 一种基于乱序语言模型的预训练模型-PERT
一种基于乱序语言模型的预训练模型-PERT

写在前面
今天分享给大家一篇哈工大讯飞联合实验室的论文,一种基于乱序语言模型的预训练模型-PERT,全名《PERT: PRE-TRAINING BERT WITH PERMUTED LANGUAGE MODEL》。该篇论文的核心是,将MLM语言模型的掩码词预测任务,替换成词序预测任务,也就是在不引入掩码标记[MASK]的情况下自监督地学习文本语义信息,随机将一段文本的部分词序打乱,然后预测被打乱词语的原始位置。
PERT模型的Github以及对应的开源模型其实年前就出来了,只是论文没有放出。今天一瞬间想起来去看一眼,这不,论文在3月14号的时候挂到了axirv上,今天分享给大家。
paper:https://arxiv.org/pdf/2203.06906.pdf
github:https://github.com/ymcui/PERT
介绍
预训练语言模型(PLMs)目前在各种自然语言处理任务中均取得了优异的效果。预训练语言模型主要分为自编码和自回归两种。自编码PLMs的预训练任务通常是掩码语言模型任务,即在预训练阶段,使用[MASK]标记替换原始输入文本中的一些token,并在词汇表中恢复这些被[MASK]的token。
常用预训练语言模型总结:https://zhuanlan.zhihu.com/p/406512290
那么,自编码PLMs只能使用掩码语言模型任务作为预训练任务吗?我们发现一个有趣的现象“在一段文本中随机打乱几个字并不会影响我们对这一段文本的理解”,如下图所示,乍一看,可能没有注意到句子中存在一些乱序词语,并且可以抓住句子的中心意思。该论文探究了是否可以通过打乱句子中的字词来学习上下文的文本表征,并提出了一个新的预训练任务,即乱序语言模型(PerLM)。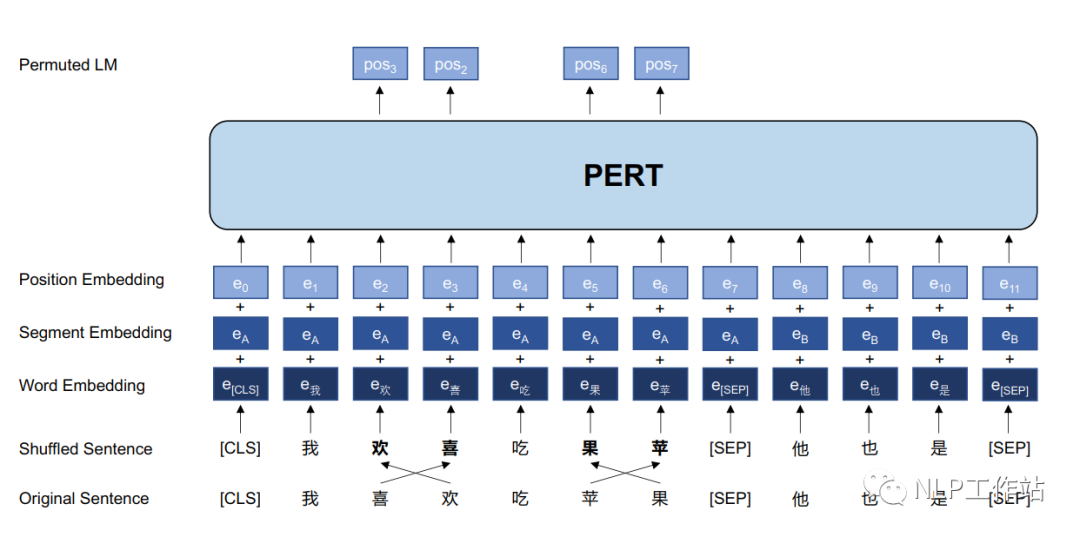
模型
PERT模型结构如上图所示。PERT模型结构与BERT模型结构相同,仅在模型输入以及预训练目标上略有不同。
PERT模型的细节如下:
- 采用乱序语言模型作为预训练任务,预测目标为原始字词的位置;
- 预测空间大小取决于输入序列长度,而不是整个词表的大小(掩码语言模型预测空间为词表);
- 不采用NSP任务;
- 通过全词屏蔽和N-gram屏蔽策略来选择乱序的候选标记;
- 乱序的候选标记的概率为15%,并且真正打乱顺序仅占90%,剩余10%保持不变。
