 低分辨率行为识别技术具有广泛的应用价值
低分辨率行为识别技术具有广泛的应用价值

导读】在CVPR 2022 ActivityNet: Tiny Actions Challenge赛道中,中国科学院深圳先进技术研究院多媒体中心在低分辨率视频行为识别任务的解决方案获得冠军。
安防监控是智慧城市的重要组成部分。然而,在城市监控场景下,行人目标往往距离摄像头远,所占像素小,这为理解目标的行为带来了很大挑战。
为此,CVPR 2022 ActivityNet: Tiny Actions Challenge引入了TinyVIRAT低分辨率行为识别视频数据集。该数据集从监控摄像头上截取视频,没有包含任何人为的下采样和降质处理,填补了真实场景下的低分辨率行为识别数据的空白。
TinyVIRAT数据集共有训练数据16950个、验证数据3308个、测试数据6097个,平均每个视频数据长度在3秒左右。
这些低分辨视频数据的分辨率从10x10像素到128x128像素不等,一共包含26种行为标签,包含人体动作和汽车等交通工具行驶相关的类别[4]。

图1 TinyVIRAT低分辨行为识别数据集示例
这个数据集存在两个主要的识别难点:
目标离摄像头的距离很远,分辨率很低,行为细节模糊;
数据集呈现严重的类别不平衡现象。图2展示了TinyVIRAT训练集的样本比例分布。
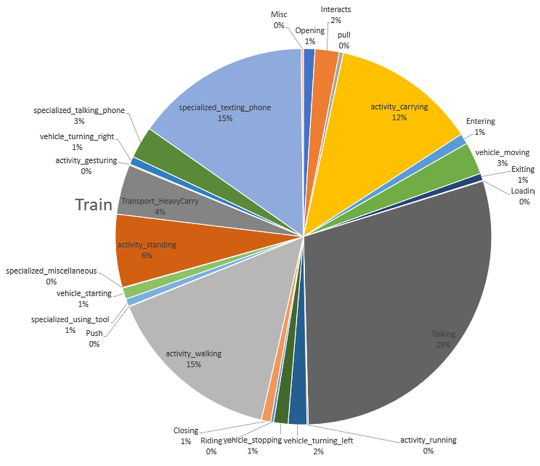
图2 TinyVIRAT训练集样本分布比例图
为了解决上述问题,我们采用了如图3所示识别流程:
通过精选识别骨干网络并进行数据增强和平衡来减轻数据集的过拟合;
设计了高低分双模态行为识别框架,通过高分辨率识别网络的知识指导低分辨率行为识别网络的训练;
进行模型融合和后处理应对数据集的类别不均衡现象。
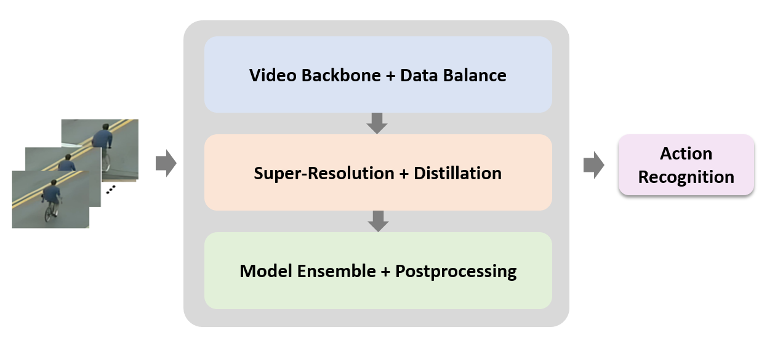
图3 低分辨率行为识别方案流程图
骨干网络选择和数据增强
本方案中,我们选用鲁棒高效的视频表征模型ir-CSN-ResNet[1]和 Uniformer-Base[2]作为骨干网络。这两个网络都包含时空建模的轻量化设计,在TinyVIRAT数据集上的识别结果较好,过拟合程度较低。
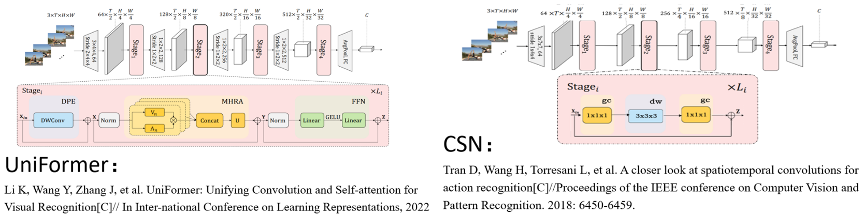
图4 Uniformer/CSN 行为识别网络结构示意图
由于本数据集是真实场景下的低分辨率数据集,直接使用这两种网络效果并不是很好,需要进行额外的参数设置。在训练和测试的过程中,我们把每个视频平均分成16份,在每一份随机选择一帧得到视频采样数据。
为了缓解数据集类别不平衡的现象,我们选出了训练集中的长尾类别数据,把它们进行水平翻转扩充数据量。如表1所示,这两种额外设置提升了Baseline结果。
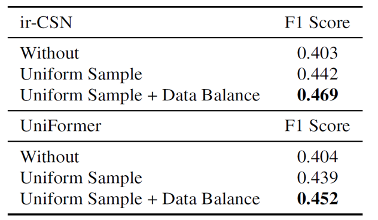
表1 视频骨干网络和主要训练设定实验结果
高低分双模态行为识别框架
如上所述,TinyVIRAT这个低分辨率数据集常常无法清晰的显示行为主体的动作细节。
为了降低数据的噪声,增强部分动作细节,我们提出一种高低分双模态模型蒸馏训练框架,该框架以高分辨率视频知识作为引导,提升低分辨率目标行为的识别精度。训练框架流程图如图5所示:
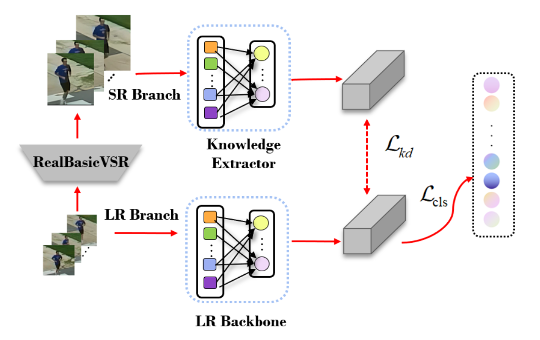
图5 高低分双模态模型蒸馏训练框架
首先,我们应用预训练的RealBasicVSR[3]视频超分辨率模型,将低分辨率视频转化成分辨率较高、动作细节较为清晰的训练数据,如图6所示。以这些视频为基础,我们可以训练高分辨率视频的特征提取网络。

