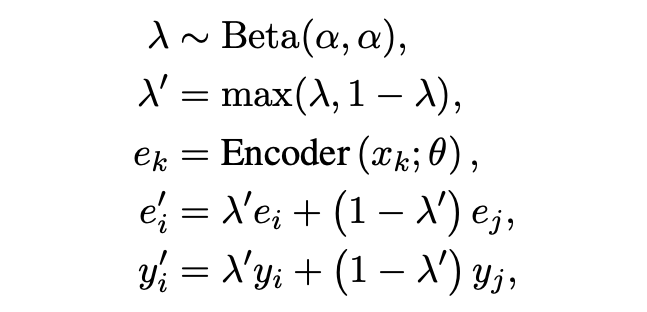
「Pseudo-Loss」:文中的解释比较拗口,其实本质也是一种在半监督训练过程中常用的对模型输出墒的约束。
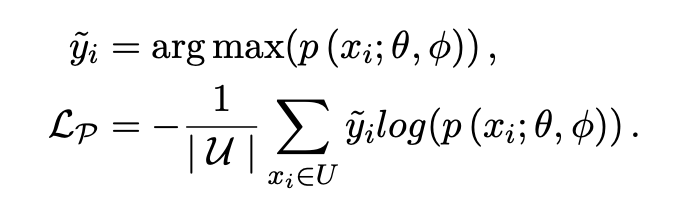
「Self-consistency Regularization」:其他的很多带噪学习方法大都是多模型集成决策的想法,但我们认为可以利用 dropout 机制来使得单个模型做自集成。噪声数据因为与标签的真实分布相悖,往往会导致子模型之间产生很大的分歧,我们不希望在高噪声环境下子模型的分歧越来越大,故而采用了 R-Drop 来约束子模型。具体的做法是,计算两次传播概率分布之间的 KL 散度,作为 loss 的一部分,并且消融实验证明这个方法是十分有效的。
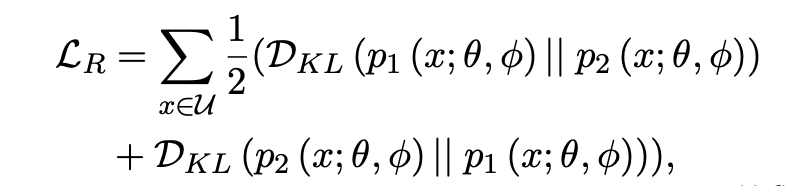
实验
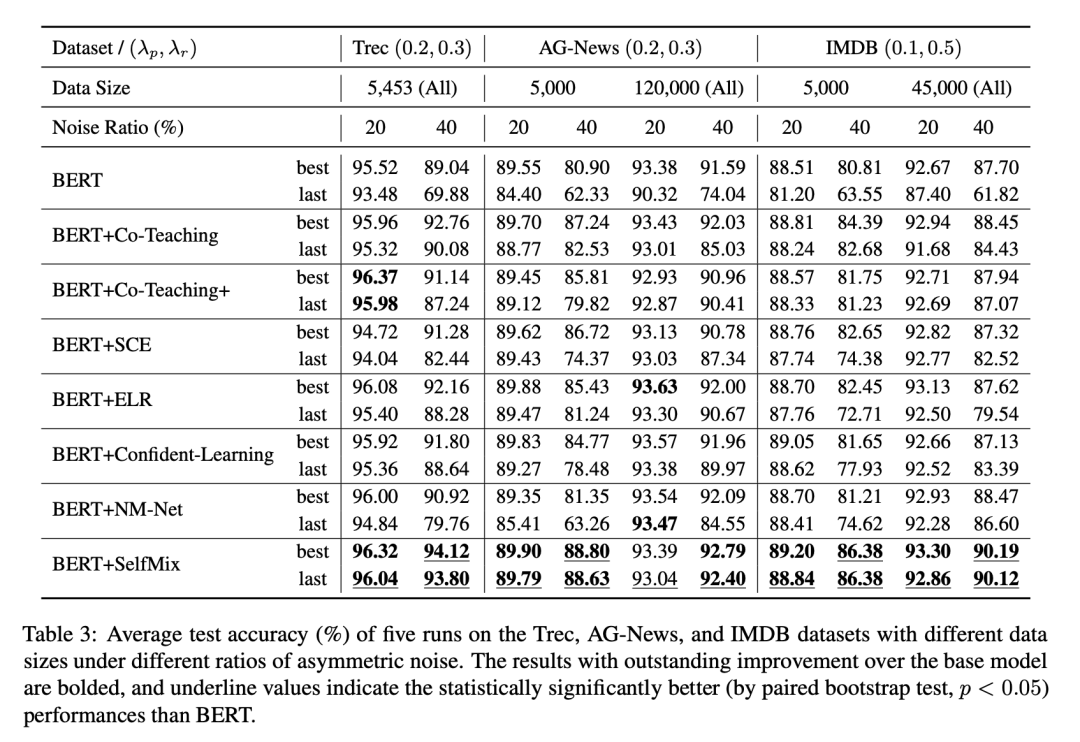
我们在 IDN (Instance-Dependent Noise) 和 Asym (Asymmetric Noise) 做了实验,并且对数据集做了切分来拟合数据充分和数据补充的情况,并设置了不同比例的标签噪声来拟合微量噪声至极端噪声下的情况,上图!
