 高端GPU芯片拉警报,国产算力芯片能力如何?
高端GPU芯片拉警报,国产算力芯片能力如何?

电子发烧友网报道(文/李弯弯)近日,英伟达高端GPU对中国供应受到限制的消息,引起热议。8月31日,英伟达发布公告称,美国通知公司向中国出口A100和H100芯片将需要新的许可证要求,同时DGX或任何其他包含A100或H100芯片的产品,以及未来性能高于A100的芯片都将受到新规管制。
9月1日,英伟达方面又表示已经获得出口许可。尽管如此,美国这番操作必然引起国内相关企业的警惕,接下来中国的互联网、云服务厂商可能会积极自研芯片,或者更多采用国内企业提供的算力芯片,然而目前国内的算力芯片能力如何呢?
A100和H100出口限制,对中国有何影响
英伟达是全球GPU领域的绝对龙头,A100是其2020年推出的数据中心级云端加速芯片,拥有540亿晶体管,采用台积电7nm工艺制程,支持FP16、FP32和FP64浮点运算,为人工智能、数据分析和HPC数据中心等提供算力。
相比于上一代V100,A100在AI训练和推理、HPC上性能都有很大的改进。据英伟达在今年8月透露,特斯拉采用了7000块A100芯片升级了其用来训练自动驾驶系统的超算中心。
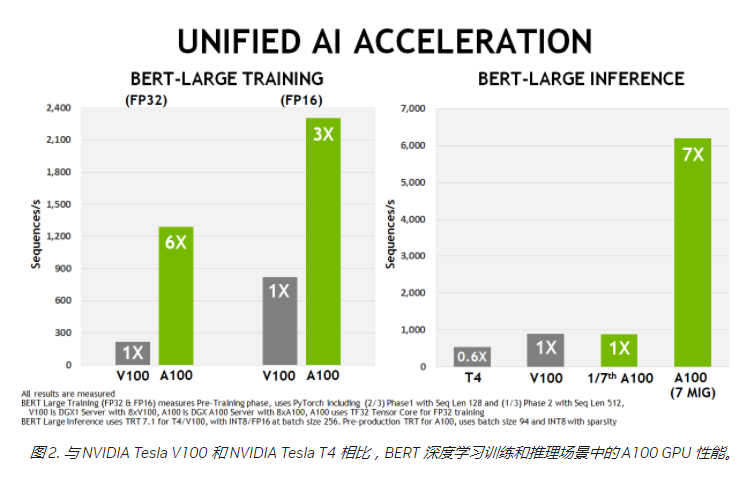
H100是英伟达今年3月发布的最新一代数据中心GPU,集成800亿晶体管,采用台积电定制的4nm工艺,预计在今年下半年正式发货,英伟达CEO黄仁勋此前表示,这款GPU具有超强的计算能力,20个H100 GPU便可承托相当于全球互联网的流量。相比于A100,H100在FP16、FP32和FP64计算上比A100快三倍,非常适用于当下流行且训练难度高的大模型。
如果A100和H100芯片出口受到限制,对中国有何影响?目前国内高端场景基本采用英伟达的A100,包括OEM厂商浪潮、联想等,云服务公司阿里、腾讯、百度等,对于即将量产的H100,国内主流厂商也已经预定,如阿里云、百度云和腾讯云等,而且目前国内没有能够与其相对标的硬件产品,如果限制,这些厂商在一些高端的应用上将无法买到可替代产品。
不过有行业分析师表示,如果出口限制,确实只是对一些高端厂商的应用有影响,而在更普遍的应用场景中,英伟达的产品并不在限制的范围,而且国内也有可替代的产品。
国产算力芯片如何突围
从长远来看,加速算力芯片的发展是必然的,那么国内算力芯片的能力怎样,如何突围呢?目前服务器加速,主要采用的是GPU芯片,占比接近90%,另外则是ASIC、FPGA等。
GPGPU芯片广泛用于商业计算和大数据处理,如天气预报、工业设计、基因工程、药物发现、金融工程等,在人工智能领域,使用GPGPU在云端运行模型训练算法,可以显著缩短海量训练数据的训练时长,减少能源消耗,从而进一步降低人工智能的应用成本。
不同应用领域,对芯片计算能力及运算精度要求也有所不同,比如用于商业计算和大数据处理(CAE仿真、物理化学、石油勘探、生命科学、气象环境等),需要双精度浮点、单精度浮点、32位整型运算;人工智能(模型训练、应用推理),要求混合精度浮点、半精度浮点、16位整型、8位整型运算。
近几年国内不少企业在这方面取得进展,包括海光信息、壁仞科技、燧原科技、摩尔线程等。
海光信息成立于2014年,不久前在科创板上市,海光信息的产品包括通用处理器(CPU)和协处理器(DCU),海光DCU属于GPGPU的一种。