图6 超分辨率数据和源数据对比图
第二,对每一个低分辨率训练视频,我们把它相对应的高分辨率视频送到高分辨率特征提取模型中,得到高分辨率分支的类别预测分数(图5上方分支)。同时,我们也把原有的低分辨视频送到低分辨率分支(图5下方分支),得到相应的类别预测分数。
第三,我们使用两种监督信号进行模型训练,使得高分辨率网络的知识能够指导低分辨率模型的学习。损失函数如式所示:
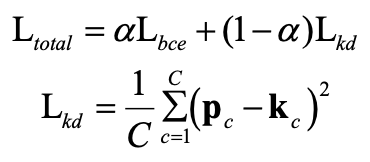
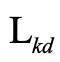 指的是知识蒸馏损失(例如MSE损失),p代表低分辨率分支的预测向量,k代表高分辨率分支得到的额外知识。
指的是知识蒸馏损失(例如MSE损失),p代表低分辨率分支的预测向量,k代表高分辨率分支得到的额外知识。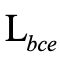 是预测向量和真实标签的交叉熵损失。
是预测向量和真实标签的交叉熵损失。
消融实验结果如表2所示。表中2021 TinyAction Top1 Model指的是2021年ActivityNet Tiny Actions Challenge的最佳团队模型[4],它在TinyVIRAT数据集上的识别F1 Score为0.478。
表中ir-CSN表示用低分辨率数据直接训练得到的模型,ir-CSN(SR)表示用超分辨率后的数据训练得到模型,ir-CSN(SR+KD)指的是用高低分双模态模型蒸馏机制训练得到的模型。ir-CSN(SR+KD)模型取得了最佳的提交结果,在单模型上比去年的最佳方案提升了1.4%。