ASYM 噪声实验结果
ASYM 噪声按照一个特定的噪声转移矩阵将一个类别样本的标签随机转换为一个特定类别的标签,来形成类别之间的混淆。
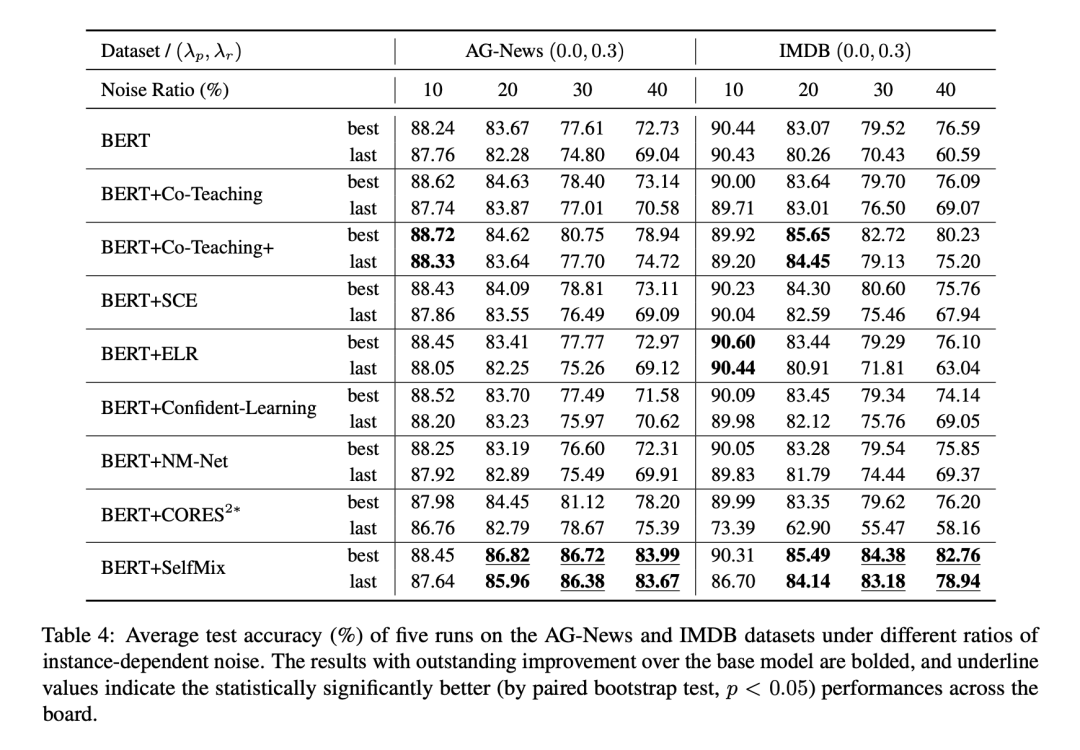
IDN 噪声实验结果
为了拟合基于样本特征的错标情况,我们训练了一个LSTM文本分类,对于一个样本,将LSTM对于其预测结果中更容易错的类别作为其可能的噪声标签。
其他的一些讨论
GMM 是否有效:从 a-c, d-f 可看出高斯混合模型能够比较充分得拟合 clean 和 noise 样本的 loss 分布。
SelfMix 对防止模型过拟合噪声的效果是否明显:d, h 两张图中,BERT-base 和 SelfMix 的 warmup 过程是完全一致的,warmup 过后 SelfMix 确实给模型的性能带来了一定的提升,并且趋于稳定,有效避免了过拟合噪声的现象。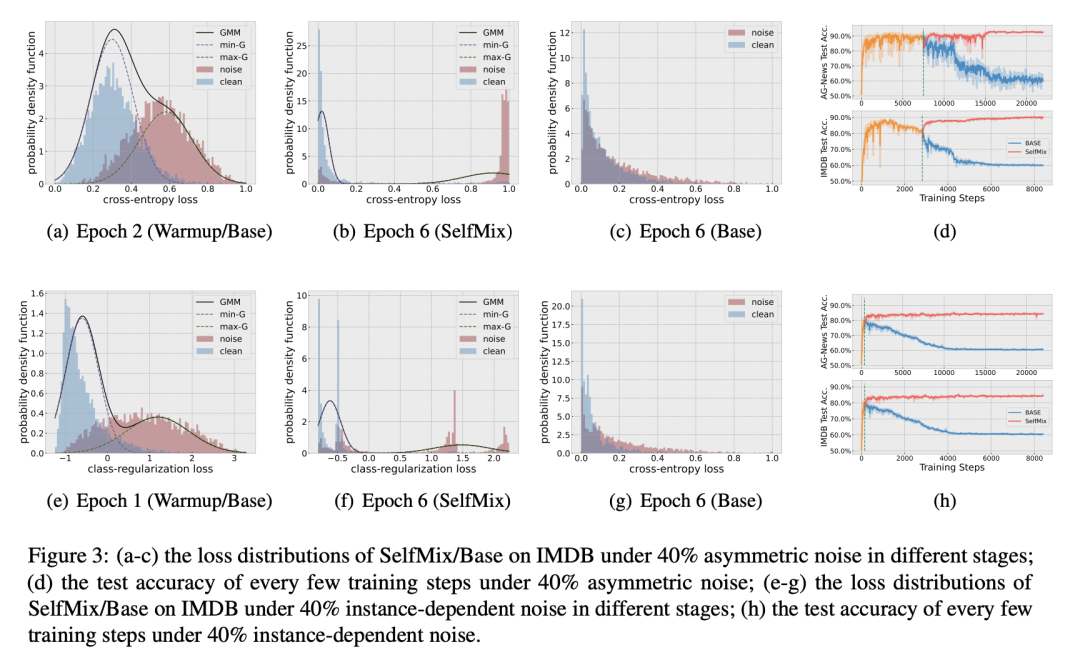