由于乱序语言模型不使用[MASK]标记,减轻了预训练任务与微调任务之间的gap,并由于预测空间大小为输入序列长度,使得计算效率高于掩码语言模型。PERT模型结构与BERT模型一致,因此在下游预训练时,不需要修改原始BERT模型的任何代码与脚本。注意,与预训练阶段不同,在微调阶段使用正常的输入序列,而不是打乱顺序的序列。
中文实验结果与分析
预训练参数
- 数据:由中文维基百科、百科全书、社区问答、新闻文章等组成,共5.4B字,大约20G。
- 训练参数:词表大小为21128,最大序列长度为512,batch大小为416(base版模型)和128(large版模型),初始学习率为1e-4,使用 warmup动态调节学习率,总训练步数为2M,采用ADAM优化器。
- 训练设备:一台TPU,128G。
机器阅读理解MRC任务
在CMRC2018和DRCD两个数据集上对机器阅读理解任务进行评测,结果如下表所示。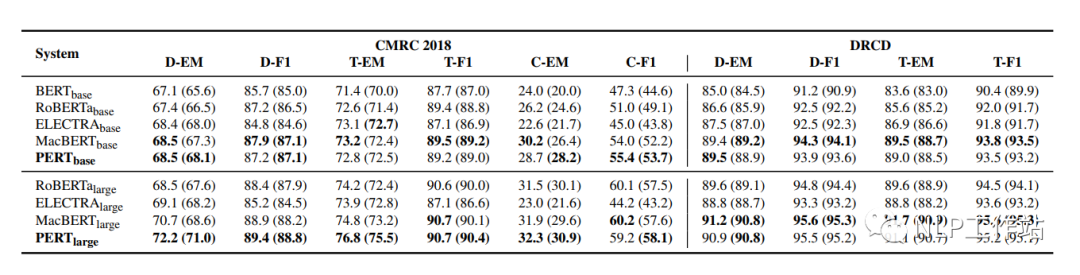
PERT模型相比于MacBERT模型有部分的提高,并且始终优于其他模型。
文本分类TC任务
在XNLI、LCQMC、BQ Corpus、ChnSentiCorp、TNEWS和OCNLI 6个数据集上对文本分类任务进行评测,结果如下表所示。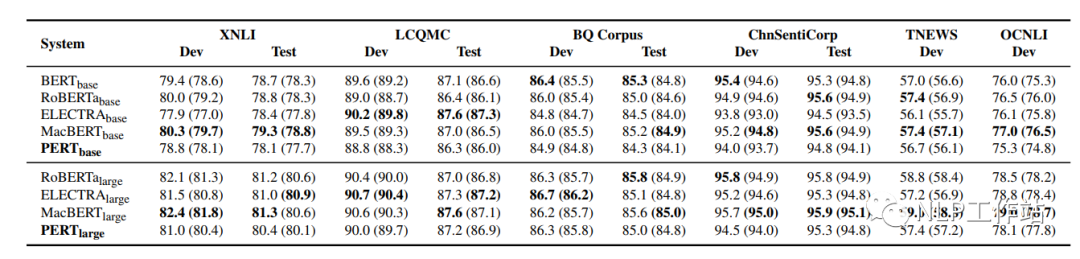
在文本分类任务上,PERT模型表现不佳。推测与MRC任务相比,预训练中的乱序文本给理解短文本带来了困难。
命名实体识别NER任务
在MSRA-NER和People’s Daily两个数据集上对命名实体识别任务进行评测,结果如下表所示。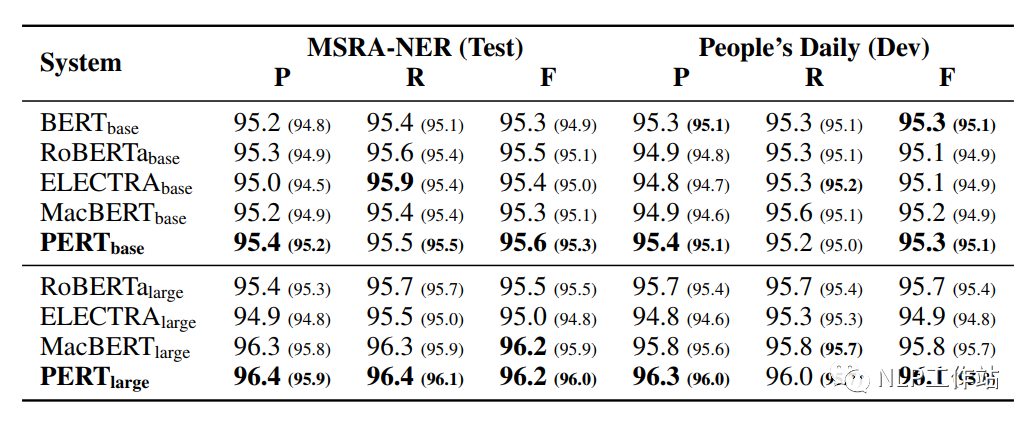
PERT模型相比于其他模型均取得最优的效果,表明预训练中的乱序文在序列标记任务中的良好能力。
对比机器阅读理解、文本分类和命名实体识别三个任务,可以发现,PERT模型在MRC和NER任务上表现较好,但在TC任务上表现不佳,这意味着TC任务对词语顺序更加敏感,由于TC任务的输入文本相对较短,有些词语顺序的改变会给输入文本带来完全的意义变化。然而,MRC任务的输入文本通常很长,几个单词的排列可能不会改变整个文章的叙述流程;并且对于NER任务,由于命名实体在整个输入文本中只占很小的比例,因此词语顺序改变可能不会影响NER进程。
语法检查任务
在Wikipedia、Formal Doc、Customs和Legal 4个数据集上对文本分类任务进行评测语法检查任务进行评测,结果如下表所示。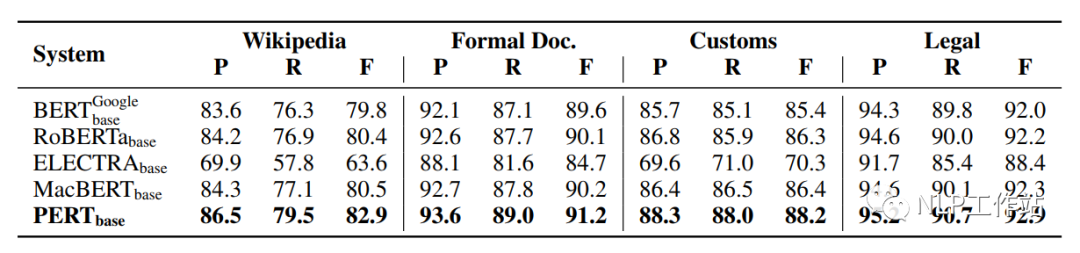
PERT模型相比于其他模型均取得最优的效果,这是由于下游任务与预训练任务非常相似导致的。
预训练的训练步数对PERT模型的影响