表2 高低分双模态蒸馏框架消融实验结果
后处理与模型融合
该数据集的长尾效应比较严重。为此,我们设计后处理与模型融合方案,进一步提升长尾类别的识别准确率。
第一,我们发现,训练初期得到的模型在长尾类别的识别上比经过充分训练的模型效果好。因此,对于每一个网路结构,我们会选用多个不同训练阶段的模型。经过大量消融实验和提交,我们最终选用12个模型进行融合。
第二,为了进一步提高F1-Score,我们为所有的识别类别设定识别阈值。样本数目大的类别应用较大的阈值,长尾类别设定较小的阈值。
最后,我们采用类别的先验知识辅助模型融合,进一步提升长尾类别的识别精度。例如,我们借鉴2021年DeepBlue AI冠军团队的后处理方法[4],利用互斥标签辅助判定。假设texting_phone和talking_phone两种互斥类别的预测分数都高过设定阈值,只选择预测分数较高的那个类。
经过模型融合与后处理,我们最终取得0.883的F1 Score,如表3所示。在榜单上排名第1。
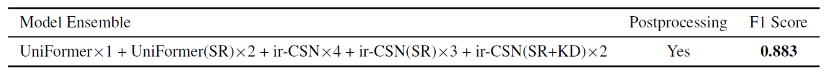
表3 模型融合和后处理最终结果
实验总结与展望
本方案中,我们重点解决真实监控场景下的低分辨率行为识别,主要的方案总结为以下三点:
选择了鲁棒高效的行为识别骨干网络,对长尾数据进行平衡和增强;
提出了高低分双模态行为识别训练框架,用超分辨率网络知识指导低分辨率行为识别;
设计面向长尾类别的模型融合和后处理方案。
关于低分辨率行为识别相关技术的应用范围较为广泛。在视频辅助裁判方面,该技术对真实情况下分辨率较低的场景具有一定的数据增强和识别能力,可以辅助判断一些离摄像机很远的动作类别,减少因摄像机远或者模糊导致的误判。
在面对庞大的低分辨视频数据库时,该技术可以对低分辨率视频进行分类,方便搜索引擎搜索。在智能安防领域,此技术可以辅助监控远离摄像头的一些模糊信息,减少监控探头的监控死角。
综上所述,本文提出的低分辨率行为识别技术在现实生活中具有较为广泛的应用价值。
-
数据
+关注
关注
8文章
7314浏览量
93983 -
分辨率
+关注
关注
2文章
1119浏览量
43246 -
识别技术
+关注
关注
0文章
211浏览量
20346
原文标题:CVPR 2022 ActivityNet竞赛冠军:中科院深圳先进院提出高低分双模态行为识别框架
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ADC分辨率与精度的区别是什么
镜头分辨率如何匹配工业相机的分辨率

电能质量在线监测装置的暂态记录分辨率如何影响故障类型识别?

电能质量在线监测装置的暂态记录分辨率对电力系统故障诊断有何影响?

分辨率对于模拟到数字转换器有什么重要性
如何构建带有VGA输出的低分辨率热成像
聚徽厂家工业液晶屏的高分辨率成像技术揭秘
分辨率 vs 噪声 —— ADC的挑战
如何计算存储示波器的垂直分辨率?
PC电脑USB3.0接口无法识别CX3设备分辨率怎么解决?
Arm精锐超级分辨率技术助力提升游戏性能

DLPDLCR3310EVM如何实现分辨率扩展的?
如何提高透镜成像的分辨率
如何选择扫描电镜的分辨率?






 工商网监
工商网监
评论