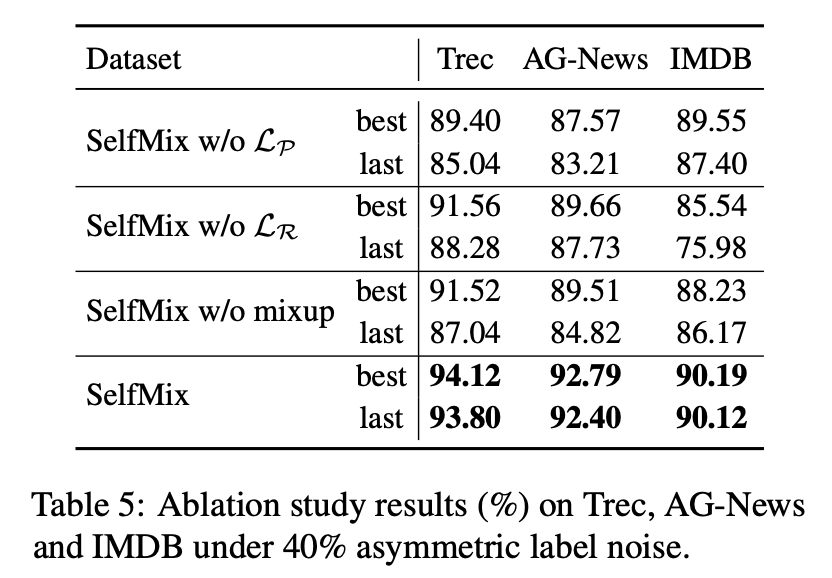
考虑到模型最终的优化目标包括三个项,我们做了消融实验,分别去掉其中一个约束来看看模型表现如何,最终证明每个约束确实对于处理噪声标签有帮助。
-
噪声
+关注
关注
13文章
1162浏览量
49428 -
语言模型
+关注
关注
0文章
575浏览量
11343 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的预训练
基于BERT的中文科技NLP预训练模型

Multilingual多语言预训练语言模型的套路
一种基于乱序语言模型的预训练模型-PERT
利用视觉语言模型对检测器进行预训练
CogBERT:脑认知指导的预训练语言模型
复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型
预训练数据大小对于预训练模型的影响
基于预训练模型和语言增强的零样本视觉学习




评论