海光DCU 8000系列,典型功耗260-350W,支持INT4、INT8、FP16、FP32、FP64运算精度,支持4个HBM2内存通道,最高内存带宽为1TB/s、最大内存容量为32GB。海光DCU协处理器全面兼容ROCm GPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,CUDA用户可以以较低代价快速迁移至ROCm平台。
可以看到,海光DCU是国内唯一支持FP64双精度浮点运算的产品,英伟达的A100、H100都支持FP64,从这一点来看,海光DCU在这方面是比较领先的。
壁仞科技今年8月发布的首款通用GPU BR100,集成770亿晶体管,支持FP16半精度浮点运算,在这方面相比英伟达、海光DCU较弱,不过据该公司介绍,BR100的16位浮点算力能达到1000T以上,8位定点算力达到2000T以上,超过英伟达的A100。
另外燧原科技此前发布的第二代人工智能训练产品邃思2.0,支持从FP32、TF32、FP16、BF16 到INT8运算,单精度FP32峰值算力40 TFLOPS,单精度张量TF32峰值算力160 TFLOPS。
天数智芯的BI芯片,集成240亿晶体管,采用7纳米先进制程,支持FP32、FP16、BF16、INT8等多精度数据混合训练,单芯算力每秒147T@FP16。
另外值得关注的还有,寒武纪2021年11月发布的第三代云端AI芯片思元370,相比于上一代芯片,思元370全面加强了FP16、BF16以及FP32的浮点算力,在全新MLUarch03架构和7nm先进工艺加持下,8位定点算力最高为256TOPS。
对比来看,目前国内厂商的芯片水平,相比于英伟达的A100和H100是存在差距的。不过在国内市场需求和美国出口限制的背景下,这些芯片厂商具有足够的技术和经验积累,去实现进一步的突破。
那么国内的芯片厂商需要如何突围呢?难度肯定是大的,燧原科技创始人赵立东在日前世界人工智能大会的论坛上谈到,国际巨头用几代人、数十年的时间投入积攒下的技术实力,我们想靠两代和几十名工程师就超越,是不可能的。
要缩短差距,除了资金、人力等的高密集投入外,也需要有更快的更迭,还有就是架构创新,赵立东认为,唯有架构实现原始创新,才能真正拥抱开放生态,使产业得到健康发展。
另外与国外芯片执着于先进的制程,国内不少厂商开始通过更先进的封装工艺、异构芯片等来寻求突破。比如寒武纪思元370采用chiplet技术,在一颗芯片中封装2颗AI计算芯粒(MLU-Die),每一个 MLU-Die 具备独立的AI计算单元、内存、IO以及 MLU-Fabric控制和接口,通过MLU-Fabric保证两个MLU-Die间的高速通讯,可以通过不同MLU-Die组合规格多样化的产品,为用户提供适用不同场景的高性价比AI芯片,壁仞科技今年8月发布的GPU BR100GPU芯片也采用了Chiplet技术。
小结
整体而言,美国限制英伟达高端GPU芯片A100和H100的出口,短期来看对中国的影响不是很大,反而对于国内算力芯片的发展或许具有促进作用。
从目前国内芯片厂商的产品来看,与英伟达A100和H100存在差距,不过也有海光信息、壁仞科技等在某些方面已经取得突破的企业,未来想要超越仍然存在困难,然而却让人相信一点点取得突破是有可能的。
9月1日,英伟达方面又表示已经获得出口许可。尽管如此,美国这番操作必然引起国内相关企业的警惕,接下来中国的互联网、云服务厂商可能会积极自研芯片,或者更多采用国内企业提供的算力芯片,然而目前国内的算力芯片能力如何呢?
