 多模态图像合成与编辑方法
多模态图像合成与编辑方法

本篇综述通过对现有的多模态图像合成与编辑方法的归纳总结,对该领域目前的挑战和未来方向进行了探讨和分析。
近期 OpenAI 发布的 DALLE-2 和谷歌发布的 Imagen 等实现了令人惊叹的文字到图像的生成效果,引发了广泛关注并且衍生出了很多有趣的应用。而文字到图像的生成属于多模态图像合成与编辑领域的一个典型任务。 近日,来自马普所和南洋理工等机构的研究人员对多模态图像合成与编辑这一大领域的研究现状和未来发展做了详细的调查和分析。

论文地址:https://arxiv.org/pdf/2112.13592.pdf
项目地址:https://github.com/fnzhan/MISE

在第一章节,该综述描述了多模态图像合成与编辑任务的意义和整体发展,以及本论文的贡献与总体结构。 在第二章节,根据引导图片合成与编辑的数据模态,该综述论文介绍了比较常用的视觉引导(比如 语义图,关键点图,边缘图),文字引导,语音引导,场景图(scene graph)引导和相应模态数据的处理方法以及统一的表示框架。 在第三章节,根据图像合成与编辑的模型框架,该论文对目前的各种方法进行了分类,包括基于 GAN 的方法,自回归方法,扩散模型方法,和神经辐射场(NeRF)方法。
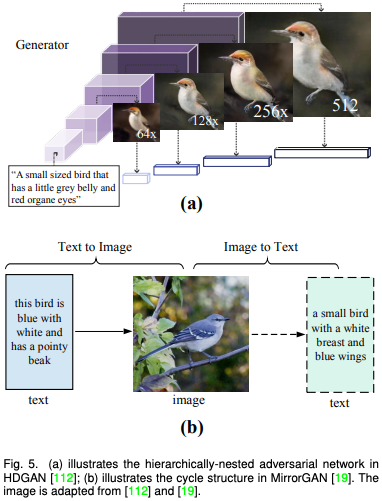
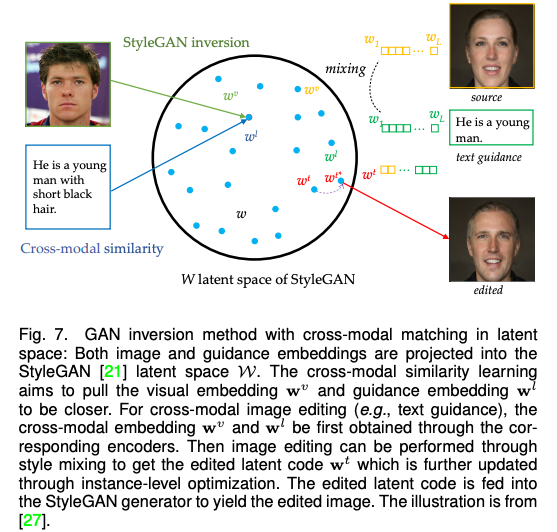
由于基于 GAN 的方法一般使用条件 GAN 和 无条件 GAN 反演,因此该论文将这一类别进一步分为模态内条件(例如语义图,边缘图),跨模态条件(例如文字和语音),和 GAN 反演(统一模态)并进行了详细描述。