不同的下游任务的最佳效果可能出现在不同的预训练步骤上,如下图所示。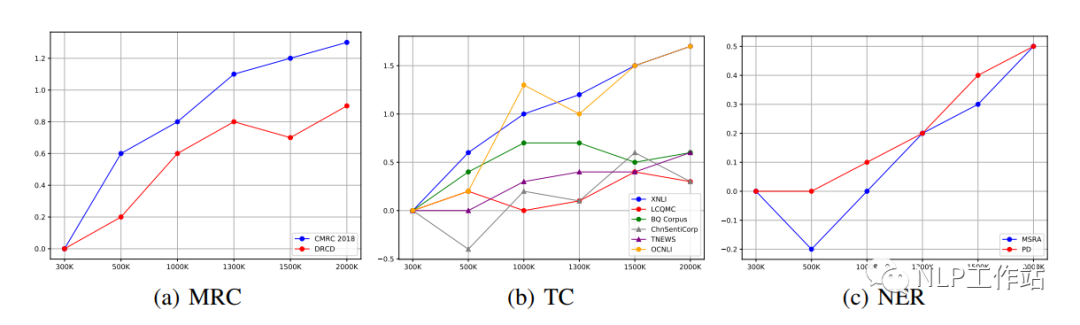
我们发现对于MRC和NER任务,随着预训练步数的增加,下游任务也会随之提高。然而,对于TC任务,不同数据的指标在不同的步数上取得最优。如果考虑到特定任务的效果,有必要在早期训练中保存部分模型。
不同的打乱粒度对PERT模型的影响
不同粒度间的打乱,可以使使输入文本更具可读性。通过在不同粒度内乱序输入文本来比较性能,如下表所示。
我们发现,在各种打乱粒度中,无限制乱序的PERT模型在所有任务中都取得了最优的效果;而选择最小粒度(词语之间)的模型,效果最差。可能原因是,虽然使用更小的粒度的乱序可以使输入文本更具可读性,但是对预训练任务的挑战性较小,使模型不能学习到更好地语义信息。
不同预测空间对PERT模型的影响
将PERT模型使用词表空间作为预测目标是否有效?如下表所示。
实验结果表明,PERT模型不需要在词表空间中进行预测,其表现明显差于在输入序列上的预测;并且将两者结合的效果也不尽如人意。
预测部分序列和预测全部序列对PERT模型的影响
ELECTRA模型的实验发现预测完全序列的效果比部分序列的更好,因此ELECTRA模型采用RTD任务对判别器采用完全序列预测。但通过本论文实验发现,预测完全序列在PERT模型中并没有产生更好的效果。表明在预训练任务中使用预测全部序列并不总是有效的,需要根据所设计的预训练任务进行调整。
总结
PERT模型的预训练思路还是挺有意思的,并在MRC、NER和WOR任务上均取得了不错的效果。并且由于结构与BERT模型一致,因此在下游任务使用时,仅修改预训练模型加载路径就实现了模型替换,也比较方便。当打比赛或者做业务时候,可以不妨试一试,说不定有奇效。(ps:我在我们自己的MRC数据集上做过实验,效果不错呦!!)
审核编辑 :李倩
-
语言模型
+关注
关注
0文章
575浏览量
11382 -
自然语言处理
+关注
关注
1文章
630浏览量
14767
原文标题:PERT:一种基于乱序语言模型的预训练模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

零基础手写大模型资料2026
Edge Impulse 唤醒词模型训练 | 技术集结


什么是大模型,智能体...?大模型100问,快速全面了解!

摩尔线程新一代大语言模型对齐框架URPO入选AAAI 2026
在Ubuntu20.04系统中训练神经网络模型的一些经验
基于大规模人类操作数据预训练的VLA模型H-RDT

如何进行YOLO模型转换?
利用自压缩实现大型语言模型高效缩减




评论