A100和H100出口限制,对中国有何影响
英伟达是全球GPU领域的绝对龙头,A100是其2020年推出的数据中心级云端加速芯片,拥有540亿晶体管,采用台积电7nm工艺制程,支持FP16、FP32和FP64浮点运算,为人工智能、数据分析和HPC数据中心等提供算力。
相比于上一代V100,A100在AI训练和推理、HPC上性能都有很大的改进。据英伟达在今年8月透露,特斯拉采用了7000块A100芯片升级了其用来训练自动驾驶系统的超算中心。
H100是英伟达今年3月发布的最新一代数据中心GPU,集成800亿晶体管,采用台积电定制的4nm工艺,预计在今年下半年正式发货,英伟达CEO黄仁勋此前表示,这款GPU具有超强的计算能力,20个H100 GPU便可承托相当于全球互联网的流量。相比于A100,H100在FP16、FP32和FP64计算上比A100快三倍,非常适用于当下流行且训练难度高的大模型。
如果A100和H100芯片出口受到限制,对中国有何影响?目前国内高端场景基本采用英伟达的A100,包括OEM厂商浪潮、联想等,云服务公司阿里、腾讯、百度等,对于即将量产的H100,国内主流厂商也已经预定,如阿里云、百度云和腾讯云等,而且目前国内没有能够与其相对标的硬件产品,如果限制,这些厂商在一些高端的应用上将无法买到可替代产品。
不过有行业分析师表示,如果出口限制,确实只是对一些高端厂商的应用有影响,而在更普遍的应用场景中,英伟达的产品并不在限制的范围,而且国内也有可替代的产品。
国产算力芯片如何突围
从长远来看,加速算力芯片的发展是必然的,那么国内算力芯片的能力怎样,如何突围呢?目前服务器加速,主要采用的是GPU芯片,占比接近90%,另外则是ASIC、FPGA等。
GPGPU芯片广泛用于商业计算和大数据处理,如天气预报、工业设计、基因工程、药物发现、金融工程等,在人工智能领域,使用GPGPU在云端运行模型训练算法,可以显著缩短海量训练数据的训练时长,减少能源消耗,从而进一步降低人工智能的应用成本。
不同应用领域,对芯片计算能力及运算精度要求也有所不同,比如用于商业计算和大数据处理(CAE仿真、物理化学、石油勘探、生命科学、气象环境等),需要双精度浮点、单精度浮点、32位整型运算;人工智能(模型训练、应用推理),要求混合精度浮点、半精度浮点、16位整型、8位整型运算。
近几年国内不少企业在这方面取得进展,包括海光信息、壁仞科技、燧原科技、摩尔线程等。
海光信息成立于2014年,不久前在科创板上市,海光信息的产品包括通用处理器(CPU)和协处理器(DCU),海光DCU属于GPGPU的一种。
海光DCU 8000系列,典型功耗260-350W,支持INT4、INT8、FP16、FP32、FP64运算精度,支持4个HBM2内存通道,最高内存带宽为1TB/s、最大内存容量为32GB。海光DCU协处理器全面兼容ROCm GPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,CUDA用户可以以较低代价快速迁移至ROCm平台。
可以看到,海光DCU是国内唯一支持FP64双精度浮点运算的产品,英伟达的A100、H100都支持FP64,从这一点来看,海光DCU在这方面是比较领先的。
壁仞科技今年8月发布的首款通用GPU BR100,集成770亿晶体管,支持FP16半精度浮点运算,在这方面相比英伟达、海光DCU较弱,不过据该公司介绍,BR100的16位浮点算力能达到1000T以上,8位定点算力达到2000T以上,超过英伟达的A100。
另外燧原科技此前发布的第二代人工智能训练产品邃思2.0,支持从FP32、TF32、FP16、BF16 到INT8运算,单精度FP32峰值算力40 TFLOPS,单精度张量TF32峰值算力160 TFLOPS。
天数智芯的BI芯片,集成240亿晶体管,采用7纳米先进制程,支持FP32、FP16、BF16、INT8等多精度数据混合训练,单芯算力每秒147T@FP16。
另外值得关注的还有,寒武纪2021年11月发布的第三代云端AI芯片思元370,相比于上一代芯片,思元370全面加强了FP16、BF16以及FP32的浮点算力,在全新MLUarch03架构和7nm先进工艺加持下,8位定点算力最高为256TOPS。
对比来看,目前国内厂商的芯片水平,相比于英伟达的A100和H100是存在差距的。不过在国内市场需求和美国出口限制的背景下,这些芯片厂商具有足够的技术和经验积累,去实现进一步的突破。
那么国内的芯片厂商需要如何突围呢?难度肯定是大的,燧原科技创始人赵立东在日前世界人工智能大会的论坛上谈到,国际巨头用几代人、数十年的时间投入积攒下的技术实力,我们想靠两代和几十名工程师就超越,是不可能的。