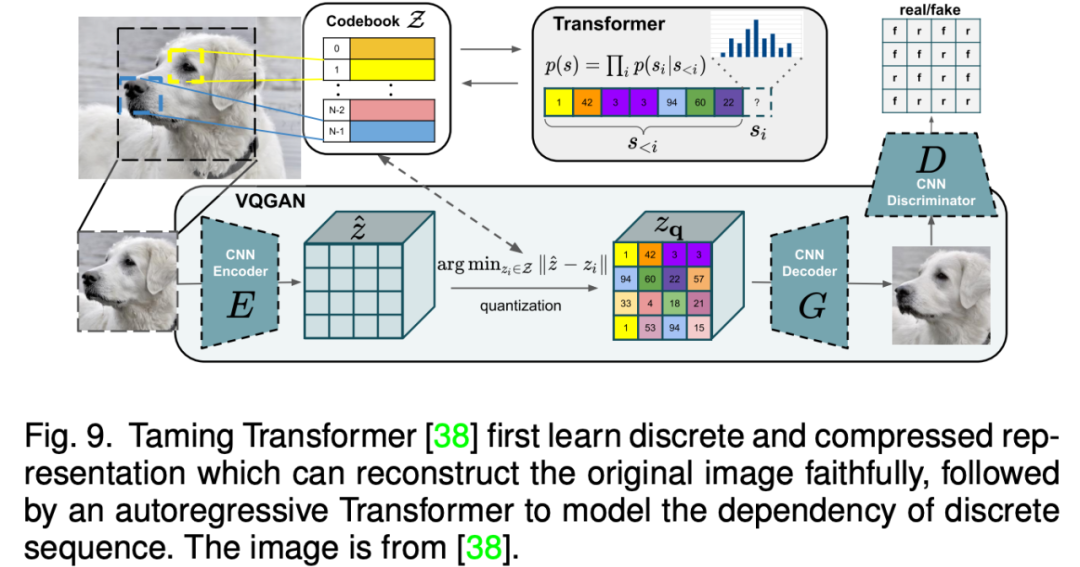
相比于基于 GAN 的方法,自回归模型方法能够更加自然的处理多模态数据,以及利用目前流行的 Transformer 模型。自回归方法一般先学习一个向量量化编码器将图片离散地表示为 token 序列,然后自回归式地建模 token 的分布。由于文本和语音等数据都能表示为 token 并作为自回归建模的条件,因此各种多模态图片合成与编辑任务都能统一到一个框架当中。
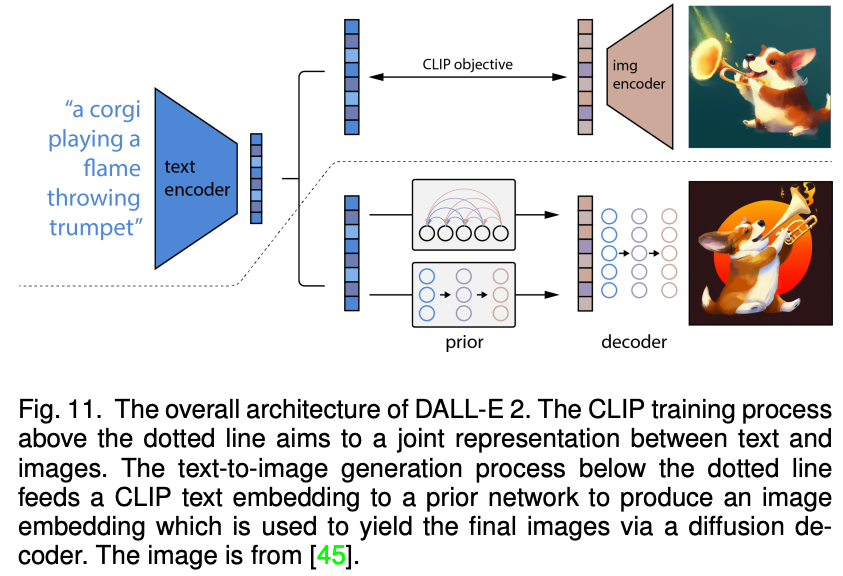
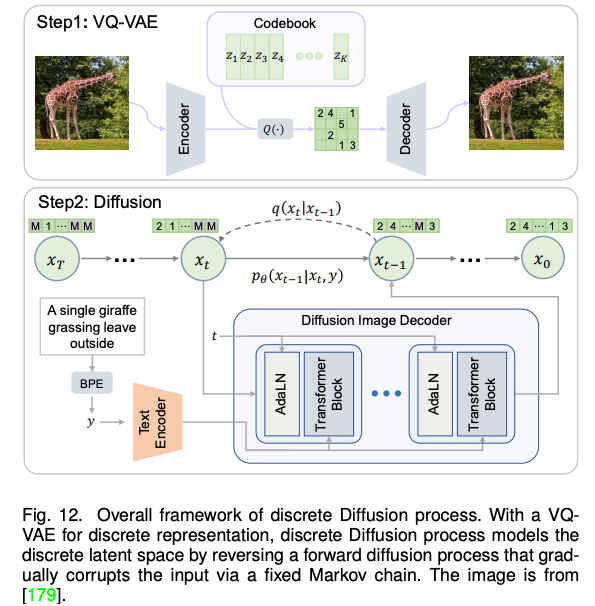
近期,火热的扩散模型也被广泛应用于多模态合成与编辑任务。例如效果惊人的 DALLE-2 和 Imagen 都是基于扩散模型实现的。相比于 GAN,扩散式生成模型拥有一些良好的性质,比如静态的训练目标和易扩展性。该论文依据条件扩散模型和预训练扩散模型对现有方法进行了分类与详细分析。
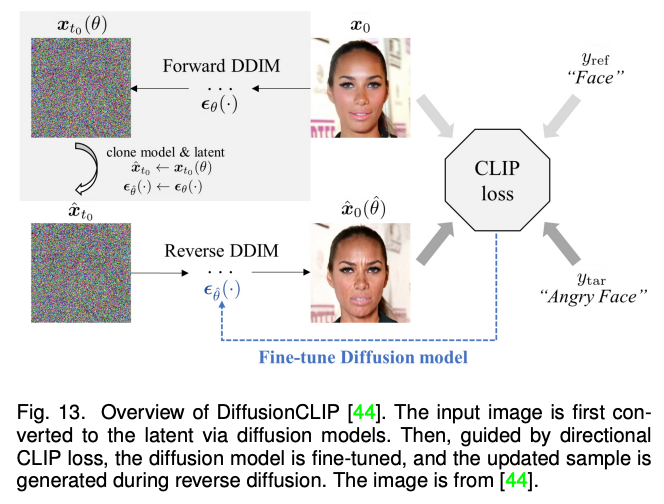
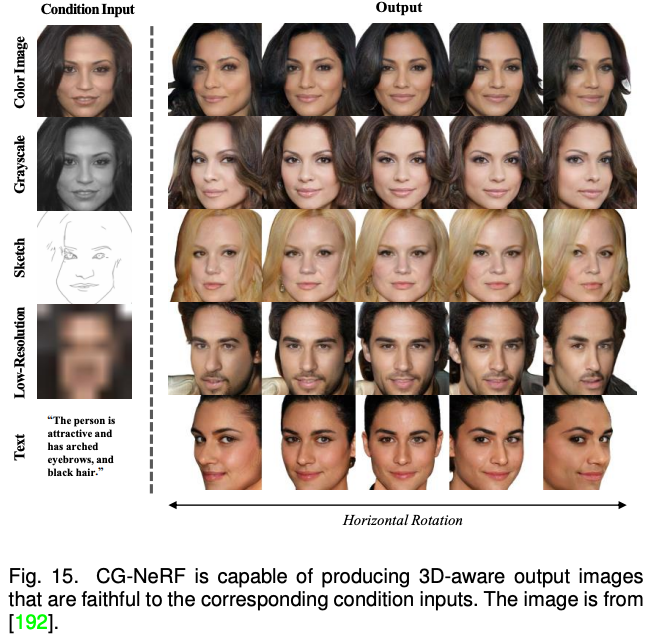
以上方法主要聚焦于 2D 图像的多模态合成与编辑。近期随着神经辐射场(NeRF)的迅速发展,3D 感知的多模态合成与编辑也吸引了越来越多的关注。由于需要考虑多视角一致性,3D 感知的多模态合成与编辑是更具挑战性的任务。本文针对单场景优化 NeRF,生成式 NeRF 和 NeRF 反演的三种方法对现有工作进行了分类与总结。 随后,该综述对以上四种模型方法的进行了比较和讨论。总体而言,相比于 GAN,目前最先进的模型更加偏爱自回归模型和扩散模型。而 NeRF 在多模态合成与编辑任务的应用为这个领域的研究打开了一扇新的窗户。
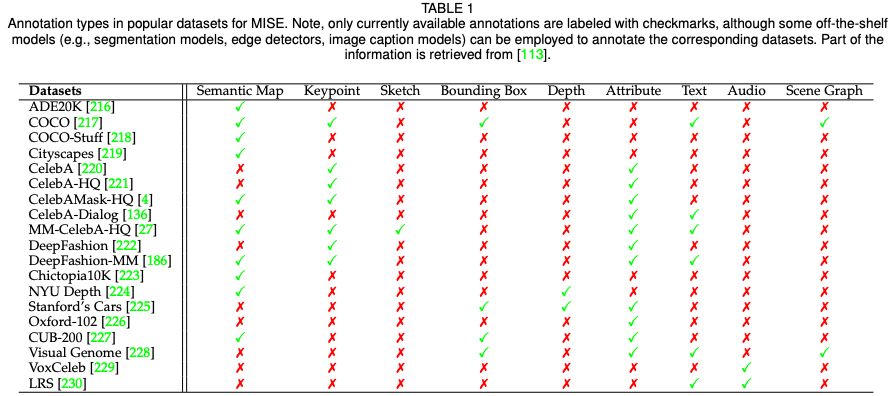
在第四章节,该综述汇集了多模态合成与编辑领域流行的数据集以及相应的模态标注,并且针对各模态典型任务(语义图像合成,文字到图像合成,语音引导图像编辑)对当前方法进行了定量的比较。 在第五章节,该综述对此领域目前的挑战和未来方向进行了探讨和分析,包括大规模的多模态数据集,准确可靠的评估指标,高效的网络架构,以及 3D 感知的发展方向。 在第六和第七章节,该综述分别阐述了此领域潜在的社会影响和总结了文章的内容与贡献。
-
谷歌
+关注
关注
27文章
6257浏览量
111942 -
数据
+关注
关注
8文章
7347浏览量
95004 -
图像
+关注
关注
2文章
1096浏览量
42435
原文标题:多模态图像合成与编辑这么火,马普所、南洋理工等出了份详细综述
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

基于多通道分类合成的SAR图像分类研究
高分辨率合成孔径雷达图像的直线特征多尺度提取方法
基于超图的多模态关联特征处理方法
基于双残差超密集网络的多模态医学图像融合方法

基于联合压缩感知的多模态目标统一跟踪方法

简述文本与图像领域的多模态学习有关问题
用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统

VisCPM:迈向多语言多模态大模型时代

多模态大模型最全综述来了!

基于几何分析的神经辐射场编辑方法

大模型+多模态的3种实现方法




评论