要缩短差距,除了资金、人力等的高密集投入外,也需要有更快的更迭,还有就是架构创新,赵立东认为,唯有架构实现原始创新,才能真正拥抱开放生态,使产业得到健康发展。
另外与国外芯片执着于先进的制程,国内不少厂商开始通过更先进的封装工艺、异构芯片等来寻求突破。比如寒武纪思元370采用chiplet技术,在一颗芯片中封装2颗AI计算芯粒(MLU-Die),每一个 MLU-Die 具备独立的AI计算单元、内存、IO以及 MLU-Fabric控制和接口,通过MLU-Fabric保证两个MLU-Die间的高速通讯,可以通过不同MLU-Die组合规格多样化的产品,为用户提供适用不同场景的高性价比AI芯片,壁仞科技今年8月发布的GPU BR100GPU芯片也采用了Chiplet技术。
小结
整体而言,美国限制英伟达高端GPU芯片A100和H100的出口,短期来看对中国的影响不是很大,反而对于国内算力芯片的发展或许具有促进作用。
从目前国内芯片厂商的产品来看,与英伟达A100和H100存在差距,不过也有海光信息、壁仞科技等在某些方面已经取得突破的企业,未来想要超越仍然存在困难,然而却让人相信一点点取得突破是有可能的。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
芯片
+关注
关注
462文章
53534浏览量
459018 -
gpu
+关注
关注
28文章
5099浏览量
134447
发布评论请先 登录
相关推荐
热点推荐
华为领衔,三剑客入局!十万卡智算集群落地,国产算力芯片强势崛起
的“驱动燃料”。中移动在现场展示了“国芯国连”AI算力集群,移动云磐石智算交换机、超级点AI算力集群也闪亮登场。在奔向AI+时代当中,AI

“四算合一”算力平台,芯片国产化率超九成,兼容8种国产AI芯片
电子发烧友网报道(文/李弯弯)4月11日消息,由中国移动承建的全国首个“四算合一”算力网络调度平台正式投入使用。四算合一是指将通用算
融资超20亿,这家“非GPU”芯片公司跻身国产AI算力第一梯队
电子发烧友报道(文/黄晶晶)谷歌 TPU 对英伟达 GPU 的直接竞争,引发市场广泛关注。而如今,中国 AI 芯片领域也正加速布局,发力非GPU芯片


“汽车智能化” 和 “家电高端化”
“带轮子的超级计算机” 了!而这一切都离不开 7nm 级别的高算力芯片:
智能座舱的 “大脑” 需求:现在新车流行的 7 屏联动、4K 高清显示、语音控制、人脸识别,都需要芯片有超
发表于 10-28 20:46
国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?
最近行业都在说“算力是AI的命门”,但国产芯片真的能接住这波需求吗?
前阵子接触到海思昇腾910B,实测下来有点超出预期——7nm工艺下算
发表于 10-27 13:12
阿里自研AI芯片央视曝光,国产算力崛起新里程碑
,因为其中披露了阿里旗下平头哥最新研发的面向人工智能的PPU芯片。这一曝光,不仅让大众看到了阿里在AI芯片领域的深厚积累与卓越成果,更标志着国产AI芯片产业迈向了新的发展阶段。 从
摩尔线程副总裁王华:AI工厂全栈技术重构算力基建,开启国产 GPU 黄金时代
协同,重新定义了 AI 基础设施的生产力公式 ——AI 工厂生产效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性。作为国内率先实现单

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
前言
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」书中的芯片知识是比较接近当前的顶尖芯
发表于 06-18 19:31
AIGC算力基础设施技术架构与行业实践
代提升1.5倍,内存容量达288GB,适配千亿参数模型训练需求。 国产突破:国内首款6nm高性能GPU芯片于2025年5月成功点亮,性能对标国际中端产品,已获亿元级订单;国产
大算力芯片的生态突围与算力革命
电子发烧友网报道(文 / 李弯弯)大算力芯片,即具备强大计算能力的集成电路芯片,主要应用于高性能计算(HPC)、人工智能(AI)、数据中心、
DeepSeek对芯片算力的影响
DeepSeek模型,尤其是其基于MOE(混合专家)架构的DeepSeek-V3,对芯片算力的要求产生了深远影响。为了更好地理解这一影响,我们可以从几个方面进行分析。一.MOE架构对算


算智算中心的算力如何衡量?
(ComputationalPower)是指智算中心通过其内部的计算设备(如CPU、GPU、AI芯片等)对数据进行处理和计算的能力。它体现了智算






 工商网监
工商网监
评论